动手学深度学习实现DAY-1
节选自“ElitesAI·动手学深度学习PyTorch版”
线性回归;Softmax与分类模型、多层感知机
文本预处理;语言模型;循环神经网络基础
线性回归
主要内容包括:
- 线性回归的基本要素
- 线性回归模型从零开始的实现
- 线性回归模型使用pytorch的简洁实现
线性回归的基本要素
模型
为了简单起见,这里我们假设价格只取决于房屋状况的两个因素,即面积(平方米)和房龄(年)。接下来我们希望探索价格与这两个因素的具体关系。线性回归假设输出与各个输入之间是线性关系:
price=warea⋅area+wage⋅age+bprice=warea⋅area+wage⋅age+b
数据集
我们通常收集一系列的真实数据,例如多栋房屋的真实售出价格和它们对应的面积和房龄。我们希望在这个数据上面寻找模型参数来使模型的预测价格与真实价格的误差最小。在机器学习术语里,该数据集被称为训练数据集(training data set)或训练集(training set),一栋房屋被称为一个样本(sample),其真实售出价格叫作标签(label),用来预测标签的两个因素叫作特征(feature)。特征用来表征样本的特点。
损失函数
在模型训练中,我们需要衡量价格预测值与真实值之间的误差。通常我们会选取一个非负数作为误差,且数值越小表示误差越小。一个常用的选择是平方函数。 它在评估索引为 ii 的样本误差的表达式为
l(i)(w,b)=12(y^(i)−y(i))2,l(i)(w,b)=12(y^(i)−y(i))2,
L(w,b)=1n∑i=1nl(i)(w,b)=1n∑i=1n12(w⊤x(i)+b−y(i))2.L(w,b)=1n∑i=1nl(i)(w,b)=1n∑i=1n12(w⊤x(i)+b−y(i))2.
优化函数 - 随机梯度下降
当模型和损失函数形式较为简单时,上面的误差最小化问题的解可以直接用公式表达出来。这类解叫作解析解(analytical solution)。本节使用的线性回归和平方误差刚好属于这个范畴。然而,大多数深度学习模型并没有解析解,只能通过优化算法有限次迭代模型参数来尽可能降低损失函数的值。这类解叫作数值解(numerical solution)。
在求数值解的优化算法中,小批量随机梯度下降(mini-batch stochastic gradient descent)在深度学习中被广泛使用。它的算法很简单:先选取一组模型参数的初始值,如随机选取;接下来对参数进行多次迭代,使每次迭代都可能降低损失函数的值。在每次迭代中,先随机均匀采样一个由固定数目训练数据样本所组成的小批量(mini-batch)BB,然后求小批量中数据样本的平均损失有关模型参数的导数(梯度),最后用此结果与预先设定的一个正数的乘积作为模型参数在本次迭代的减小量。
(w,b)←(w,b)−η|B|∑i∈B∂(w,b)l(i)(w,b)(w,b)←(w,b)−η|B|∑i∈B∂(w,b)l(i)(w,b)
学习率: ηη代表在每次优化中,能够学习的步长的大小
批量大小: BB是小批量计算中的批量大小batch size
总结一下,优化函数的有以下两个步骤:
- (i)初始化模型参数,一般来说使用随机初始化;
- (ii)我们在数据上迭代多次,通过在负梯度方向移动参数来更新每个参数。
矢量计算
在模型训练或预测时,我们常常会同时处理多个数据样本并用到矢量计算。在介绍线性回归的矢量计算表达式之前,让我们先考虑对两个向量相加的两种方法。
- 向量相加的一种方法是,将这两个向量按元素逐一做标量加法。
- 向量相加的另一种方法是,将这两个向量直接做矢量加法。
In [1]:
import torch import time # init variable a, b as 1000 dimension vector n = 1000 a = torch.ones(n) b = torch.ones(n)
In [2]:
# define a timer class to record time
class Timer(object):
"""Record multiple running times."""
def __init__(self):
self.times = []
self.start()
def start(self):
# start the timer
self.start_time = time.time()
def stop(self):
# stop the timer and record time into a list
self.times.append(time.time() - self.start_time)
return self.times[-1]
def avg(self):
# calculate the average and return
return sum(self.times)/len(self.times)
def sum(self):
# return the sum of recorded time
return sum(self.times)
现在我们可以来测试了。首先将两个向量使用for循环按元素逐一做标量加法。
In [3]:
timer = Timer()
c = torch.zeros(n)
for i in range(n):
c[i] = a[i] + b[i]
'%.5f sec' % timer.stop()
另外是使用torch来将两个向量直接做矢量加法:
In [4]:
timer.start() d = a + b '%.5f sec' % timer.stop()
结果很明显,后者比前者运算速度更快。因此,我们应该尽可能采用矢量计算,以提升计算效率。
线性回归模型从零开始的实现
In [5]:
# import packages and modules %matplotlib inline import torch from IPython import display from matplotlib import pyplot as plt import numpy as np import random print(torch.__version__)
生成数据集
使用线性模型来生成数据集,生成一个1000个样本的数据集,下面是用来生成数据的线性关系:
price=warea⋅area+wage⋅age+bprice=warea⋅area+wage⋅age+b
In [6]:
# set input feature number
num_inputs = 2
# set example number
num_examples = 1000
# set true weight and bias in order to generate corresponded label
true_w = [2, -3.4]
true_b = 4.2
features = torch.randn(num_examples, num_inputs,
dtype=torch.float32)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()),
dtype=torch.float32)
使用图像来展示生成的数据
In [7]:
plt.scatter(features[:, 1].numpy(), labels.numpy(), 1);
读取数据集
In [8]:
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices) # random read 10 samples
for i in range(0, num_examples, batch_size):
j = torch.LongTensor(indices[i: min(i + batch_size, num_examples)]) # the last time may be not enough for a whole batch
yield features.index_select(0, j), labels.index_select(0, j)
In [9]:
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, '\n', y)
break
初始化模型参数
In [10]:
w = torch.tensor(np.random.normal(0, 0.01, (num_inputs, 1)), dtype=torch.float32) b = torch.zeros(1, dtype=torch.float32) w.requires_grad_(requires_grad=True) b.requires_grad_(requires_grad=True)
定义模型
定义用来训练参数的训练模型:
price=warea⋅area+wage⋅age+bprice=warea⋅area+wage⋅age+b
In [11]:
def linreg(X, w, b):
return torch.mm(X, w) + b
定义损失函数
我们使用的是均方误差损失函数:
l(i)(w,b)=12(y^(i)−y(i))2,l(i)(w,b)=12(y^(i)−y(i))2,
In [12]:
def squared_loss(y_hat, y):
return (y_hat - y.view(y_hat.size())) ** 2 / 2
定义优化函数
在这里优化函数使用的是小批量随机梯度下降:
(w,b)←(w,b)−η|B|∑i∈B∂(w,b)l(i)(w,b)(w,b)←(w,b)−η|B|∑i∈B∂(w,b)l(i)(w,b)
In [13]:
def sgd(params, lr, batch_size):
for param in params:
param.data -= lr * param.grad / batch_size # ues .data to operate param without gradient track
训练
当数据集、模型、损失函数和优化函数定义完了之后就可来准备进行模型的训练了。
In [14]:
# super parameters init
lr = 0.03
num_epochs = 5
net = linreg
loss = squared_loss
# training
for epoch in range(num_epochs): # training repeats num_epochs times
# in each epoch, all the samples in dataset will be used once
# X is the feature and y is the label of a batch sample
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y).sum()
# calculate the gradient of batch sample loss
l.backward()
# using small batch random gradient descent to iter model parameters
sgd([w, b], lr, batch_size)
# reset parameter gradient
w.grad.data.zero_()
b.grad.data.zero_()
train_l = loss(net(features, w, b), labels)
print('epoch %d, loss %f' % (epoch + 1, train_l.mean().item()))
In [15]:
w, true_w, b, true_b
线性回归模型使用pytorch的简洁实现
In [16]:
import torch
from torch import nn
import numpy as np
torch.manual_seed(1)
print(torch.__version__)
torch.set_default_tensor_type('torch.FloatTensor')
生成数据集
在这里生成数据集跟从零开始的实现中是完全一样的。
In [17]:
num_inputs = 2 num_examples = 1000 true_w = [2, -3.4] true_b = 4.2 features = torch.tensor(np.random.normal(0, 1, (num_examples, num_inputs)), dtype=torch.float) labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()), dtype=torch.float)
读取数据集
In [18]:
import torch.utils.data as Data
batch_size = 10
# combine featues and labels of dataset
dataset = Data.TensorDataset(features, labels)
# put dataset into DataLoader
data_iter = Data.DataLoader(
dataset=dataset, # torch TensorDataset format
batch_size=batch_size, # mini batch size
shuffle=True, # whether shuffle the data or not
num_workers=2, # read data in multithreading
)
In [19]:
for X, y in data_iter:
print(X, '\n', y)
break
定义模型
In [20]:
class LinearNet(nn.Module):
def __init__(self, n_feature):
super(LinearNet, self).__init__() # call father function to init
self.linear = nn.Linear(n_feature, 1) # function prototype: `torch.nn.Linear(in_features, out_features, bias=True)`
def forward(self, x):
y = self.linear(x)
return y
net = LinearNet(num_inputs)
print(net)
In [21]:
# ways to init a multilayer network
# method one
net = nn.Sequential(
nn.Linear(num_inputs, 1)
# other layers can be added here
)
# method two
net = nn.Sequential()
net.add_module('linear', nn.Linear(num_inputs, 1))
# net.add_module ......
# method three
from collections import OrderedDict
net = nn.Sequential(OrderedDict([
('linear', nn.Linear(num_inputs, 1))
