HBase基本架构知识
一、HBase组成
1.Client:利用 RPC 机制与 HMaster 和HRegionServer通信;
2.Zookeeper: 协调,避免 HMaster 单点问题;HMaster没有单点问题,HBase 中可以启动多个HMaster,通过 ZooKeeper 的 Master Election 机制保证总有一个 Master 在运行。
3.HMaster:负责 Table 和 Region 的管理工作;
(1) 管理用户对 Table 的 CRUD 操作;
(2) 管理 HRegionServer的负载均衡,调整Region 分布;
(3) 在 RegionSplit 后,负责新Region 分配;
(4) 在 HRegionServer停机后,负责失效 HRegionServer 上的Region 迁移;
4.HRegionServer:HBase 最核心模块,响应用户IO请求,向 HDFS 中读写数据;

HRegionServer 内部管理了一系列 HRegion对象,每个 HRegion 对应 Table 中的一个Region,HRegion 由多个 HStore 组成,每个 HStore 对应 Table 中的一个 Column Familiy 的存储。
HStore 是 HBase 存储的核心,其中由两部分构成,一部分是 MemStore,一部分是 StoreFile。StoreFile 文件数量增长到一定阈值后,会触发 Compact合并操作,将多个StoreFile 合并成一个 StoreFile,合并过程中会进行版本合并和数据删除。StoreFile 在完成 Compact 合并操作后,会逐步形成越来越大的 StoreFile,当单个StoreFile 大小超过一定阈值后,会触发 Split 操作,同时把当前Region 分裂成2个Region,父Region 会下线,新分裂出的2个孩子Region 会被 HMaster 分配到相应的 HRegionServer 上,使得原先1个Region 压力得以分流到2个Region 上。
二、Table 与Region
Region是 HBase集群分布数据的最小单位。
Region 是部分数据,所以是所有数据的一个自己,但Region包括完整的行,所以Region 是行为单位表的一个子集。
每个Region 有三个主要要素:
-
- 它所属于哪张表
- 它所包含的的第一行(第一个Region 没有首行)
- 他所包含的最后一行(末一个Region 没有末行)
当表初写数据时,此时表只有一个Region,当随着数据的增多,Region 开始变大,等到它达到限定的阀值大小时,变化把Region 分裂为两个大小基本相同的Region,而这个阀值就是StoreFile 的设定大小(参数:hbase.hRegion.max.filesize 新版本默认10G) ,在第一次分裂Region之前,所有加载的数据都放在原始区域的那台服务器上,随着表的变大,Region 的个数也会相应的增加,而Region 是HBase集群分布数据的最小单位。
(但Region 也是由block组成,Region是属于单一的RegionServer,除非这个RegionServer 宕机,或者其它方式挂掉,再或者执行balance时,才可能会将这部分Region的信息转移到其它机器上。)
这也就是为什么 Region比较少的时候,导致Region 分配不均,总是分派到少数的节点上,读写并发效果不显著,这就是HBase 读写效率比较低的原因。
三、元数据表 .META.和 -ROOT-
HBase内部维护着两个元数据表,分别是-ROOT- 和 .META. 表。他们分别维护者当前集群所有Region 的列表、状态和位置。
(1) .META. 记录用户表的 Region 信息,可以有多个 Region,.META.会随需要被Split。
(2) -ROOT- 记录 .META. 表的 Region 信息,只有一个 Region,-ROOT-永不会被Split。
(3) ZooKeeper 中记录 -ROOT- 表的 Location,.META. 和 -ROOT- 的关系见下图。
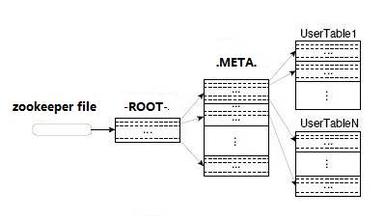
-ROOT- 表包含.META. 表的Region 列表,因为.META. 表可能会因为超过Region 的大小而进行分裂,所以-ROOT-才会保存.META.表的Region索引,-ROOT-表是不会分裂的。而.META. 表中则包含所有用户Region(user-space Region)的列表。表中的项使用Region 名作为键。Region 名由所属的表名、Region 的起始行、创建的时间以及对其整体进行MD5 hash值。
四、Region 定位流程
算法:B+树定位,通过ZooKeeper 来查找 -ROOT-,然后是.META.,然后找到Table里的Region。
