【NLP】天池新闻文本分类(五)——基于深度学习的文本分类2
【NLP】天池新闻文本分类(五)——基于深度学习的文本分类2
- 前言
- Word2Vec文本法
- Word2Vec词向量
- TextCNN文本分类
- TextRNN文本分类
- HAN文本分类
前言
本文是NLP之新闻文本分类挑战赛(赛题链接)。
的第五篇:基于深度学习得文本分类2。上一篇是基于深度学习的文本分类1,介绍了基于FastText的文本分类。本篇将介绍Word2Vec的文本表示方法、使用TextCNN、TextRNN进行文本分类、以及使用HAN网络结构进行文本分类。
Word2Vec文本法
Word2Vec词向量
word2vec模型背后的基本思想是对出现在上下文环境里的词进行预测。对于每一条输入文本,我们选取一个上下文窗口和一个中心词,并基于这个中心词去预测窗口里其他词出现的概率。因此,word2vec模型可以方便地从新增语料中学习到新增词的向量表达,是一种高效的在线学习算法(online learning)。
word2vec的主要思路:通过单词和上下文彼此预测,对应的两个算法分别为:
- Skip-grams (SG):预测上下文
- Continuous Bag of Words (CBOW):预测目标单词
另外提出两种更加高效的训练方法:
- Hierarchical softmax
- Negative sampling
1. Skip-grams原理和网络结构
Word2Vec模型中,主要有Skip-Gram和CBOW两种模型,从直观上理解,Skip-Gram是给定input word来预测上下文。而CBOW是给定上下文,来预测input word。
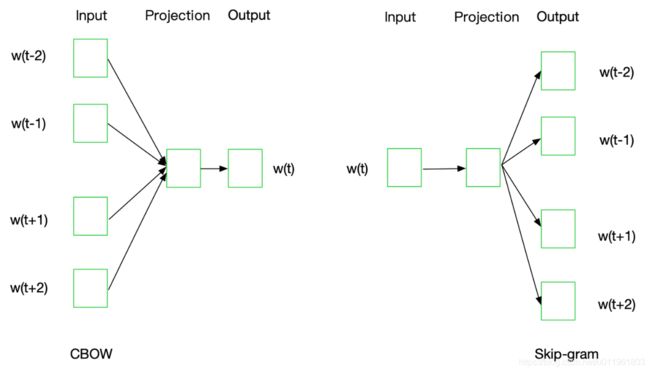
Word2Vec模型实际上分为了两个部分,第一部分为建立模型,第二部分是通过模型获取嵌入词向量。
Word2Vec的整个建模过程实际上与自编码器(auto-encoder)的思想很相似,即先基于训练数据构建一个神经网络,当这个模型训练好以后,我们并不会用这个训练好的模型处理新的任务,我们真正需要的是这个模型通过训练数据所学得的参数,例如隐层的权重矩阵——后面我们将会看到这些权重在Word2Vec中实际上就是我们试图去学习的“word vectors”。
Skip-grams过程
假如我们有一个句子“The dog barked at the mailman”。
1.首先我们选句子中间的一个词作为我们的输入词,例如我们选取“dog”作为input word;
2.有了input word以后,我们再定义一个叫做skip_window的参数,它代表着我们从当前input word的一侧(左边或右边)选取词的数量。如果我们设置skip_window=2,那么我们最终获得窗口中的词(包括input word在内)就是[‘The’, ‘dog’,‘barked’, ‘at’]。skip_window=2代表着选取左input word左侧2个词和右侧2个词进入我们的窗口,所以整个窗口大小span=2x2=4。另一个参数叫num_skips,它代表着我们从整个窗口中选取多少个不同的词作为我们的output word,当skip_window=2,num_skips=2时,我们将会得到两组 (input word, output word) 形式的训练数据,即 (‘dog’, ‘barked’),(‘dog’, ‘the’)。
