Java Web学习之路--HttpResponse应用
什么是HttpResponse?
HTTP响应由状态行、状态头、状态体,还有一个空行组成。HttpResponse对象就封装了HTTP响应的信息。
1.利用HttpResponse向浏览器发送字符文本:
我们前面说过response对象,代表HTTP响应。那么向浏览器发送字符就是最基本的功能了,这里我们就来聊一下。
- 其实现在的eclipse在创建HttpServlet类后,会自动配置输出为getWriter():
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setContentType("text/html");
PrintWriter out = response.getWriter();
out.println("");
out.println("");
out.println(" A Servlet ");
out.println(" ");
out.print(" This is ");
out.print(this.getClass());
out.println(", using the GET method");
out.println(" ");
out.println("");
out.flush();
out.close();
}
不单单是只有getWriter()方法,还有getOutputStream()方法,这两者都可以向浏览器发送字符文本。我们接下来就来讨论一下这两者的使用方法和区别。
-
**getWriter()方法:**
PrintWriter out=response.getWriter();
out对象用于输出字符流数据
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setContentType("text/html");
//response.setContentType("text/html;charset=UTF-8");//防止乱码
PrintWriter out = response.getWriter();
out.println("The big watermelon in the East");
out.print("
");
out.println("东边的大西瓜");
out.flush();
out.close();
}

上边的英文正常输出,但是下边的中文错误。
那么为什么会出现这种情况呢?
Tomcat默认的编码是ISO-8859-1,但是中文不支持这个码表。
如何解决呢?
- 我们设置为编码为UTF-8看看
response.setCharacterEncoding("UTT-8");
PrintWriter out = response.getWriter();
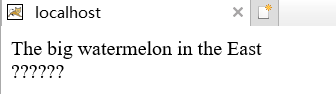
还是乱码的,因为我们虽然把中文字符设置成UTF-8,但是浏览器不知道你是UTF-8,它在显示的时候会首选自己默认的编码,浏览器默认编码GB2312。
-
如果我们改为GB2312。

不会乱码了。 -
最简单的不会乱码的方法
上面在展示自动生成的代码时大家有没有注意到;
response.setContentType("text/html");
这里就是Servlet给我们提供的一个更好的解决乱码的方法:
//设置浏览器使用UTF-8编码显示数据,并把中文转码的码表设置成UTF-8
response.setContentType("text/html;charset=UTF-8");
-
**getOutStream()方法:**
ServletOutputStream os=response.getOutputStream();
os用于输出字节流数据。
熟悉io的同学们对这肯定是不陌生的
而getOutStream又为我们提供了print()和write()两种方法
- print()
- 同样的我们先来输出英文:
ServletOutputStream os=response.getOutputStream();
os.print("The big watermelon in the East");
os.close();
成功:

- 输出中文:
ServletOutputStream os=response.getOutputStream();
os.print("东边的大西瓜");
os.close();
这里出现了报错500,我们前面在讲HTTP协议的时候提到过,当状态码为500时是服务器端出现错误,这里当然指的就是Tomcat。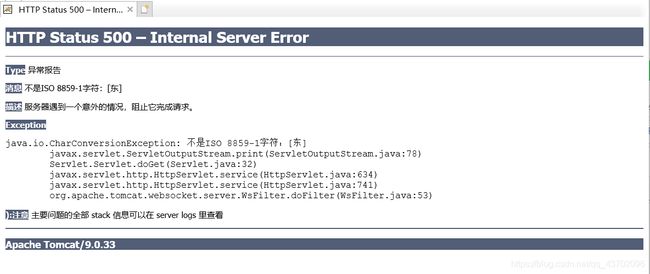
为了弄清根本原因,我们进入eclipse去看一下报错信息:
![]()
看到这,我们就知道了,Tomcat使用的是IOS 8859-1编码,而中文对ISO 8859-1编码不支持。我们上面也提到了,在io中outputStream输出的是字节流 ,二进制数据。那么我们只需在输出前,把中文转换成响应的字节流就好了,这时候就要靠write()了。
- write()
ServletOutputStream os=response.getOutputStream();
os.write("东边的大西瓜".getBytes("gb2312"));
os.close();
成功:

