tensorflow从入门到放弃再到精通(3.3):手写数字图片识别神经网络搭建
本节使用tensorflow来搭建神经网络
1.搭建网络
对于第一层网络模型来说,它接受的输入是![]() ,输出的1为
,输出的1为![]() ,设计为长度是256的向量,我们不需要显示的编写ReLU(
,设计为长度是256的向量,我们不需要显示的编写ReLU(![]() )的计算逻辑。
)的计算逻辑。
#创建一层网络,设置输出节点为256,激活函数为ReLU
layers.Dense(256,activation='relu')
在tensorflow中的Sequential容器可以很方便的搭建多层的网络,对于三层网络的搭建,我们能够快速的完成
#利用Sequential容器封装3个神经网络,前网络输出默认作为后网络的输入
model = keras.Sequential([ 3个非线性层的嵌套模型
layers.Dense(256, activation('relu')), # 隐藏层 1
layers.Dense(128, activation('relu')), # 隐藏层 2
layers.Dense(10)]) # 输出层,输出节点数为 10第一层输出的节点为256,第二层输出的节点为128,最后输出为10。直接调用这个模型的对象model(x)就可以返回模型最后一层的输出o。
搭建完了神经网络的对象,输入给定的x,调用model(x)得到模型输出o,通过mse计算损失值L;
with tf.GradientTape() as tape: # 构建梯度记录环境
x = tf.reshape(x, (-1,28*28)) # 打平操作,[b, 28, 28] => [b, 784]
out = model(x) # Step1. 得到模型输出 output [b, 784] => [b, 10]
y_onehot = tf.one_hot(y, depth=10) # [b] => [b, 10]
loss = tf.square(out-y_onehot) # 计算差的平方和,[b, 10]
loss = tf.reduce_sum(loss)/x.shape[0] #计算每个样本的平方误差
在利用tensorflow提供提供的自动求导函数tape.gradient(loss,model.trainable_variables)求出模型中所有参数的梯度信息,
# Step3. 计算参数的梯度 w1, w2, w3, b1, b2, b3
grads = tape.gradient(loss, model.trainable_variables)
计算获得的梯度结果使用 grads 列表变量保存。在使用optimizers对象自动按照梯度更新法则去更新模型的参数
# 自动计算梯度
grads = tape.gradient(loss,model.trainable_variables)
# w' = w - lr * grad,更新网络参数
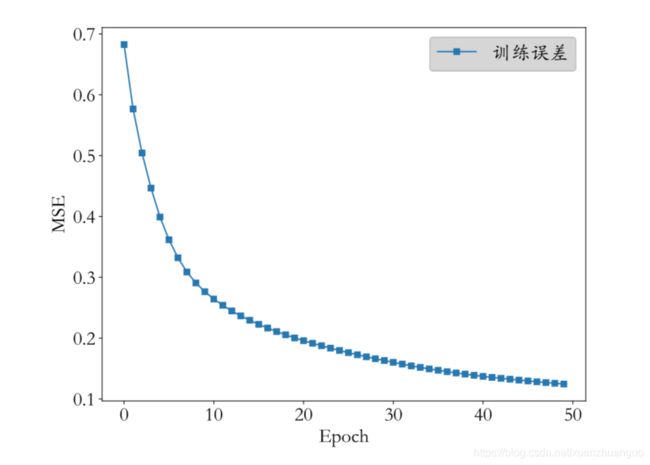
optimizer.apply_gradients(zip(grads, model.trainable_variables))循环多次之后,就能使用训练好的模型去预测位置的图片的类型概率分布。手写数字图片 MNIST 数据集的训练误差曲线如图,由于 3 层的神经网络表达能力较强,手写数字图片识别任务相对简单,误差值可以较快速、稳定地下降,其中,把对数据集的所有样本迭代一遍叫作一个 Epoch,我们可以在间隔数个 Epoch 后测试模型的准确率等指标,方便监控模型的训练效果。