SegNet: A Deep convolutioa Encoder-Decoder Architecture for image Segmentation
摘要
我们呈现了一个新颖和实践可行的深度全卷积模型来进行逐像素的语义分割,网络名叫做SegNet。核心的训练分割的引擎包含一个编码网络和一个与之相联系的解码网络,后面还有一个逐像素的分类层。编码网络的结构拓扑上和VGG16的前13层网络相同。解码网络的作用是将低分辨率的编码特征图映射成输入分辨率的特征图来完成逐像素的分类。我么的SegNet形式上的新颖之处在于解码网络对低分辨率输入特征图进行上采样。解码器使用在编码阶段与之相联系的max pool中用来计算的max pooling索引来完成非线性上采样。这可以不用再学习上采样的参数。上采样之后的特征图是稀疏的,然后再和一个可以训练的滤波器进行卷积来产生密集特征图。我们将我们提出的网络模型与广泛被使用的FCN和广为人知的DeepLab-LargeFOV【3】,DeconvNet【4】进行了比较。比较结果展示了我们的内存和准确率平衡使得性能上得到了很大的提升。
SegNet主要是被场景理解应用所驱动产生的。因此,它在推理阶段内存和计算时间上都必须很高效。相比于其他模型,它的训练参数数量更少,可以使用端到端的随机梯度下降来进行学习。我们也针对SegNet和其他模型在路面场景数据集和SUN RGB-D 室内数据集上进行了一个controlled benchmark。这些量化的评价指标显示了SegNet相比于其他模型在推理时间上,有效的内存使用上性能有很大提升。我们提供了 Caffe源代码和一个demo。
1.介绍
现在在逐像素的语义标注上有一个非常活跃的研究【7, 8, 9, 2, 4, 10, 11, 12, 13, 3, 14, 15, 16】。但是最近的一些方法都是直接尝试采用为逐像素标注的类别预测设计的深度网络【7】。结果虽然也很激动人心,但是也比较粗糙【3】。这主要是因为最大池化和下采样降低了特征图的尺寸。我们设计SegNet的主要动机在于我们需要将低分辨率特征映射到输入分辨率来完成逐像素的分类。这种映射必须产生对准确的边界定位非常有用的特征。
我们的SegNet网络主要是被路面场景理解的应用所驱动,场面场景理解要求对外观(道路、建筑),形状(汽车、行人)建模,理解环境关系(不同类别比如说路面和人行道)。在典型的道路场景中大多数的像素属于大类别比如说道路、建筑,因此网络必须产生平滑分割。引擎也必须能够根据形状(即使小尺寸)来描绘出物体。因此,在提取出来的图像表示中保留边界信息很重要。端到端的训练可以使用权重更新技术共同优化网络参数,这样会有很大的好处,因为它更容易repeatable。
SegNet的核心组成是解码网络,包含与每一个编码层所对应的解码层。使用最大索引来执行非线性上采样,这个idea来自于一个为非监督学习设计的网络【19】.在解码阶段重新使用最大池化索引有几个实际的好处:(1)提升了边界划分的能力;(2)减少了端到端训练的参数;(3)这种形式的上采样经过很小的修改就可以包含进任何形式的编码解码网络中如【2, 10】。
这篇论文的主要贡献在于我们对SegNet解码技术的分析和使用了FCN。很多最近的完成分割的深度网络有相同的编码网络如VGG16,但是解码网络的形式不同。其它网络的训练参数的量级达到了数亿,因此端到端地训练会有很大的困难。因为训练很困难使它们往往采用多阶段训练(FCN)【2】,或增加一个预训练【11, 20】,使用辅助技术如区域提议推理【4】,或full Training【10】,提升性能的后处理技术【3】.我们分析了【2, 4】中使用的解码过程,reveal their pros and cons。
我们在两个场景分割任务中评价了SegNet的性能 ,Cam Vid 路面场景【22】和SUN RGB-D indoor 场景分割【23】.方法【3】也使用了分类网络和单独的CRF(条件随机长)后处理技术来执行分割。为了证明SegNet网络性能,我们有一个实时在线的路面场景分割的demo,里面有11个自动驾驶感兴趣的类别。
Section3描述和分析了SegNet, Section4在室内室外场景数据集上评价SegNet。Section5一个一般性的和其他模型的比较讨论。

2.文献回顾
- 语义分割数据集【21】,【22】,【23】,【25】,【26】;
- 室内RGBD逐像素语义分割因为NYU数据集的发布【25】越来越流行。这个数据集显示深度通道可提升分割性能。
- 新的用来分割的深度网络【2】【4】【10】【13】【14】通过解码或映射低分辨率的图像表示来完成逐像素预测。在所有这些网络里编码网络都是VGG16。
- FCN的编码网络参数量很大(134M),解码网络的参数两却很少(0.5M)。总体的尺寸依然很大,使得它很难在特定任务上完成端到端的训练。因此,FCN的作者才使用逐阶段的训练。FCN除了训练相关的问题,在解码阶段需要重新使用编码的特征图使得测试时内存消耗非常大。我们详细地研究了这种网络作为重要的对比模型。
- FCN+RNN (Fine-tunning on large dataset 【21】【42】)
- CRF-RNN
- DeConvolutional Network【4】
- 我们的模型受到Ranzato等【19】的无监督特征学习网络的启发。核心的学习模块是编码-解码网络。编码网络包括卷积,tanh非线性,最大池化,下采样。对于每一个样本,池化过程中计算max值的索引被存储下来传递给解码器。解码器使用这个索引对特征图上采样。上采样之后的特征图再进行卷积,重建输入图像。网络使用分类预训练。
- 论文【50】讨论了从低分辨率的特征图上去学习上采样的需要,这种学习正是本论文的核心。

3.结构
SegNet = Encoder + Decoder + a final pixelwise classification layer
编码网络使用VGG16,丢弃3个卷积层;一下子使参数量从134M变为14.7M。
编码网络中的每一层在解码网络中都有一个对应的层,因此解码网络也有13层。最终的解码器输出给一个多类别的soft-max分类器给每一个像素产生一个类别概率。
编码网络: 卷积 + BN + ReLU + Max Pooling
