《A Deep Generative Framework for Paraphrase Generation》论文笔记--相关工作、实验
一、相关工作:
(Quirk,Brockett,and Dolan 2004) apply SMT tools, trained on large volumes of sentence pairs from news articles. (Zhao et al. 2008) proposed a model that uses multiple resources to improve SMT based paraphrasing, paraphrase table and feature function which are then combined in a log-linear SMT model. Some old methods use data-driven methods and hard coded rules such as (Madnani and Dorr 2010), (McKeown 1983b). (Hassan et al. 2007) proposes a system for lexical substitution using thesaurus methods. (Kozlowski,McCoy,andVijay-Shanker 2003) pairs elementary semantic structures with their syntactic realization and generate paraphrases from predicate/argument structure. As mentioned in (Prakash et al. 2016), the application of deep learning models to paraphrase generation has not been explored rigorously yet. This is one of the first major works that used deep architecture for paraphrase generation and introduce the residual recurrent neural networks.
1. 2004年,应用SMT工具,对新闻文章中的大量句子对进行了训练。
2. 2008年,提出了一个模型,该模型使用多种资源来基于释义、释义表和特征函数改进SMT,然后将它们组合成对数线性SMT模型。
3. 2010年,使用数据驱动方法和硬编码规则。
4. 2007年,提出了使用词库方法进行词汇替换的系统。
5. 2003年,将基本语义结构与其句法实现配对,并从谓词/参数结构生成释义。
6. 2016年,提出深度学习模型在复述句生成中的应用尚未得到严格探索。这是使用深度体系结构生成复述句并引入残留递归神经网络的第一批主要著作之一。
Finally, our work is also similar in spirit to other generative models for text, e.g. controllable text generation (Hu et al. 2017), which combines VAE and explicit constraints on independent attribute controls. Other prior works on VAE for text generation include (Bowman et al. 2015; Semeniuta, Severyn, and Barth 2017) which used VAEs to model holistic properties of sentences such as style, topic and various other syntactic features.
与本文提出的相似研究:
1. 2017年,将VAE和显式约束相结合。
2. 2015年、2017年,使用VAE对句子的整体属性进行建模,例如风格、主题和各种其他句法特征。
二、实验
1. 数据集:(两个)
We evaluate our framework on two datasets, one of which (MSCOCO) is for the task of standard paraphrase generation and the other (Quora) is a newer dataset for the specific problem of question paraphrase generation.
我们在两个数据集上评估我们的框架,其中(MSCOCO)用于复述生成任务;(Quora)是一个较新的数据集,用于问题复述的特定问题。
(1)MSCOCO:
MSCOCO(Linetal.2014):This dataset ,also used previously to evaluate paraphrase generation methods (Prakashet al. 2016), contains human annotated captions of over 120K images. Each image contains five captions from five different annotators. This dataset is a standard benchmark dataset for image caption generation task. In majority of the cases, annotators describe the most prominent object/action in an image, which makes this dataset suitable for the paraphrase generation task. The dataset has separate division for training and validation.Train 2014 contains over 82K images and Val 2014 contains over 40K images. From the five captions accompanying each image, we randomly omit one caption, and use the other four as training instances (by creating two source-reference pairs). Because of the free form nature of the caption generation task (Vinyals et al. 2015), some captions were very long. We reduced those captions to the size of 15 words (by removing the words beyond the first 15) in order to reduce the training complexity of the models, and also to compare our results with previous work (Prakash et al. 2016). Some examples of input sentence and their generated paraphrases can be found in Table 4.
