Selenium的使用:模拟登陆爬取知乎
Selenium的使用:模拟登陆爬取知乎页面搜索功能搜索关键字抓取知乎问题页面及知乎专栏文章
- 爬虫思路
- 知识点
- 前期准备
- 正文
- 小结
爬虫思路
通过知乎的搜索功能实现输入关键字搜索并将得到页面的所有数据进行存储,保存的数据如下:
Problem 问题
ProblemUrl 问题的链接
ProblemTime 发布问题的时间
Author 提问人
AuthorUrl 提问人的个人主页链接
知识点
- Selenium 模拟登陆并使用cookies访问
- ActionChains 模拟用户进行滚动和点击操作
- html文件结构化
前期准备
安装库
pip install selenium 浏览器自动化框架
pip install fake_useragent 随机请求头
pip install lxml
正文
- 目标:模拟登陆并获取到登陆状态的cookies:
要点:通过Selenium调用浏览器进行登陆操作
from selenium import webdriver
from newspider.connectionHbase import zhihuHbase #本地自己写的连接Hbash
class zhihuSpider(object):
def __init__(self):
self.userAgen = UserAgent().chrome
version = int(str(self.userAgen).split("Chrome/")[1][:2]) #得到当前获取到的浏览器版本
while version < 35: #旧版本的浏览器无法访问知乎,因此对浏览器头进行版本筛选处理
self.userAgen = UserAgent().chrome
version = int(str(self.userAgen).split("Chrome/")[1][:2])
# print(self.userAgen)
options = webdriver.ChromeOptions()
options.add_argument('user-agent={}'.format(self.userAgen)) # 添加随机请求头
options.add_argument('--headless') # 进入无头模式
self.driver = webdriver.Chrome()#用于登录
self.HeadlessDriver = webdriver.Chrome(chrome_options=options) #用于爬取
self.header = {'User-Agent': self.userAgen}
def loginUrl(self):
self.driver.get("https://www.zhihu.com/signin?next=%2F")#知乎登录页面
input("请完成登陆操作后按回车继续执行爬虫")
cookies = self.driver.get_cookies() # 获取登陆的Cookies
cookie_dict={}
for cookie in cookies:
cookie_dict[cookie['name']] = cookie['value']
print(cookie_dict)
return self.SearchPage(cookie_dict)
改进:可添加以下代码
调用键盘按键操作实现自动化输入账号密码并模拟鼠标点击实现登录
from selenium.webdriver.common.keys import Keys #模拟键盘
from selenium.webdriver.common.action_chains import ActionChains #模拟鼠标
- 目标:访问搜索页面进行搜索关键字(可不使用Cookies,因是否有登陆页面都没区别)
要点:因知乎采用下拉滚动条加载新内容,因此使用Selenium进行访问链接并进行多次滚动操作
import time
def SearchPage(self,cookie_dict):
#输入搜索的内容
SearchUrl = "https://www.zhihu.com/search?type=content&q={}".format("xxx")
self.driver.get(SearchUrl)
# 将页面滚动到最后,执行多次
for i in range(10):
self.driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')#滚动到页面最底部,使自动加载新内容
time.sleep(1)
html = self.driver.page_source
response = etree.HTML(html)
print(response)
- 目标:获取页面所有问题链接,并使用带登录状态的Cookies一一访问得到response
要点:搜索得到的内容分别为两大板块:知乎板块、专栏板块
import requests
#知乎板块
plate = response.xpath('//h2/div/a/@href')
print("{}{}".format("知乎板块的数量:", len(plate)))
for i in plate:
#ProblemUrl为问题编辑日志的链接,该页面里有关于该问题的具体编辑时间,这里要存储的是发布的问题时间
ProblemUrl = "{}{}{}{}{}".format("https://www.zhihu.com/",i.split("/")[1],"/",i.split("/")[2],"/log")
time.sleep(0.5) #放慢爬取速度
ProblemResponse = requests.get(ProblemUrl, cookies=cookie_dict, headers=self.header)
ProblemHtml = ProblemResponse.text
ProblemResponse = etree.HTML(ProblemHtml)
self.ProblemPage(ProblemUrl,ProblemResponse,ProblemHtml)#调用知乎板块写入函数
#知乎专栏板块
columnPlate = response.xpath('//h2/a/@href')
print("{}{}".format("专栏板块的数量:", len(columnPlate)))
for j in columnPlate:
ProblemUrl = "{}{}".format("https:", j)
time.sleep(0.5)
self.getcolumnPlate(ProblemUrl) #调用知乎专栏的函数
- 目标:处理知乎板块的页面response:
要点:部分问题发布人为匿名用户,不存在用户链接,因此需要做个try异常处理

