计算机三级 数据库技术 学习笔记
版权声明:本文为CSDN博主「RanLZ」的原创文章,转载请附上原文出处链接。
计算机三级 数据库技术
第一章 数据库应用系统开发方法
1.1 数据库应用系统生命周期
1.1.1 软件工程与软件开发方法
- 瀑布模型
- 快速原型模型
- 螺旋模型
1.1.2 DBAS生命周期模型
p s . ps. ps.按照瀑布模型原理设计
D B A S DBAS DBAS 的生命周期由以下五个基本活动组成:
- 项目规划
- 需求分析
- 系统设计
- 实现与部署
- 运行与维护
3 3 3条设计主线:
- 数据组织与存储设计
- 数据访问与处理设计
- 应用设计
设计阶段分为以下3个步骤:
- 概念设计
- 逻辑设计
- 物理设计
1.2 规划与分析
1.2.1 系统规划与分析
- 任务称述
- 确定任务目标
- 确定系统范围和边界
- 确定用户视图
1.2.2 可行性分析
- 经济可行性
- 技术可行性
- 操作可行性
- 开发方案选择
1.2.3 项目规划
- 确定项目的目标和范围
- 更加 D B A S DBAS DBAS 软件开发模型,分解和定义整个项目包括的工作活动和任务
- 估算完成该项目的规模及所需各种资源
- 制定合理的 D B A S DBAS DBAS 项目计划
1.3 需求分析
- 需求获取
- 需求分析
- 需求描述
- 规范说明
- 需求验证
1.3.1 数据需求分析
描述用户需要组织的信息内容形成数据字典。
数据字典包括以下五部分:
- 数据项
- 数据结构
- 数据流
- 数据存储和处理过程
1.3.2 功能需求分析
描述系统要做什么。
1.数据处理需求分析
数据处理需求分析结果可表示为数据流图 ( D F D ) (DFD) (DFD) 或 D B A S DBAS DBAS 应支持的各种数据处理事务规范。
事务规范包括以下几方面的事物描述信息:
- 事务名称。
- 事务描述。功能、性能、完整性约束等方面的描述。
- 事务所访问的数据项。
- 事务用户。启动或执行该事务的事件或用户。
数据需求分析与数据处理需求分析的结果组织在一起,可以构成数据字典文档,该文档也被成为数据规范说明书。
2.业务规则需求分析
应用领域业务规则(又称为业务处理逻辑、业务逻辑)描述了应用领域中的业务功能、处理流程和步骤。
1.3.3 性能描述
描述系统应当做到什么程度。
D B A S DBAS DBAS 性能指标:
- 数据操作响应时间,或数据访问响应时间。
- 系统吞吐量。
- 运行并发访问的最大用户数。
- 每 T P S TPS TPS 代价值。
影响 D B A S DBAS DBAS 性能的主要因素:
- 系统的硬件资源。
- 网络通信设备性能。
- 操作系统环境。
- 数据库的逻辑设计和物理设计质量。
- D B M S DBMS DBMS 的配置和性能。
- 数据库应用程序自身。
1.3.4 其他需求分析
1.存储需求分析
- 初始数据库大小。
- 数据库增长速度。
2.安全性需求分析
- D B A S DBAS DBAS 系统应达到的安全控制级别。
- 各类用户的数据视图和视图访问权限。
- D B A S DBAS DBAS 应有的口令保护机制或者其他安全认证机制。
3.备份和恢复需求分析
- D B A S DBAS DBAS 运行过程中备份数据库的时间和备份周期。
- 备份数据是备份全部数据,还是其中的一部分。
- 备份方式是采用完全备份还是采用差异备份。
1.4 系统设计
如果需求分析阶段的任务是解决“干什么”的问题,那么系统设计阶段的任务是确定”怎么干“。
1.4.1 概念设计
1.数据库概念模型设计
数据库概念模型可能采用多种方式表示,如最常见的 E R ER ER 方法。
2.系统总体设计
- D B A S DBAS DBAS 体系结构设计。
- D B A S DBAS DBAS 系统硬件平台的选型和配置。
- 应用软件结构设计。
- 业务规则初步设计。
- 对系统关键技术进行方案选型和初步设计。
1.4.2 逻辑设计
- 数据库逻辑结构设计。
- 应用程序概要设计。
- 数据库事务概要设计。
1.4.3 物理设计
- 数据库物理结构设计。
- 数据库事务详细设计。
- 应用程序详细设计。
1.5 实现与部署
- 建立数据库结构。
- 数据加载。
- 事务和应用程序的编码及测试。
- 系统集成、测试与试运行。
- 系统部署。
1.6 运行管理与维护
主要包括日常维护、系统监控与分析、系统性能优化调整、系统进化升级等。
第二章 需求分析
2.1 需求分析
2.1.1 需求分析的概念与意义
需求分析是描述待开发的系统所要完成的功能。
目标是深入描述软件的功能和性能,确定软件设计的约束和软件同其他系统元素接口细节,定义软件的其他有效需求。
软件产品的下列特性使得需求获取困难重重:
- 软件功能复杂
- 需求的可变性
- 软件产品的不可见性
通常,一个计算机应用系统的需求分析工作是在系统分析人员与用户不断交互的过程中完成的。
2.1.2 需求获取的方法
- 面谈
- 实地观察
- 问卷调查
- 查阅资料
2.1.3 需求分析过程
- 标识问题
- 建立需求模型
- 描述需求
1). 需求概述
2). 功能需求
3). 信息需求
4). 性能需求
5). 环境需求
6). 其他需求 - 确认需求
需要评审委员会审核下列内容:
1). 功能需求
2). 数据需求
3). 性能
4). 数据管理
5). 其他需求
2.2 需求分析方法
2.2.1 需求分析方法概述
结构化分析与功能建模方法主要有 D F D DFD DFD 、 I D E F 0 IDEF0 IDEF0 等。
结构化分分析方法的基本特征是 抽象 和 分解。
结构化分析及建模方法的主要优点是:
- 不过早陷入具体的细节。
- 从整体或宏观入手分析问题。
- 通过图像化的模型对象直观地表示系统要做什么,完成什么功能。
- 图像化建模方法方便系统分析员理解和描述系统。
- 模型对象不涉及太多技术术语,便于用户理解模型。
2.2.2 DFD需求建模方式
D F D DFD DFD 建模方法的核心是 数据流。
1.DFD方法的基本元素
- 数据流。数据流用一个箭头描述数据的流向,箭头上标注的内容可以是信息说明或数据项。
- 处理。在图中用矩形框表示。指向处理的数据流为该处理的输入数据,离开处理的数据流为该处理的输出数据。
- 数据存储。对其进行的存取分别以指向或离开数据存储的箭头表示。
- 外部项(也称数据源或数据终点)。以圆角框或平行四边形表示。

2.DFD图
采用自顶向下逐步细化的结构化分析方法表示目标系统。

3.DFD建模过程
- 明确目标,确定系统范围。
- 建立顶层 D F D DFD DFD 图。
- 构建第一层 D F D DFD DFD 分解图。
- 开发 D F D DFD DFD 层次结构图。
- 保持均匀的模型深度。
- 按困难程度进行选择。
- 如果一个处理难以确切命名,可以考虑对它重新进行分解。
- 检查确认 D F D DFD DFD 图。
- 父图中描述过的数据流必须要在相应的子图中出现。
- 一个处理至少有一个输入流和一个输出流。
- 一个存储必定有流入的数据流和流出的数据流。
- 一个数据流至少有一端是处理框。
- 模型图中表达和描述的信息是全面的、完整的、正确的、一致的。
2.2.3其他需求建模方法
1.IDEF0方法简介
I D E F 0 IDEF0 IDEF0 描述系统功能及相互关系;
I D E F 1 IDEF1 IDEF1 描述系统信息及其数据之间的联系;
I D E F 2 IDEF2 IDEF2 用于系统模拟,建立动态模型。
组成 I D E F 0 IDEF0 IDEF0 图的基本元素是矩形框和箭头。
矩形框代表功能活动,写在矩形框中的动词短语描述功能活动的名称,活动的编号按照要求写在矩形框右下角指定位置。