MSCOCO是图像标题生成问题中常用的数据集,该数据集人工注释了120,000多张图像,每张图像的由5个人分别进行注释。考虑到每一个注释者描述的都是图片中最重要的部分,因此这个数据集可以应用于复述句生成任务。
将该数据集分为训练集和测试集,其中82,000张图片为训练集,40,000张为测试集。同时随机选取每张图片中5种注释中的一个进行舍弃,将剩余4种分成2组训练对(一组两句:原始句和复述句)。
此外,由于一些图像的注释内容可能很长,为了降低模型训练复杂度,本文将这些句子删减成15词以内(删除从第15个词开始之后的部分)。示例如图4所示:

(2)Quora:
Quora released a new dataset in January 2017. The dataset consists of over 400K lines of potential question duplicate pairs. Each line contains IDs for each question in the pair, the full text for each question, and a binary value that indicates whether the questions in the pair are truly a duplicate of each-other. Wherever the binary value is 1,the question in the pair are not identical; they are rather paraphrases of each-other. So, for our study, we choose all such question pairs with binary value 1. There are a total of 155K such questions. In our experiments, we evaluate our model on 50K, 100K and 150K training dataset sizes. For testing, we use 4K pairs of paraphrases. Some examples of question and their generated paraphrases can be found in Table5.
2017年1月发布,包含400,000行可能是重复问题的问题对。每行包含内容有:ID、问题描述、问题是否为复述句(如果是1,则是复述句)。所以,本文选择为1的行进行试验,共155,000行。
训练数据集的规模为:50,000、100,000、150,000;测试数据集为:4000。示例如图5所示:

2. 实验基准
参见表1:
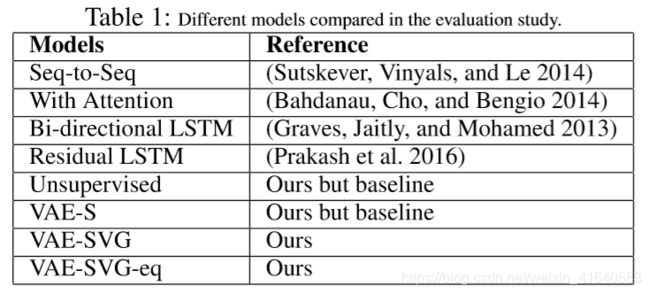
We consider several state-of-the-art baselines for our experiments. These are described in Table 1. For MSCOCO, we report results from four baselines, with the most important of them being by (Prakash et al. 2016) using residual LSTM. Residual LSTM is also the current state-of-the-art on the MSCOCO dataset. For the Quora dataset, there were no known baseline results, so we compare our model with (1) standard VAE model i.e., the unsupervised version, and (2) a “supervised” variant VAE-S of the unsupervised model. In the unsupervised version, the VAE generator reconstructs multiple variants of the input sentence using the VAE generative model trained only using the original sentence(without their paraphrases); in VAE-S, the VAE generator generates the paraphrase conditioned on the original sentence, just like in the proposed model. This VAE-S model can be thought of as a variation of the proposed model where we remove the encoder LSTM related to the paraphrase sentence from the encoder side. Alternatively, it is akin to a variation of VAE where decoder is made supervised by making it to generate “paraphrases” (instead of the reconstructing original sentence as in VAE) by conditioning the decoder on the input sentence.
对于数据集MSCOCO,选择4个实验基准进行对比,其中最重要的是2016年提出的采用残差LSTM方法。
对于数据集Quora,没有已知的实验基准,因此,采用的对比基准为:(1)标准VAE模型(无监督);(2)VAE-S(“监督”)。
其中,无监督学习中的VAE生成器不使用复述句,只使用原始句进行训练生成输入句的变形。
而VAE-S,则是以原始句子为条件生成复述句,与本文提出的方法类似,区别在于本文提出的方法删除了encoder部分中与复述句相关的encoder LSTM。说VAE-S是“监督”学习,是因为该模型调节在输入句子上调节decoder来使其生成“复述”(而不是像在VAE中那样重构原始句子)。
3. 实验设置:
Our framework primarily uses the following experimental setup. These settings are directly borrowed from an existing implementation of the paper(Bowmanetal.2015), and were not fine tuned for any of the datasets. In our setup, we do not use any external word embeddings such as Glove; rather we train these as part of the model-training. The dimension of the embedding vector is set to 300, the dimension of both encoder and decoder is 600, and the latent space dimension is 1100. The number of layers in the encoder is 1 and in decoder 2. Models are trained with stochastic gradient descent with learning rate fixed at a value of 5×10−5 with dropout rate of 30%. Batch size is kept at 32. Models are trained for a predefined number of iterations, rather than a fixed number of epochs. In each iteration, we sequentially pick the next batch. A fixed number of iterations makes sure that we do not increase the training time with the amount of data. When the a mount of data is increased, we run fewer passes over the data as opposed to the case when there is less data. Number of units in LSTM are set to be the maximum length of the sequence in the training data.
