caffe源码学习——1.熟悉protobuf,会读caffe.proto
要想学习caffe源码,首当其冲的要阅读的,就是caffe.proto这个文件。它定义了caffe中用到的许多结构化数据。
caffe采用了Protocol Buffers的数据格式。
那么,Protocol Buffers到底是什么东西呢?简单说:
Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。
更多有关Protocol Buffers的了解,强烈推荐两篇博文。博文1,博文2.1,博文2.2
感觉可能有必要更细致地学一下protobuf,否则还是看不太懂caffe.proto和其他一些的模型的prototxt
下面更细地看一下protocol buffers的官网教程吧!
1. 先看一个简单的example
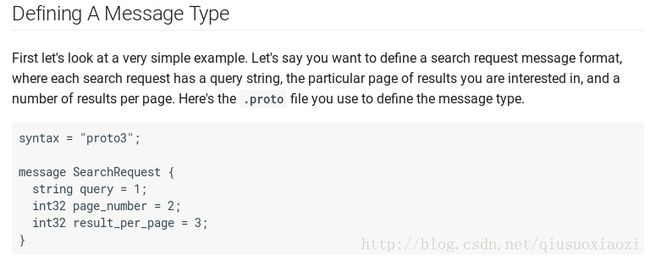
考虑到protobuf最初是为了google搜索业务开发的,举这例子也是可以理解的。其中
- 第一行proto3表示用的是proto3,默认是proto2
- 定义了3种type的数据,一种string type,两种scalar type。还可以定义其他的一些types,比如下面的enumerations,从而得到
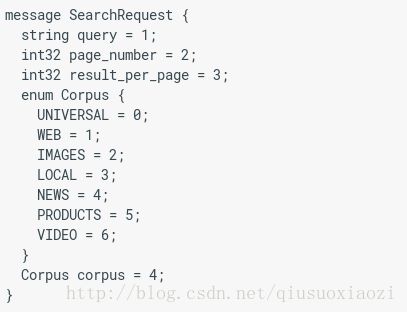
where the corpus can be UNIVERSAL, WEB, IMAGES, LOCAL, NEWS, PRODUCTS or VIDEO. 而且规定了,第一个(此处即UNIVERSAL)必须从0开始(不建议出现负值),原因如下:
- 必须要有一个为0,作为数值缺省值
- 0必须是第一个,因为根据proto2语法,enum的第一个规定为缺省值
(下图是各种type的default value,上面的两点分别对应第4,5两点)

此外通过设置option allow_alias = true,就可以assigning the same value to different enum constants,如下图(第二个代码块,没有设置成true,如果取消注释会编译报错)

由于这些缺省值的存在,所以设计的时候就要格外注意了:
For example, don’t have a boolean that switches on some behaviour when set to false if you don’t want that behaviour to also happen by default. Also note that if a scalar message field is set to its default, the value will not be serialized on the wire.
上面讲到的enum type是定义在message里面的,enum还可以定义在外部,这样就可以供其他message调用
You can define enums within a message definition, as in the above example, or outside – these enums can be reused in any message definition in your .proto file. You can also use an enum type declared in one message as the type of a field in a different message, using the syntax MessageType.EnumType.
When you run the protocol buffer compiler on a .proto that uses an enum, the generated code will have a corresponding enum for Java or C++, a special EnumDescriptor class for Python that’s used to create a set of symbolic constants with integer values in the runtime-generated class.
此外,message还可以调用其他message,如下SearchResponse调用了Result
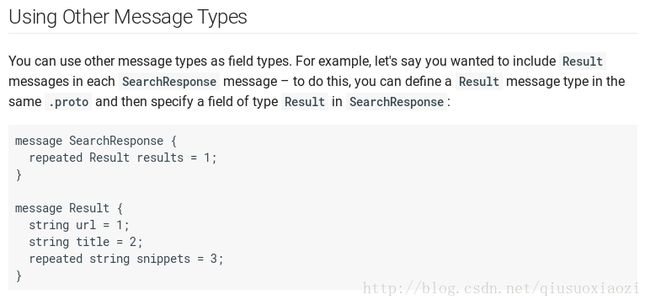
如果上面的Result是在另个.proto文件中,可以通过import来调用
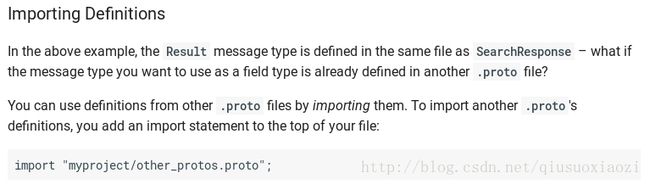

上问提到的各种tags就是为了encode的时候能够indentify不同field

看得要吐了,先打住吧。。
看到这里,再推荐一个博客,很好的回顾梳理了刚学的知识(最好再加上前边提到的博文1,博文2.1,博文2.2)。看了倍感清爽,越来越感觉到:学习,只需要投入时间,精力,然后保持专注,问题自然会迎刃而解的!
引用刚才提到的博客的一些材料