- 左侧输入箭头表示活动需要的数据;
- 矩形框上方控制箭头描述了影响这个活动执行的事件或约束条件;
- 右边输出箭头说明由活动产生的结果和信息;
- 下方的进入的机制箭头表示实施该活动的物理手段或完成活动需要的资源(计算机系统、人或组织)。
输入与控制二者的作用是有区别的,输入强调被活动消耗或变化的内容,而控制强调对活动的约束条件。
每个箭头所表示的数据用一个名词短语描述,数据可以是信息或对象。
2.UML用例模型简介
U M L UML UML 方法采用面向对象思想建模,其中的用例模型用于描述系统功能需求。
2.2.4 DFD与IDEF0比较
- 在 I D E F 0 IDEF0 IDEF0 图中箭头不是强调流或顺序,而是强调数据约束。
- 相对 D F D DFD DFD 图, I D E F 0 IDEF0 IDEF0 图中的箭头有更加丰富的语义,不仅能够表示出数据流,还可以表示出控制流和说明处理或活动实例方式的一些约束。
- 两个模型的组成元素更简单, I D E F 0 IDEF0 IDEF0 模型结构更清楚,容易理解,更适合用于大型复杂系统的需求建模。
第三章 数据库结构设计
3.1 数据库概念设计
概念设计是数据库设计的核心环节。通过对用户需求进行综合、归纳与抽象,形成一个独立于具体DBMS的概念模型。
3.1.1 概念设计的任务
- 定义和描述应用领域涉及的数据范围。
- 获取应用领域或问题领域的信息模型。
- 描述清楚数据的属性特征。
- 描述清楚数据之间的关系。
- 定义和描述数据的约束。
- 说明数据的安全性要求。
- 支持用户的各种数据处理需求。
- 保证信息模型能转化成数据库的逻辑结构(即数据库模式)。
3.1.2 概念设计的依据及过程
1.概念设计的依据
依据:数据库概念设计以需求分析的结果为依据,即说明书、 D F D DFD DFD 图以及需求阶段收集到的应用领域中的各类报表等。
结果:概念设计需要构造信息模型( E R ER ER )与编写概念设计说明书。
2.概念设计的过程
- 明确建模目标。(确定模型覆盖的问题范围)
- 定义实体集。(自底向上标识和定义实体集)
- 定义联系。(实体间关联关系)
- 建立信息模型。(构造 E R ER ER 模型)
- 确定实体集属性。(属性描述一个实体集的特征或性质)
- 对信息模型进行集成与优化。(检查和消除命名不一致、结构不一致等)
概念设计是 D B DB DB 设计的核心环节。概念数据模型是对现实世界的抽象和模拟。
3.1.3 数据建模方法
1.ER建模方法
- 实体或实例:客观存在并可相互区分的事物叫实体。
- 实体集:同型实体的集合称为实体集。
- 属性:实体所具有的某一特性。一个实体可以由若干个属性来刻画。每个属性的取值范围称为域。
- 码:实体集中能唯一标识每一个实例的属性或属性组称为该实体集的码。用来区别同一实体集中的不同实体的称为主码。
- 联系:描述实体之间的相互关系,联系也可以有属性。同类联系的集合称为联系集。
- 一对一联系(1:1)
- 一对多联系(1:n)
- 多对多联系(m:n)
- 符号
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dg1Rovot-1581409962530)(en-resource://database/1977:0)]
2.IDEF1X建模方法(了解)
I D E F 1 X IDEF1X IDEF1X 侧重分析、抽象和概括应用领域中的数据需求,被称为数据建模方法。
3.2 数据库逻辑设计
3.2.1 概述
数据库逻辑设计的任务是把数据库概念设计的结果( E R ER ER 模型),转换为具体的数据库管理系统支持的数据模型。

3.2.2 个人补充
1.关系模型
关系模型就是用二维表结构来表示实体及实体之间联系的模型。
关系的描述称为关系模式。关系模式由五部分组成,即它是一个五元组:R(U,D,DOM,F)。
- R:关系名。
- U:组成该关系的属性名集合。
- D:属性组U中属性所来自的域。
- DOM:属性到域的映射
- F:属性组U上的一组数据依赖。
由于 D D D 、 D O M DOM DOM对模式设计的关系不大,这里把关系模式简化为一个三元组:R
当且仅当 U U U上的一个关系 R R R 满足 F F F 时, R R R 称为关系模式 R < U , F > R
关系数据库设计的核心:关系模式的设计。
2.数据依赖
定义:设 R ( U ) R(U) R(U) 是一个属性集 U U U 上的关系模式, X X X 和 Y Y Y 是 U U U 的子集。若对于 R ( U ) R(U) R(U) 的任意一个可能的关系 r r r , r r r 中不可能存在两个元组在 X X X 上属性组相等,而在 Y Y Y 上的属性值不等,则称“X函数确定Y”或“Y函数依赖于X”,记作 X → Y X \rightarrow Y X→Y。
2.1函数依赖
普遍存在于生活中,这种依赖关系类似于数学中的函数 y = f ( x ) y=f(x) y=f(x),自变量x确定之后,相应的函数值y也就唯一地确定了。
2.2多值依赖
教师号可能多值依赖课程号,因为给定一个(课程号,参考书号)的组合,可能有对应多个教师号。这是因为多个老师可以使用相同或不同的参考书上同一门课。
简单点讲,函数就是唯一确定的关系;多值依赖却。
2.3函数依赖的几种特例
2.3.1 平凡函数依赖与非平凡函数的依赖
如果 X → Y X \rightarrow Y X→Y,且 Y ⊄ X Y \not\subset X Y⊂X,则 X → Y X \rightarrow Y X→Y 称为非平凡函数依赖。
若 Y ⊆ X Y \subseteq X Y⊆X,则称 X → Y X \rightarrow Y X→Y 为平凡函数依赖。
由于 Y ⊆ X Y \subseteq X Y⊆X时,一定有 X → Y X \rightarrow Y X→Y,平凡函数依赖必然成立,没有意义,所以一般所说的函数依赖总是指非平凡函数依赖。
2.3.2 完全函数依赖与部分函数依赖
完全函数依赖:
成绩依赖于学号和课程号两个字段的组合;但只知道学号无法确定成绩,同理只知道课程号也无法确定成绩;只有学号和课程号组合在一起才能标识哪个学生哪门课程的成绩;
因此 (学号,课程号) → \rightarrow → 成绩 是“完全函数依赖”。
部分函数依赖:
姓名、性别和班级三个属性只依赖于主键中的学号,与“课程号”无关。
因此(学号,课程号) → \rightarrow → 姓名 是“部分函数依赖”。
课程名和学时数只依赖于课程号,
因此(学号,课程号) → \rightarrow → 课程名 是“部分函数依赖”。
2.3.3 传递函数依赖
班主任依赖于班级,与学号无关,与课程号也无关。又因班级依赖于学号,所以班主任间接依赖于学号。
因此,(学号,课程号) → \rightarrow → 班主任 是“传递函数依赖”。
3.候选码、主码、外码
如果某属性组的值能唯一确定整个元组的值,则称该属性组为候选码或侯选关键字。
候选码如果有多个,可以选其中的一个作为主码。
属性或属性组 X X X 不是关系模式 R R R 的码(不是主码或候选码),但 X X X 是另一个关系模式的码,则称 X X X 是 R R R 的外部码,也称外码 。
4.范式
关系模式满足的约束条件称为范式。根据满足规范化的程度不同,范式由低到高分为1NF,2NF,3NF,BCNF,4NF,5NF。
- 1NF:如果关系模式 R R R ,其所有属性都是不可再分的基本数据项,则称 R R R 属于第一范式, R ∈ 1 N F R∈1NF R∈1NF。
- 2NF:如关系模式 R ∈ 1 N F R∈1NF R∈1NF,且每个非主属性完全函数依赖于主码,则称 R R R 属于第二范式, R ∈ 2 N F R∈2NF R∈2NF。
- 3NF:如果关系模式 R R R 为 2 N F 2NF 2NF ,并且 R R R 中的每个非主属性不传递依赖于 R R R 的主码,则称关系 R R R 是属于第3范式的, R ∈ 3 N F R∈3NF R∈3NF。
- BCNF:满足3NF且不允许主键的一部分被另一部分或其它部分所决定(即满足3范式,并且主属性之间没有依赖关系)。
3.3 数据库物理设计
3.3.1 物理设计概述
概述:物理数据库设计是设计数据库的存储结构和物理实现方法。
目的:将数据的逻辑描述转换为实现技术规范,设计数据存储方案,以便提供足够好的性能并确保数据库数据的完整性、安全性、 可靠性。
3.3.2 数据库的物理结构
物理设备上的存储结构与存取方法称为数据库的物理结构 。
数据库中的数据以文件形式存储在外设存储介质上。
一个文件在物理上可看作是存放记录的一系列磁盘块组成的,成为物理文件。
数据库的物理结构需要解决如下问题:文件组织、文件结构、文件存取、索引技术。
3.3.3 索引
索引是数据库中独立的存储结构,其作用是提供一种无须扫描每个页面(存储表格数据的物理块)而快速访问数据页的方案。
1.索引技术
索引技术是一种快速数据访问技术。
索引技术的关键:建立记录域取值到记录的物理地址间的映射关系,即索引。
2.索引技术分类
- 有序索引技术:也被称为索引文件机制。利用索引文件实现记录域取值到记录物理地址之间的映射关系。记录域就是查找码,查找码也称排序域。
- 散列技术:也称哈希索引机制。散列技术利用一个散列函数实现记录域取值到记录物理地址间的直接映射关系。这里记录域就是查找码,也称散列函数的排序域或散列域
3.有序索引
- 聚集索引和非聚集索引
- 聚集索引:数据文件中数据记录的排列顺序与索引文件中索引项的排列顺序一致,或者说索引文件中按照其查找码指定的顺序与数据文件中数据文件的排列顺序相一致。
- 非聚集索引:数据文件中数据记录的排列顺序与索引文件中的索引项的排序不一致。
- 一个数据文件只可建立一个聚集索引,但可建立多个非聚集索引。
- 稠密索引与稀疏索引
- 稠密索引:数据文件中每个查找码在索引文件中都对应一个索引记录。
- 稀疏索引:只是一部分查找码的值有对应的索引记录。
- 主索引与辅索引
- 主索引:在数据文件的主码属性值上建立的索引
- 辅索引:在数据文件的非主属性上建立的索引
- 唯一索引:可以确保索引列不包含重复的值。在多列唯一索引的情况下,可确保每个值的组合是唯一的。
- 单层索引和多层索引:当数据文件很大时,即使采用稀疏索引,建立的索引文件也会很大。可以对索引项本身再建立起一级稀疏索引,组成二层索引结构多层索引的典型例子是B数和B+树索引。
3.3.4 数据库物理设计
目标:目标是得到存储空间占用少,数据访问效率高和维护代价低的数据库物理模式。
1. 物理设计内容
- 数据库逻辑模式描述:根据数据库逻辑结构信息设计目标DBMS可支持的关系表(这里称为基本表)的模式信息。
- 文件组织与存取设计:根据应用情况将易变部分与稳定部分、存取频率较高部分与存取频率较低部分分开存放,以提高系统性能。
- 数据分布设计
- 确定系统配置
- 物理模式评估
影响数据文件存储结构的因素:
- 存取时间
- 存储空间利用率
- 维护代价
- ps.这三个方面常常是相互矛盾的
解决办法:
- 适当冗余
- 增加聚簇功能
- ps.必须进行权衡,选择一个折中方案。
2. 数据库逻辑模式描述
- 面向目标数据库描述基本表和视图
- 设计基本表业务规范
3.DB文件组织与存储设计
- 使用事务-基本表交叉引用矩阵

