我投的是基础研究,感觉自己比较幸运,好像是顺利的走了TST的内推,因为在笔试的时候监考官让我们在试卷右上角标注TST。而且面试通知的也是直接去银科大厦,在腾讯的茶水间面的。
接下来说说面试和笔试。
笔试其实挺无语的,和去年的题大量重合,我前一天刚好找了去年的题看,所以很多变态题都答上了。当然,其实还是有3,4道题根本没记住答案(但是知道是去年的题),所以就乱答的。附加题认真答了一道,另一道基本不会,随便写了几行。后来在一面的时候看到自己卷子的分数是71,面试官跟我说分数还不错,我无语ing……
然后是面试,面试一共分2次,最后一次是广州那边经理的电面,可能在5.1左右才打过来。一来比较晚,二来不怎么问技术了,三来我还没接到,所以就不说了。需要提一下的是,选事业群根本0效果,最后面试的部门还是腾讯自己定的,就是说每个部门自己从简历&笔试结果中挑觉得满意的,然后通知他们去面试。也就是说,参加面试的时候,你的实习部门就已经定好了。面试我的部门是腾讯微信模式识别组,据面试官介绍微信的总部在广州,不过他们这个30人的研发小组在北京,是从腾讯研究院分出来的,主要做基于微信的NLP,语音和图像方面的识别算法。
一面:
面试官态度都很好,一共两个人。第一个人主要问了大量简历上的内容,问的很细,很深。比如我获过某个奖,那么他就会问我做负责什么部分,做的什么东西,是怎么做的。我的一段实习经历他也很仔细的问了,基本上就是把我在那个公司做过的所有东西都介绍了,而且是细致到在设计xxx算法时设计和提取了xxx特征,这个xxx特征的具体是怎么提取的,以及物理意义等。总的来说,就是把简历里面能问的基本问了个遍。所以说,大家写简历的时候,自己没把握的最好别写,因为有些面试官会问的很细,或者就挑那种你提了一句的东西使劲问,看你到底有没有做过。简历大概问了半个小时,然后他说我们做几道算法题吧,给了我三道题和一叠纸,给我一个小时做。题都不算难,不过要求编程实现,三道题分别是:
1.用最快的方法计算斐波那契数列
我觉得用o(n)非递归的方法就行,当然有o(log n)的更快方法,不过这个非递归挺难写的(要是递归就达不到o(log n))。
注:有人提到了直接用公式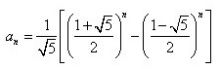 来计算值,时间复杂度可以降低到o(1),真的如此吗?
来计算值,时间复杂度可以降低到o(1),真的如此吗?
对此我进行了深入的调研,首先,这个公式里面包含了两个求幂算式,也就是说需要pow函数,那么pow函数的原理是什么呢?在VC里面这个函数的源代码是无法看到的,但是pow函数的原理还是可以查到的,因为在这里n只取整数,那么算一个数的整数次幂,最快的方法也是o(log n),所以,这部分的运算的实际时间复杂度是o(log n),并不是所谓的o(1)。
空口无凭,我编了一小段程序来验证自己的想法,定义了两个求斐波那契数列的函数,其中fab1是用公式算,fab2用o(n)的方法计算。
void fab1(double in){ double a=1/sqrt((double)5); double b=pow((0.5+sqrt((double)5)/2),in); double c=pow((0.5-sqrt((double)5)/2),in); //printf("%lf\n",a*(b-c)); }; void fab2(int in){ int a=0,b=1,res,i; for(i=2;i<=in;i++){ res=a; a=b; b+=a; } }; int main(){ LARGE_INTEGER freq,begin,end; QueryPerformanceFrequency(&freq); QueryPerformanceCounter(&begin); for(int i=1;i<=100000;i++) fab1(50);//fab2(50); QueryPerformanceCounter(&end); double time=(double)(end.QuadPart-begin.QuadPart)/(double)freq.QuadPart*1000; printf("%lf\n",time); system("pause"); return 0; }
每次求n=50的值,循环取10000次和100000次,得到的结果如下:
循环10000次时,fab1平均时间在1.9微秒左右,fab2平均时间在2.5微秒左右
循环100000次时,fab1平均时间在18微秒左右,fab2平均时间在25微秒左右
所谓的o(1)时间复杂度无论如何也不可能和o(n)复杂度差距这么小吧?因此,斐波那契数列的最低时间复杂度就是o(log n),另外,由于公式中的数字都是浮点型,如果使用整型的o(log n)算法,理论上应该比这种公式法还要快。
2.给定整数sum,在乱序数组中寻找所有满足x+y=sum的组合并打印
这个很简单,就是先排序,然后维护一头一尾两个指针,找到所有组合,时间复杂度o(nlog n+n)
这个也可以用哈希做,时间复杂度o(n),不过数据的范围不能太大。
3.在一个超长数组中寻找第K大数
这个不能用快排的partition做,因为数组超长,所以暗含不能全部装入内存中。我当时没太理解题目,所以写了那个用partition做的算法,后来觉得有可能是考堆排序,又大致写了堆排序那个算法的思路:读入前K个数并建立一个大根堆,然后依次读入数组中剩下的数并调整堆,最后从堆中输出最小的那个数就行,时间复杂度o(klog k+n)
第二个面试官看了我的代码和思路之后,觉得大致没问题,然后说我再考你两道吧,说思路就行。
1.在2个排序好的数组中找所有元素的第k大
