Python智能对话机器人实现
前言:看了许多大佬的博客,感觉做一个人工智能对话机器人其实不难。当然,从底层开始自己做是不可能的,那得自己研究语音识别算法,神经网络建立模型等等,要掌握一大堆超级高深的数学知识底蕴。今天,我做的只是裁缝,将调用各种API,各种第三库,将这一件衣服给缝的漂漂亮亮的。好了,请看我的!
目录
- 需求说明
- 思路分析
- 前期准备
- 具体实现
- 第一步:
- 第二步:
- 第三部
- 第四步
- 测试项目
- 评价反思
需求说明
用Pyhton做一个机器人,就像小爱同学,天猫精灵一样智能。可以对话,算术,百科,聊天,当然不能像小爱同学一样语音控制操作硬件,咱们只是从纯软件角度进行实现。
思路分析
前期准备
准备好 python 编译器 ,第三方库有 speech_recognition,baidu-aip,requests、json,pyttsx3 . 其中baidu-aip 需要去 https://ai.baidu.com/ 获取secret key,key,appID 三者才能使用baidu-aip 。百度的技术确实牛。
1-2:录音,使用 speech_recognition 包
2-3:百度API 导入模块:pip install baidu_aip
3-4:图灵API 导入requests、json模块
4-5:STT 模块pyttsx3,S它会将文字转为语音
5-6:播放
具体实现
第一步:
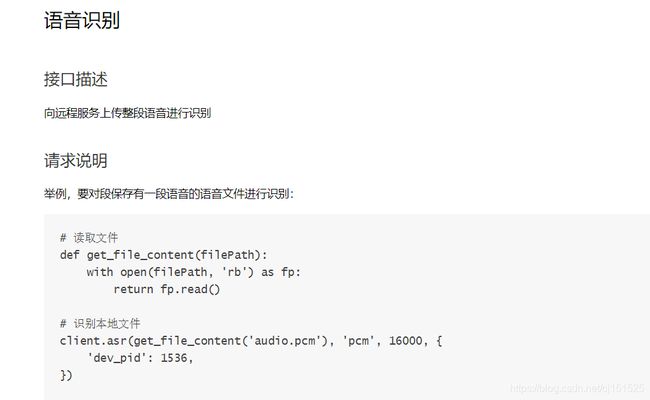
将我们的声音转换成音频文件,要求请看百度API文档,如下图:

使用speech_recognition包进行录音:
import speech_recognition as sr
# Use SpeechRecognition to record 使用语音识别包录制音频
def my_record():
rate = 16000 #录音参数必须满足 16k 采样率
r = sr.Recognizer() #实例化一个识别器r
with sr.Microphone(sample_rate=rate) as source: # 打开麦克风 句柄 source
print("please say something")
audio = r.listen(source) #通过麦克风进行录音
with open("voices/myvoices.wav", "wb") as f: #设置文件名,类型
f.write(audio.get_wav_data()) #将录音数据转换成wav格式写入文件
print("录音完成!")
my_record()
如果有看不懂speech_recognition 的用法或注释或者代码的,请移步官方教程学习speech_recognition 官方文档
第二步:
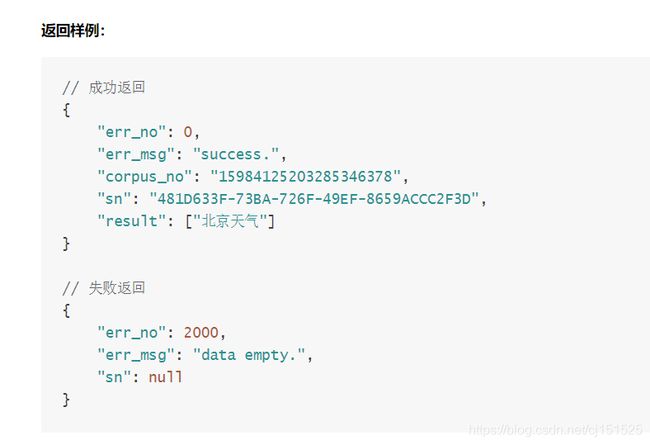
我们已经在上面获取到了音频文件,那要怎么把音频文件转化为文字呢?在这里,我们就需要调用百度的语音识别API接口,同时我们需要安装这个接口包,导入模块:pip install baidu_aip。导入我们需要的模块名,然后将音频文件发送给出去,返回文字。https://ai.baidu.com/docs#/ASR-Online-Python-SDK/b3e9a8da 详细请看技术文档!