3.神经网络基于这些训练数据将会输出一个概率分布,这个概率代表着我们的词典中的每个词作为input word的output word的可能性。这句话有点绕,我们来看个例子。第二步中我们在设置skip_window和num_skips=2的情况下获得了两组训练数据。假如我们先拿一组数据 (‘dog’, ‘barked’) 来训练神经网络,那么模型通过学习这个训练样本,会告诉我们词汇表中每个单词当’dog’作为input word时,其作为output word的可能性。
也就是说模型的输出概率代表着到我们词典中每个词有多大可能性跟input word同时出现。例如:如果我们向神经网络模型中输入一个单词“Soviet“,那么最终模型的输出概率中,像“Union”, ”Russia“这种相关词的概率将远高于像”watermelon“,”kangaroo“非相关词的概率。因为”Union“,”Russia“在文本中更大可能在”Soviet“的窗口中出现。
我们将通过给神经网络输入文本中成对的单词来训练它完成上面所说的概率计算。下面的图中给出了一些我们训练样本的例子。我们选定句子“The quick brown fox jumps over lazy dog”,设定我们的窗口大小为2(window_size=2),也就是说我们仅选输入词前后各两个词和输入词进行组合。下图中,蓝色代表input word,方框内代表位于窗口内的单词。
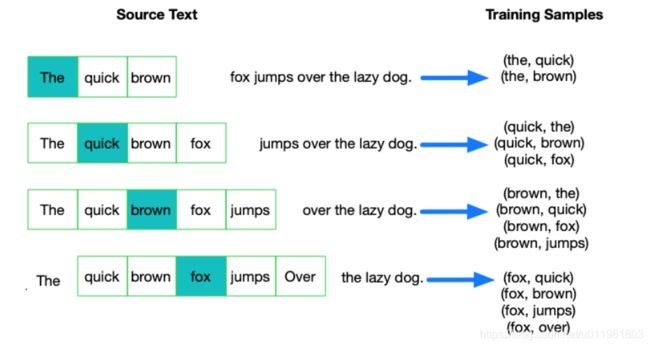

我们的模型将会从每对单词出现的次数中习得统计结果。例如,我们的神经网络可能会得到更多类似(“Soviet“,”Union“)这样的训练样本对,而对于(”Soviet“,”Sasquatch“)这样的组合却看到的很少。因此,当我们的模型完成训练后,给定一个单词”Soviet“作为输入,输出的结果中”Union“或者”Russia“要比”Sasquatch“被赋予更高的概率。
TextCNN文本分类
TextCNN利用CNN(卷积神经网络)进行文本特征抽取,不同大小的卷积核分别抽取n-gram特征,卷积计算出的特征图经过MaxPooling保留最大的特征值,然后将拼接成一个向量作为文本的表示。
这里我们基于TextCNN原始论文的设定,分别采用了100个大小为2,3,4的卷积核,最后得到的文本向量大小为100*3=300维。
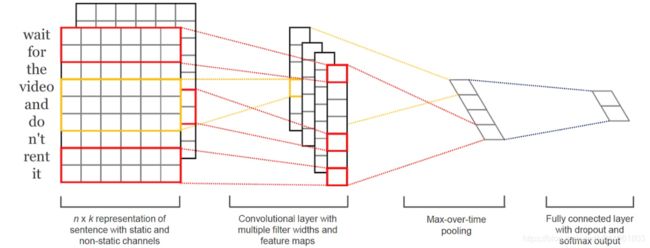
TextCNN
- 模型搭建
self.filter_sizes = [2, 3, 4] # n-gram window
self.out_channel = 100
self.convs = nn.ModuleList([nn.Conv2d(1, self.out_channel, (filter_size, input_size), bias=True) for filter_size in self.filter_sizes])
- 前向传播
pooled_outputs = []
