卷积函数的FPGA实现(一)编写卷积IPcore的BRAM实现
背景:我们将MTCNN的卷积改为了zynqNet需要的嵌套的for循环形式,并且相对看懂了相应的zyqnNet的c代码,现在我们可以直接将卷积模块单独拆分出来构建一个IPcore。
目的:构建卷积的IPcore
ZynqNet解析(四)FPGA端程序解析 https://blog.csdn.net/weixin_36474809/article/details/82683399
ZynqNet解析(五)具体硬件实现 https://blog.csdn.net/weixin_36474809/article/details/82702008
MTCNN(七)卷积的更改 https://blog.csdn.net/weixin_36474809/article/details/83145601
目录
一、更改的顺序
二、卷积的3*3 MACC
三、OCache累加
3.1 增加全局变量
3.2 数据于OBRAM上累加
3.3 写出OBRAM到DRAM上
四、ImageCache
4.1 ImageCache的大小
4.2 写入IBRAM顺序
4.3 从DRAM读出的顺序
4.4 加载的顺序
4.5 IBRAM上的值的验证
4.6 从IBRAM读出
4.7 读入ProcessingElement的buffer
五、weightCache
5.1 WBRAM的大小
5.2 在WBRAM的地址
5.3 从DRAM加载入WBRAM
5.4 WBRAM的验证
5.5 从WBRAM中读入到buffer
5.6 验证buffer正确

一、更改的顺序
将用到的变量设为namespace内的extern全局变量。调试通过
将处理的程序写为子函数,调试通过
将相应的全部变量的运算函数加入namespace,调试通过
二、卷积的3*3 MACC
循环顺序为for height,for width,for channel_In,for channel_Out
void ProcessingElement::macc2d(const float pixels[9],const float weights[9],
float& result) {
#pragma HLS inline
float accumulator = 0.0f;
float multresult[9];
#pragma HLS ARRAY_PARTITION variable = multresult complete dim = 0
L_MACC_multiply:
for (int i = 0; i < 9; i++) {
#pragma HLS UNROLL
multresult[i] = pixels[i] * weights[i];
}
L_MACC_accumulate:
for (int i = 0; i < 9; i++) {
#pragma HLS UNROLL
accumulator = accumulator + multresult[i];
}
result = accumulator;
}九个数字相乘相加。我们在之前只用将这几个数字写入数组就行。我们关注怎么运用OCache将这九个数字搬入相应的数组。关注如何将累加结果送入Ocache累加。
三、OCache累加
全局变量 float OutputCache::OBRAM[MAX_NUM_CHOUT];其中OBRAM的大小为MAX_NUM_CHOUT,为最大的输出的通道数。根据前面for height与for width就确定了是针对单个输出的像素点,所以for channel in与for channle out就是单个像素点上先循环feature map然后循环output channel。
for channel in时固定feature,然后权重进行循环,MACC后放入OBRAM。然后换一个channel in的9*9,再进行更换weiht然后累加与OBRAM。
3.1 增加全局变量
namespace MemoryController {
void writeBackOutputChannel(float * SHARED_DRAM, int co, float data);
extern int peixl_out_offset;
extern int out_channelSize;
};BRAM与DRAM之间的数据搬运是MemoryController完成的,所以需要在memroyController之中设置相应的偏移量。
3.2 数据于OBRAM上累加
ProcessingElement::macc2d(pixels,weights,macc_sum);
if (cur_channel_in == 0) {
OutputCache::setOutChannel(cur_channel_out, macc_sum);
} else {
OutputCache::accumulateChannel(cur_channel_out, macc_sum);
}
void OutputCache::accumulateChannel(int co, float value_to_add) {
#pragma HLS inline
#pragma HLS FUNCTION_INSTANTIATE variable = co
#pragma HLS ARRAY_PARTITION variable = OBRAM cyclic factor = N_PE
#pragma HLS RESOURCE variable=OBRAM core=RAM_T2P_BRAM latency=2
float old_ch = getOutChannel(co);
float new_ch = old_ch + value_to_add;
setOutChannel(co, new_ch);
};
float OutputCache::getOutChannel(int co) {
#pragma HLS inline
return OBRAM[co];