Max-pooling is used to achieve translation invariance over small spatial shifts in the input image. Sub-sampling results in a large input image context (spatial window) for each pixel in the feature map. While several layers of max-pooling and sub-sampling can achieve more translation invariance for robust classification correspondingly there is a loss of spatial resolution of the feature maps. The increasingly lossy (boundary detail) image representation is not beneficial for segmentation where boundary delineation is vital. Therefore, it is necessary to capture and store boundary information in the encoder feature maps before sub-sampling is performed. If memory during inference is not constrained, then all the encoder feature maps (after subsampling) can be stored. This is usually not the case in practical applications and hence we propose a more efficient way to store this information. It involves storing only the max-pooling indices, i.e, the locations of the maximum feature value in each pooling window is memorized for each encoder feature map. In principle, this can be done using 2 bits for each 2 × 2 pooling window and is thus much more efficient to store as compared to memorizing feature map(s) in float precision.
这一段话说到了最大池化不仅仅降低维度减少计算量的作用,增大了特征图像素点的感受野,也引入了平移不变性,这种平移不变性使得卷积网络在分类中鲁棒性增强。这段话也明确地指出卷积特征能够提取细节信息,位置信息,物体边界信息。但是池化却在不断地丢失这种信息。
解码器采用最大池化中保存下来的索引来上采样,会产生稀疏的特征图。
DeconvNet【53】和U-Net【16】与SegNet有相同的结构,但是它们的参数量更大,需要更多的计算资源,很难实现端到端训练,主要是因为它们使用了全连接层。

3.1解码器的变体
- SegNet-Basic有4个编码器和4个解码器(从结构图中可以看出)。编码和解码阶段每一个卷积后面都有一个BN,解码阶段卷积之后没有add bias,也没有ReLU非线性。
FCN的decoder
On the right in Fig. 3 is the FCN (also FCN-Basic) decoding technique. The important design element of the FCN model is dimensionality reduction step of the encoder feature maps. This compresses the encoder feature maps which are then used in the corresponding decoders. Dimensionality reduction of the encoder feature maps, say of 64 channels, is performed by convolving them with 1 × 1 × 64 × K trainable filters, where K is the number of classes. The compressed K channel final encoder layer feature maps are the input to the decoder network. In a decoder of this network, upsampling is performed by inverse convolution using a fixed or trainable multi-channel upsampling kernel. We set the kernel size to 8 × 8. This manner of upsampling is also termed as deconvolution.
SegNet的decoder
Note that, in comparison, SegNet the multi-channel convolution using trainable decoder filters is performed after upsampling to densifying feature maps. The upsampled feature map in FCN has K channels. It is then added element-wise to the corresponding resolution encoder feature map to produce the output decoder feature map. The upsampling kernels are initialized using bilinear interpolation weights [2].
这段话解释了FCN中的decoder的结构,在FCN里上采样是通过反卷积来完成,反卷积的参数这里说是可以是固定的也可以是可训练的。融合低层的信息前每个分支都是要进行一次卷积核尺寸为1*1的卷积,这里说的主要是为了降维。这里说上采样卷积核是用双线性插值的权重进行初始化。
3.2训练
- 损失函数:交叉熵,The loss is summed up over all the pixels in a mini-batch.