# ......
]))
print(net)
print(net[0])
初始化模型参数
In [22]:
from torch.nn import init init.normal_(net[0].weight, mean=0.0, std=0.01) init.constant_(net[0].bias, val=0.0) # or you can use `net[0].bias.data.fill_(0)` to modify it directly
In [23]:
for param in net.parameters():
print(param)
定义损失函数
In [24]:
loss = nn.MSELoss() # nn built-in squared loss function
# function prototype: `torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')`
定义优化函数
In [25]:
import torch.optim as optim optimizer = optim.SGD(net.parameters(), lr=0.03) # built-in random gradient descent function print(optimizer) # function prototype: `torch.optim.SGD(params, lr=, momentum=0, dampening=0, weight_decay=0, nesterov=False)`
训练
In [26]:
num_epochs = 3
for epoch in range(1, num_epochs + 1):
for X, y in data_iter:
output = net(X)
l = loss(output, y.view(-1, 1))
optimizer.zero_grad() # reset gradient, equal to net.zero_grad()
l.backward()
optimizer.step()
print('epoch %d, loss: %f' % (epoch, l.item()))
In [27]:
# result comparision dense = net[0] print(true_w, dense.weight.data) print(true_b, dense.bias.data)
两种实现方式的比较
-
从零开始的实现(推荐用来学习)
能够更好的理解模型和神经网络底层的原理
-
使用pytorch的简洁实现
能够更加快速地完成模型的设计与实现
softmax和分类模型
内容包含:
- softmax回归的基本概念
- 如何获取Fashion-MNIST数据集和读取数据
- softmax回归模型的从零开始实现,实现一个对Fashion-MNIST训练集中的图像数据进行分类的模型
- 使用pytorch重新实现softmax回归模型
softmax的基本概念
-
分类问题
一个简单的图像分类问题,输入图像的高和宽均为2像素,色彩为灰度。
图像中的4像素分别记为x1,x2,x3,x4x1,x2,x3,x4。
假设真实标签为狗、猫或者鸡,这些标签对应的离散值为y1,y2,y3y1,y2,y3。
我们通常使用离散的数值来表示类别,例如y1=1,y2=2,y3=3y1=1,y2=2,y3=3。 -
权重矢量
o1=x1w11+x2w21+x3w31+x4w41+b1o1=x1w11+x2w21+x3w31+x4w41+b1
o2=x1w12+x2w22+x3w32+x4w42+b2o2=x1w12+x2w22+x3w32+x4w42+b2
o3=x1w13+x2w23+x3w33+x4w43+b3o3=x1w13+x2w23+x3w33+x4w43+b3
- 神经网络图
下图用神经网络图描绘了上面的计算。softmax回归同线性回归一样,也是一个单层神经网络。由于每个输出o1,o2,o3o1,o2,o3的计算都要依赖于所有的输入x1,x2,x3,x4x1,x2,x3,x4,softmax回归的输出层也是一个全连接层。

softmax回归是一个单层神经网络softmax回归是一个单层神经网络
既然分类问题需要得到离散的预测输出,一个简单的办法是将输出值oioi当作预测类别是ii的置信度,并将值最大的输出所对应的类作为预测输出,即输出 argmaxioiargmaxioi。例如,如果o1,o2,o3o1,o2,o3分别为0.1,10,0.10.1,10,0.1,由于o2o2最大,那么预测类别为2,其代表猫。
- 输出问题
直接使用输出层的输出有两个问题:- 一方面,由于输出层的输出值的范围不确定,我们难以直观上判断这些值的意义。例如,刚才举的例子中的输出值10表示“很置信”图像类别为猫,因为该输出值是其他两类的输出值的100倍。但如果o1=o3=103o1=o3=103,那么输出值10却又表示图像类别为猫的概率很低。
- 另一方面,由于真实标签是离散值,这些离散值与不确定范围的输出值之间的误差难以衡量。
softmax运算符(softmax operator)解决了以上两个问题。它通过下式将输出值变换成值为正且和为1的概率分布:
y^1,y^2,y^3=softmax(o1,o2,o3)y^1,y^2,y^3=softmax(o1,o2,o3)
其中
y^1=exp(o1)∑3i=1exp(oi),y^2=exp(o2)∑3i=1exp(oi),y^3=exp(o3)∑3i=1exp(oi).y^1=exp(o1)∑i=13exp(oi),y^2=exp(o2)∑i=13exp(oi),y^3=exp(o3)∑i=13exp(oi).
容易看出y^1+y^2+y^3=1y^1+y^2+y^3=1且0≤y^1,y^2,y^3≤10≤y^1,y^2,y^3≤1,因此y^1,y^2,y^3y^1,y^2,y^3是一个合法的概率分布。这时候,如果y^2=0.8y^2=0.8,不管y^1y^1和y^3y^3的值是多少,我们都知道图像类别为猫的概率是80%。此外,我们注意到
argmaxioi=argmaxiy^iargmaxioi=argmaxiy^i
因此softmax运算不改变预测类别输出。
- 计算效率
- 单样本矢量计算表达式
为了提高计算效率,我们可以将单样本分类通过矢量计算来表达。在上面的图像分类问题中,假设softmax回归的权重和偏差参数分别为
- 单样本矢量计算表达式
W=⎡⎣⎢⎢⎢w11w21w31w41w12w22w32w42w13w23w33w43⎤⎦⎥⎥⎥,b=[b1b2b3],W=[w11w12w13w21w22w23w31w32w33w41w42w43],b=[b1b2b3],
设高和宽分别为2个像素的图像样本ii的特征为
x(i)=[x(i)1x(i)2x(i)3x(i)4],x(i)=[x1(i)x2(i)x3(i)x4(i)],
输出层的输出为
o(i)=[o(i)1o(i)2o(i)3],o(i)=[o1(i)o2(i)o3(i)],
预测为狗、猫或鸡的概率分布为
y^(i)=[y^(i)1y^(i)2y^(i)3].y^(i)=[y^1(i)y^2(i)y^3(i)].
softmax回归对样本ii分类的矢量计算表达式为
o(i)y^(i)=x(i)W+b,=softmax(o(i)).o(i)=x(i)W+b,y^(i)=softmax(o(i)).
- 小批量矢量计算表达式
为了进一步提升计算效率,我们通常对小批量数据做矢量计算。广义上讲,给定一个小批量样本,其批量大小为nn,输入个数(特征数)为dd,输出个数(类别数)为qq。设批量特征为X∈Rn×dX∈Rn×d。假设softmax回归的权重和偏差参数分别为W∈Rd×qW∈Rd×q和b∈R1×qb∈R1×q。softmax回归的矢量计算表达式为
OY^=XW+b,=softmax(O),O=XW+b,Y^=softmax(O),
其中的加法运算使用了广播机制,O,Y^∈Rn×qO,Y^∈Rn×q且这两个矩阵的第ii行分别为样本ii的输出o(i)o(i)和概率分布y^(i)y^(i)。
交叉熵损失函数
对于样本ii,我们构造向量y(i)∈Rqy(i)∈Rq ,使其第y(i)y(i)(样本ii类别的离散数值)个元素为1,其余为0。这样我们的训练目标可以设为使预测概率分布y^(i)y^(i)尽可能接近真实的标签概率分布y(i)y(i)。
- 平方损失估计
Loss=|y^(i)−y(i)|2/2Loss=|y^(i)−y(i)|2/2
然而,想要预测分类结果正确,我们其实并不需要预测概率完全等于标签概率。例如,在图像分类的例子里,如果y(i)=3y(i)=3,那么我们只需要y^(i)3y^3(i)比其他两个预测值y^(i)1y^1(i)和y^(i)2y^2(i)大就行了。即使y^(i)3y^3(i)值为0.6,不管其他两个预测值为多少,类别预测均正确。而平方损失则过于严格,例如y^(i)1=y^(i)2=0.2y^1(i)=y^2(i)=0.2比y^(i)1=0,y^(i)2=0.4y^1(i)=0,y^2(i)=0.4的损失要小很多,虽然两者都有同样正确的分类预测结果。
改善上述问题的一个方法是使用更适合衡量两个概率分布差异的测量函数。其中,交叉熵(cross entropy)是一个常用的衡量方法:
H(y(i),y^(i))=−∑j=1qy(i)jlogy^(i)j,H(y(i),y^(i))=−∑j=1qyj(i)logy^j(i),
其中带下标的y(i)jyj(i)是向量y(i)y(i)中非0即1的元素,需要注意将它与样本ii类别的离散数值,即不带下标的y(i)y(i)区分。在上式中,我们知道向量y(i)y(i)中只有第y(i)y(i)个元素y(i)y(i)y(i)y(i)为1,其余全为0,于是H(y(i),y^(i))=−logy^y(i)(i)H(y(i),y^(i))=−logy^y(i)(i)。也就是说,交叉熵只关心对正确类别的预测概率,因为只要其值足够大,就可以确保分类结果正确。当然,遇到一个样本有多个标签时,例如图像里含有不止一个物体时,我们并不能做这一步简化。但即便对于这种情况,交叉熵同样只关心对图像中出现的物体类别的预测概率。
假设训练数据集的样本数为nn,交叉熵损失函数定义为
ℓ(Θ)=1n∑i=1nH(y(i),y^(i)),ℓ(Θ)=1n∑i=1nH(y(i),y^(i)),
其中ΘΘ代表模型参数。同样地,如果每个样本只有一个标签,那么交叉熵损失可以简写成ℓ(Θ)=−(1/n)∑ni=1logy^(i)y(i)ℓ(Θ)=−(1/n)∑i=1nlogy^y(i)(i)。从另一个角度来看,我们知道最小化ℓ(Θ)ℓ(Θ)等价于最大化exp(−nℓ(Θ))=∏ni=1y^(i)y(i)exp(−nℓ(Θ))=∏i=1ny^y(i)(i),即最小化交叉熵损失函数等价于最大化训练数据集所有标签类别的联合预测概率。
模型训练和预测
在训练好softmax回归模型后,给定任一样本特征,就可以预测每个输出类别的概率。通常,我们把预测概率最大的类别作为输出类别。如果它与真实类别(标签)一致,说明这次预测是正确的。在3.6节的实验中,我们将使用准确率(accuracy)来评价模型的表现。它等于正确预测数量与总预测数量之比。
获取Fashion-MNIST训练集和读取数据
在介绍softmax回归的实现前我们先引入一个多类图像分类数据集。它将在后面的章节中被多次使用,以方便我们观察比较算法之间在模型精度和计算效率上的区别。图像分类数据集中最常用的是手写数字识别数据集MNIST[1]。但大部分模型在MNIST上的分类精度都超过了95%。为了更直观地观察算法之间的差异,我们将使用一个图像内容更加复杂的数据集Fashion-MNIST[2]。
我这里我们会使用torchvision包,它是服务于PyTorch深度学习框架的,主要用来构建计算机视觉模型。torchvision主要由以下几部分构成:
- torchvision.datasets: 一些加载数据的函数及常用的数据集接口;
- torchvision.models: 包含常用的模型结构(含预训练模型),例如AlexNet、VGG、ResNet等;
- torchvision.transforms: 常用的图片变换,例如裁剪、旋转等;
- torchvision.utils: 其他的一些有用的方法。
In [37]:
# import needed package
%matplotlib inline
from IPython import display
import matplotlib.pyplot as plt
import torch
import torchvision
import torchvision.transforms as transforms
import time
import sys
sys.path.append("/home/kesci/input")
import d2lzh1981 as d2l
print(torch.__version__)
print(torchvision.__version__)
1.3.0 0.4.1a0+d94043a
get dataset
In [38]:
mnist_train = torchvision.datasets.FashionMNIST(root='/home/kesci/input/FashionMNIST2065', train=True, download=True, transform=transforms.ToTensor()) mnist_test = torchvision.datasets.FashionMNIST(root='/home/kesci/input/FashionMNIST2065', train=False, download=True, transform=transforms.ToTensor())
class torchvision.datasets.FashionMNIST(root, train=True, transform=None, target_transform=None, download=False)
- root(string)– 数据集的根目录,其中存放processed/training.pt和processed/test.pt文件。
- train(bool, 可选)– 如果设置为True,从training.pt创建数据集,否则从test.pt创建。
- download(bool, 可选)– 如果设置为True,从互联网下载数据并放到root文件夹下。如果root目录下已经存在数据,不会再次下载。
- transform(可被调用 , 可选)– 一种函数或变换,输入PIL图片,返回变换之后的数据。如:transforms.RandomCrop。
