1 流计算
静态数据和流数据
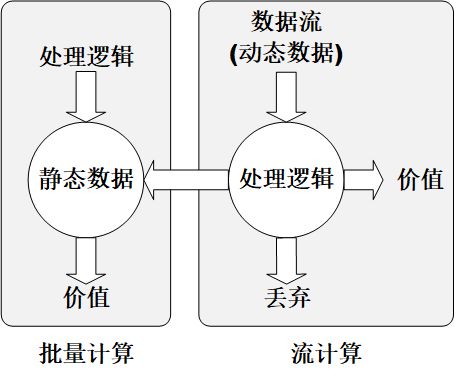
静态数据类似存储在水库中的水,是相对静止不动的,如数据仓库中储存的数据、关系型数据库中存储的数据等。流数据是指在时间分布和数量上无限的一系列动态数据合体,数据记录是流数据的最小组成单元。
静态数据和流数据的处理,分别对应两种不同的计算模式:批量计算和实时计算。数据的两种处理模型如下图所示。
2 Spark Streaming
Spark Streaming简介
Spark Streaming是构建在spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。Spark Streaming可结合批处理和交互式查询,适用需要将历史数据和实时数据联合分析的应用场景。
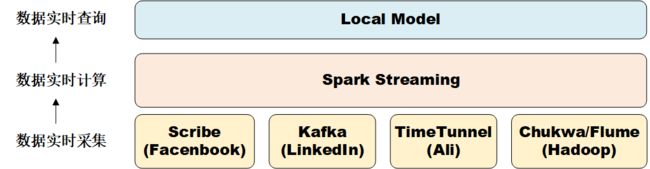
针对流数据的实时计算称为流计算。总体来说,流计算秉承一个基本理念,即数据的价值随着时间的流逝而降低。对于一个流计算系统来说,它应达到高性能、海量式、实时性、分布式、易用性和可靠性等要求。流计算系统一般包括:数据实时采集、数据实时计算和数据实时查询服务三大部分,Spark Streaming的实时计算系统的三大组成部分如下图所示。
Spark Streaming最主要的抽象是离散化数据流(Discretized Stream, DStream),表示连续不断的数据流。Streaming内部按照时间片将数据分成一段一段,每一段数据转换成一个RDD,并且对DStream的操作最终都会被转化成对RDD的操作。其执行流程如下图所示,

思考:DStream是由多个具有时间属性的RDD组成。
Spark Streaming 和Hadoop Storm对比
Spark Streaming只能实现秒级的计算,而Hadoop Storm可以实现毫秒级的响应,因此Spark Streaming无法满足实时性要求非常高的场景,只能胜任其他流式准实时计算场景。
相比于Storm,Spark Streaming是基于RDD的,更容易做高效的容错处理。Spark Streaming的离散化工作机制,使其可以同时兼容批量和实时数据处理的逻辑和算法,适用需要将历史数据和实时数据联合分析的应用场景。
Hadoop+Storm的Lambda架构涉及的组件较多,部署比较繁琐,而Spark Streaming同时集成了流式计算和批量计算的功能,涉及组件少,部署简单。
Spark Streaming 工作机制
Spark Streaming有一个Reciver组件,作为一个守护进程运行在Executor上,每个Receiver负责一个DStream输入流。Reciver组件收到数据之后会提交给Spark Streaming程序进行处理。处理的结果可以传递给可视化显示或者保存到HBase、HDFS中。如下图所示,

3 DStream编程
Spark Streaming编程的基本步骤
- 通过创建输入DStream来定义输入源;
- 通过对DStream应用转换和输出操作来定义计算流;
- 调用StreamContext对象的start()方法,启动接收和处理流程;
- 调用StreamContext对象的awaitTermination()方法,等待流计算结束或者调用stop()方法,手动结束流计算;
创建Streaming Context
import org.apache.spark.streaming._
val ssc = new StreamingContext(sc, Seconds(1))
编写独立应用程序时
import org.apache.spark.streaming._
val sc = new SparkConf().setAppName("AppName")
val ssc = new StreamingContext(sc, Seconds(1))
从文件中不停的获取数据流
package sparkstudy.sparkstreaming
import org.apache.spark._
import org.apache.spark.streaming._
object StreamingFromFile {
def main(args: Array[String]) = {
val sparkConf = new SparkConf().setAppName("StreamingFromFile")
val ssc = new StreamingContext(sparkConf, Seconds(2))
val lines = ssc.textFileStream("file:///root/data/streaming")
val words = lines.flatMap(line => line.split(","))
val wordsCount = words.map(x => (x, 1)).reduceByKey(_ + _)
wordsCount.print()
ssc.start()
ssc.awaitTermination()
}
}
- 只会对/root/data/streaming目录下新增的文件进行操作,即使修改历史文件,streaming也不会再操作。
- ssc.stop()之后,只有退出会话,不能再通过同一个会话启动DStreaming;
辅助脚本,用于不停的生成新的文件
mkdir /root/data/streaming
rm -f streaming/*
for v in `seq 1 100`;do tail -n $(($v+10)) user_login.txt > streaming/$v.txt; sleep 1; done
从socket中读取数据流
使用Linux中的nc命令模拟服务端
nc -lk 9999
Streaming客户端
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.storage.StorageLevel
import org.apache.spark.internal.Logging
import org.apache.log4j.{Level,Logger}
object StreamingExamples extends Logging {