懒得看,看下面截图也行:
# 音频文件转文字:采用百度的语音识别python-SDK
# 百度语音识别API配置参数
from aip import AipSpeech
APP_ID = '16847874'
API_KEY = '6XATdS1rGo2NV27jHGemaada'
SECRET_KEY = '0SINmEBfvotQXl1itzrMcwedaxuBaw4h'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
path = 'voices/myvoices.wav'
# 将语音转文本STT
def listen():
# 读取录音文件
with open(path, 'rb') as fp:
voices = fp.read()
try:
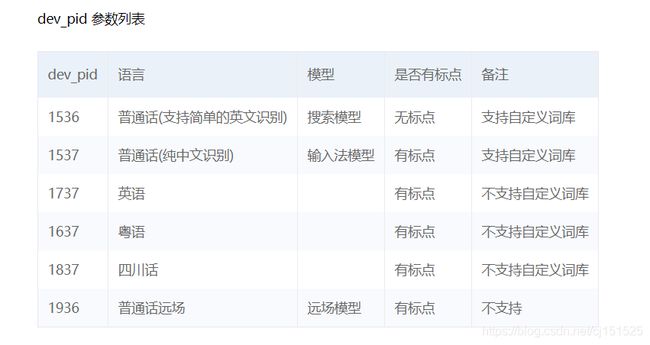
# 参数dev_pid:1536普通话(支持简单的英文识别)、1537普通话(纯中文识别)、1737英语、1637粤语、1837四川话、1936普通话远场
result = client.asr(voices, 'wav', 16000, {'dev_pid': 1537, })
result_text = result["result"][0]
print("you said: " + result_text)
return result_text
except KeyError:
print("KeyError")
第三部
上一步我们已经成功将我们的声音转化为文字了,然后我们再调用图灵机器人的API接口,做自动应答。图灵机器人对中文的识别准确率高达90%,是目前中文语境下智能度最高的机器人。有很多在Python中使用图灵机器人API的博客,但都是1.0版本,本博客介绍的是在Python中使用图灵机器人API v2.0的方法,1.0版本的调用方式已失效。接口文档如下:
https://www.kancloud.cn/turing/www-tuling123-com/718227

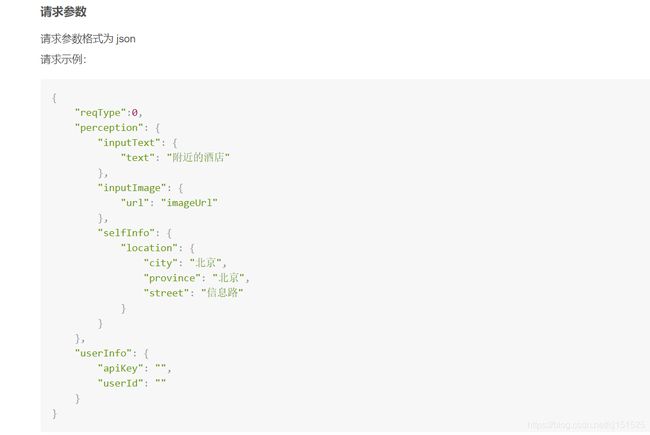
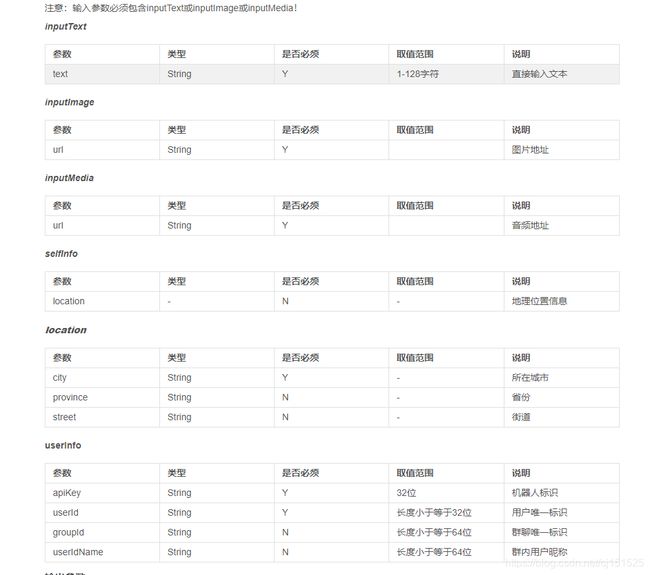
# 与机器人对话:调用的是图灵机器人
import requests
import json
# 图灵机器人的API_KEY、API_URL
turing_api_key = "75854c5f9e6d4be"
api_url = "http://openapi.tuling123.com/openapi/api/v2" # 图灵机器人api网址
headers = {'Content-Type': 'application/json;charset=UTF-8'}
# 图灵机器人回复
def Turing(text_words=""):
#请求
req = {
"reqType": 0, # 输入类型 为文本
"perception": {
"inputText": {
"text": text_words # 输入文本信息