- target_transform(可被调用 , 可选)– 一种函数或变换,输入目标,进行变换。
In [39]:
# show result print(type(mnist_train)) print(len(mnist_train), len(mnist_test))
60000 10000
In [40]:
# 我们可以通过下标来访问任意一个样本 feature, label = mnist_train[0] print(feature.shape, label) # Channel x Height x Width
torch.Size([1, 28, 28]) 9
如果不做变换输入的数据是图像,我们可以看一下图片的类型参数:
In [41]:
mnist_PIL = torchvision.datasets.FashionMNIST(root='/home/kesci/input/FashionMNIST2065', train=True, download=True) PIL_feature, label = mnist_PIL[0] print(PIL_feature)
In [42]:
# 本函数已保存在d2lzh包中方便以后使用
def get_fashion_mnist_labels(labels):
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat',
'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
return [text_labels[int(i)] for i in labels]
In [43]:
def show_fashion_mnist(images, labels):
d2l.use_svg_display()
# 这里的_表示我们忽略(不使用)的变量
_, figs = plt.subplots(1, len(images), figsize=(12, 12))
for f, img, lbl in zip(figs, images, labels):
f.imshow(img.view((28, 28)).numpy())
f.set_title(lbl)
f.axes.get_xaxis().set_visible(False)
f.axes.get_yaxis().set_visible(False)
plt.show()
In [44]:
X, y = [], []
for i in range(10):
X.append(mnist_train[i][0]) # 将第i个feature加到X中
y.append(mnist_train[i][1]) # 将第i个label加到y中
show_fashion_mnist(X, get_fashion_mnist_labels(y))
In [45]:
# 读取数据 batch_size = 256 num_workers = 4 train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers) test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=num_workers)
In [46]:
start = time.time()
for X, y in train_iter:
continue
print('%.2f sec' % (time.time() - start))
4.89 sec
softmax从零开始的实现
In [47]:
import torch
import torchvision
import numpy as np
import sys
sys.path.append("/home/kesci/input")
import d2lzh1981 as d2l
print(torch.__version__)
print(torchvision.__version__)
1.3.0 0.4.1a0+d94043a
获取训练集数据和测试集数据
In [48]:
batch_size = 256 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
模型参数初始化
In [49]:
num_inputs = 784 print(28*28) num_outputs = 10 W = torch.tensor(np.random.normal(0, 0.01, (num_inputs, num_outputs)), dtype=torch.float) b = torch.zeros(num_outputs, dtype=torch.float)
784
In [50]:
W.requires_grad_(requires_grad=True) b.requires_grad_(requires_grad=True)
Out[50]:
tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], requires_grad=True)
对多维Tensor按维度操作
In [51]:
X = torch.tensor([[1, 2, 3], [4, 5, 6]]) print(X.sum(dim=0, keepdim=True)) # dim为0,按照相同的列求和,并在结果中保留列特征 print(X.sum(dim=1, keepdim=True)) # dim为1,按照相同的行求和,并在结果中保留行特征 print(X.sum(dim=0, keepdim=False)) # dim为0,按照相同的列求和,不在结果中保留列特征 print(X.sum(dim=1, keepdim=False)) # dim为1,按照相同的行求和,不在结果中保留行特征
tensor([[5, 7, 9]])
tensor([[ 6],
[15]])
tensor([5, 7, 9])
tensor([ 6, 15])
定义softmax操作
y^j=exp(oj)∑3i=1exp(oi)y^j=exp(oj)∑i=13exp(oi)
In [52]:
def softmax(X):
X_exp = X.exp()
partition = X_exp.sum(dim=1, keepdim=True)
# print("X size is ", X_exp.size())
# print("partition size is ", partition, partition.size())
return X_exp / partition # 这里应用了广播机制
In [53]:
X = torch.rand((2, 5)) X_prob = softmax(X) print(X_prob, '\n', X_prob.sum(dim=1))
tensor([[0.1927, 0.2009, 0.1823, 0.1887, 0.2355],
[0.1274, 0.1843, 0.2536, 0.2251, 0.2096]])
tensor([1., 1.])
softmax回归模型
o(i)y^(i)=x(i)W+b,=softmax(o(i)).o(i)=x(i)W+b,y^(i)=softmax(o(i)).
In [54]:
def net(X):
return softmax(torch.mm(X.view((-1, num_inputs)), W) + b)
定义损失函数
H(y(i),y^(i))=−∑j=1qy(i)jlogy^(i)j,H(y(i),y^(i))=−∑j=1qyj(i)logy^j(i),
ℓ(Θ)=1n∑i=1nH(y(i),y^(i)),ℓ(Θ)=1n∑i=1nH(y(i),y^(i)),
ℓ(Θ)=−(1/n)∑i=1nlogy^(i)y(i)ℓ(Θ)=−(1/n)∑i=1nlogy^y(i)(i)
In [55]:
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]]) y = torch.LongTensor([0, 2]) y_hat.gather(1, y.view(-1, 1))
Out[55]:
tensor([[0.1000],
[0.5000]])
In [56]:
def cross_entropy(y_hat, y):
return - torch.log(y_hat.gather(1, y.view(-1, 1)))
定义准确率
我们模型训练完了进行模型预测的时候,会用到我们这里定义的准确率。In [57]:
def accuracy(y_hat, y):
return (y_hat.argmax(dim=1) == y).float().mean().item()
In [58]:
print(accuracy(y_hat, y))
0.5
In [59]:
# 本函数已保存在d2lzh_pytorch包中方便以后使用。该函数将被逐步改进:它的完整实现将在“图像增广”一节中描述
def evaluate_accuracy(data_iter, net):
acc_sum, n = 0.0, 0
for X, y in data_iter:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
In [60]:
print(evaluate_accuracy(test_iter, net))
0.1457
训练模型
In [61]:
num_epochs, lr = 5, 0.1
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size,
params=None, lr=None, optimizer=None):
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n = 0.0, 0.0, 0
for X, y in train_iter:
y_hat = net(X)
l = loss(y_hat, y).sum()
# 梯度清零
if optimizer is not None:
optimizer.zero_grad()
elif params is not None and params[0].grad is not None:
for param in params:
param.grad.data.zero_()
l.backward()
if optimizer is None:
d2l.sgd(params, lr, batch_size)
else:
optimizer.step()
train_l_sum += l.item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item()
n += y.shape[0]
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f'
% (epoch + 1, train_l_sum / n, train_acc_sum / n, test_acc))
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, batch_size, [W, b], lr)
epoch 1, loss 0.7870, train acc 0.751, test acc 0.794 epoch 2, loss 0.5702, train acc 0.813, test acc 0.809 epoch 3, loss 0.5254, train acc 0.826, test acc 0.814 epoch 4, loss 0.5009, train acc 0.832, test acc 0.822 epoch 5, loss 0.4853, train acc 0.837, test acc 0.828
模型预测
现在我们的模型训练完了,可以进行一下预测,我们的这个模型训练的到底准确不准确。 现在就可以演示如何对图像进行分类了。给定一系列图像(第三行图像输出),我们比较一下它们的真实标签(第一行文本输出)和模型预测结果(第二行文本输出)。
In [62]:
X, y = iter(test_iter).next() true_labels = d2l.get_fashion_mnist_labels(y.numpy()) pred_labels = d2l.get_fashion_mnist_labels(net(X).argmax(dim=1).numpy()) titles = [true + '\n' + pred for true, pred in zip(true_labels, pred_labels)] d2l.show_fashion_mnist(X[0:9], titles[0:9])
softmax的简洁实现
In [63]:
# 加载各种包或者模块
import torch
from torch import nn
from torch.nn import init
import numpy as np
import sys
sys.path.append("/home/kesci/input")
import d2lzh1981 as d2l
print(torch.__version__)
1.3.0
初始化参数和获取数据
In [64]:
batch_size = 256 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
定义网络模型
In [65]:
num_inputs = 784
num_outputs = 10
class LinearNet(nn.Module):
def __init__(self, num_inputs, num_outputs):
super(LinearNet, self).__init__()
self.linear = nn.Linear(num_inputs, num_outputs)
def forward(self, x): # x 的形状: (batch, 1, 28, 28)
y = self.linear(x.view(x.shape[0], -1))
return y
# net = LinearNet(num_inputs, num_outputs)
class FlattenLayer(nn.Module):
def __init__(self):
super(FlattenLayer, self).__init__()
def forward(self, x): # x 的形状: (batch, *, *, ...)