def setStreamingLogLevels() {
val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElements()
if (!log4jInitialized) {
logInfo("Setting log level to [WARN] for Streaming examples.")
Logger.getRootLogger.setLevel(Level.WARN)
}
}
}
object StreamingFromSocket {
def main(args: Array[String]) = {
if (args.length < 2) {
System.err.println("StreamingFromSocket ")
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
val sparkConf = new SparkConf().setAppName("StreamingFromSocket")
val ssc = new StreamingContext(sparkConf, Seconds(1))
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(line => line.split(","))
val wordsCount = words.map(x => (x, 1)).reduceByKey(_ + _)
wordsCount.print()
ssc.start()
ssc.awaitTermination()
}
}
从RDD队列中读取数据流
可以调用StreamingContext对象的queueStream()方法创建基于RDD队列的DStream。下面的例子中,每个1秒创建一个RDD放入队列,Spark Streaming每隔2秒就从队列中取出数据进行处理
import org.apache.spark._
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming._
import org.apache.spark.storage.StorageLevel
object StreamingFromRddQueue {
def main(args: Array[String]) = {
val sparkConf = new SparkConf().setAppName("StreamingFromRddQueue")
val ssc = new StreamingContext(sparkConf, Seconds(2))
val rddQueue = new scala.collection.mutable.SynchronizedQueue[RDD[Int]]()
val queueStream = ssc.queueStream(rddQueue)
val mappedStream = queueStream.map(r => (r % 10,1))
val reduceStream = mappedStream.reduceByKey(_ + _)
reduceStream.print()
ssc.start()
for( i <- 1 to 10) {
rddQueue += ssc.sparkContext.makeRDD(1 to 100, 2)
Thread.sleep(1000)
}
ssc.stop()
}
}
从kafka中读取数据流
kafka的安装和部署方法以及topic创建和测试方法请参考:Kafka集群的安装和部署。
创建topic
kafka-topics.sh --create \
--zookeeper master:2181,slave2:2181,slave3:12181 \
--partitions 3 --replication-factor 3 --topic streaming
- 下载并拷贝spark-streaming-kafka*.jar包到
$SPARK_HOME/jars/kafka目录下 - 拷贝
$KAFKA_HOME/lib下的所有jar包到$SPARK_HOME/jars/kafka
mkdir $SPARK_HOME/jars/kafka
cp spark-streaming-kafka-0-8_2.11-2.1.0.jar $SPARK_HOME/jars/kafka/
cp $KAFKA_HOME/libs/*.jar $SPARK_HOME/jars/kafka/
启动spark
sh $SPARK_HOME/sbin/start-all.sh
生产者程序
package sparkstudy.sparkstreaming
import java.util.HashMap
import org.apache.kafka.clients.producer.KafkaProducer
import org.apache.kafka.clients.producer.ProducerConfig
import org.apache.kafka.clients.producer.ProducerRecord
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
object MyKafkaProducer {
def main(args: Array[String]) = {
if (args.length < 4) {
System.err.println("StreamingFromSocket ")
System.exit(1)
}
val Array(brokers, topic, messagePerSec, wordsPerMessage) = args
val props = new HashMap[String, Object]
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
val producer = new KafkaProducer[String, String](props)
// send some messages
while(true) {