- class balancing :
When there is large variation in the number of pixels in each class in the training set (e.g road, sky and building
pixels dominate the CamVid dataset) then there is a need to weight the loss differently based on the true class. This is termed class balancing. We use median frequency balancing [13] where the weight assigned to a class in the loss function is the ratio of the median of class frequencies computed on the entire training set divided by the class frequency. This implies that larger classes in the training set have a weight smaller than 1 and the weights of the smallest classes are the highest. We also experimented with training the different variants without class balancing or equivalently using natural frequency balancing.
这里说的class frequency到底是什么,这是一个很大的疑问。
一篇解释SegNet比较好的博客
原文地址:SegNet
复现详解:http://mi.eng.cam.ac.uk/projects/segnet/tutorial.html
实现代码: github
TensorFlow
简介:
SegNet是Cambridge提出旨在解决自动驾驶或者智能机器人的图像语义分割深度网络,开放源码,基于caffe框架。SegNet基于FCN,修改VGG-16网络得到的语义分割网络,有两种版本的SegNet,分别为SegNet与Bayesian SegNet,同时SegNet作者根据网络的深度提供了一个basic版(浅网络)。
网络框架:
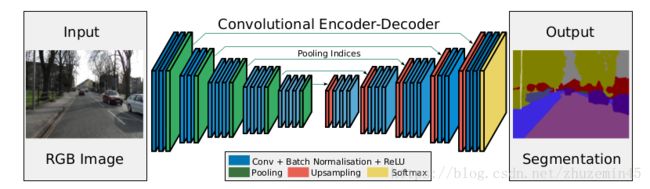
SegNet和FCN思路十分相似,只是Encoder,Decoder(Upsampling)使用的技术不一致。此外SegNet的编码器部分使用的是VGG16的前13层卷积网络,每个编码器层都对应一个解码器层,最终解码器的输出被送入soft-max分类器以独立的为每个像素产生类概率。
左边是卷积提取特征,通过pooling增大感受野,同时图片变小,该过程称为Encoder,右边是反卷积(在这里反卷积与卷积没有区别)与upsampling,通过反卷积使得图像分类后特征得以重现,upsampling还原到图像原始尺寸,该过程称为Decoder,最后通过Softmax,输出不同分类的最大值,得到最终分割图。
Encoder:
Encoder过程中,通过卷积提取特征,SegNet使用的卷积为same卷积,即卷积后保持图像原始尺寸;在Decoder过程中,同样使用same卷积,不过卷积的作用是为upsampling变大的图像丰富信息,使得在Pooling过程丢失的信息可以通过学习在Decoder得到。SegNet中的卷积与传统CNN的卷积并没有区别。

Pooling&Upsampling(decoder):
Pooling在CNN中是使得图片缩小一半的手段,通常有max与mean两种Pooling方式,下图所示的是max Pooling。max Pooling是使用一个2x2的filter,取出这4个权重最大的一个,原图大小为4x4,Pooling之后大小为2x2,原图左上角粉色的四个数,最后只剩最大的6,这就是max的意思。
在SegNet中的Pooling与其他Pooling多了一个index功能(该文章亮点之一),也就是每次Pooling,都会保存通过max选出的权值在2x2 filter中的相对位置,对于上图的6来说,6在粉色2x2 filter中的位置为(1,1)(index从0开始),黄色的3的index为(0,0)。同时,从网络框架图可以看到绿色的pooling与红色的upsampling通过pool indices相连,实际上是pooling后的indices输出到对应的upsampling(因为网络是对称的,所以第1次的pooling对应最后1次的upsamping,如此类推)。
Upsamping就是Pooling的逆过程(index在Upsampling过程中发挥作用),Upsamping使得图片变大2倍。我们清楚的知道Pooling之后,每个filter会丢失了3个权重,这些权重是无法复原的,但是在Upsamping层中可以得到在Pooling中相对Pooling filter的位置。所以Upsampling中先对输入的特征图放大两倍,然后把输入特征图的数据根据Pooling indices放入,下图所示,Unpooling对应上述的Upsampling,switch variables对应Pooling indices。
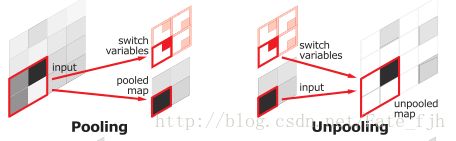
对比FCN可以发现SegNet在Unpooling时用index信息,直接将数据放回对应位置,后面再接Conv训练学习。这个上采样不需要训练学习(只是占用了一些存储空间)。反观FCN则是用transposed convolution策略,即将feature 反卷积后得到upsampling,这一过程需要学习,同时将encoder阶段对应的feature做通道降维,使得通道维度和upsampling相同,这样就能做像素相加得到最终的decoder输出.

