光线追踪
书上讲常量内存的那章有个用光线追踪画球的东西。
暂时没用常量内存实现了一下。
不得已自己写了个mvec3结构体
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include > > (p, pp, spnum, width, height);
status = cudaGetLastError();
if (status != cudaSuccess) {
fprintf(stderr, "Build kernel failed.\n");
goto Error;
}
status = cudaDeviceSynchronize();
if (status != cudaSuccess) {
fprintf(stderr, "kernel run failed.\n");
goto Error;
}
status = cudaMemcpy(res, p, width*height*4, cudaMemcpyDeviceToHost);
if (status != cudaSuccess) {
fprintf(stderr, "Memcpy failed.\n");
goto Error;
}
Error:
cudaFree(p);
cudaFree(pp);
HANDLE_ERROR(cudaDeviceReset());
return ;
} sphere.in文件
2
0 0 10 3
255 0 0
3 3 10 3
0 255 0也就是站在(0,0,0)点像z轴正方向看了
效果图:
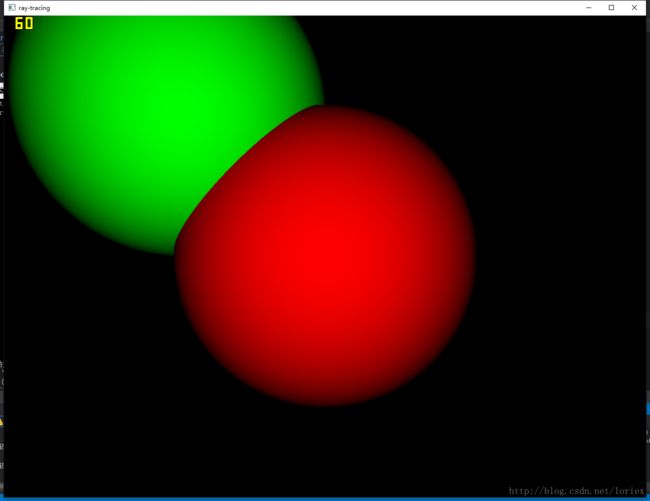
换成用常量内存存储Spheres,然后球数目增加到了200,渲染2560*1920的图
实测用常量内存还是全局内存速度都几乎一样都是1170ms
倒是如果在每一个线程束里用__shared__复制一遍Spheres数组能够将时间缩减到1080ms
差不多9%的性能提升
于是用__constant__存储球然后再加个球与光线的判定优化勉强达到了970ms
于是最后达不到书上所说的近50%的性能提升,这个日后再细究。。
以及:感觉我的代码内存泄漏有点严重Orz
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include > > (p, spnum, width, height);
status = cudaGetLastError();
if (status != cudaSuccess) {
fprintf(stderr, "Build kernel failed.\n");
goto Error;
}
status = cudaDeviceSynchronize();
if (status != cudaSuccess) {
fprintf(stderr, "kernel run failed.\n");
goto Error;
}
status = cudaMemcpy(res, p, width*height*4, cudaMemcpyDeviceToHost);
if (status != cudaSuccess) {
fprintf(stderr, "Memcpy failed.\n");
goto Error;
}
Error:
cudaFree(p);
cudaFree(pp);
HANDLE_ERROR(cudaDeviceReset());
return ;
} 效果图:
