InterValue抗量子hash算法&分层共识机制介绍
文章目录
- InterValue抗量子哈希算法
- 1.抗量子攻击的哈希算法
- 2.抗量子攻击的数字签名算法
- InterValue分层共识机制
- 1.HashNet共识
- 2.BA-VRF共识
InterValue抗量子哈希算法
1.抗量子攻击的哈希算法
密码学中的哈希算法又称为散列函数或杂凑函数,它在现代密码学中扮演着重要的角色。哈希算法是一个公开的函数H,它将任意长的消息M映射为较短的、固定氏度的值h。h称为消息摘要,也称为哈希值、散列值或杂凑值。哈希算法的结构如图9-10所示。
区块链为了保证数据不被篡改,除了保存原始数据或交易记录,还要保存其哈希函数值。区块链上的交易数据通常通过很多次哈希后得到最终的Merkle Hash值,区块链上的地址数据通常是通过计算得到一个Hash值,并通过特定的编码将Hash值转化为由数字和字母组成的字符串后(如在比特币区块链中采用的是Base58编码)记入区块链。
量子计算机针对哈希算法目前最有效的攻击方法是GROVER算法,该算法可以将对Hash算法的攻击复杂度从O(2n)降为O(2n/2),因此,目前比特币系统采用的哈希算法PIREMD160算法由于输出长度只有160比特,在量子攻击下是不安全的。抵抗量子攻击的有效手段是通过增加哈希算法的输出长度来有效降低GROVER算法威胁,目前普遍认为只要哈希算法输出长度不少于256比特时,是可以有效抵抗量子攻击的。另外,除了量子攻击威胁外,一系列在实践中被广泛应用的Hash函数如MD4、MD5,SHA-1和HAVAL等受到差分分析、模差分和消息修改方法等传统方法的攻击,因此区块链中的哈希算法也需要考虑的是对传统攻击的抵抗能力。
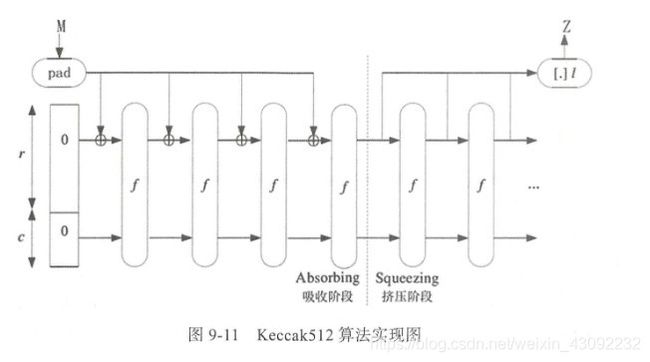
早期的区块链项目如比特币、莱特币、以太坊都采用了存在设计缺陷(但不是致命的)的SHA系列哈希算法,最近新的区块链项目都采用以美国国家标准与技术研究院SHA-3计划系列算法为代表的新哈希算法。InterValue采用SHA-3计划的胜出算法Keccak512,该算法蕴含许多杂凑函数和密码算法最新的设立理念和思想,且设计方式简单,非常方便硬件实现。算法是Guido Bertoni、Joan Daemen、Michael Peters和GilesVan Assche在2008年10月提交的,Keccak512算法采用了标准的sponge结构,可将任意长度的输入比特映射成固定长度的输出比特,该算法速度非常快速,在英特尔酷睿2处理器下的平均速度为12.5周期每字节。
如图9-11所示,在海绵结构的吸收阶段,每个消息分组与状态内部的r比特进行异或,然后与后面固定的c比特一起封装成1600比特的数据进行轮函数 f f f处理,然后再进入挤压过程。在挤压阶段,可以通过迭代24次循环产生n比特固定输出长度的Hash值,每个循环R只有最后一步轮常数不同,但是该轮常数在碰撞攻击时经常被忽略不计。该算法被证明具有很好的差分性质,至目前为止第三方密码分析没有显示Keccak512有安全弱点。量子计算机下针对Keccak512算法的第一类原像攻击复杂度是2256,量子计算机下针对Keccak512算法的第二类原像攻击复杂度是2128,因此采用Keccak512算法的lnterValue可以抵抗量子计算下的GROVER算法攻击。
2.抗量子攻击的数字签名算法
哈希算法可以保证交易数据不被篡改,但是无法保证对数据和摘要同时的替换攻击,同时也不能保证交易数据的不可否认性,数字签名算法涉及公钥、私钥和钱包等工具,它有两个作用:一是证明消息确实是由信息发送方签名并发发出来的,保证不可否认性;二是确定消息的完整性。数字签名技术是将摘要信息用发送者的私钥加密,与原文一起传送给接收者。接收者只有用发送者的公钥才能解密被加密的摘要信息,然后用哈希算法对收到的原文产生一个摘要信息,与解密的摘要信息对比。如果相同,则说明收到的信息是完整的,在传输过程中没有被修改,否则说明信息被修改过,因此数字签名能够验证信息的完整性并保证信息的不可否认性。