Client 访问用户数据之前需要访问 ZooKeeper,然后访问 -ROOT- 表,接着访问 .META. 表,最后才能找到用户数据的位置去访问。中间需要多次网络操作,不过 Client 端会执行 Cache 缓存。
(1) 客户端client首先连接到ZooKeeper这是就要先查找-ROOT-的位置。
(2) 然后client通过-ROOT-获取所请求行所在范围所属的.META.Region的位置。
(3) client接着查找.META.Region来获取user-space Region所在的节点和位置。
(4) 接着client就可以直接和管理者那个Region的RegionServer进行交互。
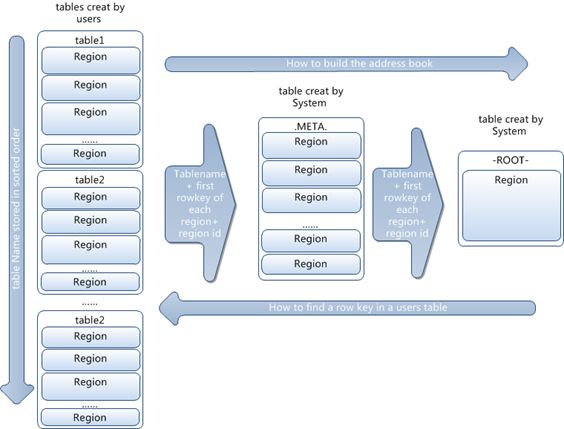
每个行操作可能要访问三次远程节点,为了节省这些代价,client会缓存他们遍历-ROOT-和.META. 的位置以及user-space Region的开始行和结束行,这样每次访问就不会再从表中去查询了,但如果变动了怎么办?却是存在这个问题,这样的话client 会出现错误,那此时Region毫无疑问是移动了,这时,client 会再次从.META.查找Region 的新位置并再次将其放入到缓存中去,周而复始。同样道理如果.META.的Region移动了,client 也才会去-ROOT-表查询.META.Region的新位置。
HMaster是Hbase主/从集群架构中的中央节点。通常一个HBase集群存在多个HMaster节点,其中一个为Active Master,其余为Backup Master.
Hbase每时每刻只有一个hmaster主服务器程序在运行,hmaster将region分配给region服务器,协调region服务器的负载并维护集群的状态。Hmaster不会对外提供数据服务,而是由region服务器负责所有regions的读写请求及操作。
由于hmaster只维护表和region的元数据,而不参与数据的输入/输出过程,hmaster失效仅仅会导致所有的元数据无法被修改,但表的数据读/写还是可以正常进行的。
HMaster的作用:
- 为Region server分配region
- 负责Region server的负载均衡
- 发现失效的Region server并重新分配其上的region
- HDFS上的垃圾文件回收
- 处理schema更新请求
HRegionServer作用:
- 维护master分配给他的region,处理对这些region的io请求
- 负责切分正在运行过程中变的过大的region
可以看到,client访问hbase上的数据并不需要master参与(寻址访问zookeeper和region server,数据读写访问region server),master仅仅维护table和region的元数据信息(table的元数据信息保存在zookeeper上),负载很低。
注意:master上存放的元数据是region的存储位置信息,但是在用户读写数据时,都是先写到region server的WAL日志中,之后由region server负责将其刷新到HFile中,即region中。所以,用户并不直接接触region,无需知道region的位置,所以其并不从master处获得什么位置元数据,而只需要从zookeeper中获取region server的位置元数据,之后便直接和region server通信。
HRegionServer存取一个子表时,会创建一个HRegion对象,然后对表的每个列族创建一个Store实例,每个Store都会有一个MemStore和0个或多个StoreFile与之对应,每个StoreFile都会对应一个HFile, HFile就是实际的存储文件。因此,一个HRegion有多少个列族就有多少个Store。
一个HRegionServer会有多个HRegion和一个HLog。
当HRegionServer意外终止后,HMaster会通过Zookeeper感知到。
Zookeeper作用在于:
1、hbase regionserver 向zookeeper注册,提供hbase regionserver状态信息(是否在线)。
2、hmaster启动时候会将hbase系统表-ROOT- 加载到 zookeeper cluster,通过zookeeper cluster可以获取当前系统表.META.的存储所对应的regionserver信息。
zookeeper是hbase集群的"协调器"。由于zookeeper的轻量级特性,因此我们可以将多个hbase集群共用一个zookeeper集群,以节约大量的服务器。多个hbase集群共用zookeeper集群的方法是使用同一组ip,修改不同hbase集群的"zookeeper.znode.parent"属性,让它们使用不同的根目录。比如cluster1使用/hbase-c1,cluster2使用/hbase-c2,等等。