CVPR2020无人驾驶论文摘要
CVPR2020无人驾驶论文摘要
无人
导读/ Starsky是一种比较独特的方案。它是在高速上自动驾驶,第一公里最后一公里采用远程驾驶的模式,Starsky的卡车可以由人类远程操作。没有使用较为昂贵的激光雷达,而是选择了摄像头+毫米波雷达的传感器配置。

国际计算机视觉与模式识别会议(CVPR)是IEEE一年一度的学术性会议,在世界范围内具有顶级的权威性与影响力,同时也是圈内学者关注和交流的重要场所。
素有计算机视觉领域“奥斯卡”之称的CVPR有着相当严苛的录用标准。据统计,会议往年的平均录取率不超过30%,而根据CVPR2020官方公布论文收录结果,本届CPVR共接收6656篇论文,中选1470篇,“中标率”只有22%,堪称十年来最难入选的一届。
然而,在论文接收率下降的同时,中国科技企业被录取论文数量却不降反增,百度作为AI代表企业今年中选22篇,比去年的17篇增加了5篇。在自动驾驶领域,与安全息息相关的车辆识别全新数据合成方法研究便位列其中。
近年来,CVPR蓬勃发展的重要原因,很大一部分是源自于中国科技公司的贡献。本次会议中,百度入选的22篇论文,全面涵盖视觉领域下的自动驾驶中的车辆检测、人脸检测&识别、视频理解&分析、图像超分辨及场景实例级分割等众多热门子领域,也向国际领域展示了中国视觉技术水平的深厚积累。
除了多篇论文被收录,百度还将在本届CVPR中联合悉尼科技大学、南开大学等单位共同主办弱监督学习研讨会(The 2nd Workshop onLearning from Imperfect Data),以及与中科院等单位共同主办活体检测研讨会(The 4th Workshop on MediaForensics),与更多顶尖学者进行深入交流。
如下为百度入选CVPR 2020的部分论文展示:
1.车辆识别
3D Part Guided Image
Editing for Fine-grained Object Understanding
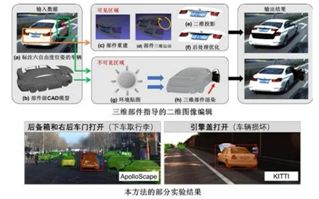
在自动驾驶场景中,准确地感知“特殊”状态的车辆对行驶安全至关重要(例如:车门打开可能有乘客下车,尾灯闪烁意味着即将变道)。针对此难题,本文提出了一个全新的数据合成(增强)方法,即通过对齐的部件级三维模型对二维图像中的车辆进行编辑,自动生成大量“特殊”状态(例如:开启的车门、后备箱、引擎盖,闪烁的前照灯、尾灯)的车辆图像与语义标注结果。针对生成的训练数据,本文设计了一个双路骨干网络使得模型可以泛化到真实的测试数据,与传统的模型渲染方法相比,本方法平衡了域差异的问题并且更加轻量便捷。
为了验证方法的有效性,本文构建了CUS (Cars in Uncommon States) 数据集,标注了约1400张真实街景下车辆处于特殊状态的图像。实验结果表明:本文提出的方法可以有效地对“特殊”状态的车辆进行检测、整车的实例级分割、部件的语义分割以及状态描述,对自动驾驶的安全决策有着重要的意义。
2.目标检测&跟踪
Associate-3Ddet:Perceptual-to-Conceptual association for 3D Point Cloud
Object Detection
目标检测技术是机器人和自动驾驶领域中最重要的模式识别任务之一。本文提出了一种领域自适应的方法来增强稀疏点云特征的鲁棒性。更具体地说,是将来自真实场景的特征(感知域特征)和从包含丰富细节信息的完整虚拟点云特征(概念域特征)进行了关联。这种域适应特征关联的方法实际上是模拟在人脑进行物体感知时的联想关联功能。这种三维目标检测算法在训练过程中增强了特征提取能力,在推理阶段不需要引入任何额外的组件,使得该框架易于集成到各种三维目标检测算法中。
Neural Message Passingand Attentive Spatiotemporal Transformer for Point
Cloud Based 3D Video Object Detection