现有区块链系统大都采用椭圆曲线数字签名方案ECDSA。ECDSA是基于椭圆曲线的DSA签名算法而提出的,作为ANSI、IEEE、NIST和ISO的标准,ECDSA具有系统参数小、处理速度快、密钥尺寸小、抗攻击性强和带宽要求低等优点,比如160bit ECC与1024 bit RSA、DSA有相同的安全强度,而224bit ECC则与2048bit RSA、DSS具有相同的安全强度。但是量子计算机下有针对ECDSA签名算法非常高效的SHOR攻击算法,SHOR算法适用于解决大整数分解、离散对数求逆等困难数学问题,导致ECDSA签名算法在量子攻击下相当不安全。目前抗量子SHOR算法攻击的公钥密码体制主要包括基于格理论的公钥密码、以McEliece公钥密码为代表的基于编码公钥体制和以MQ公钥密码为代表的基于多变量多项式的三类。McEliece公钥密码体制的安全性基于纠错码问题,安全性强,但计算效率低。MQ公钥密码体制,即多变元二次多项式公钥密码体制,基于有限域上的多变元二次多项式方程组的难解性,在安全性方面的缺点比较明显。相比之下,基于格理论的公钥加密体制算法简洁、计算速度快、占用存贮空间小。lnterValue采用基于格理论的签名算法NTRUSign-251。

已经证明NTRUSign-251签名算法的安全性最终等价于求一个502维整数格巾的最短向量问题,而格中最短向量问题是在SHOR攻击算法下无效的,在量子计算机下也没有其他的求解快速算法,目前最好的启发式算法也是指数级的,攻击NTRUSign-251签名算法的时间复杂度约为2168,因此采用NTRUSign-251算法的InterValue可以抵抗量子计算下的SHOR算法攻击。
参考链接:InterValue:新型抗量子攻击密码算法解析
参考文献:《DAG区块链技术-原理与实践》
InterValue分层共识机制
InterValue设计了基于哈希网数据结构的HashNet共识机制和基于随机选择函数的拜占庭协商(BA-VRF)共识机制,提出了基于HashNet的增强DAG共识和用于公证人选择的BA-VRF共识机制相结合的双层共识机制,在InterValue1.0版至3.0版中,由于基于HashNet的增强DAG共识实现较为闲难,因此先实现基础DAG共识和BA-VRF共识相结合的双层共识机制。交易并发量高、交易确认速度快,可快速构建面向不同应用场景的生态体系。自lnterValue4.0版开始,基础DAG共识将替换为基于HashNet的DAG共识,InterValue的共识机制为HashNet的DAG共识和IBA-VRF共识机制相结合的双层共识机制。
1.HashNet共识
(1) HashNet基本思想
已有的Hashgraph共识算法通过Gossip网络和虚拟投票策略达成交易顺序的共识,该共识的前提是要求网络节点超过2n/3的投票能力具有对famous witness事件的一致投票结果,其中n是全网的当前投票能力总和,该投票能力通常为节点的持股数量。由于采用了本地投票策略,Hashgraph可以实现较快的交易确认速度。然而该方法存在以下问题:
-
在广域网环境中,节点波动性较强,全网的投票能力n的波动也随之增强,这可能导致系统长时间无法找到满足2n/3投票一致的事件,从而无法达成共识。
-
受节点稳定性、处理能力、带宽等因素影响,不同节点处理事件的能力差别较大。若系统中存在大量能力较弱的节点参与投票,同样会造成系统长时间无法达成共识。
-
广域网环境下,节点频繁波动可能导致节点被分割成多个子网。根据Gossip邻居交换协议,节点会周期性剔除长时间未更新的邻居。当邻居稳定后,节点可在子网内达成共识。此时若子网规模较小,很容易使恶意节点在同一轮产生两个以上famous witness事件,从而产生双花交易。