- 估计各事务的执行频率,即单位时间内事务的执行次数
- 对于每张基本表,汇总所有作用于该表上的各事务的操作频率信息,得到如下数据访问估计信息:该表是否被频繁访问,该表中哪些属性列的访问频率较高和作用于这些属性上的操作类型和查询条件类型(等值查询,范围查询)
3.1基本表选择合适的文件结构的原则:
- 如果数据库中的一个基本表中的数据量很少,并且插入、删除、更新等操作很频繁,该基本表可以采用堆文件组织方式。堆文件无需建立索引,维护代价非常低,向表中加载数据访问效率较低,但在数据量较少时,定位文件记录的时间非常短。当需要向新创建的基本表批量加载数据时,可将表的文件结构优先选为堆文件,向表中加载数据后重新调整文件结构,如改为数据查询效率更高的B+树文件。
- 顺序文件支持基于查找码的顺序访问,也支持快速的二分查找。如果用户的查询条件定义在查找码上,则顺序文件是比较合适的文件结构
- 如果用户查询是基于散列域值的等值匹配,特别是如果访问顺序是随机的,则散列文件比较合适,但散列文件组织不适合下列情况:
- 基于散列域值的非精确查询(模糊查询,范围查询)
- 基于非散列域的查询
- B树和B+树文件是实际数据库系统中非常广泛的索引文件结构,适合于定义在大数据量基本表上、基于查找码的等值查询、范围从查询、模糊查询和部分查询。B树和B+树属于动态索引,可以随着数据文件的内容变化不断调整,保证数据查询的性能不会恶化。
5.如某些频繁执行且需要进行多表连接的操作的查询,可以考虑将这些基本表组织为聚集文件,以改善查询效率。
3.2一个基本表建立索引的原则:
- 对于经常需要进行查询、连接、统计操作的,且数据量较大的可以考虑建立索引;而对于经常进行插入、删除、更新操作或小数据量的基本表应尽量避免建立索引 。
- 一个表上除了可以建立一个聚集索引外还可以建立多个非聚集索引。多个索引为用户提供了多个查找码快速访问文件的手段。但是索引越多,对表内数据更新时维护索引所需要的开销就越大。因此对于一个更新频繁的表应该不建或减少索引。
- 索引可以由用户根据需要随时创建或删除,以提高数据查询性能。
3.3对于基本表可以考虑在下面属性上建立索引:
- 表的主码(大部分关系型数据库会自动会为主码建立唯一索引)。
- 在where查询子句中引用率较高的属性。
- 参与连接操作的属性。
- 在Order by子句、group by子句中出现过的属性。
- 在某一范围内频繁搜索的属性,但只有当使用索引查询其结果不超过记录总数20%时索引才有明显效果。
- 如果where子句中同时包含一个表的多个属性,则可以考虑为这些属性建立多属性索引;如果数据库文件需要频繁执行精确匹配查询(等值查询),则可以考虑建立散列索引,而B+树等有序索引更适合于范查询。
- 当一个属性有较多的不同值时,使用索引有明显的作用;当一个属性的不同值很少时,使用索引没有好处。
- 对于包含大量空值的属性建立索引要仔细考虑,因为很多数据库管理系统中的索引不引用具有空值的行,对空值的查找要使用全表扫描来实现。
4.数据分布设计
4.1不同类型数据的物理分布
数据库备份数据、日志文件备份数据用于故障恢复,使用频率低且数据量大,可以存储在磁带中。而应用数据、索引和日志使用频繁,要求响应时间短,必须放在支持直接存取的磁盘存储介质上。
4.2应用数据的划分与分布
- 根据数据的使用特征划分(频繁使用分区和非频繁使用分区)
- 根据时间、地点划分(时间或地点相同的属于同一分区)
- 分布式数据库系统(DDBS)中的数据划分(水平划分或垂直划分)
- 派生属性数据分布(增加派生列或不定义派生属性)
- 关系模式的去规范化(降低规范化提高查询效率)
4.3派生属性划分
派生属性指该属性取值可以根据表中其他属性的取值唯一确定。
44关系模式去规范化
在数据库物理设计阶段,可以根据实际需要对数据库中某些3NF、BCNF模式考虑是否可以降低其规范化程度,以提高查询效率。
3.3.5其他物理设计环节
- 确定系统配置:数据库配置参数(如允许同时使用数据库的用户数、允许同时打开数据库对象数、数据库初始空间大小),磁盘块使用参数,内存缓存区参数(如缓存区个数和大小),时间片大小,装填因子,锁的大小。
- 物理模式评估:对数据库物理设计结果从存取时间、存储空间、维护代价等方面进行评估,重点是时间和空间效率。
第四章 数据库应用系统功能设计与实施
4.1 软件体系结构与设计过程
4.1.1 软件体系结构
软件体系结构又称软件架构,软件体系结构 = {构件,连接件,约束}。
软件体系结构是软件系统中最本质的东西。良好的体系结构必须是普适、高效和稳定的。
软件体系结构有多种风格和类型 ,如分层体系结构、模型-视图-控制器( M V C MVC MVC )体系结构、客户端/服务器体系结构等。
4.1.2 软件设计过程
- 软件开发由设计、实现、测试三个环节组成,设计又包含概要设计和详细设计。
- 概要设计的任务是进行软件总体结构设计,可采用层次结构图建立软件总体结构图。
- 详细设计的任务是进行数据设计、过程设计及人机界面设计。
- 设计原则:模块化、信息隐藏、抽象与逐步求精。
- 软件设计可选用结构化设计方法、面向对象设计方法或面向数据设计方法等。
4.2 DBAS总体设计
DBAS总体设计的任务是确定系统总体框架, 主要内容包括:
- DBAS体系结构设计;
- 软件体系结构设计;
- 软件硬件选型与配置设计;
- 业务规则初步设计。
4.2.1 DBAS体系结构设计
将系统从功能、层次/结构、地理分布等角度进行分解,划分为多个子系统,定义各子系统功能;设计系统的全局控制,明确各子系统间的交互和接口关系。
1.客户/服务器体系结构(C/S)
C / S C/S C/S 结构将数据库管理功能与数据库应用相分离,将 D B M S DBMS DBMS 数据管理功能在客户端和服务器之间进行合理的分布和配置。其中数据库服务器完成DBMS核心功能。而客户端或应用服务器则负责完成用户交互功能,接受用户数据,根据业务规则处理应用任务,生成并向数据库服务器发出数据操作请求,然后从数据库服务器接受数据查询结果并通过客户端反馈给用户。
两层 C / S C/S C/S 结构的数据库应用系统,其特点:
- D B A S DBAS DBAS 的数据管理和数据处理功能被分解并分布在客户端和数据库服务器上。客户端人机交互,数据库服务器数据管理。
- 数据库服务器可以为多个客户端应用提供共享的数据管理功能,避免了为每一个新的应用单独开发对应的服务器端数据管理功能,提高了应用程序相对于数据库的独立性,减少了应用程序的开发和维护代价。
- 客户端可以通过网络访问多个不同数据源。
- 客户端除了完成人机交互功能外,还需要完成面向应用的数据处理功能,负荷较重,属于典型的胖客户端。
2. 浏览器/服务器结构(B/S)
三层浏览器/服务器( B / S B/S B/S )结构,数据处理功能分解并分布在表示层、功能层和数据层三个层次上,分别由 W e b Web Web 浏览器、 W e b Web Web 应用服务器和数据库服务器来实现,其特点是:
- 表示层位于客户端,由Web浏览器实现。客户端功能单一,一般只安装 W e b Web Web 浏览器。没有其他用户应用程序,属于典型的瘦客户端。
- 功能层位于 w e b web web 应用服务器,实现面向具体应用领域的业务规则。
- 数据层位于数据库服务器,通过 D B M S DBMS DBMS 完成具体的数据存储和数据存取等数据管理功能。
三层 B / S B/S B/S 结构将人机交互、应用逻辑处理和数据管理三类功能相互分离,提高了系统的可维护性。
4.2.2 DBAS软件总体设计
应用软件总体设计得到的系统总体结构和分层模块结构可以用模块结构图表示。
4.2.3 软硬件选型与配置设计
为保证DBAS功能性能顺利实现,总体设计阶段需要对软硬件设备做出合理选择,并进行初步配置设计。
软硬件选型涉及内容包括:
- 网络及网络设备选型。
- 数据存储设备及备份方案制定。
- 应用服务器、Web服务器选型。
- 确定系统终端软件环境。
- 确定软件平台及开发语言、工具。
- 系统中间件及第三方软件选型。
考虑以下因素:
- 数据规模:数据量大小、数据增长速度。
- 系统性能:系统响应时间、并发访问需求、系统吞吐量、实时性需求、峰值时系统响应速度。
- 安全可靠性:数据安全性、数据传输安全性、系统访问安全性、设备可靠性。
- 用户需求:用户的特性化需求。
- 项目预算情况。
4.2.4 业务规则初步设计
任务:从系统的角度,规划 D B A S DBAS DBAS 的业务流程,使之符合客户的实际业务需要。
DBAS的各项业务活动具有逻辑上的先后关系,可将它们表示成一个操作序列,并用业务流程图表示。
4.3 DBAS功能概要设计
在总体设计结果基础上,将DBAS应用软件进一步细化为模块/子模块,组成应用软件的系统-子系统-模块-子模块层次结构,并从结构、行为、数据三方面进行设计。
功能角度DBAS系统通常划分四个层次实现:
- 表示层:负责所有与用户交互的功能。
- 业务逻辑层:负责根据业务逻辑需要将表示层获取的数据进行组织后,传递给数据访问层,或将数据访问层获取的数据进行相应的加工后传递给表示层用于展示。
- 数据访问层:负责与DBMS系统进行交互,提取或存入应用系统所需的数据。
- 数据持久层:负责保存和管理应用系统数据。
4.3.1 表示层概要设计
人机界面设计,影响系统易用性。目前第四代是 W I M P WIMP WIMP(窗口、图标、菜单、指示器)与 W e b Web Web 技术、多任务处理技术相结合。
设计原则:
- 用户应当感觉系统的运行始终在自己控制下。
- 当系统发生错误或程序运行时间长时应该提供有意义的反馈信息。
- 一个好的用户界面应该容忍用户的各种操作错误。
- 用户界面应该遵循一定的标准和常规。
- 用户界面应采取灵活多样的数据输入方式,尽量减少用户的输入负担。
- 使用 w e b web web 界面设计应具有简洁性;清晰分类信息,导航;界面一致性;界面美观与交互性能折中平衡。
4.3.2 业务逻辑层概要设计
设计原则:高内聚低(松)耦合,即构件单一原则;构件独立功能;接口简单明确;构件间关系简单,过于复杂,就细化,分解。
高内聚和松耦合是相互矛盾的,分解程度越粗的系统耦合性越低,分解越细的系统内聚度越高。
设计内容:结构,行为,数据,接口,故障处理、安全设计,系统维护和保障等。
4.3.3 数据访问层概要设计
任务:针对 D B A S DBAS DBAS 的数据处理需求设计用于操作数据库的各类事务。
事务概要设计核心在于辨识和设计事务自身处理逻辑,注重流程,不考虑与平台相关、具体操作方法和事务实现机制。
一个完整的事务概要设计包括事务名称、访问的关系表及其数据项、事务逻辑(事务描述)、事务用户(使用、启动、调用该事务的软件模块和系统)。
4.3.4 个人补充
- 事务:事务(Transaction)是访问并可能更新数据库中各种数据项的一个程序执行单元(unit)。
- 事务的特性:原子性、一致性、隔离性、持续性。称为ACID特性。
- 原子性(atomicity)。一个不可分割的工作单位。
- 一致性(consistency)。从一个一致性状态变到另一个一致性状态。
- 隔离性(isolation)。执行不能被其他事务干扰。
- 持久性(durability)。永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。
4.4 DBAS功能详细设计
4.4.1 表示层详细设计
人机界面采用原型迭代法合适,三个步骤:
- 初步设计:设计人机交互命令系统并优化。(总体设计)
- 用户界面细节设计。如组织形式、风格、彩色,操作方式。(概要设计)
- 原型设计与改进(详细设计)
4.4.2 业务逻辑层详细设计
设计各模块内部处理流程和算法、具体数据结构、对外详细接口等。
4.5 应用系统安全结构设计
4.5.1 数据安全设计
- 安全性保护:防止非法用户对数据库的非法使用,避免数据泄露、篡改或破坏。
- 完整性保护:保证数据源的正确性、一致性和相容性。
- 并发性控制:保证多个用户能共享数据库,并维护数据一致性。
- 数据备份与恢复:系统失效后的数据恢复,配合定时备份数据库,不丢失数据。
- 数据加密传输:将一些高级的敏感数据通过一定的加密算法后传输。
1.数据库安全性保护
主要保护方式:
- 用户身份鉴别:Windows身份验证、SQL身份验证。
- 权限控制:对后台数据库是不同用户对数据的不同存取需求设置不同权限;对前台 程序是为每个合法用户设定权限等级,外部用户设置有限查询功能。
- 视图机制:通过视图机制把保密数据对无权用户隐藏。
2.数据库的完整性保护
数据库的完整性指数据库中数据的正确性、一致性及相容性。
方法:设置完整性检查,即对数据设置一些约束条件(如实体完整性、参考完整性、用户自定义完整性)。
完整性约束条件作用对象:列(类型、范围、精度、排序)、元组(记录中各属性之间的联系约束)、关系(若干记录间、关系集合与集合之间的联系)三种级别。
DBAS中,完整性约束功能包括完整性约束条件设置和检查。
3.数据库的并发控制
并发访问:事务在时间上重叠执行。
常用技术:封锁技术,一段时间禁止某用户对数据对象做某些操作以避免数据不一致的问题。
基本的封锁一般包括排他锁( X X X 锁)和共享锁( S S S 锁)两种类型。
- 排它锁(简记为 X X X 锁),写锁,若事务 T T T 对数据对象 A A A 加上 X X X 锁,则只允许 T T T 读取和修改 A A A ,其它任何事务都不能再对 A A A 加任何类型的锁,直到 T T T 释放 A A A 上的锁. 排它锁保证了其它事务在 T T T 释放 A A A 上的锁之前不能再读取和修改 A A A。
- 共享锁(简记为 S S S 锁),读锁,若事务 T T T 对数据对象 A A A 加上 S S S 锁,则其它事务只能再对 A A A 加 S S S 锁,而不能加 X X X 锁,直到 T T T 释放 A A A 上的 S S S 锁。共享锁保证了其它事务可以读 A A A ,但在 T T T 释放 A A A 上的 S S S 锁之前不能对 A A A 做任何修改。
不可避免带来死锁问题,可以考虑以下原则:
- 按同一顺序访问资源。
- 避免事务中的用户交互。
- 采取小事务模式,尽量缩短事务的长度,减少占有锁时间。
- 尽量使用记录级别的锁(行锁),少用表级别的锁。
- 使用绑定连接,使同一应用所打开的两个或多个连接可以相互合作。次级连接获得的任何锁可以像由主连接获得的锁那样持有,反之亦然,因此不会相互阻塞。
4.数据库的备份与恢复
数据库恢复的基本原理:利用存储在系统其他存储器上的冗余数据(即数据备份)来重建。
数据库备份与恢复策略:
- 双机热备(基于Active/Standby方式的服务器热备)。
- 数据转储(也称为数据备份)。
- 数据加密存储(针对高敏感数据)。
5.数据加密传输
常见的数据加密传输手段:
- 数字安全证书
- 对称密钥加密
- 数字签名
- 数字信封
实施:购买第三方中间件产品整合是一个快速有效的解决方案。
4.5.2 环境安全设计
- 漏洞与补丁:定期查找漏洞更新补丁。
- 计算机病毒防护:杀毒软件;实时监控。
- 网络环境安全:防火墙;入侵检测系统;网络隔离(逻辑隔离与物理隔离)。
- 物理环境安全 :如防盗设施;UPS;温湿度报警器等。
4.5.3 制度安全设计
管理层面安全措施。
4.6 DBAS实施
DBAS实施阶段主要包括以下工作:
- 创建数据库
考虑因素:初始空间大小;数据库增量大小;访问性能(如并发数,访问频率) - 数据装载
步骤:筛选数据—转换数据格式—输入数据—校验数据 - 编写与调试应用程序
- 数据库系统试运行(功能测试与性能测试)
4.6.1 创建数据库
数据定义语言DDL.
创建数据库应该考虑:
- 初始空间大小
- 数据库增量大小
- 访问性能
4.6.2 数据装载
- 筛选数据
- 转换数据格式
- 输入数据
- 检验数据
4.6.3 编写与调试应用程序
4.6.4 数据库系统试运行
- 功能测试
- 性能测试
应该先测试DBMS的恢复功能,做好数据库转储和恢复工作。
第五章 UML与数据库应用系统
5.1 DBAS建模
5.1.1 统一建模语言(UML)
U M L UML UML 是一种基于面向对象的可视化的通用( G e n e r a l General General )建模语言,该方法结合了 B o o c h Booch Booch , O M T OMT OMT , 和 O O S E OOSE OOSE 方法的优点,统一了符号体系,并从其它的方法和工程实践中吸收了许多经过实际检验的概念和技术。
UML只是一种建模语言,不是一种建模方法。
建模方法应包括建模语言和建模过程两部分:
- 建模语言:提供这种方法用于表示建模结果的符号。(图形符号:可视化)
- 建模过程:描述建模时需要遵循的步骤。
UML由语义(自然语言)与表示法(可视化标准符号)组成。
其语义定义在一个四层建模概念框架中:
- 元元模型(Meta-Meta Model),代表要定义的所有事物。
- 元模型( Meta Model ),UML的基本元素 ,“事物”概念的实例。
- 模型层( Model ),UML的模型,类模型或类型模型。
- 用户模型( User Model ),UML模型的实例,对象模型或实例模型。
视图是对系统的模型在某方面的投影,注重于系统的某个方面。
UML中包括五种视图:
- 结构视图、
- 实现视图、
- 行为视图、
- 环境视图、
- 用例视图。
UML2.0有十三种不同的图:
- 结构图:类图,对象图,复合结构图,包图,组件图,部署图
- 行为图:用例图,交互图(顺序图、通信图、交互概述图、时间图)、状态图和活动图
5.2 DBAS业务流程与需求表达
5.2.1 业务流程与活动图
活动图主要描述系统、用例和程序模块中逻辑流程的执行次序,并行次序。最适合描述系统或子系统的工作流程。
活动图用于低层次程序模块的作用类似于流程图,但活动图可以描述并行操作,而流程图只能描述串行操作。
一张活动图中有且只能有一个起点,可有多个结束点。
- 起始点:指一连串活动的开始点。在一张活动图中,必须有且只有一个起始点。
- 结束点:指一连串活动的终点。在一张活动图中,可以有多个结束点。
- 加粗直线为同步条,表示这之后的活动路线可以并行执行,或在其上的所有并行活动执行完毕后,到此转为顺序执行。
- 分区:在整个活动表达上,是一个非常重要的概念。可以利用分区来将活动分配给对应的角色。