基于单帧点云的3D目标检测器通常无法应对目标遮挡、远距离和非均匀采样等情况,而点云视频(由多个点云帧组成)通常包含丰富的时空信息,可以改善上述情况下的检测效果,因此本文提出一个端到端的在线3D点云视频目标检测器。论文中的Pillar Message Passing
Network(PMPNet),可将点云俯视图下的非空栅格编码为图节点,并在节点间进行信息传递以动态改善节点感受野,PMPNet可以有效结合图空间的非欧特性和CNN的欧式特性;在时空特征聚合模块中,还提出空间和时间注意力机制来强化原始的Conv-GRU层,空间注意力机制对new memory进行前景增强和背景抑制,时间注意力机制用以对齐相邻帧中的动态前景目标。该3D点云视频目标检测器在nuScenes大型基准集上达到了领先效果。
A Unified Object Motionand Association Model for Efficient Online
Multi-object Tracking

利用单目标跟踪器(SOT)作为运动预测模型执行在线多目标跟踪(MOT)是当前的流行方法,但是这类方法通常需要额外设计一个复杂的相似度估计模型来解决相似目标干扰和密集遮挡等问题。本文利用多任务学习策略,将运动预测和相似度估计到一个模型中。值得注意的是,该模型还设计了一个三元组网络,可同时进行SOT训练、目标ID分类和排序,网络输出的具有判别力的特征使得模型可以更准确地定位、识别目标和进行多目标数据关联;此外,论文中提出了一个任务专属注意力模块用于强调特征的不同上下文区域,进一步强化特征以适用于SOT和相似度估计任务。该方法最终得到一个低存储(30M)和高效率(5FPS)的在线MOT模型,并在MOT2016和MOT2017标准测试集上取得了领先效果。
3.人脸检测&识别

HAMBox: Delving into Online High-quality Anchors for Detecting Outer Faces
近期,关于人脸检测器利用锚点构建一个结合分类和坐标框回归的多任务学习问题,有效的锚点设计和锚点匹配策略使得人脸检测器能够在大姿态和尺度变化下精准定位人脸。本次论文中,百度提出了一种在线高质量锚点挖掘策略HAMBox,它可以使得异常人脸(outer faces)被补偿高质量的锚点。HAMBox方法可以成为一种基于锚点的单步骤人脸检测器的通用优化方案。该方案在WIDER
FACE、FDDB、AFW和PASCAL Face多个数据集上的实验表明了其优越性,同时在2019年WIDER Face and Pedestrian Challenge上,以mAP
57.13%获得冠军,享誉国际。
FaceScape: a Large-scale High Quality 3D Face Dataset and Detailed
Riggable 3D Face Prediction

该论文发布大尺度高精度人脸三维模型数据库FaceScape,并首次提出从单幅图像预测高精度、可操控人脸三维模型的方法。FaceScape数据库包含约18000个高精度三维面部模型,每个模型包含基底模型和4K分辨率的置换图及纹理贴图,能够表征出面部极细微的三维结构和纹理。与现有公开的三维人脸数据库相比,FaceScape在模型数量和质量上均处于世界最高水准。
在FaceScape数据库的基础之上,本文还探索了一项具有挑战性的新课题:以单幅人脸图像为输入,预测高精度、表情可操控的三维人脸模型。该方法的预测结果能够通过表情操控生成精细的面部模型序列,所生成的模型在新表情下仍然包含逼真的细节三维结构。据悉,FaceScape数据库和代码将于近期免费发布,供非商业用途的学术研究使用。
Hierarchical Pyramid Diverse Attention Network for Face Recognition

目前主流的人脸识别方法很少考虑不同层的多尺度局部特征。为此,本文提出了一个分层的金字塔多样化注意力模型。当面部全局外观发生巨大变化时,局部区域将起重要作用。最近的一些工作应用注意力模块来自动定位局部区域。如果不考虑多样性,所学的注意力通常会在一些相似的局部块周围产生冗余的响应,而忽略了其他潜在的有判别力的局部块。此外,由于姿态或表情变化,局部块可能以不同的尺度出现。为了缓解这些挑战,百度团队提出了一种金字塔多样化注意模块,以自动和自适应地学习多尺度的多样化局部表示。更具体地说,开发了金字塔注意力模块以捕获多尺度特征;同时为了鼓励模型专注于不同的局部块,开发了多元化的学习方法。其次,为了融合来自低层的局部细节或小尺度面部特征图,可以使用分层双线性池化来代替串联或添加。
4.视频理解&分析
ActBERT: Learning Global-Local Video-Text Representations