return x.view(x.shape[0], -1)
from collections import OrderedDict
net = nn.Sequential(
# FlattenLayer(),
# LinearNet(num_inputs, num_outputs)
OrderedDict([
('flatten', FlattenLayer()),
('linear', nn.Linear(num_inputs, num_outputs))]) # 或者写成我们自己定义的 LinearNet(num_inputs, num_outputs) 也可以
)
初始化模型参数
In [66]:
init.normal_(net.linear.weight, mean=0, std=0.01) init.constant_(net.linear.bias, val=0)
Out[66]:
Parameter containing: tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], requires_grad=True)
定义损失函数
In [67]:
loss = nn.CrossEntropyLoss() # 下面是他的函数原型 # class torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
定义优化函数
In [68]:
optimizer = torch.optim.SGD(net.parameters(), lr=0.1) # 下面是函数原型 # class torch.optim.SGD(params, lr=, momentum=0, dampening=0, weight_decay=0, nesterov=False)
训练
In [69]:
num_epochs = 5 d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, None, None, optimizer)
epoch 1, loss 0.0031, train acc 0.749, test acc 0.794 epoch 2, loss 0.0022, train acc 0.814, test acc 0.800 epoch 3, loss 0.0021, train acc 0.826, test acc 0.811 epoch 4, loss 0.0020, train acc 0.833, test acc 0.826 epoch 5, loss 0.0019, train acc 0.837, test acc 0.825
多层感知机
- 多层感知机的基本知识
- 使用多层感知机图像分类的从零开始的实现
- 使用pytorch的简洁实现
多层感知机的基本知识
深度学习主要关注多层模型。在这里,我们将以多层感知机(multilayer perceptron,MLP)为例,介绍多层神经网络的概念。
隐藏层
下图展示了一个多层感知机的神经网络图,它含有一个隐藏层,该层中有5个隐藏单元。

表达公式
具体来说,给定一个小批量样本X∈Rn×dX∈Rn×d,其批量大小为nn,输入个数为dd。假设多层感知机只有一个隐藏层,其中隐藏单元个数为hh。记隐藏层的输出(也称为隐藏层变量或隐藏变量)为HH,有H∈Rn×hH∈Rn×h。因为隐藏层和输出层均是全连接层,可以设隐藏层的权重参数和偏差参数分别为Wh∈Rd×hWh∈Rd×h和 bh∈R1×hbh∈R1×h,输出层的权重和偏差参数分别为Wo∈Rh×qWo∈Rh×q和bo∈R1×qbo∈R1×q。
我们先来看一种含单隐藏层的多层感知机的设计。其输出O∈Rn×qO∈Rn×q的计算为
HO=XWh+bh,=HWo+bo,H=XWh+bh,O=HWo+bo,
也就是将隐藏层的输出直接作为输出层的输入。如果将以上两个式子联立起来,可以得到
O=(XWh+bh)Wo+bo=XWhWo+bhWo+bo.O=(XWh+bh)Wo+bo=XWhWo+bhWo+bo.
从联立后的式子可以看出,虽然神经网络引入了隐藏层,却依然等价于一个单层神经网络:其中输出层权重参数为WhWoWhWo,偏差参数为bhWo+bobhWo+bo。不难发现,即便再添加更多的隐藏层,以上设计依然只能与仅含输出层的单层神经网络等价。
激活函数
上述问题的根源在于全连接层只是对数据做仿射变换(affine transformation),而多个仿射变换的叠加仍然是一个仿射变换。解决问题的一个方法是引入非线性变换,例如对隐藏变量使用按元素运算的非线性函数进行变换,然后再作为下一个全连接层的输入。这个非线性函数被称为激活函数(activation function)。
下面我们介绍几个常用的激活函数:
ReLU函数
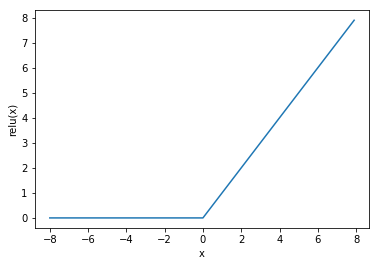
ReLU(rectified linear unit)函数提供了一个很简单的非线性变换。给定元素xx,该函数定义为
ReLU(x)=max(x,0).ReLU(x)=max(x,0).
可以看出,ReLU函数只保留正数元素,并将负数元素清零。为了直观地观察这一非线性变换,我们先定义一个绘图函数xyplot。
In [5]:
%matplotlib inline
import torch
import numpy as np
import matplotlib.pyplot as plt
import sys
sys.path.append("/home/kesci/input")
import d2lzh1981 as d2l
print(torch.__version__)
1.3.0
In [6]:
def xyplot(x_vals, y_vals, name):
# d2l.set_figsize(figsize=(5, 2.5))
plt.plot(x_vals.detach().numpy(), y_vals.detach().numpy())
plt.xlabel('x')
plt.ylabel(name + '(x)')
In [7]:
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True) y = x.relu() xyplot(x, y, 'relu')
In [8]:
y.sum().backward() xyplot(x, x.grad, 'grad of relu')

Sigmoid函数
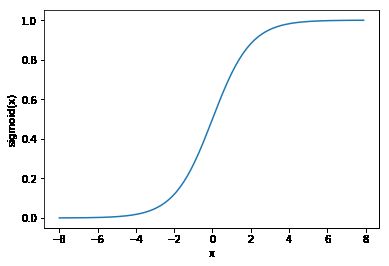
sigmoid函数可以将元素的值变换到0和1之间:
sigmoid(x)=11+exp(−x).sigmoid(x)=11+exp(−x).
In [9]:
y = x.sigmoid() xyplot(x, y, 'sigmoid')
依据链式法则,sigmoid函数的导数
sigmoid′(x)=sigmoid(x)(1−sigmoid(x)).sigmoid′(x)=sigmoid(x)(1−sigmoid(x)).
下面绘制了sigmoid函数的导数。当输入为0时,sigmoid函数的导数达到最大值0.25;当输入越偏离0时,sigmoid函数的导数越接近0。
In [10]:
x.grad.zero_() y.sum().backward() xyplot(x, x.grad, 'grad of sigmoid')

tanh函数
tanh(双曲正切)函数可以将元素的值变换到-1和1之间:
tanh(x)=1−exp(−2x)1+exp(−2x).tanh(x)=1−exp(−2x)1+exp(−2x).
我们接着绘制tanh函数。当输入接近0时,tanh函数接近线性变换。虽然该函数的形状和sigmoid函数的形状很像,但tanh函数在坐标系的原点上对称。
In [11]:
y = x.tanh() xyplot(x, y, 'tanh')

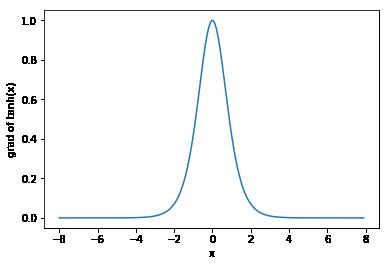
依据链式法则,tanh函数的导数
tanh′(x)=1−tanh2(x).tanh′(x)=1−tanh2(x).