}
void OutputCache::setOutChannel(int co, float data) {
#pragma HLS inline
#pragma HLS FUNCTION_INSTANTIATE variable = co
OBRAM[co] = data;
}如果是第一个输入通道就设定OBRAM相应的位置为MACC值,若不是第一个输入通道就表示需要在不同的输入通道之间进行累加。
3.3 写出OBRAM到DRAM上
}//channel_out loop
}//channel_in loop
for(cur_channel_out=0; cur_channel_out在进行完输入通道循环之后,所有的输入输出通道都在OBRAM上进行了累加,
然后,我们根据相应的地址映射将OBRAM上的数据写入DRAM之中。
四、ImageCache
float pixels[9];
float weights[9];
for (filter_row=0;filter_row<3;filter_row++){
for(filter_col=0;filter_col<3;filter_col++){
weight_loc=weight_pre_loc+filter_row*kernelSize+filter_col;
input_loc=input_pre_loc+filter_row*in_width+filter_col;
pixels[filter_row*3+filter_col]=input_ptr[input_loc];
weights[filter_row*3+filter_col]=weight_ptr[weight_loc];
}
}
ProcessingElement::macc2d(pixels,weights,macc_sum);原始的图像读入根据DRAM上的映射地址读入IBRAM上,然后从IBRAM上写入processingElement之中。我们需要找出此关系。
4.1 ImageCache的大小
首先,定义flaot ImageCache::IBRAM[MAX_IMAGE_CACHE_SIZE];在zynqNet之中,这些参数被计算好在network.h文件之中。
ImageCache是一次更新一行还是所有的iamge均存于Cache之中。我们需要找出答案。

上面为zyqnNet的ICache大小,我们下面需要安装MTCNN的尺码来。
MTCNN(三)基于python代码的网络结构更改 https://blog.csdn.net/weixin_36474809/article/details/82856171
我们找到imageCache之中对于相应的定义:
data_t ImageCache::IBRAM[MAX_IMAGE_CACHE_SIZE];
imgcacheaddr_t ImageCache::line_width;
void ImageCache::setNextChannel(data_t value) {
imgcacheaddr_t MAX_ADDR = (line_width * NUM_IMG_CACHE_LINES - 1);
// Write Value into IBRAM
IBRAM[curr_img_cache_addr] = value;
// Check and Wrap Write Address into IBRAM
if (curr_img_cache_addr == MAX_ADDR)
curr_img_cache_addr = 0;
else
curr_img_cache_addr++;
}
void ImageCache::setLayerConfig(layer_t &layer) {
#pragma HLS inline
width_in = layer.width;
height_in = layer.height;
ch_in = layer.channels_in;
line_width = ch_in * width_in;
loads_left = line_width * height_in;
curr_img_cache_addr = 0;
#pragma HLS Resource variable = loads_left core = MulnS latency = 2
reset();
}如上,IBRAM的开辟,但是针对具体的层,我们的通过MAX_ADDR = (line_width * NUM_IMG_CACHE_LINES - 1);来进行,然后line_width = ch_in * width_in;所以,归根结底,最大的值为ch_in * width_in* NUM_IMG_CACHE_LINES。我们可以输出MTCNN的此最大值。
33convIn max IBRAM num is 1536
33convIn max IBRAM num is 2520
33convIn max IBRAM num is 3904
Run Onet
33convIn max IBRAM num is 576
33convIn max IBRAM num is 2944
33convIn max IBRAM num is 2560通过在每层卷积输出中间结果,我们看到最大的IBRAM为3904(以后网络结构更改需要重新输出此值并进行调整)。
4.2 写入IBRAM顺序
我们需要注意到zynqNet与MTCNN中feature-map的不同,MTCNN中的feature-map的排列方式为for channel,for height. for width.而zynqNet中的排列方式为for height,for width, for channel.所以在读取的过程中会有一定的差别。这样,无论DRAM的IBRAM还是IBRAM到PE之中,的地址映射顺序都会产生变化。
写入IBRAM的顺序我们按照zynqNet的模式来进行,IBRAM地址一直累加。直到累加到最大值。然后归为0继续进行。