-
随着系统规模增大,节点收到的同步信息越来越多,可以预见系统的吞吐率会随节点数目的增加而降低。
基于以上挑战性问题,我们提出HashNet共识机制。如图9-7所示,HashNet采用基于双层Gossip拓扑的Hashgraph共识。上层Gossip网络中的节点称为全节点(full node),负责维护全网交易一致性。为了保持网络稳定性,全节点通过DPOS的方式选举出来,全节点之间通过Hashgraph达成共识。每个全节点从下层网络中接收两类数据:下层网络内部节点的交易数据和跨子网交易数据。下层Gossip网络巾的节点称为局部全节点(local full node),负责维护子网内部交易一致性。与全节点不同,局部全节点的选举则综合考虑其Token数量、处理能力、带宽、在线时长等因素,局部全节点之间通过Hashgraph达成子网交易共识。

Hash Net共识机制的主要优势在于:
-
全节点和局部全节点具有较强的稳定性和处理能力,能够有效避免Hashgraph长时间无法达成共识的问题,也能够避免因网络被分割造成的恶意节点攻击问题。
-
采用双层Gossip拓扑对节点分片,局部全节点只需要同步其所属子网内部的交易,保证了系统具有较好的可扩展性。
(2) 节点类型
HashNet中节点共分为四类:全节点、局部全节点、轻节点和微节点。
- 全节点:负责维护全网交易数据,并保证全网交易顺序的一致性。
- 局部全节点:负责维护子网交易数据,并保证子网交易顺序一致性。
- 轻节点:通常为轻量级客户端钱包,该节点可通过局部全节点做代理完成数据请求和发送。
- 微节点:通常为智能物联网设备,该节点可通过局部全节点做代理完成数据请求和发送。
(3)节点维护机制
在HashNet中,全节点和局部全节点的稳定性和处理能力对交易的确认速度会产生较大的影响。为此,我们设计了可信且可激励的节点加入和更新机制。
A. 全节点维护机制
基于DPOS的全节点加入机制
由于全节点需要维护全网数据信息,其稳定性至关重要。为此,我们设置可动态调整数量的全节点。其基本流程如下:
-
由INVE基金会发布全节点要求的最低配置及扩容能力。
-
申请者将节点配置信息发给基金会审核。
-
对于审核通过的节点,全网的Token持有者可投票选择信任的申请者。
-
根据DPOS排名,选择前N位申请者成为全节点,并建立HashNet顶层Gossip拓扑网络。
基于信誉值的全节点更新机制
正常情况下,所有全节点能够100%保持在线。然而,固定不变的全节点有两点安全隐患:一是固定全节点之间进行串谋;二是有一些非正常情况,全节点的软件bug,网络拥塞或者有恶意行为。这就需要更新全节点以保证共识的正确性。为此,HashNet协议基于节点的稳定性和恶意可能性为全节点设置动态信誉值。在每个周期中,信誉值最低的N/6个节点被新一轮的DPOS排名靠前的全节点申请者替换掉。
B. 局部全节点维护机制
基于加权得分的局部全节点加入机制
相对于全节点,局部全节点规模较大,且需要周期性审核。为此,我们采用POS+POW+POB+POO的方式向动判定申请者的信誉、处理能力、带宽能力和稳定性。
具体来说:
-
POS为权益证明,即申请人向全节点提交其代币数量的证明;
-
POW为工作量证明,即申请人从全节点随机领取一个特定难度的哈希求解问题,并向全节点记录其计算时间从而评估其计算能力;
-
POB为节点带宽证明,全节点向申请人发送背靠背的数据报文以测量其带宽能力;
-
POO为在线证明,即申请人将自己的最伏在线时间长度提交给全节点。
最终,申请人的综合得分可表示为:
Score=α1POS+α2POW+α3POB+α4POO
其中,αi代表相应考虑因素的权重。全节点在获得所有申请人的综合得分后,根据其件名选择得分靠前的申请人作为最终的局部全节点。
基于分片的局部全节点更新机制