下面绘制了tanh函数的导数。当输入为0时,tanh函数的导数达到最大值1;当输入越偏离0时,tanh函数的导数越接近0。
In [12]:
x.grad.zero_() y.sum().backward() xyplot(x, x.grad, 'grad of tanh')
关于激活函数的选择
ReLu函数是一个通用的激活函数,目前在大多数情况下使用。但是,ReLU函数只能在隐藏层中使用。
用于分类器时,sigmoid函数及其组合通常效果更好。由于梯度消失问题,有时要避免使用sigmoid和tanh函数。
在神经网络层数较多的时候,最好使用ReLu函数,ReLu函数比较简单计算量少,而sigmoid和tanh函数计算量大很多。
在选择激活函数的时候可以先选用ReLu函数如果效果不理想可以尝试其他激活函数。
多层感知机
多层感知机就是含有至少一个隐藏层的由全连接层组成的神经网络,且每个隐藏层的输出通过激活函数进行变换。多层感知机的层数和各隐藏层中隐藏单元个数都是超参数。以单隐藏层为例并沿用本节之前定义的符号,多层感知机按以下方式计算输出:
HO=ϕ(XWh+bh),=HWo+bo,H=ϕ(XWh+bh),O=HWo+bo,
其中ϕϕ表示激活函数。
多层感知机从零开始的实现
In [13]:
import torch
import numpy as np
import sys
sys.path.append("/home/kesci/input")
import d2lzh1981 as d2l
print(torch.__version__)
1.3.0
获取训练集
In [14]:
batch_size = 256 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size,root='/home/kesci/input/FashionMNIST2065')
定义模型参数
In [15]:
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = torch.tensor(np.random.normal(0, 0.01, (num_inputs, num_hiddens)), dtype=torch.float)
b1 = torch.zeros(num_hiddens, dtype=torch.float)
W2 = torch.tensor(np.random.normal(0, 0.01, (num_hiddens, num_outputs)), dtype=torch.float)
b2 = torch.zeros(num_outputs, dtype=torch.float)
params = [W1, b1, W2, b2]
for param in params:
param.requires_grad_(requires_grad=True)
定义激活函数
In [16]:
def relu(X):
return torch.max(input=X, other=torch.tensor(0.0))
定义网络
In [17]:
def net(X):
X = X.view((-1, num_inputs))
H = relu(torch.matmul(X, W1) + b1)
return torch.matmul(H, W2) + b2
定义损失函数
In [18]:
loss = torch.nn.CrossEntropyLoss()
训练
In [19]:
num_epochs, lr = 5, 100.0
# def train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size,
# params=None, lr=None, optimizer=None):
# for epoch in range(num_epochs):
# train_l_sum, train_acc_sum, n = 0.0, 0.0, 0
# for X, y in train_iter:
# y_hat = net(X)
# l = loss(y_hat, y).sum()
#
# # 梯度清零
# if optimizer is not None:
# optimizer.zero_grad()
# elif params is not None and params[0].grad is not None:
# for param in params:
# param.grad.data.zero_()
#
# l.backward()
# if optimizer is None:
# d2l.sgd(params, lr, batch_size)
# else:
# optimizer.step() # “softmax回归的简洁实现”一节将用到
#
#
# train_l_sum += l.item()
# train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item()
# n += y.shape[0]
# test_acc = evaluate_accuracy(test_iter, net)
# print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f'
# % (epoch + 1, train_l_sum / n, train_acc_sum / n, test_acc))
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, params, lr)
epoch 1, loss 0.0030, train acc 0.712, test acc 0.806 epoch 2, loss 0.0019, train acc 0.821, test acc 0.806 epoch 3, loss 0.0017, train acc 0.847, test acc 0.825 epoch 4, loss 0.0015, train acc 0.856, test acc 0.834 epoch 5, loss 0.0015, train acc 0.863, test acc 0.847
多层感知机pytorch实现
In [21]:
import torch
from torch import nn
from torch.nn import init
import numpy as np
import sys
sys.path.append("/home/kesci/input")
import d2lzh1981 as d2l
print(torch.__version__)
1.3.0
初始化模型和各个参数
In [22]:
num_inputs, num_outputs, num_hiddens = 784, 10, 256
net = nn.Sequential(
d2l.FlattenLayer(),
nn.Linear(num_inputs, num_hiddens),
nn.ReLU(),
nn.Linear(num_hiddens, num_outputs),
)
for params in net.parameters():
init.normal_(params, mean=0, std=0.01)
训练
In [23]:
batch_size = 256 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size,root='/home/kesci/input/FashionMNIST2065') loss = torch.nn.CrossEntropyLoss() optimizer = torch.optim.SGD(net.parameters(), lr=0.5) num_epochs = 5 d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, None, None, optimizer)
epoch 1, loss 0.0031, train acc 0.701, test acc 0.774 epoch 2, loss 0.0019, train acc 0.821, test acc 0.806 epoch 3, loss 0.0017, train acc 0.841, test acc 0.805 epoch 4, loss 0.0015, train acc 0.855, test acc 0.834 epoch 5, loss 0.0014, train acc 0.866, test acc 0.840
文本预处理
文本是一类序列数据,一篇文章可以看作是字符或单词的序列,本节将介绍文本数据的常见预处理步骤,预处理通常包括四个步骤:
- 读入文本
- 分词
- 建立字典,将每个词映射到一个唯一的索引(index)
- 将文本从词的序列转换为索引的序列,方便输入模型
读入文本
我们用一部英文小说,即H. G. Well的Time Machine,作为示例,展示文本预处理的具体过程。
In [1]:
import collections
import re
def read_time_machine():
with open('/home/kesci/input/timemachine7163/timemachine.txt', 'r') as f:
lines = [re.sub('[^a-z]+', ' ', line.strip().lower()) for line in f]
return lines
lines = read_time_machine()
print('# sentences %d' % len(lines))
# sentences 3221
分词
我们对每个句子进行分词,也就是将一个句子划分成若干个词(token),转换为一个词的序列。
In [2]:
def tokenize(sentences, token='word'):
"""Split sentences into word or char tokens"""
if token == 'word':
return [sentence.split(' ') for sentence in sentences]
elif token == 'char':
return [list(sentence) for sentence in sentences]
else:
print('ERROR: unkown token type '+token)
tokens = tokenize(lines)
tokens[0:2]
Out[2]:
[['the', 'time', 'machine', 'by', 'h', 'g', 'wells', ''], ['']]
建立字典
为了方便模型处理,我们需要将字符串转换为数字。因此我们需要先构建一个字典(vocabulary),将每个词映射到一个唯一的索引编号。
In [3]:
class Vocab(object):
def __init__(self, tokens, min_freq=0, use_special_tokens=False):
counter = count_corpus(tokens) # :
self.token_freqs = list(counter.items())
self.idx_to_token = []
if use_special_tokens:
# padding, begin of sentence, end of sentence, unknown
self.pad, self.bos, self.eos, self.unk = (0, 1, 2, 3)
self.idx_to_token += ['', '', '', '']
else:
self.unk = 0
self.idx_to_token += ['']
self.idx_to_token += [token for token, freq in self.token_freqs
if freq >= min_freq and token not in self.idx_to_token]
self.token_to_idx = dict()
for idx, token in enumerate(self.idx_to_token):
self.token_to_idx[token] = idx
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
def count_corpus(sentences):
tokens = [tk for st in sentences for tk in st]
return collections.Counter(tokens) # 返回一个字典,记录每个词的出现次数
我们看一个例子,这里我们尝试用Time Machine作为语料构建字典
In [4]:
vocab = Vocab(tokens) print(list(vocab.token_to_idx.items())[0:10])
[('', 0), ('the', 1), ('time', 2), ('machine', 3), ('by', 4), ('h', 5), ('g', 6), ('wells', 7), ('i', 8), ('traveller', 9)]
将词转为索引
使用字典,我们可以将原文本中的句子从单词序列转换为索引序列
In [5]:
for i in range(8, 10):
print('words:', tokens[i])
print('indices:', vocab[tokens[i]])
words: ['the', 'time', 'traveller', 'for', 'so', 'it', 'will', 'be', 'convenient', 'to', 'speak', 'of', 'him', ''] indices: [1, 2, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 0] words: ['was', 'expounding', 'a', 'recondite', 'matter', 'to', 'us', 'his', 'grey', 'eyes', 'shone', 'and'] indices: [20, 21, 22, 23, 24, 16, 25, 26, 27, 28, 29, 30]
用现有工具进行分词
我们前面介绍的分词方式非常简单,它至少有以下几个缺点:
- 标点符号通常可以提供语义信息,但是我们的方法直接将其丢弃了
- 类似“shouldn't", "doesn't"这样的词会被错误地处理
- 类似"Mr.", "Dr."这样的词会被错误地处理
我们可以通过引入更复杂的规则来解决这些问题,但是事实上,有一些现有的工具可以很好地进行分词,我们在这里简单介绍其中的两个:spaCy和NLTK。
下面是一个简单的例子:
In [6]:
text = "Mr. Chen doesn't agree with my suggestion."
spaCy:
In [7]:
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp(text)
print([token.text for token in doc])
['Mr.', 'Chen', 'does', "n't", 'agree', 'with', 'my', 'suggestion', '.']
NLTK:
In [8]:
from nltk.tokenize import word_tokenize
from nltk import data
data.path.append('/home/kesci/input/nltk_data3784/nltk_data')
print(word_tokenize(text))
['Mr.', 'Chen', 'does', "n't", 'agree', 'with', 'my', 'suggestion', '.']
语言模型
一段自然语言文本可以看作是一个离散时间序列,给定一个长度为TT的词的序列w1,w2,…,wTw1,w2,…,wT,语言模型的目标就是评估该序列是否合理,即计算该序列的概率:
P(w1,w2,…,wT).P(w1,w2,…,wT).
本节我们介绍基于统计的语言模型,主要是nn元语法(nn-gram)。在后续内容中,我们将会介绍基于神经网络的语言模型。
语言模型
假设序列w1,w2,…,wTw1,w2,…,wT中的每个词是依次生成的,我们有
P(w1,w2,…,wT)=∏t=1TP(wt∣w1,…,wt−1)=P(w1)P(w2∣w1)⋯P(wT∣w1w2⋯wT−1)P(w1,w2,…,wT)=∏t=1TP(wt∣w1,…,wt−1)=P(w1)P(w2∣w1)⋯P(wT∣w1w2⋯wT−1)
例如,一段含有4个词的文本序列的概率
P(w1,w2,w3,w4)=P(w1)P(w2∣w1)P(w3∣w1,w2)P(w4∣w1,w2,w3).P(w1,w2,w3,w4)=P(w1)P(w2∣w1)P(w3∣w1,w2)P(w4∣w1,w2,w3).
语言模型的参数就是词的概率以及给定前几个词情况下的条件概率。设训练数据集为一个大型文本语料库,如维基百科的所有条目,词的概率可以通过该词在训练数据集中的相对词频来计算,例如,w1w1的概率可以计算为:
P^(w1)=n(w1)nP^(w1)=n(w1)n
其中n(w1)n(w1)为语料库中以w1w1作为第一个词的文本的数量,nn为语料库中文本的总数量。
类似的,给定w1w1情况下,w2w2的条件概率可以计算为:
P^(w2∣w1)=n(w1,w2)n(w1)P^(w2∣w1)=n(w1,w2)n(w1)
其中n(w1,w2)n(w1,w2)为语料库中以w1w1作为第一个词,w2w2作为第二个词的文本的数量。
n元语法
序列长度增加,计算和存储多个词共同出现的概率的复杂度会呈指数级增加。nn元语法通过马尔可夫假设简化模型,马尔科夫假设是指一个词的出现只与前面nn个词相关,即nn阶马尔可夫链(Markov chain of order nn),如果n=1n=1,那么有P(w3∣w1,w2)=P(w3∣w2)P(w3∣w1,w2)=P(w3∣w2)。基于n−1n−1阶马尔可夫链,我们可以将语言模型改写为
P(w1,w2,…,wT)=∏t=1TP(wt∣wt−(n−1),…,wt−1).P(w1,w2,…,wT)=∏t=1TP(wt∣wt−(n−1),…,wt−1).
以上也叫nn元语法(nn-grams),它是基于n−1n−1阶马尔可夫链的概率语言模型。例如,当n=2n=2时,含有4个词的文本序列的概率就可以改写为:
P(w1,w2,w3,w4)=P(w1)P(w2∣w1)P(w3∣w1,w2)P(w4∣w1,w2,w3)=P(w1)P(w2∣w1)P(w3∣w2)P(w4∣w3)P(w1,w2,w3,w4)=P(w1)P(w2∣w1)P(w3∣w1,w2)P(w4∣w1,w2,w3)=P(w1)P(w2∣w1)P(w3∣w2)P(w4∣w3)
当nn分别为1、2和3时,我们将其分别称作一元语法(unigram)、二元语法(bigram)和三元语法(trigram)。例如,长度为4的序列w1,w2,w3,w4w1,w2,w3,w4在一元语法、二元语法和三元语法中的概率分别为
P(w1,w2,w3,w4)P(w1,w2,w3,w4)P(w1,w2,w3,w4)=P(w1)P(w2)P(w3)P(w4),=P(w1)P(w2∣w1)P(w3∣w2)P(w4∣w3),=P(w1)P(w2∣w1)P(w3∣w1,w2)P(w4∣w2,w3).P(w1,w2,w3,w4)=P(w1)P(w2)P(w3)P(w4),P(w1,w2,w3,w4)=P(w1)P(w2∣w1)P(w3∣w2)P(w4∣w3),P(w1,w2,w3,w4)=P(w1)P(w2∣w1)P(w3∣w1,w2)P(w4∣w2,w3).