5.2.2 系统需求与用例图
系统需求:用户心中的真正期望。
用例模型是把满足用户需求的所用功能表示出来的工具。
用例模型由用例、角色和系统三部分组成。
- 系统:各种用例的“黑匣子”。
- 角色:与系统交互的人或其他实体。
- 用例:完整功能所有动作(一次操作)集合。
1.角色之间的关系
通用化关系:指把某些角色的行为抽取出来作为通用行为,这些通用行为构成超类。
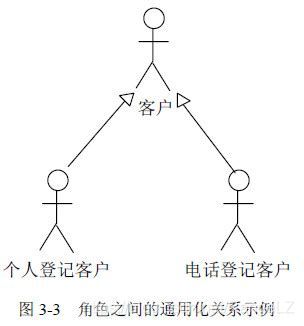
角色是与系统交互的人或其他实体。所谓“与系统交互”指的是角色从系统中接收消息,或是向系统提交消息。一个角色可以执行多个用例,反过来,一个用例可以被多个角色使用。角色是类,所以它拥有与类相同的关系描述。在用例图中用通用化关系来描述角色之间的行为。
通用化关系是指把某些角色的共同行为抽取出来作为通用行为,这些通用行为构成它们的超类。这样在定义某一具体角色时,仅仅定义其不同的行为。角色之间的通用化关系用带空心三角形(作为箭头)的直线表示,箭头的方向指向超类。
2.用例之间的关系
用例代表一个完整的功能,是所有动作的集合。动作是系统的一次操作,如与角色通信、进行计算,在系统内部进行的工作都可以称为动作。
用例用椭圆表示,用例位于系统边界的内部。用例与角色有连接关系,此关系属于关联又称为通信关联。这种关联表明哪种角色能与该用例通信。关联关系是双向的一对一关系,表示不仅角色不仅可以与用例通信。用户也可以与该角色通信,表示方法是一条连接角色和用例的带箭头直线。
用例之间存在关系,包括扩展、使用、组合三种:
- 扩展: 一用例增加新内容成为另一个用例。用例之间的扩展关系可以用带有构造型 < < e x t e n d > > <
> <<extend>>标志的通用化关系。 - 包含(使用): 一个用例使用另一个用例。用例之间的使用关系用构造型具有 < < i n c l u d e > > <
> <<include>>标志的通用化关系。 - 关联(组合): 把相关用例打成包当作整体。
ps. u s e s uses uses 和 e x t e n d s extends extends 是 U M L 1.1 UML1.1 UML1.1 中的 s t e r e o t y p e s stereotypes stereotypes(构造),它们在 U M L 1.3 UML1.3 UML1.3 (Rose2003中已经舍弃了 u s e s uses uses 关系)中被修订为 i n c l u d e include include(代替了原有的 u s e s uses uses )和 e x t e n d extend extend;

5.3 DBAS系统内部结构的表达
5.3.1 系统结构与类图
系统内部结构一般分为静态结构和动态结构。
在UML中,用类图来描述系统静态结构,用顺序图和通信图来表示系统动态结构。
类图主要表达的是问题领域的概念模型。类图由类名、属性及操作组成。
1.属性
属性包括属性的名称、类型和缺省值。 U M L UML UML 规定其语法为:可见性 名称: 类型=缺省值 {约束性}
- 可见性:不同属性具有不同的可见性。常用的由公有、受保护、私有,在 U M L UML UML 中分别用 + + +、KaTeX parse error: Expected 'EOF', got '#' at position 1: #̲、 − - − 表示。
- 名称:是一个字符串,表示属性名称。
- 类型:定义属性的种类。
- 缺省值:属性的初始值。
- 约束性:列出该属性所有可能的取值,在定义枚举类型的属性时经常使用,每个枚举值之间用逗号分隔,此外还可以用来说明该属性的其他信息,比如属性的持久性等。

2.操作
操作描述了类的动态行为,在 U M L UML UML 中,操作的语法定义如下:可见性 名称(参数表):返回类型表达式{约束性}
- 可见性:“+”表示公有操作、“#”表示受保护的操作、“-”表示私有操作。
- 名称。
- 参数表:其语法与属性的参数相同,参数的个数是任意的。
- 返回类型表达式:可选项,依赖于语言的描述。
- 约束性。
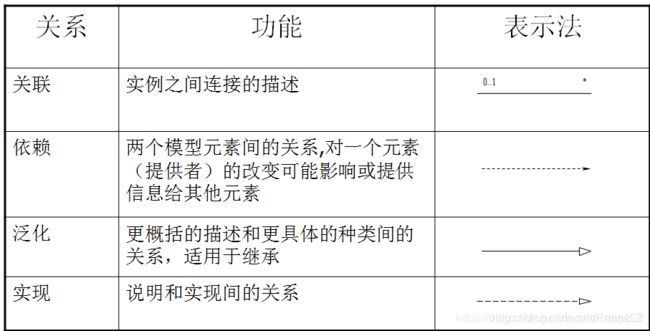
3. 关系
3.1 关联关系
3.1.1 双向关联
通常情况下关联是双向的,其图示是连接两个类之间的直线.