(1 to messagePerSec.toInt).foreach {
messageNum => val str = (1 to wordsPerMessage.toInt).map(x => scala.util.Random.nextInt(10).toString).mkString(" ")
print(str)
println()
val message = new ProducerRecord[String, String](topic, null, str)
producer.send(message)
}
Thread.sleep(1000)
}
}
}
消费者程序
package sparkstudy.sparkstreaming
import org.apache.spark._
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.kafka.KafkaUtils
import common.StreamingExamples
object MyKafkaConsumer {
def main(args: Array[String]) = {
StreamingExamples.setStreamingLogLevels()
val sc = new SparkConf().setAppName("MyKafkaConsumer")
val ssc = new StreamingContext(sc, Seconds(10))
ssc.checkpoint("/data/kafka/checkpoint")
val zkQuorum = "localhost:2181"
val groupId = "1"
val topics = "streaming"
val numThread = 1
val topicMap = topics.split(",").map((_, numThread.toInt)).toMap
val lineMap = KafkaUtils.createStream(ssc, zkQuorum, groupId, topicMap)
val lines = lineMap.map(_._2)
val words = lines.flatMap(_.split(" "))
val pair = words.map(x => (x,1))
val wordCounts = pair.reduceByKeyAndWindow(_ + _, _ - _, Minutes(2), Seconds(10), 2)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
执行生产者和消费者程序
使用maven编译上述代码,生产的jar包为SparkStreaming-0.0.1-SNAPSHOT.jar。
执行生产者程序
spark-submit --jars /root/software/spark-2.2.0-bin-hadoop2.6/jars/kafka/kafka-clients-0.10.2.0.jar \
--class sparkstudy.sparkstreaming.MyKafkaProducer SparkStreaming-0.0.1-SNAPSHOT.jar master:9092 streaming 10 4
执行消费者程序
spark-submit --jars /root/software/spark-2.2.0-bin-hadoop2.6/jars/kafka/kafka-clients-0.10.2.0.jar,\
/root/software/spark-2.2.0-bin-hadoop2.6/jars/kafka/spark-streaming-kafka-0-8_2.11-2.2.0.jar,\
/root/software/spark-2.2.0-bin-hadoop2.6/jars/kafka/metrics-core-2.2.0.jar,\
/root/software/spark-2.2.0-bin-hadoop2.6/jars/kafka/kafka_2.11-0.10.2.0.jar,\
/root/software/spark-2.2.0-bin-hadoop2.6/jars/kafka/zkclient-0.10.jar \
--class sparkstudy.sparkstreaming.MyKafkaConsumer SparkStreaming-0.0.1-SNAPSHOT.jar
spark streaming去取kafka数据时踩到的坑
错误:Caused by: java.lang.ClassNotFoundException: org.I0Itec.zkclient.IZkStateListener
解决方案:是因为未指定zk的依赖,通过jars指定zkclient库,--jars /root/software/spark-2.2.0-bin-hadoop2.6/jars/kafka/zkclient-0.10.jar
错误:java.lang.NoClassDefFoundError: org/apache/spark/Logging
解决方案:org.apache.spark.Logging is available in Spark version 1.5.2 or lower version. It is not in the 2.0.0. 因此我把spark-streaming-kafka替换成spark-streaming-kafka-0-8。因为我的spark版本使用的是2.2,scala版本使用的是2.11.8,所以使用了spark-streaming-kafka-0-8_2.11-2.2.0.jar,pom的依赖配置为:
org.apache.spark
spark-streaming-kafka-0-8_2.11
2.2.0
从flume读取数据流
flume的部署和测试请参考:flume的部署和测试
参考
- Flume_Kafka_SparkStreaming实现词频统计
- https://stackoverflow.com/questions/47951910/spark2-2-1-incompatible-jackson-version-2-8-8?rq=1