当nn较小时,nn元语法往往并不准确。例如,在一元语法中,由三个词组成的句子“你走先”和“你先走”的概率是一样的。然而,当nn较大时,nn元语法需要计算并存储大量的词频和多词相邻频率。
思考:nn元语法可能有哪些缺陷?
- 参数空间过大
- 数据稀疏
语言模型数据集
读取数据集
In [1]:
with open('/home/kesci/input/jaychou_lyrics4703/jaychou_lyrics.txt') as f:
corpus_chars = f.read()
print(len(corpus_chars))
print(corpus_chars[: 40])
corpus_chars = corpus_chars.replace('\n', ' ').replace('\r', ' ')
corpus_chars = corpus_chars[: 10000]
63282 想要有直升机 想要和你飞到宇宙去 想要和你融化在一起 融化在宇宙里 我每天每天每
建立字符索引
In [2]:
idx_to_char = list(set(corpus_chars)) # 去重,得到索引到字符的映射
char_to_idx = {char: i for i, char in enumerate(idx_to_char)} # 字符到索引的映射
vocab_size = len(char_to_idx)
print(vocab_size)
corpus_indices = [char_to_idx[char] for char in corpus_chars] # 将每个字符转化为索引,得到一个索引的序列
sample = corpus_indices[: 20]
print('chars:', ''.join([idx_to_char[idx] for idx in sample]))
print('indices:', sample)
1027 chars: 想要有直升机 想要和你飞到宇宙去 想要和 indices: [1022, 648, 1025, 366, 208, 792, 199, 1022, 648, 641, 607, 625, 26, 155, 130, 5, 199, 1022, 648, 641]
定义函数load_data_jay_lyrics,在后续章节中直接调用。
In [3]:
def load_data_jay_lyrics():
with open('/home/kesci/input/jaychou_lyrics4703/jaychou_lyrics.txt') as f:
corpus_chars = f.read()
corpus_chars = corpus_chars.replace('\n', ' ').replace('\r', ' ')
corpus_chars = corpus_chars[0:10000]
idx_to_char = list(set(corpus_chars))
char_to_idx = dict([(char, i) for i, char in enumerate(idx_to_char)])
vocab_size = len(char_to_idx)
corpus_indices = [char_to_idx[char] for char in corpus_chars]
return corpus_indices, char_to_idx, idx_to_char, vocab_size
时序数据的采样
在训练中我们需要每次随机读取小批量样本和标签。与之前章节的实验数据不同的是,时序数据的一个样本通常包含连续的字符。假设时间步数为5,样本序列为5个字符,即“想”“要”“有”“直”“升”。该样本的标签序列为这些字符分别在训练集中的下一个字符,即“要”“有”“直”“升”“机”,即XX=“想要有直升”,YY=“要有直升机”。
现在我们考虑序列“想要有直升机,想要和你飞到宇宙去”,如果时间步数为5,有以下可能的样本和标签:
- XX:“想要有直升”,YY:“要有直升机”
- XX:“要有直升机”,YY:“有直升机,”
- XX:“有直升机,”,YY:“直升机,想”
- ...
- XX:“要和你飞到”,YY:“和你飞到宇”
- XX:“和你飞到宇”,YY:“你飞到宇宙”
- XX:“你飞到宇宙”,YY:“飞到宇宙去”
可以看到,如果序列的长度为TT,时间步数为nn,那么一共有T−nT−n个合法的样本,但是这些样本有大量的重合,我们通常采用更加高效的采样方式。我们有两种方式对时序数据进行采样,分别是随机采样和相邻采样。
随机采样
下面的代码每次从数据里随机采样一个小批量。其中批量大小batch_size是每个小批量的样本数,num_steps是每个样本所包含的时间步数。 在随机采样中,每个样本是原始序列上任意截取的一段序列,相邻的两个随机小批量在原始序列上的位置不一定相毗邻。
In [4]:
import torch
import random
def data_iter_random(corpus_indices, batch_size, num_steps, device=None):
# 减1是因为对于长度为n的序列,X最多只有包含其中的前n - 1个字符
num_examples = (len(corpus_indices) - 1) // num_steps # 下取整,得到不重叠情况下的样本个数
example_indices = [i * num_steps for i in range(num_examples)] # 每个样本的第一个字符在corpus_indices中的下标
random.shuffle(example_indices)
def _data(i):
# 返回从i开始的长为num_steps的序列
return corpus_indices[i: i + num_steps]
if device is None:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
for i in range(0, num_examples, batch_size):
# 每次选出batch_size个随机样本
batch_indices = example_indices[i: i + batch_size] # 当前batch的各个样本的首字符的下标
X = [_data(j) for j in batch_indices]
Y = [_data(j + 1) for j in batch_indices]
yield torch.tensor(X, device=device), torch.tensor(Y, device=device)
测试一下这个函数,我们输入从0到29的连续整数作为一个人工序列,设批量大小和时间步数分别为2和6,打印随机采样每次读取的小批量样本的输入X和标签Y。
In [5]:
my_seq = list(range(30))
for X, Y in data_iter_random(my_seq, batch_size=2, num_steps=6):
print('X: ', X, '\nY:', Y, '\n')
X: tensor([[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17]])
Y: tensor([[ 7, 8, 9, 10, 11, 12],
[13, 14, 15, 16, 17, 18]])
X: tensor([[ 0, 1, 2, 3, 4, 5],
[18, 19, 20, 21, 22, 23]])
Y: tensor([[ 1, 2, 3, 4, 5, 6],
[19, 20, 21, 22, 23, 24]])
相邻采样
在相邻采样中,相邻的两个随机小批量在原始序列上的位置相毗邻。
In [6]:
def data_iter_consecutive(corpus_indices, batch_size, num_steps, device=None):
if device is None:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
corpus_len = len(corpus_indices) // batch_size * batch_size # 保留下来的序列的长度
corpus_indices = corpus_indices[: corpus_len] # 仅保留前corpus_len个字符
indices = torch.tensor(corpus_indices, device=device)
indices = indices.view(batch_size, -1) # resize成(batch_size, )
batch_num = (indices.shape[1] - 1) // num_steps
for i in range(batch_num):
i = i * num_steps
X = indices[:, i: i + num_steps]
Y = indices[:, i + 1: i + num_steps + 1]
yield X, Y
同样的设置下,打印相邻采样每次读取的小批量样本的输入X和标签Y。相邻的两个随机小批量在原始序列上的位置相毗邻。
In [7]:
for X, Y in data_iter_consecutive(my_seq, batch_size=2, num_steps=6):
print('X: ', X, '\nY:', Y, '\n')
X: tensor([[ 0, 1, 2, 3, 4, 5],
[15, 16, 17, 18, 19, 20]])
Y: tensor([[ 1, 2, 3, 4, 5, 6],
[16, 17, 18, 19, 20, 21]])
X: tensor([[ 6, 7, 8, 9, 10, 11],
[21, 22, 23, 24, 25, 26]])
Y: tensor([[ 7, 8, 9, 10, 11, 12],
[22, 23, 24, 25, 26, 27]])
循环神经网络
本节介绍循环神经网络,下图展示了如何基于循环神经网络实现语言模型。我们的目的是基于当前的输入与过去的输入序列,预测序列的下一个字符。循环神经网络引入一个隐藏变量HH,用HtHt表示HH在时间步tt的值。HtHt的计算基于XtXt和Ht−1Ht−1,可以认为HtHt记录了到当前字符为止的序列信息,利用HtHt对序列的下一个字符进行预测。
循环神经网络的构造
我们先看循环神经网络的具体构造。假设Xt∈Rn×dXt∈Rn×d是时间步tt的小批量输入,Ht∈Rn×hHt∈Rn×h是该时间步的隐藏变量,则:
Ht=ϕ(XtWxh+Ht−1Whh+bh).Ht=ϕ(XtWxh+Ht−1Whh+bh).
其中,Wxh∈Rd×hWxh∈Rd×h,Whh∈Rh×hWhh∈Rh×h,bh∈R1×hbh∈R1×h,ϕϕ函数是非线性激活函数。由于引入了Ht−1WhhHt−1Whh,HtHt能够捕捉截至当前时间步的序列的历史信息,就像是神经网络当前时间步的状态或记忆一样。由于HtHt的计算基于Ht−1Ht−1,上式的计算是循环的,使用循环计算的网络即循环神经网络(recurrent neural network)。
在时间步tt,输出层的输出为:
Ot=HtWhq+bq.Ot=HtWhq+bq.
其中Whq∈Rh×qWhq∈Rh×q,bq∈R1×qbq∈R1×q。
从零开始实现循环神经网络
我们先尝试从零开始实现一个基于字符级循环神经网络的语言模型,这里我们使用周杰伦的歌词作为语料,首先我们读入数据:
In [1]:
import torch
import torch.nn as nn
import time
import math
import sys
sys.path.append("/home/kesci/input")
import d2l_jay9460 as d2l
(corpus_indices, char_to_idx, idx_to_char, vocab_size) = d2l.load_data_jay_lyrics()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
one-hot向量
我们需要将字符表示成向量,这里采用one-hot向量。假设词典大小是NN,每次字符对应一个从00到N−1N−1的唯一的索引,则该字符的向量是一个长度为NN的向量,若字符的索引是ii,则该向量的第ii个位置为11,其他位置为00。下面分别展示了索引为0和2的one-hot向量,向量长度等于词典大小。
In [2]:
def one_hot(x, n_class, dtype=torch.float32):
result = torch.zeros(x.shape[0], n_class, dtype=dtype, device=x.device) # shape: (n, n_class)
result.scatter_(1, x.long().view(-1, 1), 1) # result[i, x[i, 0]] = 1
return result
x = torch.tensor([0, 2])
x_one_hot = one_hot(x, vocab_size)
print(x_one_hot)
print(x_one_hot.shape)
print(x_one_hot.sum(axis=1))
tensor([[1., 0., 0., ..., 0., 0., 0.],
[0., 0., 1., ..., 0., 0., 0.]])
torch.Size([2, 1027])
tensor([1., 1.])