局部全节点周期性向全节点更新其综合得分,当新一轮申请开始后,已有的局部全节点和新的申请人共同竞争下一轮局部全节点。并向全节点通过分片完成更新。
(4) 分片机制
全节点在审核通过所有下一轮局部全节点申请人后,需要对这些申请人分片以保证系统的可扩展性。
A. 分片数量
分片数量是一个需要仔细权衡的变量。分片数量过少,系统的交易确认吞吐率不能有效提升;分片数量过多,底层子网遭到1/3恶意节点攻击的可能性增大,且顶层全节点网络需承担较多的跨子网交易通信。为此,我们设定最小分片的局部全节点数量为1000。极端情况下,若局部全节点数量小于l000,则分片数量为1。
B. 分片细节
为了对局部全节点分片,顶层全节点收到所有申请后,利用Gossip协议随机选择一个全节点对下一轮申请人进行分片。具体来说,在顶层Gossip网络中保存一个虚拟令牌,持有该虚拟令牌的全节点称为责任全节点,并负责分片操作。为了挑选责任全节点,每个全节点产生一个随机数。通过Gossip的邻居交换协议,能够获得产生中间位置随机数的节点,该节点即是下一轮的责任全节点。
分片时,责任全节点依据最小分片规模确定分片数量,将所有局部全节点随机划分至各个子网。每个子网有一个唯一标识符subnetid,相应的子网内的节点id以其子网subnet_id作为前缀。假设网络中有4个子网,其子网id分别是00,01,10,11。在00子网内包含四个局部全节点,则相应的节点id为0000,0001,0010,0011。通过前缀路由方式,任意两个节点能够依据其节点id获得对方的子网id信息。责任全节点为每个子网及其节点分配完id后,还需要为每个局部全节点分配初始邻居节点。这样,局部全节点可依据其邻居列表自动完成子网重建过程。
C. 交易确认细节
交易可根据输入和输出地址划分为以下四类情况。
-
情况1: input(1)–>output(1),输入和输出来自于同一分片1;
-
情况2: input(1)–>output(2) + output(3),输入来自分片1,向分片2和3分别产生一个输出;
-
情况3: input(1) + input (2)–>output(3),输入来自分片1和2,输出为分片3;
-
情况4: input (1)+ input (2)–>output(3)+output(4),输入来向分片1和2,输出为分片3和4。
情况1输入和输出来自于同一分片,只需要在子网内通过Hashgraph达成共识,然后其交易信息即可被确认。
情况2的输入和输出不在同一个分片,需要同时在输入和输出分片中通过Hashgraph达成共识。例如分片1中的Alice向分片2中的Bob和分片3中的Lily分别发送2个INVE和3个INVE。首先,在分片1中产生一笔交易减去Alice账号中的5个INVE,创建一个由Alice签名的收据。通过Hashgraph,分片1确认该收据并将收据信息发送给HashNet顶层的全节点。顶层全节点收到该收据后,产生两笔交易:向Bob的账号增加2个INVE,向Lily的账号增加3个INVE。这两笔交易附加之前的收据信息一起分别发送给分片2和分片3。在分片2和3中,通过Hashgraph达成共识后,确认该收据未被消费,Bob和Lily的账号分别增加2个INVE和3个INVE。为了保证交易原子性,分片2和3在完成确认后需要向顶层全节点发送收据表示已消费的消息,然后由顶层全节点转发该消息给分片1。假定分片2和3因网络等原因无法完成交易确认,顶层全节点在等待超时后,向分片1发送收据未被消费且增加5个INVE给Alice的交易消息,然后由分片1执行该交易。