实验的主要参数设置参考了2015年的论文《Generating sentences from a continuous space》(源码:ttps://github.com/kefirski/pytorch_RVAE),未对任何数据集做fine-tuning。本文模型中,没有使用额外的word embedding过程,而是将其作为训练的一部分。
设置:embedding向量维度:300;encoder和decoder维度:600;隐变量维度:1100;一层encoder,两层decoder。模型使用SGD进行训练,学习率:![]() ,dropout:30%,batch size为32。
,dropout:30%,batch size为32。
迭代次数是经过预训练得到的,而不是采用固定的epoch。在每次迭代过程中,都一次选择下一批数据进行训练。迭代次数固定可以保证整体的训练时间不会随着数据量的增大而增大。同时,当数据量增大时,相对于数据较少的情况,我们对数据进行的传递较少。
LSTM中的units数设置为训练数据中句子的最大长度。
4. 评测:
Quantitative Evaluation Metrics For quantitative evaluation, we use the well-known automatic evaluation metrics in machine translation domain : BLEU (Papineni et al. 2002), METEOR (Lavie and Agarwal 2007), and Translation Error Rate (TER) (Snover et al. 2006). Previous work has shown that these metrics can perform well for the paraphrase recognition task (Madnani, Tetreault, and Chodorow 2012) and correlate well with human judgments in evaluating generated paraphrases (Wubben, Van Den Bosch, and Krahmer 2010). BLEU considers exact match between reference paraphrase(s) and system generated paraphrase(s) using the concept of modified n-gram precision and brevity penalty. METEOR also uses stemming and synonyms (using WordNet) while calculating the score and is based on a combination of unigram-precision and unigram-recall with the reference paraphrase(s). TER is based on the number of edits (insertions, deletions, substitutions, shifts) required for a human to convert the system output into one of the reference paraphrases.
采用机器翻译领域中的自动评估指标:BLEU、METEOR、TER。这是因为:先前的工作表明,这些度量标准可以很好地执行复述识别任务,并且评估方式与人类的评估方式类似。
(1)BLEU:使用改进的n-gram精度和简洁度的惩罚概念来考虑参考释义和系统生成释义之间的精确匹配度。
(2)METEOR:在计算分数时还使用词干和同义词(使用WordNet),并将一元模型中的精度和召回率进行结合。
(3)TER:基于系统输出的句子和给定的参考复述句之间的编辑距离。
Qualitative Evaluation Metrics To quantify the aspects that are not addressed by automatic evaluation metrics, human evaluation becomes necessary for our problem. We collect human judgments on 100 random input sentences from both MSCOCO and Quora dataset. Two aspects are verified in human evaluation : Relevance of generated paraphrase with the input sentence and Readability of generated paraphrase. Six Human evaluators (3 for each dataset) assign a score on a continuous scale of 1-5 for each aspect per generated paraphrase, where 1 is worse and 5 is best.
定性评估指标是为了量化自动评估指标中无法评估的方面,对此,需要进行人工评估。 本文从MSCOCO和Quora数据集中随机收集了100条人工判断的句子。
人工评估验证了两个方面:(1)生成的复述句与输入句的相关性;(2)生成的复述句的可读性。
六个评估者(每个数据集3人)对生成的复述句进行评分(1-5分),其中1较差,5最佳。
5. 变体模型
In addition to the model proposed in Methodology Section, we also experiment with another variation of this model. In this variation, we make the encoder of original sentence same on both sides i.e. encoder side and the decoder side. We call this model VAE-SVG-eq (SVG stands for sentence variant generation). The motivation for this variation is that having same encoder reduces the number of model parameters, and hopefully helps in learning.
