在分类问题中,我们经常遇到一种分类结果只有 是(1) 或 不是(0)两种答案的问题,例如:
这是垃圾邮件(1) 或 这不是垃圾邮件(0)
这是有瑕疵的产品(1) 或 这是没有瑕疵的产品(0)
这类问题的预测值,只有一个离散的取值(0或者10),类似于逻辑函数,所以处理此类二元分类的方法叫逻辑回归。什么是归回(Regression)呢?顾名思义:a process for determining the statistical relationship between a random variable and one or more independent variables that is used to predict the value of the random variable。
简单来说,回归就是找出已知变量间的统计学关系。这种关系满足一个计算公式h(x),这个公式的自变量就是已知的数据x,函数值h(x)就是要预测的目标值。这一计算公式称为回归方程,得到这个方程的过程就称为回归。
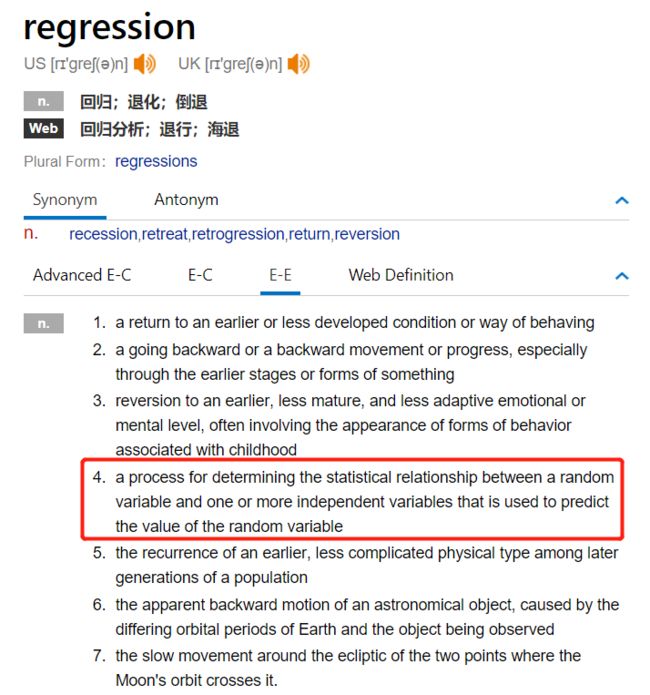
逻辑回归的预测值,
只取(0,1)两个值,如下:
由此,我们使用标准Logistic函数(logistic function),也称为Sigmoid函数(sigmoid function),参考《AI数学基础4-Sigmoid函数》,将预测值归一化到区间(0,1)内,如下:
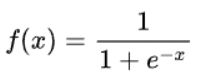
Sigmoid函数求导有一个特性
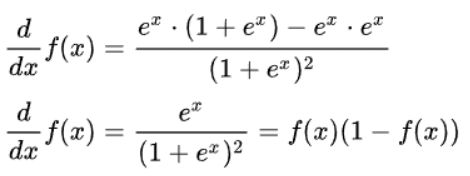
可以简记为:
该特性将在下面的推导中用到。
再回顾一下问题:
我们有一组已知的特征值,也叫输入变量,记作X,大写代表特征值向量,x代表一个样本的特征值;
一组已知特征值的输出值,也叫标签,记作Y,输出值向量, y 代表一个样本的输出值;
X 与 Y 之间的关系,记作H(X),H(X)里面的参数向量,记作W
我们的目标是:找到一个W,使得H(X)尽可能的与Y接近,或者叫相似(Likelihood),为了方便表达,约定标记:

根据推断统计学(Statistical inference)理论,我们要找到这个W,使得H(X)尽可能的与Y接近,就需要构造出W的似然函数L(W)。
为此,我们先要求得P(Y|X)的表达式,为了简化推导,先求一个样本的p(y|x),如下:
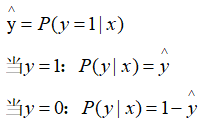
把
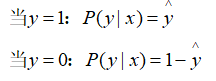
合并为一个表达式,即:
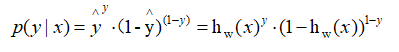
训练样本相互独立,对m个训练样本,整体的似然函数为:
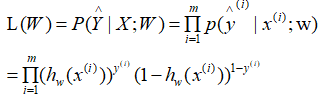
得到似然函数后,我们的目标就是,求取一个W,使得似然函数的值最大。
为了简化计算,我们对L(W)取Log,Log函数是单调递增函数;Log(L(W))最大,也意味着L(W)最大,如下:
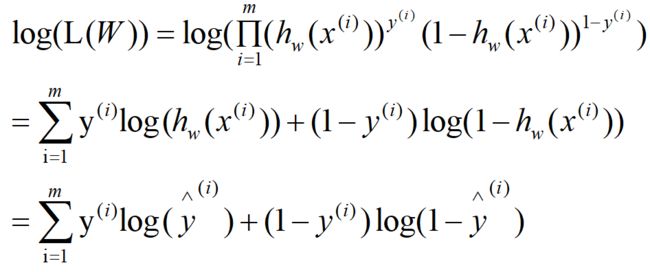
为了方面表示,我们把Log(L(W))记作:
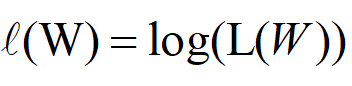
似然函数描述的是预测值与实际值的相似程度,似然函数值越大,说明越相似,所以我们希望求的它的最大值。
对于单个样本,定义一个损失函数(Loss function),用于衡量预测值与实际值的接近程度,损失函数值越小,说明“损失”越小,即衡量预测值与实际值越接近。由于似然函数单调递增,所以,可以用似然函数的负数来表示损失函数,即:
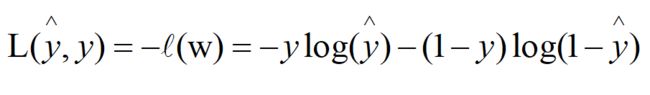
对于整个训练样本,且样本相互独立,定义代价函数(cost function),如下:
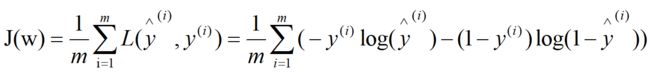
我们的目标是:找到适合的参数w,让代价函数的值最小,即总代价最低
推导完毕