受到BERT在自我监督训练中的启发,百度团队对视频和文字进行类似的联合建模,并基于叙述性视频进行视频和文本对应关系研究。其中对齐的文本是通过现成的自动语音识别功能提供的,这些叙述性视频是进行视频文本关系研究的丰富数据来源。ActBERT加强了视频文字特征,可以发掘到细粒度的物体以及全局动作意图。百度团队在许多视频和语言任务上验证了ActBERT的泛化能力,比如文本视频片段检索、视频字幕生成、视频问题解答、动作分段和动作片段定位等,ActBERT明显优于最新的一些视频文字处理算法,进一步证明了它在视频文本特征学习中的优越性。
Memory Aggregation Networks for Efficient Interactive Video Object
Segmentation
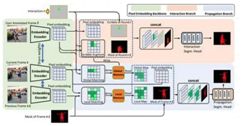
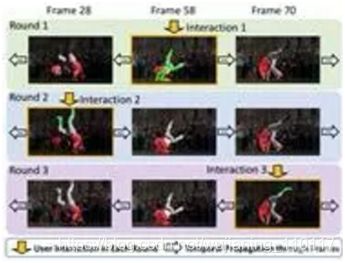

该论文目的是设计一个快速的交互式视频分割系统,用户可以基于视频某一帧在目标物上给出简单的线,分割系统会把整个视频中该目标物分割出来。此前,针对交互式视频分割的方法通常使用两个独立的神经网络,分别进行交互帧分割、将分割结果传导至其他帧。本文将交互与传导融合在一个框架内,并使用像素embedding的方法,视频中每一帧只需要提取一次像素embedding,更有效率。另外,该方式使用了创新性的记忆存储机制,将之前交互的内容作用到每一帧并存储下来,在新的一轮交互中,读取记忆中对应帧的特征图,并及时更新记忆。该方式大幅提升分割结果的鲁棒性,在DAVIS数据集上取得了领先的成绩。
Action Segmentation with Joint Self-Supervised Temporal Domain Adaptation
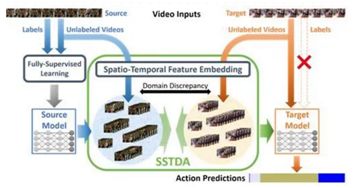
尽管最近在完全监督的领域上,动作分割技术方面取得了进步,但是其性能仍有不足。一个主要的挑战是时空变化的问题(例如不同的人可能以各种方式进行相同的动作)。因此,该论文中利用未标记的视频来解决此问题,方法是将动作分割任务重新设计为跨域(domain)问题,而且该跨域问题主要针对时空变化引起的域差异。为了减少差异,论文提出了“自我监督的时域自适应(SSTDA)”,其中包含两个自我监督的辅助任务(binary和sequential的域预测),以联合对齐嵌入不同规模时域动态的跨域特征空间,从而获得比其他域适应(DA)方法更好的效果。在三个具有挑战性的公开数据集(GTEA、50Salads和Breakfast)上,SSTDA远远领先于当前的最新方法,并且只需要65%的标签训练数据即可获得与当前最新方法可比的性能,这也表明该方法可以有效利用未标签目标视频来适应各种变化。
5。图像超分辨
Channel Attention based Iterative Residual Learning for Depth Map
Super-Resolution
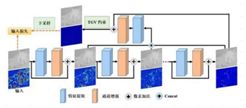
随着深度信息的应用范围越来越大,深度图像超分辨问题引起了广泛研究者的关注。深度图像超分辨率是指由低分辨率深度图像为基础,获取高质量的高分辨率深度图像。本文提出的是一种深度图像超分辨率方法,同时对低分辨率深度图像的产生方式进行分析,并提出两种模拟低分辨率深度图像生成的方式:伴随噪声的非线性插值降采样产生方式及间隔降采样产生方式。针对不同类型的低分辨率深度图像,本文使用迭代的残差学习框架以低分辨率深度图像为输入,以coarse-to-fine的方式逐步恢复高分辨率深度图像的高频信息;同时,使用通道增强的策略加强包含高频信息较多的通道在整个学习框架中的作用;另外,还使用多阶段融合的策略有效复用在coarse-to-fine过程中获得的有效信息;最后,通过TGV约束和输入损失函数进一步优化获得的高分辨率深度图像。此次提出的方法可以有效处理深度图像超分辨率问题,与目前已知的方法相比,效果显著,优势明显。
6.神经网络架构搜索
GP-NAS: Gaussian Process based Neural Architecture Search
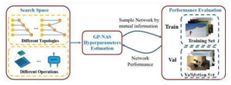