除了“方法”部分提出的模型之外,我们也对该模型的另一个变体进行了实验。 在该变体中,对原始句进行的encoder是相同的。 我们将此模型称为VAE-SVG-eq(SVG代表句子变体生成)。 选择这种变化的原因在于,具有相同的编码器会降低模型参数的数量,并希望对学习过程起作用。
6. 实验
We perform experiments on the above mentioned datasets, and report, both qualitative and quantitative results of our approach. The qualitative results for MSCOCO and Quora datasets are given in Tables 4 and 5 respectively. In these tables, Red and Blue colors denote interesting phrases which are different in the ground truth and generated variations respectively w.r.t. the input sentence. From both the tables , we see that variations contain many interesting phrases such as in front of an airport, busy street, wooden table, recover, Tech training etc. which were not encountered in input sentences. Furthermore, the paraphrases generated by our system are well-formed, semantically sensible, and grammatically correct for the most part. For example, for the MSCOCO dataset, for the input sentence “A man with luggage on wheels standing next to a white van.”, one of the variants “A young man standing in front of an airport”. is able to figure out that the situation pertains to “waiting in front of an airport”, probably from the phrases standing and luggage on wheels. Similarly, for the Quora dataset, for the question “What is my old Gmail account?”, one of the variants is “Is there any way to recover my Gmail account? ”which is very similar –but not the same– to the paraphrase available in the groundtruth. It is further able to figure out that the input sentence is talking about recovering the account. Another variant “How can I get the old Gmail account password? ”tells us that accounts are related to the password, and recovering the account might mean recovering the password as well.
对上述数据集( MSCOCO、Quora)进行实验,定性和定量结果如下。 MSCOCO和Quora数据集的定性结果如表4和表5所示。在这些表中,红色和蓝色表示产生变化的短语。从这两个表中可以看到一些在输入句中没有涉及到的短语,如in front of an airport, busy street, wooden table, recover, Tech training等。此外,我们系统生成的复述句在大多数情况下格式正确,语义合理且语法正确。例如,MSCOCO数据集,输入语句“ A man with luggage on wheels standing next to a white van”,一种复述句为:“ A young man standing in front of an airport”,该复述句可能会根据“standing”和“luggage on wheels”指出发生的背景与“waiting in front of anairport”有关。同样,对于Quora数据集,对于问题“What is my old Gmail account?”的一种复述为:“Is there any way to recover my Gmail account? ”与真实复述句很相似,但不完全相同。复述句还可以弄清楚输入的句子是在谈论恢复帐户问题。另一个复述句是 “How can I get the old Gmail account password? ” 告诉我们帐户与密码有关,恢复帐户可能也意味着要恢复密码。
(本文提出的方法可以学习到一些潜在的背景知识,使复述句中包含一些原句没有的内容)
In Tables 2 and 3, we report the quantitative results from various models for the MSCOCO and Quora datasets respectively. Since our models generate multiple variants of the input sentence, one can compute multiple metrics with respect to each of the variants. In our tables, we report average and best of these metrics. For average, we compute the metric between each of the generated variants and the ground truth, and then take the average. For computing the best variant, while one can use the same strategy, that is, compute the metric between each of the generated variants and the ground truth, and instead of taking average find the best value but that would be unfair. Note that in this case, we would be using the groundtruth to compute the best which is not available at test time. Since we cannot use the groundtruth to find the best value, we instead use the metric between the input sentence and the variant to get the best variant, and then report the metric between the best variant and the groundtruth. Those numbers are reported in the Measure column with row best-BLEU/best-METEOR.