void ImageCache::reset(){
cur_IBRAM_addr=0;
};
//load whole row from DRAM to IBRAM (in hardware is loop for row/col/channel_In)
void ImageCache::loadRowDRAM_2_IBRAM(float * input_ptr){
#pragma HLS inline
L_DRAM_PRELOADROW_X: for (int cur_col = 0; cur_col < in_width; cur_col++) {
MemoryController::setPixelLoadOffset();
loadPixelDRAM_2_IBRAM(input_ptr);
}
};
void ImageCache::loadPixelDRAM_2_IBRAM(float * input_ptr){
#pragma HLS inline
L_PRELOAD_PIXEL_FROM_DRAM: for (int ci = 0; ci < in_ChannelNum; ci++) {
#pragma HLS pipeline II = 1
#pragma HLS latency min=4
float px = MemoryController::loadInputChannelPixel(input_ptr,ci);
writeNextChannelPixel_2_IBRAM(px);
}
};
void ImageCache::writeNextChannelPixel_2_IBRAM(float pixel){
// Write Value into IBRAM
IBRAM[cur_IBRAM_addr] = pixel;
// Check and Wrap Write Address into IBRAM
if (cur_IBRAM_addr == MAX_IBRAM_ADDR)
cur_IBRAM_addr = 0;
else
cur_IBRAM_addr++;
};嵌套循环,for row, for col, for channel_in。我们保证了写入顺序的正确。
4.3 从DRAM读出的顺序
在float px = MemoryController::loadInputChannelPixel(input_ptr,ci);将图像从DRAM读出为像素值。我们现在就要确定如何将此值从DRAM中读出。读出此值之前,我们需要设定相应的偏移量以及偏移地址。
我们定义此函数功能为,从DRAM中读出当前row,col,与ci的位置的像素。
- MTCNN与zynqNet的DRAM上的像素空间排列顺序不一样,MTCNN为for channel,row,col
- zynqNet的循环顺序与MTCNN不一样,zyqnNet是根据输入图像像素位置循环,MTCNN是输出图像像素位置循环
因此我们将MTCNN加载入IBRAM的顺序设置为整行整行的加载入IBRAM。
相应的偏移地址:
input_pre_loc=cur_channel_in*in_ChannelPiexls+cur_row_out*stride*in_width+stride*cur_col_out;
所以,给定一个当前cur_row与cur_col,则相应的输入的位置为:
//load input piexl from DRAM to BRAM
void MemoryController::setPixelLoadRowOffset(int row_to_load){
pixel_loadRow_DRAM_offset=row_to_load*in_width*stride;
cur_loadPiexel_col=0;
};
void MemoryController::setPixelLoadOffset(){
load_pixel_offset=pixel_loadRow_DRAM_offset+stride*cur_loadPiexel_col;
cur_loadPiexel_col++;
};
float MemoryController::loadInputChannelPixel(float * input_ptr,int ci){
float px=input_ptr[load_pixel_offset+ci*in_channel_pixels];
return px;
};第一个为设置行的偏移量,然后计算像素值的偏移量,像素值的列的位置实现自增,最终为加载相应DRAM上的channel值。
这样,我们每加载一行之前,我们先设置相应的行偏移量,然后加载相应的行进入BRAM,加载的过程之中,每加载一个像素点,DRAM上的列的位置自增,继续加载进入下一个。
4.4 加载的顺序
我们将加载顺序设置为整行整行的加载入BRAM,运用全局变量int MemoryController::cur_loadPixel_row;,来控制加载入的行,在输出行循环的时候运用变量来实现。
MemoryController::setPixelLoadRowOffset();
ImageCache::loadRowDRAM_2_IBRAM(input_ptr);
MemoryController::setPixelLoadRowOffset();
ImageCache::loadRowDRAM_2_IBRAM(input_ptr);
//--------------nested loop for convolution----------------------------
#pragma omp parallel for
for(cur_row_out=0;cur_row_out其中,cur_loadPixel_row初始值为0,每加载一行之后,都会对相应的行地址进行自增,运用判断来确定相应的加载是否停止。
4.5 IBRAM上的值的验证
IBRAM上的地址的映射与input_ptr的不同,我们设计相应的程序,我们将地址映射进行验证。
针对每个filter循环之中的像素点。
