第三课 欠拟合与过拟合的概念
一.欠拟合与过拟合
上次课的例子中,用x1表示房间大小。通过线性回归,在横轴为房间大小,纵轴为价格的图中,画出拟合曲线。回归的曲线方程为:
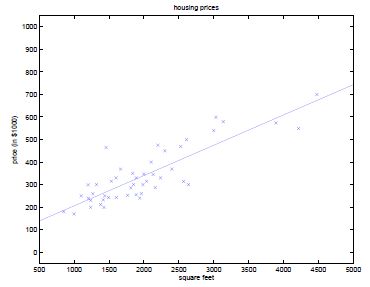
若定义特征集合为:x1表示房子大小,x2表示房子大小的平方,使用相同的算法,拟合得到一个二次函数,在图中即为一个抛物线,即:
以此类推,若训练集有7个数据,则可拟合出最高6次的多项式,可以找到一条完美的曲线,该曲线经过每个数据点。但是这样的模型又过于复杂,拟合结果仅仅反映了所给的特定数据的特质,不具有通过房屋大小来估计房价的普遍性。而线性回归的结果可能无法捕获所有训练集的信息。
所以上诉的三种拟合方法中,第二种最好。第一种为欠拟合的情况,第二种为过拟合的情况。
欠拟合:在这种情况下,数据中的某些非常明显的模式没有被成功的拟合出来。
过拟合:这种情况下,算法拟合出的结果仅反映了所给的特定数据的特质。
参数学习算法(parametric learning algorithm)
定义:参数学习算法是一类有固定数目参数,以用来进行数据拟合的算法。设该固定的参数集合为 。例如:上一节学习的线性回归参数
。例如:上一节学习的线性回归参数
非参数学习算法(Non-parametric learning algorithm)
定义:一个参数数量会随m(训练集大小)增长的算法。通常定义为参数数量随m线性增长。换句话说,就是算法所需要的东西会随着训练集合线性增长,算法的维持是基于整个训练集合的,即使是在学习以后。
二.局部加权回归算法(Locally Weighted Regression)
一种特定的非参数学习算法。也称作Loess。
算法思想:
假设对于一个确定的查询点x,在x处对你的假设h(x)求值。
算法流程:
1) 拟合出,使 最小
最小
2) w为权值,有很多可能的选择,比如:

- 其意义在于,所选取的x(i)越接近x,相应的w(i)越接近1;x(i)越远离x,w(i)越接近0。直观的说,就是离得近的点权值大,离得远的点权值小。
- 这个衰减函数比较具有普遍意义,虽然它的曲线是钟形的,但不是高斯分布。
- 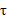 被称作波长函数,它控制了权值随距离下降的速率。它越小,钟形越窄,w衰减的很快;它越大,衰减的就越慢。
被称作波长函数,它控制了权值随距离下降的速率。它越小,钟形越窄,w衰减的很快;它越大,衰减的就越慢。
3) 返回
总结:对于局部加权回归,每进行一次预测,都要重新拟合一条曲线。但如果沿着x轴对每个点都进行同样的操作,你会得到对于这个数据集的局部加权回归预测结果,追踪到一条非线性曲线。
局部加权回归的问题:
由于每次进行预测都要根据训练集拟合曲线,若训练集太大,每次进行预测的用到的训练集就会变得很大,有方法可以让局部加权回归对于大型数据集更高效,详情参见Andrew Moore的关于KD-tree的工作。
三.Logistic回归算法
应用于二分类问题。
之前的回归问题尝试预测的变量y是连续变量,在这个分类算法中,变量y是离散的,y只取{0,1}两个值。一般这种离散二值分类问题用线性回归效果不好。
若y取值{0,1},首先改变假设的形式,使假设得到的值总在[0,1]之间,即:
所以,选取如下函数:
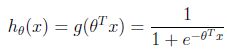
其中:

g函数一般被称为logistic函数或Sigmoid函数,图像如下:

z很小时,g(z)趋于0,z很大时,g(z)趋于1,z=0时,g(z)=0.5
假设给定x以为参数的y=1和y=0的概率:
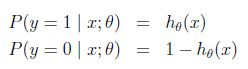
可以简写成:
(上面那个公式用y=0和y=1分别带入可得到原式)
参数的似然性:

求对数似然性:

为了使似然性最大化,类似于线性回归使用梯度下降的方法,求对数似然性对 的偏导,即:
的偏导,即:
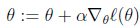
因为求最大值,此时为梯度上升。
偏导数展开:

则:

即类似上节课的随机梯度上升算法,形式上和线性回归是相同的,只是符号相反, 为logistic函数,但实质上和线性回归是不同的学习算法。
为logistic函数,但实质上和线性回归是不同的学习算法。
四 感知器算法
在logistic方法中,g(z)会生成[0,1]之间的小数,但如何是g(z)只生成0或1?
所以,感知器算法将g(z)定义如下:

同样令 ,和logistic回归的梯度上升算法类似,学习规则如下:
,和logistic回归的梯度上升算法类似,学习规则如下:

尽管看起来和之前的学习算法类似,但感知器算法是一种非常简便的学习算法,临界值和输出只能是0或1,是比logistic更简单的算法