},
"selfInfo": { # 客户端属性
"location": {
"city": "新干县",
"province": "江西省",
"street": "善政二路"
}
}
},
#用户参数
"userInfo": {
"apiKey": turing_api_key, # 你的图灵机器人apiKey
"userId": "cheney007" # 用户唯一标识(随便填, 非密钥)
}
}
req["perception"]["inputText"]["text"] = text_words #给json串赋值
response = requests.request("post", api_url, json=req, headers=headers) #向接口网站发送请求
response_dict = json.loads(response.text)
result = response_dict["results"][0]["values"]["text"] #得到接口的回复进行解析
print("AI Robot said: " + result)
return result
第四步
们得到了图灵机器人的回复之后,就需要把结果转化为语音输出,从而实现语音交互。在python中我们如何将文字转为语音并输出呢?这里就需要用到另一个模块pyttsx3,它会将文字转为语音。
import pyttsx3
def speak(workText):
# 初始化语音
engine = pyttsx3.init() # 初始化语音库
# 设置语速
rate = engine.getProperty('rate')
engine.setProperty('rate', rate - 50)
# 输出语音
engine.say(workText) # 合成语音
engine.runAndWait()
测试项目
import recognizer #录音
import baidu #录音转文字
import turing #文字得到回复
import speak #回复的文字转语音
while(True):
recognizer.my_record()
text=baidu.listen()
respondText=turing.Turing(text)
print(respondText)
speak.Speak(respondText)
评价反思
通过该博客使我学到了不少东西,虽然代码不是自己一行一行写出来的,但是确实跟着作者一步步去实现,去弄懂每一行代码,去查官方文档等等。最重要的不是记住这些代码,而是学会如何解决问题,如何去实现,如何去查找资料文档,如何借助第三方API,等等。这些经验对我个人来说应该是非常宝贵的,终生受益!再次感谢原作者。下面是原作者博客,如作者不希望我二次翻译原文,侵删!
感谢原创作者:
作者:夜空骑士
来源:CSDN
原文:https://blog.csdn.net/NIeson2012/article/details/96476878
版权声明:本文为博主原创文章,转载请附上博文链接!