//test IBRAM
//in for filter_row for filter_col
int IBRAM_line_loc=(cur_row_out*stride+filter_row)%NUM_IMG_CACHE_LINES;
int IBRAM_col_loc=cur_col_out+filter_col;
int IBRAM_loc=ImageCache::in_ChannelNum*(IBRAM_line_loc*ImageCache::in_width+IBRAM_col_loc)+cur_channel_in;
if((input_ptr[input_loc])!=ImageCache::IBRAM[IBRAM_loc])
printf("ERROR!");程序没有输出Error,则表明图像加载正确。我们可以将相应的DRAM上的图像加载进入IBRAM,并且可以用正确的映射在IBRAM上取出图像。
4.6 从IBRAM读出
//load piexl from IBRAM out to PE
int ImageCache::calcu_IBRAM_row_offset(int cur_row){
int IBRAM_line=cur_row%NUM_IMG_CACHE_LINES;
int IBRAM_line_offset=IBRAM_line*in_width*in_ChannelNum;
return IBRAM_line_offset;
};
float ImageCache::get_IBRAM_Pixel(const int IBRAM_line_offset, const int cur_col,
const int channel_in){
int IBRAM_col_offset=cur_col*in_ChannelNum;
int IBRAM_loc=IBRAM_line_offset+IBRAM_col_offset+channel_in;
float px=IBRAM[IBRAM_loc];
return px;
}读出时,先计算相应的行偏移,然后根据列与通道计算出相应的偏移量从IBRAM之中将像素读出来。
4.7 读入ProcessingElement的buffer
之前我们通过相应的位置映射从input_ptr之中读入buffer,现在,我们舍去inpu_ptr,而是运用上面的映射重新将其读入buffer。
float pixel_buffer[9];
ProcessingElement::loadPixel_buffer(cur_row_out*stride, stride*cur_col_out,
cur_channel_in, pixel_buffer);每个像素点根据相应的输入图像对应的行与列加载。在每个输出的像素点上进行滤波器的循环,直接将相应的值加载入buffer之中。
//get IBRAM pixel into buffer
void ProcessingElement::loadPixel_buffer(const int up_row,const int left_col,
const int cur_In_channel, float pixel_buffer[9]){
#pragma HLS inline
#pragma HLS pipeline
load_pixel_2_PE_row_loop:
for (int cur_filterRow=0;cur_filterRow<3;cur_filterRow++){
int pixel_row_to_load=up_row+cur_filterRow;
int IBRAM_line_offset=ImageCache::calcu_IBRAM_row_offset(pixel_row_to_load);
load_pixel_2_PE_col_loop:
for (int cur_filterCol=0;cur_filterCol<3;cur_filterCol++){
int pixel_col_to_load=left_col+cur_filterCol;
float px=ImageCache::get_IBRAM_Pixel(IBRAM_line_offset,pixel_col_to_load,
cur_In_channel);
pixel_buffer[3*cur_filterRow+cur_filterCol]=px;
}
}
};这次,值是从IBRAM之中读出的。
//load piexl from IBRAM out to PE
int ImageCache::calcu_IBRAM_row_offset(int cur_row){
int IBRAM_line=cur_row%NUM_IMG_CACHE_LINES;
int IBRAM_line_offset=IBRAM_line*in_width*in_ChannelNum;
return IBRAM_line_offset;
};
float ImageCache::get_IBRAM_Pixel(const int IBRAM_line_offset, const int cur_col,
const int channel_in){
int IBRAM_col_offset=cur_col*in_ChannelNum;
int IBRAM_loc=IBRAM_line_offset+IBRAM_col_offset+channel_in;
float px=IBRAM[IBRAM_loc];
return px;
}添加相应的验证:
float pixel_buffer[9];
ProcessingElement::loadPixel_buffer(cur_row_out*stride, stride*cur_col_out,
cur_channel_in, pixel_buffer);
//test loaded pixel[9]
for (filter_col=0;filter_col<9;filter_col++){