def ProblemPage(self,ProblemUrl,ProblemResponse,ProblemHtml):
ProblemTimeList = ProblemResponse.xpath('//div/time/text()') #问题编辑时间有多个,这里取最早的时间即发布时间
Problem = ProblemResponse.xpath('//div/h2/a/text()')[0]
ProblemUrl = ProblemUrl
ProblemTime = ProblemTimeList[-1]
try:#部分问题发布人为匿名用户,因此不存在用户链接
author = ProblemResponse.xpath('//div/div/a[@target="_blank"]/text()')[-1]
authorUrl = "{}{}".format("https://www.zhihu.com",ProblemResponse.xpath('//div/div/a[@target="_blank"]/@href')[-1])
except IndexError:#为匿名用户
author = ProblemResponse.xpath('//div[@class="zm-item"]/div/a/text()')[-1]
authorUrl = None
# print(ProblemHtml)
# print("{}{}".format("问题:",Problem))
# print("{}{}".format("问题链接:", ProblemUrl))
# print("{}{}".format("发布问题的时间:", ProblemTime))
# print("{}{}".format("提问人:", author))
# print("{}{}".format("提问人的主页链接:", authorUrl))
return self.storage(Problem, ProblemUrl, ProblemTime, author, authorUrl)#调用存储函数
5.目标: 使用专栏板块的链接,获取信息
要点:二次及多次编辑的专栏文章的显示时间将为最后编辑时间,鼠标左击将得到发布时间
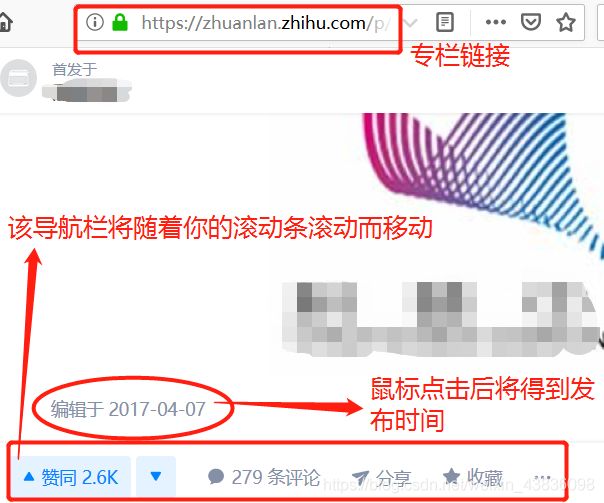
因导航栏而引发的坑
在通过使用模拟鼠标右键单击实验中发现
from selenium.webdriver.common.action_chains import ActionChains
leftClick = driver.find_element_by_class_name(“ContentItem-time”) #编辑时间处
actions = ActionChains(driver)
actions.move_to_element(leftClick).context_click().perform() #模拟鼠标移动到编辑时间处进行单击右键
解决方法:通过锁定到时间处的下方标签处并使用模拟鼠标移动的方式移动到时间处左击
leftClick = self.HeadlessDriver.find_element_by_id(“Popover4-toggle”)

通过模拟鼠标移动的方式,将鼠标移动到时间处,然后进行左键单击操作
actions = ActionChains(self.HeadlessDriver)
actions.move_to_element_with_offset(leftClick,50,-40).click().perform()

def getcolumnPlate(self,ProblemUrl):
self.HeadlessDriver.get(ProblemUrl)#带随机请求头以及Cookies的浏览器
leftClick = self.HeadlessDriver.find_element_by_id("Popover4-toggle")#发布时间下边的标签位置
actions = ActionChains(self.HeadlessDriver)
actions.move_to_element_with_offset(leftClick,50,-40).click().perform() #将模拟鼠标锁定到指定位置并移动(50,-40)以此移动到发布时间的位置进行左键点击操作
html = self.HeadlessDriver.page_source
#print(html)
columnResponse = etree.HTML(html)
Problem = columnResponse.xpath('//h1[@class="Post-Title"]/text()')[0]
ProblemUrl = ProblemUrl
author =columnResponse.xpath('//a[@class="UserLink-link"]/text()')[0]
authorUrl = "{}{}".format("https:",columnResponse.xpath('//a[@class="UserLink-link"]/@href')[0])
untreatedProblemTime =columnResponse.xpath('//div[@class="ContentItem-time"]/text()')[0]
#处理部分时间为“发布于昨天XX:XX”
if "昨天" in untreatedProblemTime:
t = time.time() - 3600
t = time.strftime('%Y-%m-%d', time.localtime(t))
ProblemTime = "{}{}".format(t,str(untreatedProblemTime).split("昨天")[1])
elif "-" not in untreatedProblemTime:
t = time.time()
t = time.strftime('%Y-%m-%d', time.localtime(t))
ProblemTime = "{}{}".format(t,str(untreatedProblemTime).split("于 ")[1])
else:
ProblemTime = str(untreatedProblemTime).split("于 ")[1]
# print("{}{}".format("专栏板块:", Problem))
# print("{}{}".format("专栏板块:", ProblemUrl))
# print("{}{}".format("专栏板块:", ProblemTime))
# print("{}{}".format("专栏板块:", author))
# print("{}{}".format("专栏板块:", authorUrl))
return self.storage(Problem,ProblemUrl,ProblemTime,author,authorUrl)#调用存储函数
小结
以上,我们实现了如下逻辑:
__init__方法,定义初始常量
loginUrl方法,实现了调用浏览器登录并保存Cookies
SearchPage,实现了通过滚动滚动条得到完整的html,并抓取所有知乎问题及专栏的链接,并对知乎问题的链接进行带Cookies及随机浏览器头的访问请求,得到response。
ProblemPage,实现了对知乎问题页面的内容抓取,得到我们想要的数据。
getcolumnPlate,实现了调用浏览器模拟鼠标点击,得到文章发布时间并保存完整的html,从而得到我们想要的数据。