表2和表3记录了MSCOCO和Quora数据集的实验结果。由于本文提出的模型能够生成多个输入句的复述句,因此可以针对每一个复述句采用多种评测标准进行分析。如表所示,分别记录了平均结果和最优结果。
均值:计算生成复述句和给定复述句的评测指标,然后取均值。
最优:根据输入句和生成复述句之间的指标获得最优复述句,然后记录生成的最优复述句和给定的复述句之间的度量值。
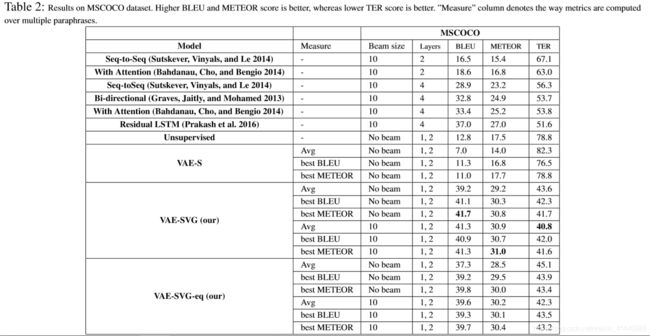

In Table2, we report the results for MSCOCO dataset. For this dataset, we compare the results of our approach with existing approaches. As we can see, we have a significant improvement w.r.t. the baselines. Both variations of our supervised model i.e., VAE-SVG and VAE-SVG-eq perform better than the state-of-the-art with VAE-SVG performing slightly better than VAE-SVG-eq. We also evaluate with respect to be stvariant. The best variant is computed using different metrics, that is, BLEU and METEOR, however the best variant is not always guaranteed to perform better than average since best variant is computed with respect to the input question not based on the ground truth. When using the best variant, we get improvement in all three metrics in the case of non-beam search, however when experimented with generating paraphrases through beam-search, we get further improvement for METEOR and TER however these improvement are not as significant as for the Quora dataset, as you will see below. This could be because MSCOCO is an image captioning dataset which means that dataset does not contain fully formed grammatical sentences, as one can see from the examples in Table 4. In such cases, beam search is not able to capture the structure of the sentence construction. When comparing our results with the state-of-the-art baseline, the average metric of the VAE-SVG model is able to give a 10% absolute point performance improvement for the TER metric, a significant number with respect to the difference between the best and second best baseline which only stands at 2% absolute point. For the BLEU and METEOR, our best results are 4.7% and 4% absolute point improvement over the state-of-the-art.
表2记录了MSCOCO数据集的实验结果。可以看出本文提出的方法(VAE-SVG和VAE-SVG-eq)要更好,并且VAE-SVG的性能则略高于VAE-SVG-eq。
其中生成的最优复述句是根据不同的度量方式(BLEU和METEOR)计算得到的,但是最优复述句的表现效果并不是一直要比平均值更好,这是因为最优复述句是根据输入句计算得到的,而不是给定的标注句。当使用最优复述句的时候,在beam-search情况下,在三个指标上都有所改进;但在根据beam-search生成复述句时,虽然METEOR和TER上有了进一步的改进,但是这些改进不如Quora数据集。这是因为MSCOCO是一个图像数据集,该数据集包含不完整的语法句子,如表4所示。在这种情况下,beam-search无法获取句子的结构。将我们的实验结果与最新的方法进行对比时,VAE-SVG模型的平均指标能够使TER指标提高10%。对于BLEU和METEOR,最优结果提高了4.7%和4%。
In Table 3, we report results for the Quora dataset. As we can see, both variations of our model perform significantly better than unsupervised VAE and VAE-S, which is not surprising. We also report the results on different training sizes, and as expected, as we increase the training data size, results improve. Comparing the results across different variants of supervised model, VAE-SVG-eq performs the best. This is primarily due to the fact that in VAE-SVG-eq, the parameters of the input question encoder are shared by the encoding side and the decoding side. We also experimented with generating paraphrases through beam-search, and, unlike MSCOCO, it turns out that beam search improves the results significantly. This is primarily because beam-search is able to filter out the paraphrases which had only few common terms with the input question. When comparing the best variant of our model with unsupervised model (VAE), we are able to get more than 27% absolute point (more than 3 times) boost in BLEU score, and more than 19% absolute point (more than 2 times )boost in METEOR; and when comparing with VAE-S, we are able to get a boost of almost 19% absolute points in BLEU (2 times) and more than 10% absolute points in METEOR (1.5 times).