if(pixel_buffer[filter_col]!=pixels[filter_col])
printf("Error!");
}验证无误,说明可以读出相应的像素值。可以直接将此buffer值送入macc模块之中进行运算。
ProcessingElement::macc2d(pixel_buffer,weights,macc_sum);五、weightCache
相较于图像,权重是一次性将一层的权重一起读到WBRAM之中。
5.1 WBRAM的大小
zynqNet之中:
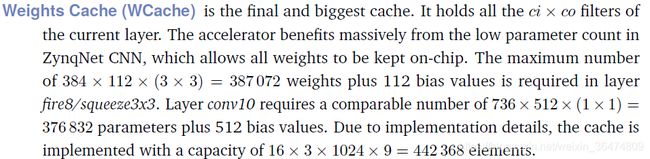
zynqNet中的权重是四维向量的权重,四维向量的运算一来繁琐,二来容易出错。为了避免三维权重带来的影响,我们将权重设为三维的权重。
WBRAM[N_PE][MaxFiltersPer_PE][9]
为得到相应的输出,我们设置相应的运算
//parameters about WBRAM
int out_channelNum=weightIn->out_ChannelNum;
printf("Co num = %d \n",out_channelNum);
int max_co_Num_per_PE=(out_channelNum+N_PE-1)/N_PE;
printf("max_co_Num_per_PE= %d \n",max_co_Num_per_PE);
int max_filters_per_PE=max_co_Num_per_PE*weightIn->in_ChannelNum;
printf("max_filters_per_PE= %d\n \n",max_filters_per_PE);
if(max_co_Num_per_PE>MAXCO_PER_PE)MAXCO_PER_PE=max_co_Num_per_PE;
if(max_filters_per_PE>MAX_FILTERS_PER_PE)MAX_FILTERS_PER_PE=max_filters_per_PE;
printf("-----------%d %d --------\n",MAXCO_PER_PE,MAX_FILTERS_PER_PE);输出最多时为每个PE上最大的输出通道为8,最多的filter数为512,所以我们将BRAM的尺寸定为WBRAM[8][512][9]
5.2 在WBRAM的地址
根据相应的输入与输出通道计算出权重在WBRAM上的位置。
void WeightsCache::get_WBRAM_addr(const int cur_ci, const int cur_co,int &PEID, int &filterID){
PEID=cur_co%N_PE;
filterID=(cur_co/N_PE)*inChannelNum+cur_ci;
}MTCNN的权重的顺序为for out_channel, for in_channel, for 3*3filter
5.3 从DRAM加载入WBRAM
根据计算得到的WBRAM的地址,我们直接从DRAM之加载权重入WBRAM之中。
void WeightsCache::load_WBRAM_from_DRAM(float * weight_ptr){
int PEID,filterID;
float *WBRAM_ptr; float *weight_DRAM_ptr;
for(int cur_co=0;cur_co5.4 WBRAM的验证
验证WBRAM的权重值与加载出的weight[9]一致
//test WBRAM
int PEID,filterID;
WeightsCache::get_WBRAM_addr(cur_channel_in,cur_channel_out,PEID,filterID);
float * WBRAM_ptr=WeightsCache::WBRAM[PEID][filterID];
for(int i=0;i<9;i++){
if(WBRAM_ptr[i]!=weights[i])printf("WBRAM ERROR!");
}5.5 从WBRAM中读入到buffer
void WeightsCache::get_9_weights_to_buffer(int cur_ci, int cur_co,float weight_buffer[9]){
// Array Partitioning
#pragma HLS ARRAY_PARTITION variable = WBRAM complete dim = 1 // PE ID
//#pragma HLS ARRAY_PARTITION variable = WBRAM complete dim = 2 // block ID
//#pragma HLS ARRAY_PARTITION variable = WBRAM complete dim = 4 // weight ID
#pragma HLS RESOURCE variable = WBRAM core = RAM_S2P_BRAM latency = 3
int PEID,filterID;
WeightsCache::get_WBRAM_addr(cur_ci,cur_co,PEID,filterID);
for(int i=0;i<9;i++){
weight_buffer[i]=WBRAM[PEID][filterID][i];
}
}5.6 验证buffer正确
float weights_buffer[9];float macc_sum;
WeightsCache::get_9_weights_to_buffer(cur_channel_in,cur_channel_out,weights_buffer);
//test weights_buffer
for(int i=0;i<9;i++){
if(weights_buffer[i]!=weights[i])printf("weight buffer ERROR!");
}