情况3和4中输入来自于不同分片,因此需要得到多个分片的确认才能继续交易,我们引人“锁定”和“释放”两个操作保证交易的原子性。例如分片1中的Alice和分片2中的Bob共同向分片3中的Lily支忖5个INVE,其中Alice支付2个INVE,Bob支付3个INVE。假设该交易信息由分片1产生。第一步,该交易信息在分片1中通过Hashgraph达成共识,此时Alice账号zhong 2个INYE被“锁定”并产生由Alice签名的有效性证明,发送该有效性证明给顶层全节点;第二步,顶层全节点将交易信息路由给分片2,由分片2通过Hashgraph达成共识,若Bob账号中有足够余额,则3个INVE会被“锁定”并产生由Bob签名的有效性证明,发送该有效性证明给顶层全节点;第三步,顶层全节点收到Alice和Bob的有效性证明后,分别向分片1和2发送两笔交易:从Alice账号中减去2个INVE,从Bob账号中减去3个INVE,井生成收据返回给全节点;第四步,全节点收到双方收据后,向分片3发送增加5个INVE给Lily的交易信息,并附加上收据;第五步,在分片3中该交易达成共识后,确认收据未被消费,成功向Lily增加5个INVE。为了保证交易原子性,该过程中若出现Bob没有足够余额、不能增加5个INVE给Lily等情况,顶层全节点可向分片1和2发送消息完成状态回滚。
D.事件全排序
理论上来说,上述分片策略已经能够实现子网内交易和跨子网交易顺序一致性。然而,局部全节点由于需要周期性切换分片,难以对所有事件全排序。为此,我们利用顶层全节点实现所有事件的全排序,其基本思想是子网局部全节点周期性将其已确认的交易信息按顺序打包发送给顶层全节点,顶层全节点利用其已存储的跨子网交易顺序达成全网交易共识。
具体来说,每个分片根据Hashgraph共识算法对其已确认的交易信息排序。每个分片周期性随机选择一个顶层全节点,将该分片已确认且顶层全节点未确认的交易打包到一个事件中并发送给顶层全节点。顶层全节点收到该事件后,利用Gossip协议在顶层网络中分发该事件。由于全节点记录了跨子网交易的顺序,因此可以对各个分片的交易实现全排序。假设系统中共包含三个分片,每个分片上经过Hashgraph共识后所有事件排序如图9-8所示,其中白色节点代表片内交易,其余颜色节点表示跨子网交易,事件之间的连线表示跨子网交易的顺序。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M88TUHB3-1597757819537)(2-2.jpg)]
即b2发生在e1之前,d1发生在c2之前,b3发生在d2之前。为了对所有事件全排序,我们采用自底向上扫描的排序方法。其基本思想是:依次遍历每个分片的事件,若当前事件有依赖且尚未被遍历则跳过该分片。在图9-8中,首先遍历分片1,从a1至e1,由于e1依赖于b2且b2尚未被遍历,因此切换至分片2;分片2中a2、b2没有依赖事件,c2的依赖事件d1已被遍历,d2的依赖事件b3没有被遍历,因此切换至分片3;分片3中所有事件没有依赖;此时切换至分片1获得e1, 切换至分片2获得d2和e2。因此所有事件的全排序结果为:
a1,b1,c1,d1,a2,b2,c2,a3,b3,c3,d3,e3,e1,d2,e2。
E.理论分析
定理:假设局部全节点总数为N,每个片内的局部全节点总数为间,则全网的分片数量为C=N/N0。假设单个子网内交易吞吐率为 α \alpha α,任意两个子网之间交易吞吐率为 β \beta β。HashNet 的交易吞吐率为:
f ( C ) = 2 α + β 2 C + β ( C 2 − C − 1 ) 2 f(C) = \frac{2\alpha+\beta}{2C} + \frac{\beta(C^2-C-1)}{2} f(C)=2C2α+β+2β(C2−C−1)
由上式可知, f ( C ) f(C) f(C)的二阶导数大于0,因此, f ( C ) f(C) f(C)有最小值,分片的数量越多,系统中交易吞吐率越高。
2.BA-VRF共识
基于可验证随机函数的拜占庭协商共识(BA-VRF)是一种基于可验证随机函数( Verifiabl e Random Function, VRF)和BA算法构建的共识机制,该共识机制能够随机选出少量全节点作为公证节点,井确定公证节点的优先级。
