matlab 实现基本apriori算法
刚刚学了数据挖掘的这个算法,马上实现下,怕忘掉了。。感觉matlab的好处就是矩阵可以一起进行逻辑运算,不过我没有进行预处理,输入的数据集保存在txt文件里,且都是以0-1矩阵构成的,不考虑出现次数。输出只实现了得到k-频繁项集,没有计算最终的关联规则。。那个感觉要遍历什么的,用矩阵枚举???还没想到怎么弄。。。。
现在就贴贴代码,可能存在很多地方没有考虑到,,希望各位大神指点。。。。。谢谢。。
从k频繁项集得到k+1频繁项集,通过两个k频繁项向量进行或运算得到。。
剪枝判断k+1-候选项的子串是否在k频繁项集中存在,通过向量 异或 xor来判断
统计支持度 提取数据集中指定列 进行与运算 再通过 sum 求和计算 支持度。。
%修改 原来判断两向量是否相等 matlab可以直接用==来判断 如向量 a,b 若用 a==b 等到新的向量 其中若对应位置相等 则为1 否则为0 。。所以好像可以改下下(http://zhidao.baidu.com/question/131185458.html)
% 求真子集 matlab可以用combntns函数 等改 。。
1、init.m
初始化函数,得到1-频繁项集及支持度,输入数据集和最小支持度
function [L A]=init(D,min_sup) %D表示数据集 min_sup 最小支持度
[m n]=size(D);
A=eye(m,n);
B=(sum(D))';
i=1;
while(i<=m)
if B(i)2、apriori_gen.m
function [C]=apriori_gen(A,k)%产生Ck(实现组内连接及剪枝 )
%A表示第k-1次的频繁项集 k表示第k-频繁项集
[m n]=size(A);
C=zeros(0,n);
%组内连接
for i=1:1:m
for j=i+1:1:m
flag=1;
for t=1:1:k-1
if ~(A(i,t)==A(j,t))
flag=0;
break;
end
end
if flag==0 break;
end
c=A(i,:)|A(j,:);
flag=isExit(c,A); %剪枝
if(flag==1)C=[C;c];
end
end
end3、 isExit.m
function flag=isExit(c,A)%判断c串的子串在A中是否存在
[m n]=size(A);
b=c;
for i=1:1:n
c=b;
if c(i)==0 continue
end
c(i)=0;
flag=0;
for j=1:1:m
A(j,:);
a=sum(xor(c,A(j,:)));
if a==0
flag=1;
break;
end
end
if flag==0 return
end
end4、get_k_itemset.m
function [L C]=get_k_itemset(D,C,min_sup)%D为数据集 C为第K次剪枝后的候选集 获得第k次的频繁项集
m=size(C,1);
M=zeros(m,1);
t=size(D,1);
i=1;
while i<=m
C(i,:);
H=ones(t,1);
ind=find(C(i,:)==1);
n=size(ind,2);
for j=1:1:n
D(:,ind(j));
H=H&D(:,ind(j));
end
x=sum(H');
if x
5、主函数 apriori.m
function [L]=apriori(D,min_sup)
[L A]=init(D,min_sup)%A为1-频繁项集 L中为包含1-频繁项集以及对应的支持度
k=1;
C=apriori_gen(A,k) %产生2项的集合
while ~(size(C,1)==0)
[M C]=get_k_itemset(D,C,min_sup)%产生k-频繁项集 M是带支持度 C不带
if ~(size(M,1)==0)L=[L;M]
end
k=k+1;
C=apriori_gen(C,k)%产生组合及剪枝后的候选集
end举例数据集
abc =
1 1 1 1 0
0 1 1 0 1
1 1 1 0 1
0 1 0 1 1
1 1 1 1 0
输入:apriori(abc,3)
输出:
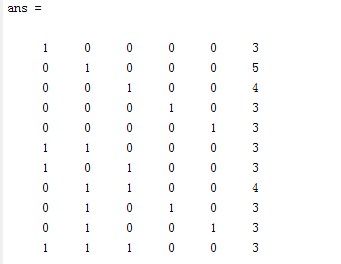
频繁项集+支持度