表3记录了Quora数据集的实验结果,可以看到本文提出的两种方法都比无监督的VAE和VAE-S更优。此外,也对不同数量的数据集进行了实验,结果表明:训练数据量越大,实验结果越好。将本文提出的两种监督模型进行对比,实验表明:VAE-SVG-eq的实验效果要更好。主要原因在于:输入句的encoder参数由编码端和解码端共享。
此外,也尝试了通过beam-search生成复述句,效果很好。主要原因在于:beam-search能够筛选出与输入句仅仅有很少公共短语的复述句。
将提出的最优模型与无监督模型(VAE)进行比较,可以发现:BLEU提升27%以上;METEOR提升19%以上;
与VAE-S相比:BLEU提升19%以上;METEOR提升10%以上;
The results of the qualitative human evaluation are shown in Table 6. From the Table, we see that our method produces results which are close to the groundtruth for both metrics Readability and Relevance. Note that Relevance of the MSCOCO dataset is 3.38 which is far from a perfect score of 5 because unlike Quora, MSCOCO dataset is an image caption dataset, and therefore allows for a larger variation in the human annotations.
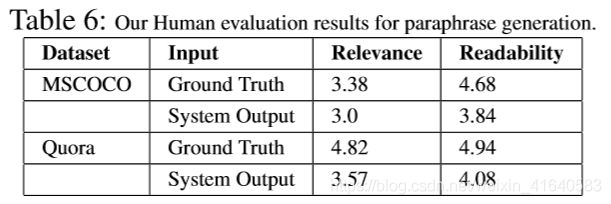
定性实验结果如表6。从表中可以看出,我们方法所产生的结果在可读性和相关性上都接近于真实值。虽然MSCOCO数据集的相关性为3.38,与5分的理想成绩相距较大,这是因为MSCOCO数据集是图像数据集,允许更大的错误。
Note that one can use the metric between the variant and the input question to provide filtering in the case of multiple variants, or even to decide if a variant needs to be reported or not. So in order to make the system more practical (a high precision system ), we choose to report the variant only when the confidence in the variantis more than a threshold. We use the metric between input question and the variant to compute this confidence. Naturally this thresholding reduces the recall of the system. In Figure 3, we plot the recall for Quora dataset, after thresholding the confidence (computed using the BLEU between the variant and the input question), and the average metrics for those candidates that pass the threshold. Interestingly, we can increase the BLEU score of the system as much as up to 55% at the recall of 10%. Plots generated using other metrics such as METEOR and TER showed a similar trend.
在生成多个复述句的情况下,可以计算每个复述句与输入句之间的度量来判断是否要记录这个复述句。因此,为了保证系统更加实用,选择当变量的置信度(通过复述句和输入句之间的度量来计算)大于某一预置的时候才进行记录;但也导致了系统的召回率降低。
在图3中,设置置信度(通过复述句和输入句之间的BLEU计算)的阈值、 并将通过该阈值的候选集(Quora数据集)的召回率进行图像绘制。此外,在召回率为10%的情况下,可以将系统的BLEU分数提高多达55%。 使用其他度量标准(例如METEOR和TER)生成的图显示了类似的趋势。
三、结论
In this paper we have proposed a deep generative framework, in particular, a Variational Autoencoders based architecture, augmented with sequence-to-sequence models, for generating paraphrases. Unlike traditional VAE and unconditional sentence generation model, our model conditions the encoder and decoder sides of the VAE on the input sentence, and therefore can generate multiple paraphrases for a given sentence in a principled way. We evaluate the proposed method on a general paraphrase generation dataset, and show that it outperforms the state-of-the-art by a significant margin, without any hyper-parameter tuning. We also evaluate our approach on a recently released question paraphrase dataset, and demonstrate its remarkable performance. The generated paraphrases are not just semantically similar to the original input sentence, but also able to capture new concepts related to the original sentence.
文中提出了一种深度生成框架:是一种基于自动编码器变形的体系结构,对sequence-to-sequence模型起到强化作用。与传统的VAE和无条件语句生成模型不同,提出的模型在输入语句上对VAE的encoder和decoder端进行条件调整,能够生成多个复述句。并做了大量实验,证明本文提出方法的有效性:生成的复述句不仅在语义上接近输入句,也能够捕获与原始句子相关的新概念。