我们每次采样的小批量的形状是(批量大小, 时间步数)。下面的函数将这样的小批量变换成数个形状为(批量大小, 词典大小)的矩阵,矩阵个数等于时间步数。也就是说,时间步tt的输入为Xt∈Rn×dXt∈Rn×d,其中nn为批量大小,dd为词向量大小,即one-hot向量长度(词典大小)。
In [3]:
def to_onehot(X, n_class):
return [one_hot(X[:, i], n_class) for i in range(X.shape[1])]
X = torch.arange(10).view(2, 5)
inputs = to_onehot(X, vocab_size)
print(len(inputs), inputs[0].shape)
5 torch.Size([2, 1027])
初始化模型参数
In [4]:
num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size
# num_inputs: d
# num_hiddens: h, 隐藏单元的个数是超参数
# num_outputs: q
def get_params():
def _one(shape):
param = torch.zeros(shape, device=device, dtype=torch.float32)
nn.init.normal_(param, 0, 0.01)
return torch.nn.Parameter(param)
# 隐藏层参数
W_xh = _one((num_inputs, num_hiddens))
W_hh = _one((num_hiddens, num_hiddens))
b_h = torch.nn.Parameter(torch.zeros(num_hiddens, device=device))
# 输出层参数
W_hq = _one((num_hiddens, num_outputs))
b_q = torch.nn.Parameter(torch.zeros(num_outputs, device=device))
return (W_xh, W_hh, b_h, W_hq, b_q)
定义模型
函数rnn用循环的方式依次完成循环神经网络每个时间步的计算。
In [5]:
def rnn(inputs, state, params):
# inputs和outputs皆为num_steps个形状为(batch_size, vocab_size)的矩阵
W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
H = torch.tanh(torch.matmul(X, W_xh) + torch.matmul(H, W_hh) + b_h)
Y = torch.matmul(H, W_hq) + b_q
outputs.append(Y)
return outputs, (H,)
函数init_rnn_state初始化隐藏变量,这里的返回值是一个元组。
In [6]:
def init_rnn_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), )
做个简单的测试来观察输出结果的个数(时间步数),以及第一个时间步的输出层输出的形状和隐藏状态的形状。
In [7]:
print(X.shape) print(num_hiddens) print(vocab_size) state = init_rnn_state(X.shape[0], num_hiddens, device) inputs = to_onehot(X.to(device), vocab_size) params = get_params() outputs, state_new = rnn(inputs, state, params) print(len(inputs), inputs[0].shape) print(len(outputs), outputs[0].shape) print(len(state), state[0].shape) print(len(state_new), state_new[0].shape)
torch.Size([2, 5]) 256 1027 5 torch.Size([2, 1027]) 5 torch.Size([2, 1027]) 1 torch.Size([2, 256]) 1 torch.Size([2, 256])
裁剪梯度
循环神经网络中较容易出现梯度衰减或梯度爆炸,这会导致网络几乎无法训练。裁剪梯度(clip gradient)是一种应对梯度爆炸的方法。假设我们把所有模型参数的梯度拼接成一个向量 gg,并设裁剪的阈值是θθ。裁剪后的梯度
min(θ∥g∥,1)gmin(θ‖g‖,1)g
的L2L2范数不超过θθ。
In [8]:
def grad_clipping(params, theta, device):
norm = torch.tensor([0.0], device=device)
for param in params:
norm += (param.grad.data ** 2).sum()
norm = norm.sqrt().item()
if norm > theta:
for param in params:
param.grad.data *= (theta / norm)
定义预测函数
以下函数基于前缀prefix(含有数个字符的字符串)来预测接下来的num_chars个字符。这个函数稍显复杂,其中我们将循环神经单元rnn设置成了函数参数,这样在后面小节介绍其他循环神经网络时能重复使用这个函数。
In [9]:
def predict_rnn(prefix, num_chars, rnn, params, init_rnn_state,
num_hiddens, vocab_size, device, idx_to_char, char_to_idx):
state = init_rnn_state(1, num_hiddens, device)
output = [char_to_idx[prefix[0]]] # output记录prefix加上预测的num_chars个字符
for t in range(num_chars + len(prefix) - 1):
# 将上一时间步的输出作为当前时间步的输入
X = to_onehot(torch.tensor([[output[-1]]], device=device), vocab_size)
# 计算输出和更新隐藏状态
(Y, state) = rnn(X, state, params)
# 下一个时间步的输入是prefix里的字符或者当前的最佳预测字符
if t < len(prefix) - 1:
output.append(char_to_idx[prefix[t + 1]])
else:
output.append(Y[0].argmax(dim=1).item())
return ''.join([idx_to_char[i] for i in output])
我们先测试一下predict_rnn函数。我们将根据前缀“分开”创作长度为10个字符(不考虑前缀长度)的一段歌词。因为模型参数为随机值,所以预测结果也是随机的。
In [10]:
predict_rnn('分开', 10, rnn, params, init_rnn_state, num_hiddens, vocab_size,
device, idx_to_char, char_to_idx)
Out[10]:
'分开濡时食提危踢拆田唱母'
困惑度
我们通常使用困惑度(perplexity)来评价语言模型的好坏。回忆一下“softmax回归”一节中交叉熵损失函数的定义。困惑度是对交叉熵损失函数做指数运算后得到的值。特别地,
- 最佳情况下,模型总是把标签类别的概率预测为1,此时困惑度为1;
- 最坏情况下,模型总是把标签类别的概率预测为0,此时困惑度为正无穷;
- 基线情况下,模型总是预测所有类别的概率都相同,此时困惑度为类别个数。
显然,任何一个有效模型的困惑度必须小于类别个数。在本例中,困惑度必须小于词典大小vocab_size。
定义模型训练函数
跟之前章节的模型训练函数相比,这里的模型训练函数有以下几点不同:
- 使用困惑度评价模型。
- 在迭代模型参数前裁剪梯度。
- 对时序数据采用不同采样方法将导致隐藏状态初始化的不同。
In [11]:
def train_and_predict_rnn(rnn, get_params, init_rnn_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, is_random_iter, num_epochs, num_steps,
lr, clipping_theta, batch_size, pred_period,
pred_len, prefixes):
if is_random_iter:
data_iter_fn = d2l.data_iter_random
else:
data_iter_fn = d2l.data_iter_consecutive
params = get_params()
loss = nn.CrossEntropyLoss()
for epoch in range(num_epochs):
if not is_random_iter: # 如使用相邻采样,在epoch开始时初始化隐藏状态
state = init_rnn_state(batch_size, num_hiddens, device)
l_sum, n, start = 0.0, 0, time.time()
data_iter = data_iter_fn(corpus_indices, batch_size, num_steps, device)
for X, Y in data_iter:
if is_random_iter: # 如使用随机采样,在每个小批量更新前初始化隐藏状态
state = init_rnn_state(batch_size, num_hiddens, device)
else: # 否则需要使用detach函数从计算图分离隐藏状态
for s in state:
s.detach_()
# inputs是num_steps个形状为(batch_size, vocab_size)的矩阵
inputs = to_onehot(X, vocab_size)
# outputs有num_steps个形状为(batch_size, vocab_size)的矩阵
(outputs, state) = rnn(inputs, state, params)
# 拼接之后形状为(num_steps * batch_size, vocab_size)
outputs = torch.cat(outputs, dim=0)
# Y的形状是(batch_size, num_steps),转置后再变成形状为
# (num_steps * batch_size,)的向量,这样跟输出的行一一对应
y = torch.flatten(Y.T)
# 使用交叉熵损失计算平均分类误差
l = loss(outputs, y.long())
# 梯度清0
if params[0].grad is not None:
for param in params:
param.grad.data.zero_()
l.backward()
grad_clipping(params, clipping_theta, device) # 裁剪梯度
d2l.sgd(params, lr, 1) # 因为误差已经取过均值,梯度不用再做平均
l_sum += l.item() * y.shape[0]
n += y.shape[0]
if (epoch + 1) % pred_period == 0:
print('epoch %d, perplexity %f, time %.2f sec' % (
epoch + 1, math.exp(l_sum / n), time.time() - start))
for prefix in prefixes:
print(' -', predict_rnn(prefix, pred_len, rnn, params, init_rnn_state,
num_hiddens, vocab_size, device, idx_to_char, char_to_idx))
训练模型并创作歌词
现在我们可以训练模型了。首先,设置模型超参数。我们将根据前缀“分开”和“不分开”分别创作长度为50个字符(不考虑前缀长度)的一段歌词。我们每过50个迭代周期便根据当前训练的模型创作一段歌词。
In [12]:
num_epochs, num_steps, batch_size, lr, clipping_theta = 250, 35, 32, 1e2, 1e-2 pred_period, pred_len, prefixes = 50, 50, ['分开', '不分开']
下面采用随机采样训练模型并创作歌词。
In [13]:
train_and_predict_rnn(rnn, get_params, init_rnn_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, True, num_epochs, num_steps, lr,
clipping_theta, batch_size, pred_period, pred_len,
prefixes)
epoch 50, perplexity 65.808092, time 0.78 sec - 分开 我想要这样 我不要再想 我不要再想 我不要再想 我不要再想 我不要再想 我不要再想 我不要再想 我 - 不分开 别颗去 一颗两 三颗四 一颗四 三颗四 一颗四 一颗四 一颗四 一颗四 一颗四 一颗四 一颗四 一 epoch 100, perplexity 9.794889, time 0.72 sec - 分开 一直在美留 谁在它停 在小村外的溪边 默默等 什么 旧你在依旧 我有儿有些瘦 世色我遇见你是一场 - 不分开吗 我不能再想 我不 我不 我不 我不 我不 我不 我不 我不 我不 我不 我不 我不 我不 我不 epoch 150, perplexity 2.772557, time 0.80 sec - 分开 有直在不妥 有话它停留 蜥蝪横怕落 不爽就 旧怪堂 是属于依 心故之 的片段 有一些风霜 老唱盘 - 不分开吗 然后将过不 我慢 失些 如 静里回的太快 想通 却又再考倒我 说散 你想很久了吧?的我 从等 epoch 200, perplexity 1.601744, time 0.73 sec - 分开 那只都它满在我面妈 捏成你的形状啸而过 或愿说在后能 让梭时忆对着轻轻 我想就这样牵着你的手不放开 - 不分开期 然后将过去 慢慢温习 让我爱上你 那场悲剧 是你完美演出的一场戏 宁愿心碎哭泣 再狠狠忘记 不是 epoch 250, perplexity 1.323342, time 0.78 sec - 分开 出愿段的哭咒的天蛦丘好落 拜托当血穿永杨一定的诗篇 我给你的爱写在西元前 深埋在美索不达米亚平原 - 不分开扫把的胖女巫 用拉丁文念咒语啦啦呜 她养的黑猫笑起来像哭 啦啦啦呜 我来了我 在我感外的溪边河口默默