BA-VRF每分钟执行一次,每次达成共识将随机选出若干全节点作为公证节点,公证节点有权发送公证单元,公证单元须满足DAG共识中的父子引用规则。公证节点发送的公证单元成为稳定主链的单元后,该公证节点可以获得公证奖励。当交易活跃时,新单元不断产生,则公证节点会及时获得公证奖励;当交易不活跃时,极端情况下一分钟内没有新单元产生,已经发送公证单元的节点在发送的公证单元成为稳定主链单元时获得公证奖励,没有发送公证单元的节点不获得公证奖励。
(1)共识状态
BA-VRF有最终共识和临时共识两种状态。
如果一个全节点达到最终共识,意味着其他全节点也达到了最终共识或者在同一轮中的临时共识必须同意这一共识结果,无论强同步假设是否成立。而临时共识意味着其他全节点可能在其他公证单元上达到了临时共识,没有全节点已经达到了最终共识。所有公证单元都必须直接或间接引用之前生成的公证单元,这可以确保BA-VRF的安全性。
BA-VRF产生临时共识有两种情况。首先,如果网络是强同步的,一个攻击者可以以一个很小的概率让BA-VRF达到临时共识。此情况下,BA-VRF不会达成最终共识,也不能确认网络是强同步的。但经过几轮后,很大概率上会达到最终共识。第二种情况是,网络是弱同步的,整个网络都被攻击者控制。此情况下,BA-VRF将达到临时共识,选举出不同的公证节点集合,形成多分叉共识。这能够避免BA-VRF达到最终共识,因为全节点被分成了不同的组,各组之间并不同意对方。为了恢复活性,BA-VRF将被周期性地执行,直到消除意见分歧。一旦网络恢复到强同步状态,将会在短时间内达成共识。
(2)全节点选择
抽签算法是基于可验证随机函数(VRF)构造而成的,可根据每个参与BA-VRF共识的全节点的权重选出这些节点的随机子集。某全节点被选中的概率约等于自身权重与总权重的比值。抽签的随机性源于VRF函数和一个可公开验证的随机种子,每个全节点可根据随机种子验证自己是再被选中。
VRF函数定义:给定任意字符串,VRF函数输出u合希值和证明结果。
所有全节点执行抽签算法来确定向己是否被赋予公证权,被选中的全节点通过P2P网络向其他全节点广播自己的抽签结果。需要说明的是,抽签选择全节点的概率与全节点向身权重成正比,以抵御Sybil攻击。权重大的全节点可能会被选中多次,为此抽签算法会输出全节点被选中的次数。如果一个全节点被多次选中,那么它就被当成多个不同的全节点。
(3)拜占庭协商
拜占庭协商(BA)能为每一个被选中的全节点确定公证优先级并提供公证优先级的证明。达成拜占庭共识需要执行多个步骤,BA算法会被执行多次。每次协商者都从抽签开始,所有全节点都去查看它们是否被选中成为当前BA的参与者。参与者广播一个包含选择公证优先级的消息。每一个全节点用它们收到的公证优先级消息去初始化BA算法。上述过程将被不断重复执行,直到某轮协商有足够多的全节点达成共识。在不同全节点之间,BA算法并不是同步的,每个全节点发现之前的步骤结束后应立即查看新的参与者选举结果。只有全节点在某轮协商中投票并最终达成共识,它才可以参与下一轮协商。
每次协商者都从抽签开始,所有全节点都去查看它们是否被选中成为当前BA的参与者。参与者广播一个包含选择公证优先级的消息。每一个全节点用它们收到的公证优先级消息去初始化BA算法。上述过程将被不断重复执行,直到某轮协商有足够多的全节点达成共识。在不同全节点之间,BA算法并不是同步的,每个全节点发现之前的步骤结束后应立即查看新的参与者选举结果。只有全节点在某轮协商中投票并最终达成共识,它才可以参与下一轮协商。
BA算法的一个重要特征是,参与者不需要维护私有状态,仅有私钥,所以参与者每个步骤之后都可以被更换,以减少对参与者的攻击。当网络是强同步的,BA算法保证如果所有的诚实全节点以相同内容进行初始化,那么可以在很少的交互步骤之内达到最终共识。此情况下,即使存在少量攻击者,所有的诚实全节点也将在有限交互步骤下达到最终共识。