3.1.2 单向关联
如果类和类之间的关联是单向的则称为导航关联。导航关联采用实体箭头连接两个类,只有箭头所指的方向上才有这种关联关系。

3.1.3 多重性
如果关联上没有角色名,则隐含着用类名作为角色名。
角色具有多重性,表示有多少对象参与该关联。多重性表示参与对象的数目的上下界限制。*代表0到无穷大,“1”是“1…1"的简写,"6…10"表示6到10个对象。没有明确标识关联的重数则为1。

3.1.4 关联类
关联类通过一根虚线与关联连接,用于描述关联可能需要记录的一些信息
3.1.5 聚集
聚集是一种特殊的关联,它表示类之间整体与部分的关系。部分可以参加多个整体则构成共享聚集,整体拥有部分,部分与整体共存则构成了组成关系。
共享聚集表示为空心菱形,组成表示为实心菱形。


3.2 继承关系
人们将具有共同特性的元素抽象成类别,并通过增加其内涵进一步分类。
在面向对象方法中前者被称为一般元素、基类元素或父元素,将后者称为特殊元素或子元素。
继承关系表示为一头为空心三角形的连线。

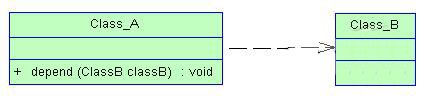
3.3 依赖关系
有两个元素 X X X 和 Y Y Y ,如果修改元素 X X X 的定义会引起元素 Y Y Y 定义的修改,则称元素 Y Y Y 依赖于元素 X X X 。
3.4 精化关系
表示同一事物的两种描述之间的关系。对同一事物的两种描述建立在不同的抽象层上。比如定义了某种抽象数据类型,然后将其实现为某种语言中的类,那么抽象定义的类型与用语言实现的类之间就是精化关系,这种情况叫实现,用带空心的三角形的虚线表示。

3.5 汇总
5.3.2 系统结构与顺序图
针对每一个特定的用例,如何用类图所规范的对象,来完成用例交付的任务,就必须用顺序图表达。
顺序图有两个坐标轴:纵向表示时间的持续过程,横向表示对象,每一个对象用矩形框表示,纵向的虚线表示对象在序列中的执行情况,称为对象的“生命线”。
对象间的通信用对象生命线之间的水平消息线表示,消息线的箭头说明消息的类型,单步、异步、简单。
顺序图中后面发生消息应该比前面发生的线画的低一些,以表示他们之间的时间关系。
5.3.3 系统结构与通信图
通信图是交互图的一种,也称为协作图。
通信图显示对象间组织交互关系和链接。不侧重交互顺序,用序列号来确定消息及其并发线程的顺序。
通信图中主要元素基本和顺序图相同,只是在消息的传递上要特别表达消息的传递是由哪一个对象到另外一个对象。
顺序图强调时间,通信图强调空间。
5.4 DBAS系统微观设计的表达
5.4.1 微观设计与对象图
对象图是类图的实例,描述特定时间中所有对象在系统中的结构,是一个快照。

5.4.2 微观设计与状态机图
状态图用来描述有关事件或对象的状态转移。
状态图只能有一个起始状态,可有多个结束状态。
状态间的转移由事件驱动。
当一个对象或某一个事件有非常复杂的状态转换时,可以用状态机图描述这个过程。

5.4.3 微观设计与时间图
当状态的转换由时间因素决定时,使用时间图来描述状态的变化。
描述时间驱动的状态转换,即当状态维持多少时间后转移。
时间图中,整个矩形框就是一个生命线。

5.5 DBAS系统宏观设计的表达
5.5.1 宏观设计与包图
宏观设计指将涉及的焦点放在研究比较大范围中的元素之间的联系,如包、命名空间、子系统等。
一个良好的命名空间,便于开发人员理解,并使得各个命名空间之间能够松耦合,而命名空间内则可满足高内聚的要求。
包图表示系统中不同包、命名空间或不同项目间的彼此关系。也就是逻辑层次上与实体层次上的关联性。
5.5.2 宏观设计与互概述图
是将活动图和顺序图嫁接在一起的图 。
以活动图为基础,在控制流间连接交互图,从而将所有交互图关系呈现出来。
交互概述图可以把不同的交互图结合在同一张图中来表达。
5.5.3 宏观设计与复合结构图
外部系统的整合关系着项目的成败。
在项目开始前,最好将待开发的系统与外部系统的关系做一个初步的定义。
复合结构图最重要的元素是部件,一个部件可以代表某个实体组件,也可以代表一个子系统。
复合结构图适用于系统间的沟通接口,适合做构架师在初期阶段评估系统复杂度的工具,也可以是系统维护的参考图。
5.6 DBAS系统实现与部署的表达
5.6.1 系统实现与组件图
组件图用来表示系统的静态实现视图。
用来展现一组组件间的组织和依赖,用于对源代码、可执行的发布、物理数据库等的系统建模。
组件是逻辑设计中定义的概念和功能在物理构架中的实现。