Deconvolution:
pooling&Upsampling示意图中右边的Upsampling可以知道,2x2的输入,变成4x4的图,但是除了被记住位置的Pooling indices,其他位置的权值为0,因为数据已经被pooling走了。因此,SegNet使用的反卷积在这里用于填充缺失的内容,因此这里的反卷积与卷积是一模一样,在网络框架图中跟随Upsampling层后面的是也是卷积层。
Output:
在网络框架中,SegNet,最后一个卷积层会输出所有的类别(包括other类),网络最后加上一个softmax层,由于是end to end, 所以softmax需要求出所有每一个像素在所有类别最大的概率,最为该像素的label,最终完成图像像素级别的分类。
Bayesian SegNet
可以知道,在SeNet中最后每个像素都会对每一类的概率进行计算,再通过Softmat输出概率最大的一个,然后这个像素点就认为是这一类别,对应的概率就是这一像素属于该类的概率。这种由原因到结果的推导,可以称为先验概率,任何先验概率使用都会出现一个问题,不能知道这一结果的可靠性,即便先验概率非常大,但是对于不同的样本,先验概率无法保证一定正确。正是如此,才需要有从结果寻找原因的贝叶斯概率,即后验概率,它能给出结果的可信程度,即置信度。Bayesian SegNet正是通过后验概率,告诉我们图像语义分割结果的置信度是多少。Bayesian SegNet如下图所示。

对比两框架图,并没有发现Bayesian SegNet与SegNet的差别,事实上,从网络变化的角度看,Bayesian SegNet只是在卷积层中多加了一个DropOut层,其作用后面解释。最右边的两个图Segmentation与Model Uncertainty,就是像素点语义分割输出与其不确定度(颜色越深代表不确定性越大,即置信度越低)。
DropOut
在传统神经网络中DropOut层的主要作用是防止权值过度拟合,增强学习能力。DropOut层的原理是,输入经过DropOut层之后,随机使部分神经元不工作(权值为0),即只激活部分神经元,结果是这次迭代的向前和向后传播只有部分权值得到学习,即改变权值。
因此,DropOut层服从二项分布,结果不是0,就是1,在CNN中可以设定其为0或1的概率来到达每次只让百分之几的神经元参与训练或者测试。在Bayesian SegNet中,SegNet作者把概率设置为0.5,即每次只有一半的神经元在工作。因为每次只训练部分权值,可以很清楚地知道,DropOut层会导致学习速度减慢。
Gaussian process & Monte Carlo Dropout Sampling
参考论文:Dropout as a Bayesian approximation: Representing model uncertainty in deep learning
这里只说明高斯过程与蒙特卡罗抽样的作用,不详细解释原理。 高斯过程是指任意有限个随机变量都服从联合高斯分布,同时只需要知道均值与协防差就能够确定一个高斯过程,所以高斯过程可以用于从有限维到无限维的回归问题,从已知高斯分布,增加新的随机变量分布可以求出新的高斯分布,根据新的分布可以求出其均值与方差。
如何确定一个高斯分布?需要多次采样才能确定一个分布。蒙特卡罗抽样告诉我们可以通过设计一个试验方法将一个事件的频率转化为概率,因为在足够大的样本中,事件发生的频率会趋向事件发生的概率,因此可以很方便地求出一个未知分布。通过蒙特卡罗抽样,就可以求出一个新分布的均值与方差,这样使用方差大小就可以知道一个分布对于样本的差异性,我们知道方差越大差异越大。
Use Bayesian SegNet
在Bayesian SegNet中通过DropOut层实现多次采样,多次采样的样本值为最后输出,方差最为其不确定度,方差越大不确定度越大,如图6所示,mean为图像语义分割结果,var为不确定大小。所以在使用Bayesian SegNet预测时,需要多次向前传播采样才能够得到关于分类不确定度的灰度图,Bayesian SegNet预测如下图所示。
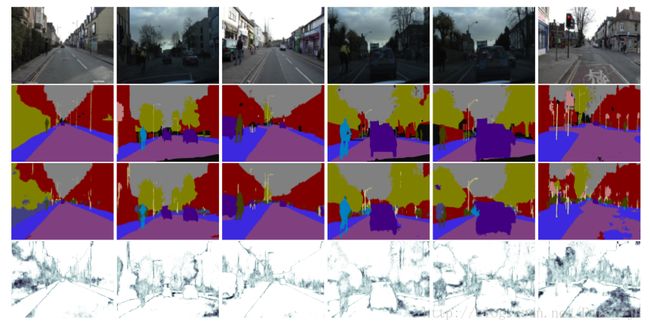
第一行为输入图像,第二行为ground truth,第三行为Bayesian SegNet语义分割输出,第四行为不确定灰度图。可以看到,
1.对于分类的边界位置,不确定性较大,即其置信度较低。
2.对于图像语义分割错误的地方,置信度也较低。
3.对于难以区分的类别,例如人与自行车,road与pavement,两者如果有相互重叠,不确定度会增加。