可是通用的应该是“UTF-8”编码,但是浏览器采用“GBK”编码这时候我们同样会出现乱码的情况。这时候我们来设置消息头,告诉浏览器我的编码格式是"UTF-8"。
response.setHeader("Content-Type", "text/html;charset=UTF-8");
ServletOutputStream os=response.getOutputStream();
os.write("东边的大西瓜".getBytes("UTF-8"));
os.close();
成功:
| getWrite()和getOutputStream()总结: |
- getWrite()时字符流,getOutputStream()是字节流,缓冲区中的存在方式不同。
- getWrite()和getOutputStream()互斥,即二者不能同时使用,因为缓冲区不能同时存在两种格式。(
使用response转发实质只有一次请求,一次响应,所以不能同时调用两种方法,重定向则不受限制) - Servlet程序向ServletOutputStream或PrintWriter对象中写入的数据将被Servlet引擎从response里面获取,Servlet引擎将这些数据当作响应消息的正文,然后再与响应状态行和各响应头组合后输出到客户端。
- Servlet的serice()方法结束后【也就是doPost()或者doGet()结束后】,Servlet引擎将检查getWriter或getOutputStream方法返回的输出流对象是否已经调用过close方法,如果没有,Servlet引擎将调用close方法关闭该输出流对象.
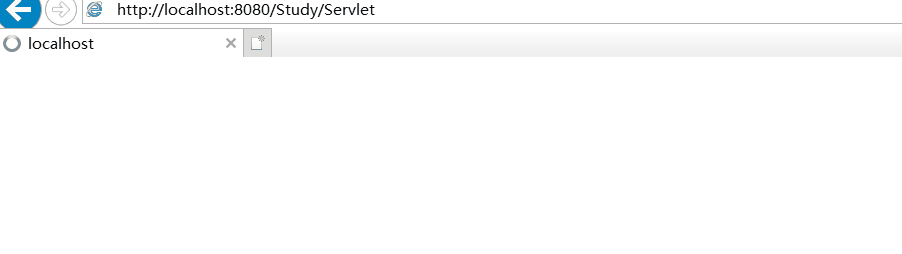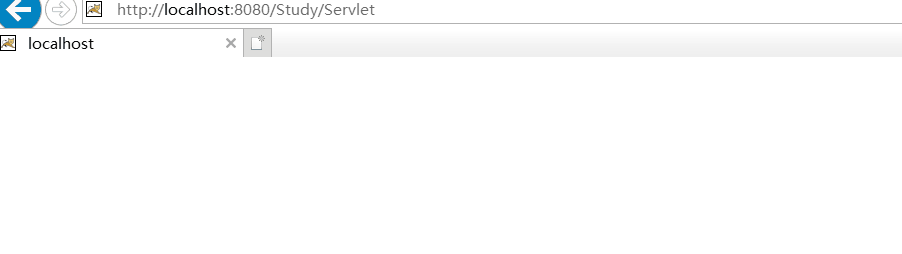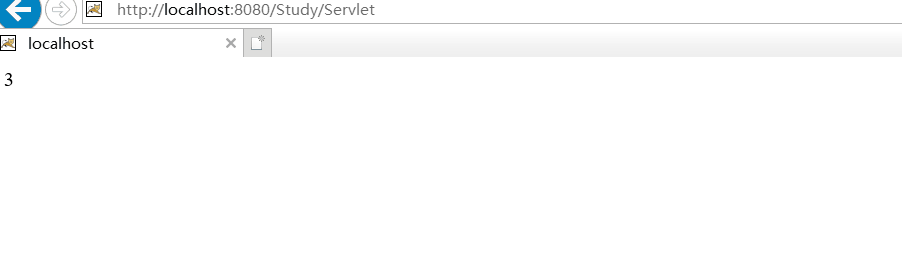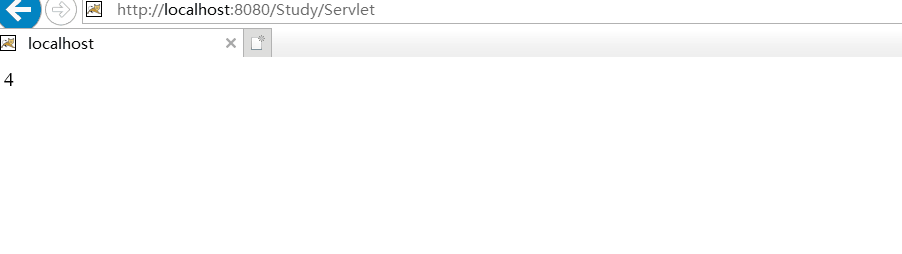
2.实现自动刷新:
- 提到自动刷新,那么可能是和消息头有关了:
private static final long serialVersionUID = 1L;
private int i;
public void init() { //初始化i值
i=0;
}
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setContentType("text/html;charset=UTF-8");
response.setHeader("Refresh", "1");
PrintWriter out = response.getWriter();
i++; //每次刷新调用servic()方法,从而i++;
out.print(i);
out.flush();
out.close();
}
运行效果图:
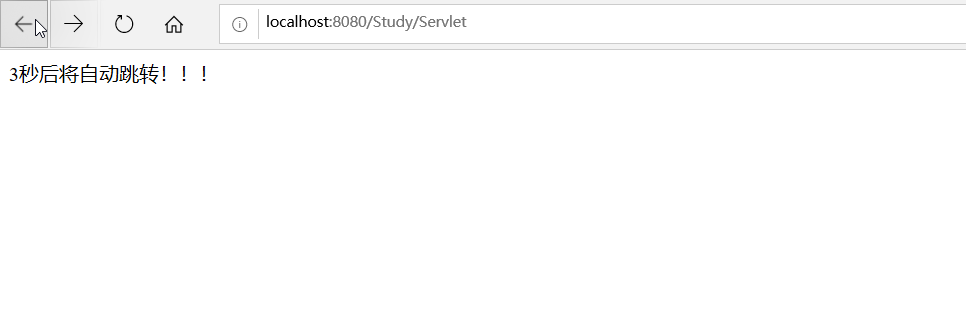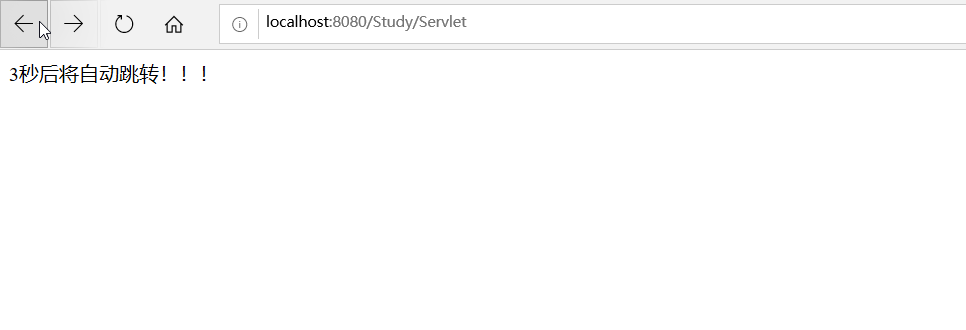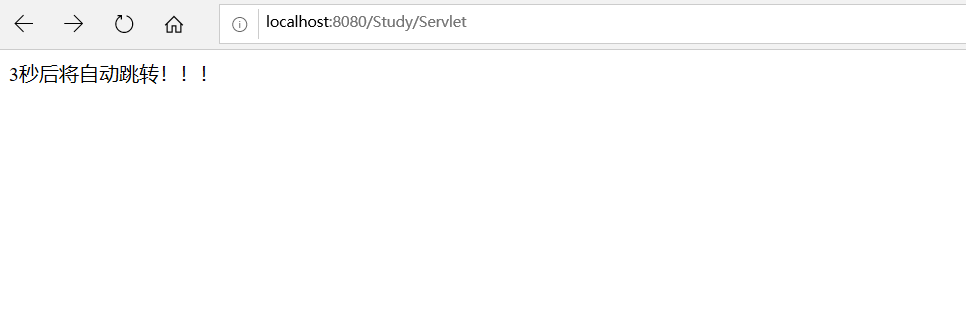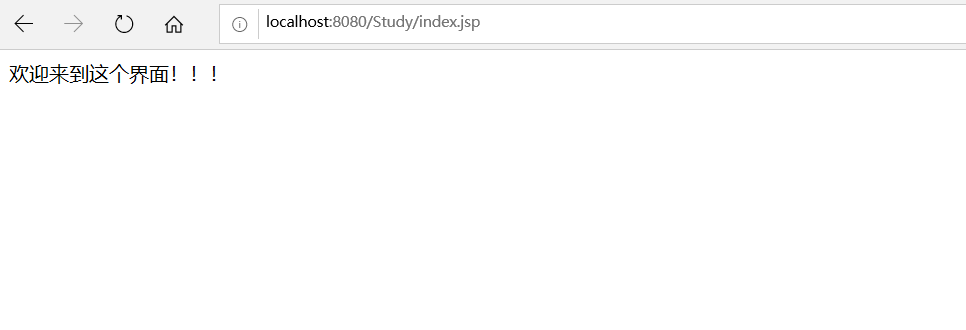
- 定时跳转:
out.print("3秒后将自动跳转!!!");
response.setHeader("Refresh","3;URL=index.jsp");
- 设置缓存:
浏览器本身是带有缓存机制的,但是有些网页是需要实时更新的,比如股票;那么就需要我们禁止缓存了:
//浏览器有三消息头设置缓存,为了兼容性!将三个消息头都设置了
response.setDateHeader("Expires", -1);
response.setHeader("Cache-Control","no-cache");
response.setHeader("Pragma", "no-cache");
3.实现文件下载:

- Servlet代码:
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
//获取路径资源
String path=this.getServletContext().getRealPath("3.png");
//读取资源
FileInputStream fileInputStream=new FileInputStream(path);
//获取到文件名,路径在电脑上保存的形式是\\
String fileName=path.substring(path.lastIndexOf("\\")+1);
//设置消息头告诉浏览器,我要下载1.png这个图片
//response.setHeader("Content-Disposition", "attachment;filename="+fileName);//该方式文件名为中文时会乱码
response.setHeader("Content-Disposition", "attachment; filename=" + URLEncoder.encode(fileName, "UTF-8"));//防止中文乱码
//把读取到的内容回送给浏览器
int len=0;
byte[] bytes=new byte[1024];
ServletOutputStream setvletOutputStream=response.getOutputStream();
while((len=fileInputStream.read(bytes))>0) {
setvletOutputStream.write(bytes,0,len);
}
setvletOutputStream.close();
fileInputStream.close();
}
- 这里我们通过点击超链接下载:
<body>
<a href="download">点击下载</a>
</body>
- 效果图:
