RMQ、树状数组、线段树
1、RMQ(区间最大值、区间最小值)
RMQ(Range Minimum/Maximum Query),即区间最值查询
O(nlogn)时间内进行预处理,然后在O(1)时间内回答每个查询
①预处理
设A[i]是要求区间最值的数列,F[i,j]表示从第i个数起连续2^j个数中的最大值。(DP的状态)
例如:
A数列为:3 2 4 5 6 8 1 2 9 7
F[1,0]表示第1个数起,长度为2^0=1的最大值,其实就是3这个数。
同理F[1,1]=max(3,2)=3 , F[1,2]=max(3,2,4,5)=5 , F[1,3]=max(3,2,4,5,6,8,1,2)=8;
并且我们可以容易的看出F[i,0]就等于A[i]。(DP的初始值)
我们把F[i,j]平均分成两段(因为F[i,j]包括2^j个数,偶数个数字;
从i到i+2^(j-1)-1为一段,i+2^(j-1)到i+2^j-1为一段(长度都为2^(j-1))
于是我们得到了状态转移方程F[i,j]=max(F[i,j-1],F[i+2^(j-1),j-1])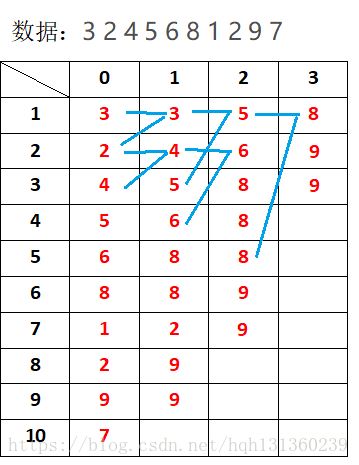
F[i,0]=A[i]
……
F[1,1]=max( F[1,0], F[2,0] )
F[2,1]=max( F[2,0], F[3,0] )
F[9,1]=max( F[9,0], F[10,0] )
……
F[1,2]=max( F[1,1], F[3,1] )
……..
F[1,3]=max( F[1,2], F[5,2] )
②查询假如我们需要查询的区间为(i,j),那么我们需要找到覆盖这个闭区间(左边界取i,右边界取j)的最小幂
(可以重复,比如查询1,2,3,4,5,我们可以查询1234和2345)
因为这个区间的长度为j-i+1,所以我们可以取k=log2(j-i+1)
则有:RMQ(i,j)=max{F[i,k],F[j-2^k+1,k]} (两段F取覆盖要求的区间)
举例说明,要求区间[1,5]的最大值,k=log2(5-1+1)=2,即求max(F[1,2],F[5-2^2+1,2])=max(F[1,2],F[2,2])
举例说明,要求区间[1,7]的最大值,k=log2(7-1+1)=2,即求max(F[1,2],F[7-2^2+1,2])=max(F[1,2],F[3,2])
举例说明,要求区间[1,8]的最大值,k=log2(8-1+1)=3,即求max(F[1,3],F[8-2^3+1,3])=max(F[1,3],F[1,3])
RMQ(1,10) --> k=log(10-1+1)=3
RMQ=max(F[1,3],F[10-2^3+1,3])
RMQ=max(F[ s ,k] , F[ e - 2<
③首先是预处理,如上图所示,F[3,3]为边界,开始下标为3,长度为2^3;其次再进行查询,查询是判断哪两个子区间合并可以得到要查询的区间,如上公式所示,如果刚好覆盖,则两个F相等(区间[1,8]),若不是刚好覆盖,一个从前到后覆盖2^k,一个从后到前预留2^k。
代码
void ST(int n) {
for (int i=1;i<=n;i++)
dp[i][0]=A[i];
for (int j =1;(1<2、树状数组(区间求和,点更新)
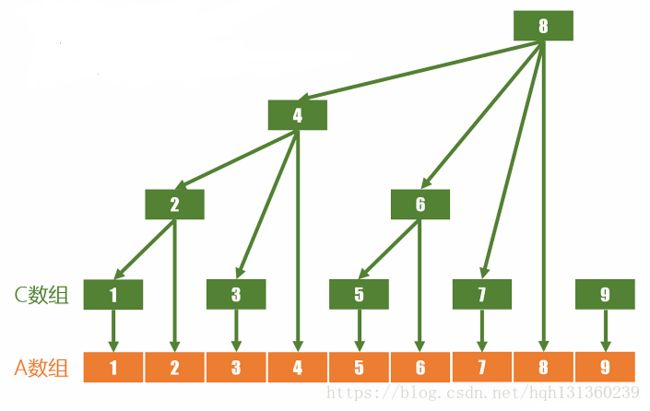
树状数组其实是一个简单的索引表,a[]数组表示输入数据,c[]数组构建树状数组,c[i]都会存储a[i]本身,但是还会存储前面的其它值。lowbit(x)=x&(-x)是求取最低为1的位置(值为1,2,4,8,16)。
比如:对于一个a[i],有哪些c[j]会包含a[i] ?第一个肯定是j=i,依次j=i+lowbit(j).
和二进制有关,是一个神奇的操作。a[1],包含a[1]的有c[1]、c[2]、c[4]、c[8]...........