我刚开始说直接调用一次归并排序的merge就行,o(k)时间复杂度,面试官说让我再想想,还有没有更快的。然后我苦苦思索了5分钟,想了一种o(log k)的,假设两个数组是降序排列,先比较两个数组的第k/2个数,如果相等,则这个数必为第k大的,如果不等,不妨假设A[k/2] 2.找到1-10000以内的所有质数 如果之前没有接触过算法的,这道题还是有些难度的,因为挨个判断质数的方法时间复杂度太高,不可行。一般的做法是,开辟一个有10000个元素的bool型数组prime[10000],然后从2开始到根号10000,即100结束,把这些数的倍数都设置为false,例如:取2的时候,prime[4],prime[6],prime[8],prime[10]...都会被设置为false,这样结束之后,再从头扫一遍prime,把里面还是true的数组的下标输出,即为范围内所有质数。不过,我当时很二的说了一句“这道题我做过”,现在想想实在是大忌啊,如果大家面试的时候遇到做过的题,一定不要马上承认做过,因为有的面试官会很不爽,面子挂不住,感觉自己出的题简单了,然后就会来一道巨难的题虐你。还好我遇到的这位面试官人比较随和,说我还挺诚实,但是,不出意外的提高了题的难度。他说我这个基本已经接近最优的时间复杂度了,但是有些值,比如prime[6],在2和3的时候被重复设置了2次false,所以还有更快一点的,让我想一想。我当时心里各种无语啊,之前做poj上面题的时候从来没想过还有更快一点的。然后我冥思苦想了几分钟,想到了质数和合数的特点,把设置false的规则修改了一下,如果到第n个数,并且该数是true,那么从n开始,下标为n乘以n之后(包括n)为true的数组元素都被设置为false,例如:2的时候,4,6,8,10...都被设置为false,那么3的时候,3*3,3*5,3*7...都被设置为false,因为2,4..都是false了,所以不会出现3*2,3*4等被重复设置为false的情况,这样就能保证每个合数仅被设置为false一次。因此,这种方法比原来的快一些(其实就快了一点点)。 答完了上面两道题,一面基本就结束了,面试官就让我回去等通知了。这次面试大概有2个小时,半个小时问简历,1个半小时问算法。 二面过程 二面是一位女面试官,人很好,完全看不出是做技术研发的,我的第一反应她应该是管理团队的,不过面试一开始我就发现自己错了,她的科研基础实在是太好了。在此,再一次提醒大家,千万不要把自己一知半解的东西放到简历上,遇上较真的面试官,肯定会悲剧的。接着说二面,她首先很有针对性的挑了我简历上那种一笔带过的东西问,看我是不是真的做过。问了大概10分钟,她开始问我的基础知识,在模式识别和机器学习领域学习了什么,我跟她说对于常用的分类器都比较熟悉,她让我对常用的分类器的熟悉程度排一下序,我说自己实现过adaboost,随机森林没写过但是肯定能写出来,svm用过,知道原理,神经网络了解原理,最不熟悉。她接着让我介绍神经网络的原理(挑我最不熟悉……),我想了1分钟,大致把节点的构成,怎么连接每一层,用梯度下降训练之类的说了一通,说实话我好久没看神经网络了,的确不算很熟了。她可能不是很满意吧,然后又追问svm和神经网络的区别。一个是线性分类器,一个是非线性分类器,这个区别其实还是挺明显的,接着我又跟她侃了一下最近比较火的深度学习(deep learning),表达了一下自己的看法,深度学习这个东西,其实计算复杂度太高,并不能覆盖所有的机器学习领域,而且是否一定要依赖于神经网络,其实也存在争议,因为有国外的团队用聚类(K-means)和线性分类器(SVM)组合的方式达到了跟受限波尔兹曼机(RBM)接近甚至超越的效果,大概说了20分钟,她算是比较满意我的回答了。接下来她问了一个很简单但是挺值得注意的问题,在图像处理方面经常需要读取图片,动态申请一个二维数组也很常见,她让我写一下我是怎么做的,下面代码是两种常见的方式 第一种都能想到,但是速度慢,申请内存是分开申请的,所以总的效率完全赶不上第二种。第二种是一次申请内存,for循环仅仅是对指针的赋值。另一方面,在释放的时候,第二种容易忘记释放二维指针的每个元素,也需要循环释放。而第二种就没有这种问题,只需要delete[] arr和delete[] pImg即可。 这道题我的答案似乎她很满意,然后又跟我接着讨论了一些搞算法要追求极致的思想等等,接着还给我展示了她们团队在微信中负责的功能(摇一摇搜歌,这个的确很强大,我自己试过了),接下来又问了我一个牛顿迭代法,一个求方程数值解的方法,这个我的确没学过……,她说我肯定学过,只不过早就忘了而已,而且她觉得这个方法很有意思,跟梯度下降非常相似。呃,我表示无语,跟她说回去一定看。这样又过去大概10分钟。最后,她总结了一下面试,说对我还是挺满意的,觉得我基础比较扎实。哦,她在面试中还提到了团队里面做算法的基本都有acm经历,我表示自己不是计算机科班出身,所以本科没做过,她说这方面还是需要学一学的,我说现在已经学习了一部分,回去再继续学。 总的感觉就是,第二轮面试就轻松了很多,大概只有40分钟。面试官问的都是跟他们研究内容相关的知识,所以基础知识很重要,另外,如果有些东西,自己不知道直说就是了,如果不懂装懂反而让面试官很反感。 当然,这个是我的面试经历,不过面试是因人而异,因面试官而异的,所以大家不要照搬,如果能帮助到大家,那是最好了。里面应该还有一些错误和问题,望不吝赐教。//方法1
unsigned char** pImg= new unsigned char*[m];
for(int i=0;i
}
unsigned char** pImg= new unsigned char*[m];
unsigned char* arr= new unsigned char[m*n];
for(int i=0;i
}