5.6.2 系统实现与部署图
部署图又叫配置图,描述系统中硬件和软件的物理配置情况与系统体系结构。
部署图说明实体组件,如可执行程序,将如何部署到实际的计算机中。
部署图要在项目进行集成测试前提供。
第六章 高级数据查询
6.1 一般数据查询功能扩展
6.1.0 补充 SELECT语句
SELECT [DISTINCT] [TOP n] select_list
-- 查询指定的列
[INTO new_table]
--将查询结果创建到新表
[FROM table_source]
--查询行所在的表
[WHERE search_conditition]
--指定返回行的搜索条件
[GROUP BY group_by_expression]
--指定查询结果的分组条件
[HAVING search_condition]
--指定组或聚合函数的搜索条件
[ORDER BY order_expression [ASC|DESC]]
--指定结果集的排序方式
[COMPUTE expression]
--在结果集的末尾生成汇总数据行
6.1.1 使用Top限制结果集
TOP n [percent][WITH TIES]
- Top n 前n行
- Top n [percent]前n%行
- [WITH TIES]:包括最后一行取值并列的结果。
注意:在使用 T O P TOP TOP 谓词时,要写在 S E L E C T SELECT SELECT 单词的后边(如果有 D I S T I N C T DISTINCT DISTINCT 的话,则 T O P TOP TOP 写在 D I S T I N C T DISTINCT DISTINCT 的后边)、查询列表的前边。
6.1.2 使用CASE函数
简单 C A S E CASE CASE 函数的语法格式为:
CASE 测试表达式
WHEN 布尔表达式1 then 结果表达式1
WHEN 布尔表达式2 then 结果表达式2
……
WHEN 布尔表达式n then 结果表达式n
[ELSE 结果表达式n+1]
END
搜索 C A S E CASE CASE 函数的语法格式为:
CASE
WHEN 布尔表达式1 then 结果表达式1
WHEN 布尔表达式2 then 结果表达式2
……
WHEN 布尔表达式n then 结果表达式n
[ELSE 结果表达式n+1]
END
6.1.3 将查询结果保存到新表中
包含 I N T O INTO INTO 子句的 S E L E C T SELECT SELECT 语句的语法格式为:
SELECT 查询列表序列 INTO <新表名>
FROM 数据源
…… --其他行过滤、分组等子句
注意:表名前加#为局部临时表,##为全局临时表,只有表名为永久表。
例子:SELECT * INTO #HD_Customer FROM Table_Customer WHERE ……
6.2 查询结果的并、交、差运算
6.2.1 并运算
并运算(UNION):将多个查询结果合并为一个结果集。
语法:
SELECT 语句1
UNION [ALL]
SELECT 语句2
UNION [ALL]
……
SELECT 语句n
使用UNION注意:
- 要进行合并的查询,SELECT中列数必须相同,语义相同。
- 每个相对应列的数据类型隐式兼容,如char(20)与varchar(40)。
- 合并后结果采用第一个SELECT语句的列标题。
- 若需排序,则GROUP BY语句写在最后一个SELECT之后,且排序的一句是第一个SELECT中的列名。
6.2.2 交运算
交运算:返回同时在两个集合中出现的记录。
语法:
SELECT 语句1
INTERSECT
SELECT 语句2
INTERSECT
……
SELECT 语句n
6.2.3 差运算
差运算:返回第一个集合中有而第二个集合中没有的的记录。
语法:
SELECT 语句1
EXCEPT
SELECT 语句2
EXCEPT
……
SELECT 语句n
6.3 相关子查询
子查询是一条包含在另一条 S E L E C T SELECT SELECT 语句里的 S E L E C T SELECT SELECT 语句。外层的 S E L E C T SELECT SELECT 语句叫外层查询,内层的 S E L E C T SELECT SELECT 语句叫内层查询(或子查询)。子查询总是写在圆括号中。
包含子查询的语句通常采用以下格式中的一种:
- WHERE 表达式 [NOT] IN (子查询)
- WHERE 表达式 比较运算符 (子查询)
- WHERE [NOT] EXISTS (子查询)
6.3.1 使用子查询进行基于集合的测试
--实例:
SELECT Cname,Address FROM Table_Customer
WHERE Address IN(SELECT Address FROM Table_Customer WHERE Cname=‘王晓’)
AND Cname!= ‘王晓’
6.3.2 使用子查询进行比较测试
--实例:
--查询单价最高的商品的名称和单价
SELECT Goodname,SaleUnitPrice FROM Table_Goods a WHERE SaleUnitPrice=
(SELECT MAX(SaleUnitPrice) FROM Table_Goods)
6.3.3 使用子查询进行存在性测试
--实例:
--查询购买了单价高于2000元商品额顾客的会员卡号。
SELECT DISTINCT CardID FROM Table_SaleBill WHERE EXISTS(SELECT * FROM Table_SaleBillDetail WHERE SaleBillID=Table_SaleBill.SaleBillID AND UnitPrice>2000)
6.4 其他形式的子查询
6.4.1 替代表达式的子查询
在SELECT的选择列表中嵌入了一个只返回一个标量值的子查询。
--实例:
SELECT Cname,Address
(SELECT COUNT(*) FROM Table_SaleBill a
JOIN Table_Customer b ON a.CardID=b. CardID
WHERE CustomerID=‘C001’)AS TotalTimes
FROM Table_Custmer
Where CustomerID=‘C001’
6.4.2 派生表
也称为内联视图,是将子查询作为一个表处理,产生的新表为“派生表”。
--实例:查询至少买了G001和G002两种商品的顾客号和顾客名。
SELECT CustomerID,CName
FROM (SELECT * FROM Table_SaleBill a
JOIN Table_SaleBillDetail b
ON a.SaleBillID=b. SaleBillID
WHERE GoodsID=‘G001’) AS T1
JOIN (SELECT * FROM Table_SaleBill a
JOIN Table_SaleBillDetail b
ON a.SaleBillID=b. SaleBillID
WHERE GoodsID=‘G002’) AS T2
ON T1.CardID=T2.CardID
JOIN Table_Customer c ON c.CardID=T1. CardID
6.5 其他一些查询功能
6.5.1 开窗函数
SQL Server 中,一组行被称为一个窗口。
与聚合函数一样,开窗函数也是对行集组进行聚合计算,但是它不像普通聚合函数那样每组只返回一个值,开窗函数可以为每组返回多个值,因为开窗函数所执行聚合计算的行集组是窗口。
与聚合函数不同的是,开窗函数在聚合函数后增加了一个OVER 关键字。
开窗函数的调用格式为: 函数名(列)OVER(选项)
- OVER 关键字:表示把函数当成开窗函数而不是聚合函数。
- SQL 标准允许将所有聚合函数用做开窗函数,使用OVER 关键字来区分这两种用法。
其他排名函数
- DENSE_RANK():排名是连续整数
- NTILE():将有序分区中的行划分到指定数目的组中,编号从1开始,函数返回此行所属的组的编号。
- ROW_NUMBER():返回结果集中每个分区内的序列号,每个分区的第一行从1开始。
6.5.2 公用表表达式
公用表表达式(CommonTableExpression,CTE):将查询结果集指定一个临时名字,这些命名的结果集就是公用表表达式。
--格式:
WITH <common_table_expression>[,…n]
<common_table_expression>::=
expression_name[(column_name [,…n])]
AS
(SELECT语句)
第七章 数据库及数据库对象(补充)
7.1 创建及维护数据库
7.1.1 SQL Server数据库的组成
SQL Server将数据库映射为一组操作系统文件:
- 数据文件
- .mdf:主要数据文件。只有一个,大小不得小于3MB。
- .ndf :次要数据文件。有0个或多个,可在一个磁盘或多个磁盘存放。
- 日志文件
- .ldf:事务日志文件。至少有一个日志文件。
7.1.2 数据库文件组
两种类型的文件组:
- 主文件组(PRIMARY):系统定义,包含主要数据文件和任何没有明确分配的其他文件组的其他数据文件,系统表所有页均分配在主文件组中。
- 用户定义文件组:在定义或修改数据库时用 F I L E G R O U P FILEGROUP FILEGROUP 关键字指定。
注意:
- 日志文件不在文件组中,日志空间与数据空间分开管理。
- 一个文件不可以是多个文件组成员。
- 若文件组包含多个文件,则在所有文件被填满后才会自动循环增长。
- 文件加入数据库中后,不能移动到其他文件组。
- 只能指定一个文件组为默认文件组。
7.1.3 数据库文件的属性
定义数据库的数据文件和日志文件所需信息:
- 文件名及其位置 :逻辑文件名,物理文件名
- 初始大小:不能小于model数据库主要数据文件的大小
增长方式:可指定文件是否自增长(默认)。
最大大小:文件增长的最大限制。默认无限制。
7.1.4 用T-SQL创建数据库
创建数据库一般有两种方式:
- 通过SQL Server Management Studio创建数据库。
- 通过T-SQL语句创建数据库。
T − S Q L T-SQL T−SQL 语法格式:

7.1.5 说明
- PRIMARY :指定为主要数据库文件,没有指定默认第一个文件是主要数据文件。
- LOG ON :自动创建日志文件,大小为数据文件总和25%或512KB中大的。
- NAME :逻辑文件名,唯一。
- FILENAME :物理文件名。
- SIZE:初始大小,.mdf大小不小于model,.ndf默认为1MB。
- MAXSIZE:最大大小,未指定则文件自动增长到磁盘满。
- UNLIMITED :增长无限制,一般指定为日志文件2TB,数据文件16TB.
- FILEGROWTH:指定文件自动增量,不超过MAXSIZE.默认数据文件1MB,日志文件为当前文件的10%。
- FILEGROUP :文件组逻辑名,唯一,不能是系统名。
- DEFAULE :指定该文件组为默认文件组。

7.1.6 修改数据库
1.扩大数据库空间
- 扩大数据库中已有文件的大小
- 为数据库添加新的文件
2.收缩数据库空间
- 即释放数据库中未使用的空间,文件的收缩从末尾开始。
- 自动收缩:AUTO_SHRINK,默认false。
- 手工收缩:收缩数据库中某个文件大小;
-
按比例收缩整个数据库大小。
3.添加和删除数据库文件
ALTER DATABASE database
{ ADD FILE < filespec > [ ,...n ] [ TO FILEGROUP filegroup_name ]
| ADD LOG FILE < filespec > [ ,...n ]
| REMOVE FILE logical_file_name
| ADD FILEGROUP filegroup_name
| REMOVE FILEGROUP filegroup_name
| MODIFY FILE < filespec >
| MODIFY NAME = new_dbname
| MODIFY FILEGROUP filegroup_name {filegroup_property
| NAME = new_filegroup_name }
| SET < optionspec > [ ,...n ] [ WITH < termination > ]
| COLLATE < collation_name >
}
4.扩大指定文件的大小:
ALTER DATABASE STU_DB
MODIFY FILE(NAME=student_data, SIZE=8MB)
5.添加新的数据文件:
ALTER DATABASE STU_DB
ADD FILE(NAME=student_data2,
FILENAME=‘E:\Data\student_data2.ndf’,
SIZE=6MB,FILEGROWTH=0)
6.收缩整个数据库的大小:
DBCC SHRINKDATABASE
例1:DBCC SHRINKDATABASE(students,20)
收缩数据库,该数据库所用文件都有20%可用空间
7.收缩指定文件的大小:
DBCC SHRINKFILE
例2:DBCC SHRINKFILE(students_data1,4)
收缩数据库到4MB大小
8.删除数据库文件:
ALTER DATABASE STU_DB
REMOVE FILE student_log1
注意:
- 添加文件时,每个文件组中的数据文件按比例填充,日志文件是依次增加的。
- 文件为空才能删除。
7.1.7 分离和附加数据库
1.分离数据库
作用:
- 实现将数据库从一台数据库服务器移到另一台,不需要重建。
- 从实例中删除,不删除数据文件和日志文件,保持了数据文件和日志文件完整一致。
- 使用sp_detach_db系统存储过程实现,如:EXEC sp_detach_db‘student’,‘true’
2.附加数据库
将分离的数据库重新附加到数据库管理系统中。
必须指定主要数据文件的物理存储位置和文件名。
CREATE DATABASE ……
FOR ATTACH|ATTACH_REBUILD_LOG
例:
CREATE DATABASE students
On(FILENAME=‘F:\Data\Students_data1.mdf’)
FOR ATTACH
7.2 架构
架构(Schema,也称模式),是数据库下的一个逻辑命名空间,是数据库对象的容器,一个数据库包含一个或多个构架,同一个数据库内架构名唯一。
7.2.1 定义构架
CREATE SCHEMA [<构架名>]
AUTHORIZATION<用户名>
7.2.3 删除构架
DROP SCHEMA [<构架名>]
7.3 分区表
7.3.1 基本概念
分区表是将表中的数据按水平分割成不同子集,并将数据子集存储在数据库一个或多个文件组中。物理上将大表分成几个小表,逻辑上还是一个大表。
合理使用分区能提高数据库性能。
是否创建分区取决于表当前数据量大小,以及将来数据量,还取决于表中数据的操作特点。
表包含(或将包含)以多种不同方式使用的大量数据
数据是分段的,比如以年份分隔。
7.3.2 创建分区表
三个步骤:
- 创建分区函数:告诉DBMS以什么方式进行分区
CREATE PARTITION FUNCTION
- 创建分区方案:作用是将分区函数生成的分区映射到文件组中
CREATE PARTITION SCHEME
- 使用分区创建表。
7.4 索引
7.4.1 创建索引