接下来采用相邻采样训练模型并创作歌词。
In [14]:
train_and_predict_rnn(rnn, get_params, init_rnn_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, False, num_epochs, num_steps, lr,
clipping_theta, batch_size, pred_period, pred_len,
prefixes)
epoch 50, perplexity 60.294393, time 0.74 sec - 分开 我想要你想 我不要再想 我不要再想 我不要再想 我不要再想 我不要再想 我不要再想 我不要再想 我 - 不分开 我想要你 你有了 别不我的可爱女人 坏坏的让我疯狂的可爱女人 坏坏的让我疯狂的可爱女人 坏坏的让我 epoch 100, perplexity 7.141162, time 0.72 sec - 分开 我已要再爱 我不要再想 我不 我不 我不要再想 我不 我不 我不要 爱情我的见快就像龙卷风 离能开 - 不分开柳 你天黄一个棍 后知哈兮 快使用双截棍 哼哼哈兮 快使用双截棍 哼哼哈兮 快使用双截棍 哼哼哈兮 epoch 150, perplexity 2.090277, time 0.73 sec - 分开 我已要这是你在著 不想我都做得到 但那个人已经不是我 没有你在 我却多难熬 没有你在我有多难熬多 - 不分开觉 你已经离 我想再好 这样心中 我一定带我 我的完空 不你是风 一一彩纵 在人心中 我一定带我妈走 epoch 200, perplexity 1.305391, time 0.77 sec - 分开 我已要这样牵看你的手 它一定实现它一定像现 载著你 彷彿载著阳光 不管到你留都是晴天 蝴蝶自在飞力 - 不分开觉 你已经离开我 不知不觉 我跟了这节奏 后知后觉 又过了一个秋 后知后觉 我该好好生活 我该好好生 epoch 250, perplexity 1.230800, time 0.79 sec - 分开 我不要 是你看的太快了悲慢 担心今手身会大早 其么我也睡不着 昨晚梦里你来找 我才 原来我只想 - 不分开觉 你在经离开我 不知不觉 你知了有节奏 后知后觉 后知了一个秋 后知后觉 我该好好生活 我该好好生
循环神经网络的简介实现
定义模型
我们使用Pytorch中的nn.RNN来构造循环神经网络。在本节中,我们主要关注nn.RNN的以下几个构造函数参数:
input_size- The number of expected features in the input xhidden_size– The number of features in the hidden state hnonlinearity– The non-linearity to use. Can be either 'tanh' or 'relu'. Default: 'tanh'batch_first– If True, then the input and output tensors are provided as (batch_size, num_steps, input_size). Default: False
这里的batch_first决定了输入的形状,我们使用默认的参数False,对应的输入形状是 (num_steps, batch_size, input_size)。
forward函数的参数为:
inputof shape (num_steps, batch_size, input_size): tensor containing the features of the input sequence.h_0of shape (num_layers * num_directions, batch_size, hidden_size): tensor containing the initial hidden state for each element in the batch. Defaults to zero if not provided. If the RNN is bidirectional, num_directions should be 2, else it should be 1.
forward函数的返回值是:
outputof shape (num_steps, batch_size, num_directions * hidden_size): tensor containing the output features (h_t) from the last layer of the RNN, for each t.h_nof shape (num_layers * num_directions, batch_size, hidden_size): tensor containing the hidden state for t = num_steps.
现在我们构造一个nn.RNN实例,并用一个简单的例子来看一下输出的形状。
In [15]:
rnn_layer = nn.RNN(input_size=vocab_size, hidden_size=num_hiddens) num_steps, batch_size = 35, 2 X = torch.rand(num_steps, batch_size, vocab_size) state = None Y, state_new = rnn_layer(X, state) print(Y.shape, state_new.shape)
torch.Size([35, 2, 256]) torch.Size([1, 2, 256])
我们定义一个完整的基于循环神经网络的语言模型。
In [16]:
class RNNModel(nn.Module):
def __init__(self, rnn_layer, vocab_size):
super(RNNModel, self).__init__()
self.rnn = rnn_layer
self.hidden_size = rnn_layer.hidden_size * (2 if rnn_layer.bidirectional else 1)
self.vocab_size = vocab_size
self.dense = nn.Linear(self.hidden_size, vocab_size)
def forward(self, inputs, state):
# inputs.shape: (batch_size, num_steps)
X = to_onehot(inputs, vocab_size)
X = torch.stack(X) # X.shape: (num_steps, batch_size, vocab_size)
hiddens, state = self.rnn(X, state)
hiddens = hiddens.view(-1, hiddens.shape[-1]) # hiddens.shape: (num_steps * batch_size, hidden_size)
output = self.dense(hiddens)
return output, state
类似的,我们需要实现一个预测函数,与前面的区别在于前向计算和初始化隐藏状态。
In [17]:
def predict_rnn_pytorch(prefix, num_chars, model, vocab_size, device, idx_to_char,
char_to_idx):
state = None
output = [char_to_idx[prefix[0]]] # output记录prefix加上预测的num_chars个字符
for t in range(num_chars + len(prefix) - 1):
X = torch.tensor([output[-1]], device=device).view(1, 1)
(Y, state) = model(X, state) # 前向计算不需要传入模型参数
if t < len(prefix) - 1:
output.append(char_to_idx[prefix[t + 1]])
else:
output.append(Y.argmax(dim=1).item())
return ''.join([idx_to_char[i] for i in output])
使用权重为随机值的模型来预测一次。
In [18]:
model = RNNModel(rnn_layer, vocab_size).to(device)
predict_rnn_pytorch('分开', 10, model, vocab_size, device, idx_to_char, char_to_idx)
Out[18]:
'分开胸呵以轮轮轮轮轮轮轮'
接下来实现训练函数,这里只使用了相邻采样。
In [19]:
def train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes):
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
model.to(device)
for epoch in range(num_epochs):
l_sum, n, start = 0.0, 0, time.time()
data_iter = d2l.data_iter_consecutive(corpus_indices, batch_size, num_steps, device) # 相邻采样
state = None
for X, Y in data_iter:
if state is not None:
# 使用detach函数从计算图分离隐藏状态
if isinstance (state, tuple): # LSTM, state:(h, c)
state[0].detach_()
state[1].detach_()
else:
state.detach_()
(output, state) = model(X, state) # output.shape: (num_steps * batch_size, vocab_size)
y = torch.flatten(Y.T)
l = loss(output, y.long())
optimizer.zero_grad()
l.backward()
grad_clipping(model.parameters(), clipping_theta, device)
optimizer.step()
l_sum += l.item() * y.shape[0]
n += y.shape[0]
if (epoch + 1) % pred_period == 0:
print('epoch %d, perplexity %f, time %.2f sec' % (
epoch + 1, math.exp(l_sum / n), time.time() - start))
for prefix in prefixes:
print(' -', predict_rnn_pytorch(
prefix, pred_len, model, vocab_size, device, idx_to_char,
char_to_idx))
训练模型。
In [20]:
num_epochs, batch_size, lr, clipping_theta = 250, 32, 1e-3, 1e-2
pred_period, pred_len, prefixes = 50, 50, ['分开', '不分开']
train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
epoch 50, perplexity 9.405654, time 0.52 sec - 分开始一起 三步四步望著天 看星星 一颗两颗三颗四颗 连成线背著背默默许下心愿 一枝杨柳 你的那我 在 - 不分开 爱情你的手 一人的老斑鸠 腿短毛不多 快使用双截棍 哼哼哈兮 快使用双截棍 哼哼哈兮 快使用双截棍 epoch 100, perplexity 1.255020, time 0.54 sec - 分开 我人了的屋我 一定令它心仪的母斑鸠 爱像一阵风 吹完美主 这样 还人的太快就是学怕眼口让我碰恨这 - 不分开不想我多的脑袋有问题 随便说说 其实我早已经猜透看透不想多说 只是我怕眼泪撑不住 不懂 你的黑色幽默 epoch 150, perplexity 1.064527, time 0.53 sec - 分开 我轻外的溪边 默默在一心抽离 有话不知不觉 一场悲剧 我对不起 藤蔓植物的爬满了伯爵的坟墓 古堡里 - 不分开不想不多的脑 有教堂有你笑 我有多烦恼 没有你烦 有有样 别怪走 快后悔没说你 我不多难熬 我想就 epoch 200, perplexity 1.033074, time 0.53 sec - 分开 我轻外的溪边 默默在一心向昏 的愿 古无着我只能 一个黑远 这想太久 这样我 不要再是你打我妈妈 - 不分开你只会我一起睡著 样 娘子却只想你和汉堡 我想要你的微笑每天都能看到 我知道这里很美但家乡的你更美 epoch 250, perplexity 1.047890, time 0.68 sec - 分开 我轻多的漫 却已在你人演 想要再直你 我想要这样牵着你的手不放开 爱可不可以简简单单没有伤害 你 - 不分开不想不多的假 已无能为力再提起 决定中断熟悉 然后在这里 不限日期 然后将过去 慢慢温习 让我爱上