上面关于属性required, optional, repeated的解释和不错,正好是我刚才犯迷糊的地方!
。。。
另外,自己把博主的代码copy下来,g++ listperson.cpp时报错:

原因应该是protobuf安装的时候,使用的是g++4.9 而后来我升级成了g++5.4 ,所以会出现Undefined reference to google::protobuf:

from this website
…Anyway,我也不知道是不是g++版本问题,反正我重装了protobuf和libprotobuf.dev(我以为的重装,总之就是apt-get move/purge…,但是不知怎地,卸载完后protoc命令还存在,我也没搞懂)后,还是不行。 后来,直到发现

above pitcure from this blog. 看来以后遇到问题还是要多google多百度!! 话说回来,这还是由于对g++/gcc工具不熟的原因。。
此后,一切就OK啦!成功的跑出了AddressBook的example,感觉对protobuf的距离又增进了^_^:
今天就打住吧! 越看,我感觉有必要好好学学C++了。。protobuf也要再深入学学,可以看看这位小石头的博客。明天,先试着看看caffe.proto,边看边学C++,争取明天能看懂上面的listperson.cpp
想要看懂listperson.cpp,先看一个基本的C++的 helloworld程序:
#include ,用于基本输入输出
int main(int argc, char *argv[]) //int argc是命令行参数输入个数,char *argv[]是命令行输入命令字符串指针
{
cout << "hello world" << endl;
return 0;
}编译命令:g++ -o hello main.cpp(hello是编译输出执行程序名,main.cpp是源代码)
C++的输入输出流,比printf, scanf简单且强大,可以自动识别基本数据类型:
- std::cont 输出
- std::cerr 错误控制
- std::cin 输入
其中::是作用域运算符
命名空间:通过定义不同的命名空间可以防止C语言存在的变量名重复的冲突,出现冲突时,编译器会提醒,程序员可以强制写入namespace1::variable或namespace2:variable来使用该常量。标准命名空间std。
突然发现,有了上面的了解,结合一些C的编程基础,listperson.cpp差不多可以看懂个大概了! listperson.cpp见下:
#include 昨天在纠结AddressBook.proto中定义了好几个message(就像是caffe.proto中也有大量的message一样),那么protocol buffer在逆向序列化数据后,怎么知道按照那个message的模板去解析数据呢?现在发现这个问题实在幼稚,看 tutorial::AddressBook address_book这一句就知道了。。
再回过头去看caffe.proto,或者看看百度文库的一篇文章,感觉了解又多了一点!
其实到这里,心里还有一个疑惑:先前的addressbook的例子,我们只输入了一种message对应的模板数据,也就是都是姓名,邮箱,电话…这一种结构,如果我在proto文件中定义了多个message,而且在输入数据的时候,输入多个不同message对应的结构的数据,那么protobuf会怎么解析数据呢?
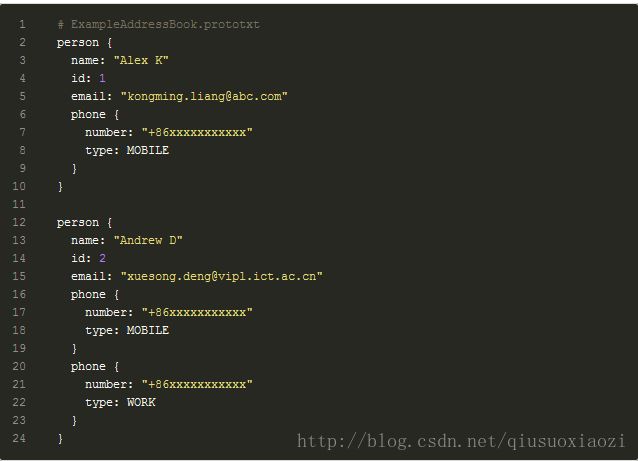
嗯, 看下面格式的对应就明白了:
定义的格式
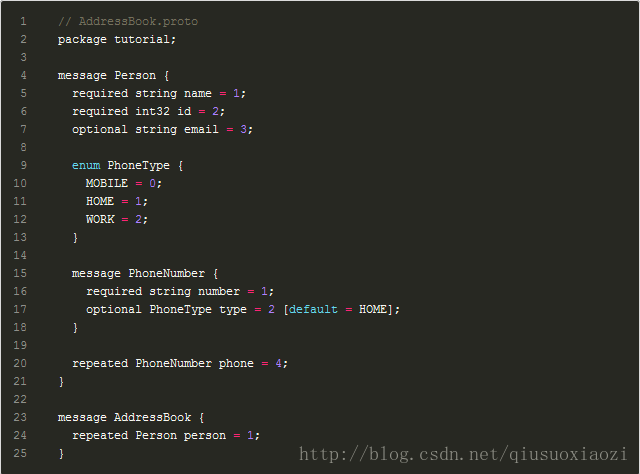
传参的格式
后面先花时间把caffe.cpp彻底看懂!!