自然语言处理实践(新闻文本分类)——task04
基于深度学习的文本分类1
FastText
FastText结构简图:

fasttext.supervised 参数如下:
| 参数 | 作用 |
|---|---|
| input_file | 训练文件路径(必须) |
| output | 输出文件路径(必须) |
| label_prefix | 标签前缀 default label |
| lr | 学习率 default 0.1 |
| lr_update_rate | 学习率更新速率 default 100 |
| dim | 词向量维度 default 100 |
| ws | 上下文窗口大小 default 5 |
| epoch | epochs 数量 default 5 |
| min_count | 最低词频 default 5 |
| word_ngrams | n-gram 设置 default 1 |
| loss | 损失函数 {ns,hs,softmax} default softmax |
| minn | 最小字符长度 default 0 |
| maxn | 最大字符长度 default 0 |
| thread | 线程数量 default 12 |
| t | 采样阈值 default 0.0001 |
| silent | 禁用 c++ 扩展日志输出 default 1 |
| encoding | 指定 input_file 编码 default utf-8 |
| pretrained_vectors | 指定使用已有的词向量 .vec 文件 default None |
层次softmax
softmax函数常在神经网络输出层充当激活函数,目的就是将输出层的值归一化到0-1区间,将神经元输出构造成概率分布,主要就是起到将神经元输出值进行归一化的作用
在标准的softmax中,计算一个类别的softmax概率时,我们需要对所有类别概率做归一化,在这类别很大情况下非常耗时,因此提出了分层softmax(Hierarchical Softmax),思想是根据类别的频率构造霍夫曼树来代替标准softmax,通过分层softmax可以将复杂度从N降低到logN,下图给出分层softmax示例:
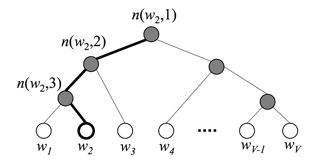
在层次softmax模型中,叶子结点的词没有直接输出的向量,而非叶子节点都有响应的输在在模型的训练过程中,通过Huffman编码,构造了一颗庞大的Huffman树,同时会给非叶子结点赋予向量。我们要计算的是目标词w的概率,这个概率的具体含义,是指从root结点开始随机走,走到目标词w的概率。因此在途中路过非叶子结点(包括root)时,需要分别知道往左走和往右走的概率。
代码展示
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import f1_score
from sklearn.externals import joblib
import fasttext
###数据读取
train_df = pd.read_csv('/content/drive/My Drive/NLP_Learn/train/train_set.csv', sep='\t')
test_df = pd.read_csv('/content/drive/My Drive/NLP_Learn/test/test_a.csv',sep='\t')
##数据格式转换
train_df['label_ft'] = '__label__' + train_df['label'].astype(str)
train_df[['text','label_ft']].to_csv('/content/drive/My Drive/NLP_Learn/train.csv', index=None, header=None, sep='\t')
##模型训练
model = fasttext.train_supervised('/content/drive/My Drive/NLP_Learn/train.csv',
lr=1.0,wordNgrams=5,verbose=2,minCount=3,epoch=50,loss="softmax")
训练时间很长。应该是数据量巨大,且n-gram改成了5,epoch改成了50(我后悔了。。。)。
将epoch改成5,n-gram改成3之后重新训练了一次。
model = fasttext.train_supervised('/content/drive/My Drive/NLP_Learn/train.csv',
lr=1.0,wordNgrams=3,verbose=2,minCount=3,epoch=5,loss="softmax")
##模型验证
val_pred = [model.predict(x)[0][0].split('__')[-1] for x in train_df['text']]
print(f1_score(train_df['label'].values.astype(str), val_pred, average='macro'))
输出结果 f1 分数为

明显强于TF-IDF + Logic的 f1 分数0.94。