通过对深度神经网络进行模型结构自动搜索, NAS(Neural
ArchitectureSearch)在各类计算机视觉的任务中都超越了人工设计模型结构的性能。
本论文旨在解决NAS中的三个重要问题:
如何衡量模型结构与其性能之间的相关性?
如何评估不同模型结构之间的相关性?
如何用少量样本学习这些相关性?
为此,本论文首先从贝叶斯视角来对这些相关性进行建模。
首先,通过引入一种新颖的基于高斯过程的NAS(GP-NAS)方法,并通过定制化的核函数和均值函数对相关性进行建模。并且,均值函数和核函数都是可以在线学习的,以实现针对不同搜索空间中的复杂相关性的自适应建模。此外,通过结合基于互信息的采样方法,可以通过最少的采样次数就能估计/学习出GP-NAS的均值函数和核函数。在学习得到均值函数和核函数之后,GP-NAS就可以预测出不同场景,不同平台下任意模型结构的性能,并且从理论上得到这些性能的置信度。在CIFAR10和ImageNet上的大量实验证明了我们算法的有效性,并且取得了SOTA的实验结果。
BFBox: Searching Face-appropriate Backbone and Feature Pyramid Network for
Robust Face Detector
本文提出的BFBox是基于神经网络架构搜索的方法,同时搜索适合人脸检测的特征提取器和特征金字塔。动机是我们发现了一个有趣的现象:针对图像分类任务设计的流行的特征提取器已经在通用目标检测任务上验证了其重要的兼容性,然而在人脸检测任务上却没有取得预期的效果。同时不同的特征提取器与特征金字塔的结合也不是完全正相关的。首先,本文对于比较好的特征提取器进行分析,提出了适合人脸的搜索空间;其次,提出了特征金字塔注意力模块(FPN-attention Module)去加强特征提取器和特征金字塔之间的联系;最后,
采取SNAS的方法同时搜出适合人脸的特征提取器和特征金字塔结构。多个数据集上的实验表明了BFBox方法的优越性。
7.结构设计
Gated Channel Transformation for Visual Recognition
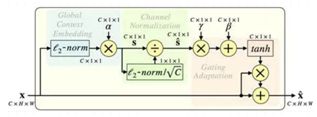
本文针对深度卷积神经网络提出了一种常规的、易应用的变换单元,即Gated Channel
Transformation (GCT) 模块。GCT结合了归一化方法和注意力机制,并使用轻量级的、易于分析的变量来隐式地学习网络通道间的相互关系。这些通道量级的变量可以直接影响神经元间的竞争或者合作行为,且能方便地与卷积网络本身的权重参数一同参与训练。通过引入归一化方法,GCT模块要远比SE-Nets的SE模块轻量,这使得将GCT部署在每个卷积层上而不让网络变得过于臃肿成为了可能。本文在多个大型数据集上针对数种基础视觉任务进行了充分的实验,即ImageNet数据集上的图片分类,COCO上的目标检测与实例分割,还有Kinetics上的视频分类。在这些视觉任务上,引入GCT模块均能带来明显的性能提升。这些大量的实验充分证明了GCT模块的有效性。
8.表征学习
Label-Isolated Memory for Long-Tailed Visual Recognition
实际场景中的数据通常遵循“长尾”分布。大量类别都是数据较少,而有少数类别数据充足。为了解决类不平衡问题,本文引入了类别隔离记忆结构(LIM)用于长尾视觉识别。首先,LIM增强了卷积神经网络快速学习尾部类别特征的能力。通过存储每个类的最显著的类别特征,独立更新存储单元,LIM进一步降低了分类器学偏的可能。其次,本文为多尺度空间特征编码引入了一种新颖的区域自注意力机制。为了提高尾类识别通用性,合并更多区别性强的特征是有好处的。本文提出以多个尺度对局部特征图进行编码,同时背景信息也被融合进来。配备LIM和区域自注意力机制,该方法在5个数据集上都取得了最好的性能。
CVPR是计算机视觉领域的国际顶级会议,百度能够在CVPR中保持多年的优势,除了在国际领域中屡获佳绩的视觉技术,其语音、人脸、NLP、OCR等技术也有不俗的成绩,调用量均为中国第一。
未来,Apollo自动驾驶技术还将不断打磨、创新,协同百度AI生态体系,致力于顶尖的学术研究、前瞻的技术布局、深入行业的落地应用,为全球自动驾驶领域贡献更多突破性的科技力量。