for i in range(len(self.filter_sizes)):
filter_height = sent_len - self.filter_sizes[i] + 1
conv = self.convs[i](batch_embed)
hidden = F.relu(conv) # sen_num x out_channel x filter_height x 1
mp = nn.MaxPool2d((filter_height, 1)) # (filter_height, filter_width)
# sen_num x out_channel x 1 x 1 -> sen_num x out_channel
pooled = mp(hidden).reshape(sen_num, self.out_channel)
pooled_outputs.append(pooled)
TextRNN文本分类
TextRNN利用RNN(循环神经网络)进行文本特征抽取,由于文本本身是一种序列,而LSTM天然适合建模序列数据。TextRNN将句子中每个词的词向量依次输入到双向双层LSTM,分别将两个方向最后一个有效位置的隐藏层拼接成一个向量作为文本的表示。
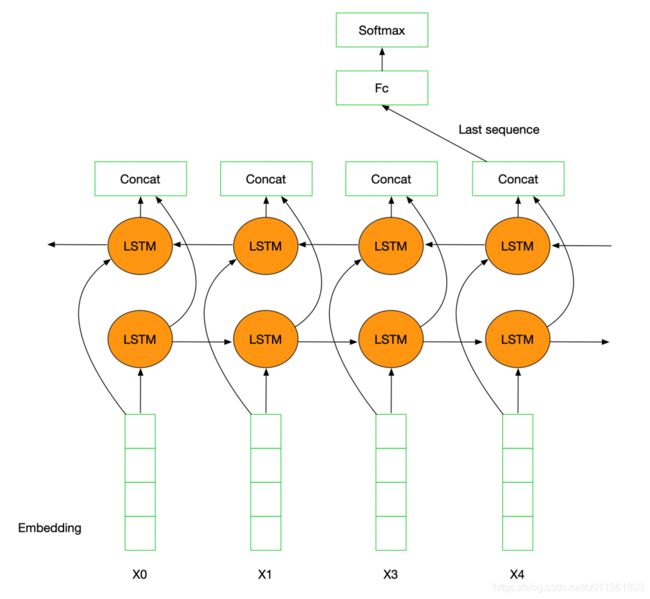
TextRNN
- 模型搭建
input_size = config.word_dims
self.word_lstm = LSTM(
input_size=input_size,
hidden_size=config.word_hidden_size,
num_layers=config.word_num_layers,
batch_first=True,
bidirectional=True,
dropout_in=config.dropout_input,
dropout_out=config.dropout_hidden,
)
- 前向传播
hiddens, _ = self.word_lstm(batch_embed, batch_masks) # sent_len x sen_num x hidden*2
hiddens.transpose_(1, 0) # sen_num x sent_len x hidden*2
if self.training:
hiddens = drop_sequence_sharedmask(hiddens, self.dropout_mlp)
HAN文本分类
Hierarchical Attention Network for Document Classification(HAN)基于层级注意力,在单词和句子级别分别编码并基于注意力获得文档的表示,然后经过Softmax进行分类。其中word encoder的作用是获得句子的表示,可以替换为上节提到的TextCNN和TextRNN,也可以替换为下节中的BERT。
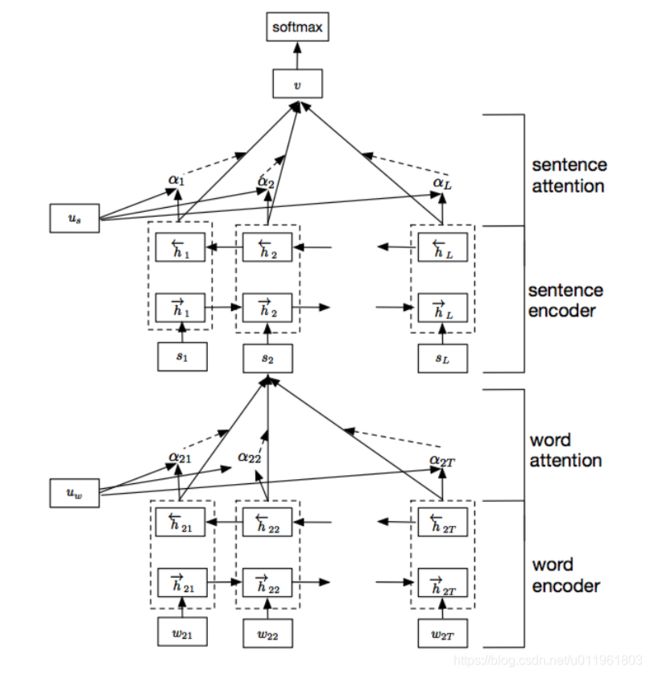
ps:由于时间比较紧,后面会有四篇文章对应如上通过Word2Vec训练词向量和三种深度学习文本分类(使用TextCNN、TextRNN完成文本分类、使用HAN进行文本分类)的详细介绍。