0001---->0010---->0100--->1000(看和最低位1的位置有关),可以得到数组树状,但是c[i]不是前i个值的和。
如何求前i个值的和:sum+=c[i]、i-=lowbit(i) ,为什么要减,判断c[i]的覆盖范围。
综述:x+=lowbit(x),x的最低位1一直前移,对应c[x]都要包含a[x]。
x-=lowbit(x),x的最低位1,消去。一下回到解放前,也就是c[x]的覆盖范围,x的最低为1可以由前移得到,也就是覆盖范围,如a[1]要加到c[8]上,c[8]的覆盖范围肯定到a[1]。
其实也可以这样理解:预处理得到c数组和求和分开理解,预处理就理解为规则需要加,求和就理解为lowbit(x)表示当前c[x]覆盖多少个数组a的值。
总而言之:第一步预处理,第二步求和、判断覆盖范围。
#include //树状数组,单点修改的区间求和问题
#define N 10005
int a[N],c[N];
int lowbit(int x){
return x&(-x);
}
void add(int i,int n,int value){
a[i]+=value;
while(i<=n){
c[i]+=value;
i+=lowbit(i);
}
}
int Query(int i){
int sum=0;
while(i>0){
sum+=c[i];
i-=lowbit(i);
}
return sum;
}
int main()
{
int n,m,value,x1,x2;
char str[5];
while(~scanf("%d%d",&n,&m)){
for(int i=1;i<=n;i++){
scanf("%d",&value);
add(i,n,value);
}
while(m--){
scanf("%s%d%d",str,&x1,&x2);
if(str[0]=='Q'){ //查询
printf("%d\n",Query(x2)-Query(x1-1));
}else{ //点修改
int tmp=x2-a[x1]; //原数a[x1]改为x2
add(x1,n,tmp);
}
}
}
return 0;
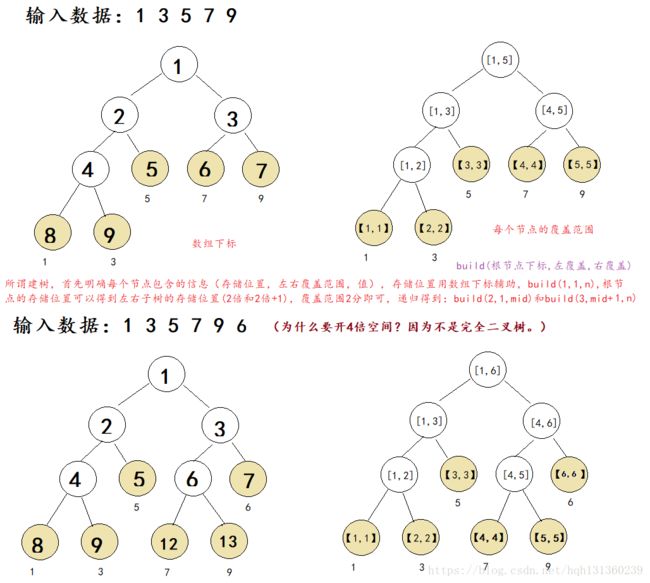
} 何为线段树?就是树节点包含覆盖范围,和范围内你想要得到的值。注意强调一点,线段树不一定事完全二叉树。点更新可以直接找到叶子节点向上更新即可。但是区间更新,找到相应区间需要向上更新和向下更新,为了节省不必要的时间,需要用到延迟更新,就是在节点上加一个标记,需要查询子节点才向下更新。也就是是在查询的时候需要判断一下,是否向下更新。
代码:
#include //poj3468
#define N 100010
struct node{
int l,r;
long long sum;
long long add;
}p[N*4]; //为什么一定要开4倍空间
int a[N];
long long ans;
void build(int o,int l,int r){
p[o].l=l;
p[o].r=r;
p[o].add=0;
if(l==r){ //叶子节点
p[o].sum=a[l];
return;
}
int mid=(l+r)/2;
build(o*2,l,mid);
build(o*2+1,mid+1,r);
p[o].sum=p[o*2].sum+p[o*2+1].sum;
}
void show(int o,int l,int r){
if(l==r){ //叶子节点
printf("%d ",p[o].sum);
return;
}
int mid=(l+r)/2;
show(o*2,l,mid);
show(o*2+1,mid+1,r);
}
//这个是非常难的,如果是单点更新,找到叶子节点即可
//区间更新,找到的是满足区间
void push_down(int o){
//左子树,和需要更新,以及add标记
p[o*2].sum += (p[o*2].r-p[o*2].l+1)*p[o].add;
p[o*2].add += p[o].add;
//同理右子树
p[o*2+1].sum += (p[o*2+1].r-p[o*2+1].l+1)*p[o].add;
p[o*2+1].add += p[o].add;
p[o].add = 0;
}
void update(int o,int l,int r,long long value){
if(p[o].l>r || p[o].r=p[o*2+1].l){
return Query(o*2+1,l,r);
}else{
return Query(o*2,l,p[o*2].r)+Query(o*2+1,p[o*2+1].l,r);
}
}
int main(){
int n,m;
int x1,x2,x3;
char str[5];
while(~scanf("%d%d",&n,&m)){
for(int i=1;i<=n;i++){
scanf("%d",&a[i]);
}
build(1,1,n);
while(m--){
scanf("%s%d%d",str,&x1,&x2);
if(str[0]=='Q'){
ans=0;
printf("%lld\n",Query(1,x1,x2));
}else{
scanf("%d",&x3);
update(1,x1,x2,x3);
}
}
//show(1,1,n);
}
return 0;
}