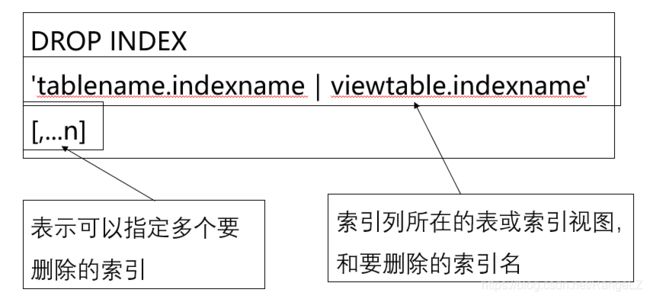
7.4.2 删除索引
7.5 索引视图
7.5.1 基本概念
标准视图也称虚拟表,返回结果集与基本表一致。标准视图的结果集不永久存放;
建立唯一聚集索引的视图,称为索引视图,也称为物化视图。建立索引后,视图的结果集存放在数据库中。
对基本表的修改会反映到索引视图存储的数据中。
7.5.2 定义索引视图
创建聚簇索引前视图必须符合的条件:
- 定义索引视图时,视图只能引用基本表,不能是其他视图。
- 引用的所以基本表和视图同一数据库,所有者相同。
- 必须用SCHEMABINDING选项建视图。
- 视图中表达式引用的所有函数必须确定。
- 对视图建立的第一个索引是唯一聚簇索引,之后在创建其他。
CREATE VIEW;WITH SCHEMABINDING; CREATE
UNIQUE CLUSTERED INDEX …
第八章 数据库后台编程
8.1 存储过程
8.1.1 基本概念
使用T-SQL语言编写代码时,有两种方式存储和执行代码:
- 在客户端存储代码,通过客户端程序或SQL命令向DBMS发出操作请求,由DBMS将结果返回给用户程序。
- 以子程序的形式将程序模块存储在数据库中,供有权限的用户通过调用反复执行。
存储过程:即存储在数据库中供所有用户程,序调用的子程序。
存储过程分为三类:
- 系统存储过程
- 用户自定义存储过程
- 扩展存储过程
用户自定义存储过程是由用户创建并能完成某一特定功能(如查询用户所需数据信息)的存储过程。
扩展存储过程是 SQL Server 可以动态装载并执行的动态链接库 (DLL)。扩展存储过程使您得以使用象 C 这样的编程语言创建自己的外部例程。对用户来说,扩展存储过程与普通存储过程一样,执行方法也相同。
存储过程的优点:
- 极高的执行效率。
- 增强代码的重用性和共享性。
- 使用存储过程可以减少网络流量。
- 使用存储过程保证安全性。
- 在大型数据库中,应用程序访问数据库的最主要方式就是存储过程。
- 存储过程可以在系统启动时自动执行。
8.1.2 创建、执行和删除存储过程
存储过程定义包含两个主要组成部分:
- 过程名称及其参数的说明;
- 过程的主体(其中包含执行过程操作的Transact-SQL语句)。创建存储过程的语法格式如下:
创建存储过程:

执行存储过程:

删除存储过程:
DROP PROCEDURE
8.2 用户定义函数
用户定义函数:类似于编程语言中的函数,其结构与存储过程类似,但函数必须有一个 R E T U R N RETURN RETURN 子句,用于返回函数值。
两类用户定义函数:标量函数和表值函数。前者返回单个数据值,表值函数返回一个表。
8.2.1 创建和调用标量函数
1.定义标量函数:
CREATE FUCTION [schema_name. ] function_name
( [ { @ parameter_name [AS] [type_schema_name. ] parameter_data_type
[ =default ] }
[,···n]
]
)
RETURNS return_data_type
[AS ]
BEGIN
function_body
RETURN scalar_expression
END
[;]
各参数说明:
- schema_name:用户定义函数所属框架的名称。
- function_name:用户定义函数的名称。
- @ parameter_name:用户定义函数中的参数
- [type_schema_name. ] parameter_data_type :参数的数据类型及其所属的架构,后者为可选项。
- [ =default ]:参数的默认值。
- return_data_type:用户定义函数的返回值类型。
- function_body:定义函数值的一系列T-SQL语句。
- scalar_expression:指定标量函数返回的标量值。
2.调用标量函数:
注意:
- 调用时需要提供函数拥有者名和函数名;
- 可以在任何出现表达式的SQL语句中调用类型一致的标量函数。
8.2.2 创建和调用内联表值函数
1.创建内联表值函数:
CREATE FUCTION [schema_name. ] function_name
( [ { @ parameter_name [AS] [type_schema_name. ] parameter_data_type
[ =default ] }
[,···n]
]
)
RETURNS TABLE
[AS ]
RETURN [ ( ] select_stmt [ ) ]
[;]
参数说明:select_stmt是定义内联表值函数返回值的单个SELECT语句;表值函数没有返回变量,没有函数体,只返回一个查询结果。
2.调用内联表值函数:
使用内联表值函数与视图类似,其作用相当于带参数的视图。
8.2.3 创建和调用多语句表值函数
创建多语句表值函数:
CREATE FUCTION [schema_name. ] function_name
( [ { @ parameter_name [AS] [type_schema_name. ] parameter_data_type
[ =default ] }
[,···n]
]
)
RETURNS @ return_variable TABLE <table_type_definition>
[AS ]
BEGIN
fuction_body
RETURN
END
[;]
<table_type_definition>:: =
( { <column_definition> <column_constraint>
| <computed_column_definition>}
[<table_constraint>][,···n]
)
参数说明:
- function_body:定义函数值的一系列T-SQL语句。
- table_type_definition:定义返回的表的结构。
调用建多语句表值函数:在SELECT的FROM子句中使用。
8.2.4 删除用户自定义函数
DROP FUNCTION { [schema_name. ] function_name} [,···n ]
8.3 触发器
8.3.1 基本概念
触发器:特殊存储过程,在对表中的数据进行UPDATE、INSERT、DELETE操作时自动触发执行,常用于保证业务规则和数据完整性,增强数据完整性约束能力。
SQL Server 2008支持三种类型的触发器:
- DML、
- DDL、
- 登录触发器。
适用场合:
- 完成比CHECK(只能实现同一表列之间取值约束)约束更复杂的数据约束。
- 保证数据库性能而维护的非规范化数据。
- 可实现复杂的商业规则。
- 评估数据修改前后的表状态,并采取对策。
8.3.2 创建触发器
CREATE TRIGGER trigger_name ON
{ table | view }
[WITH ENCRYPTION]
{ FOR | AFTER | INSTEAD OF }
{ [ INSERT ] [ , ] [ UPDATE ] [ , ]
[ DELETE ] }
AS
sql_statement[…n]
参数说明:
- FOR或AFTER:后触发型,操作、约束检查完成后触发。
- INSTEAD OF :前触发型,数据操作语句最多定义一个触发器。执行触发器而非引发语句。若满足完整性约束则需要重新执行这些数据操作。
注意:
- 一个表可建多个触发器,每个触发器可由三个操作触发。ALTER类型同一操作上建立多个触发器,INSTEAD OF类型同一操作上建立一个触发器。
- 所有建立和更改数据库以及数据库对象的语句、DROP语句不允许砸在触发器中用。
- 触发器不要返回任何结果。
8.3.3 删除触发器
DROP TRIGGER
实例
DROP TRIGGER OperateCon
DROP TRIGGER UnitPriceConsistent
DROP TRIGGER DeleteCust
8.4 游标
游标:实现对SELECT结果集的逐行处理。
8.4.1 游标的组成
游标结果集(SELECT返回结果集)与游标当前行指针(指向结果集中某一行)
特点:定位特定行;从当前位置检索一行或多行;支持当前行数据修改;对修改结果提供不同级别的可见性支持。
8.4.2 使用游标
1.声明游标
ISO标准语法:DECLARE cursor_name[1] CURSOR FOR select_statement[2]
参数说明:[1]INSENSTITIVE:创建临时副本,对临时表操作,否则对基本表;SCROLL:范围,否则只支持NEXT;[2]READ ONLY:禁止更新 UPDATE 更新列指定列或所有。
2.打开游标
OPEN cursor_name
3.提取数据
FETCH [1]FROM cursor_name [INTO @ variable_name[,…n]]
4.关闭游标
CLOSE cursor_name
可以再次打开。
5.释放游标
DEALLOCATE cursor_name
释放分配给游标的所有资源。
第九章 安全管理
9.1 安全控制概述
数据库安全性不同于数据的完整性。
- 安全性:保护数据以防止不合法用户故意造成破坏。(确保用户被允许做其想做的事情。)
- 完整性:保护数据以防止合法用户无意中造成的破坏。(确保用户做的事情是正确的。)
9.1.1 数据库安全控制的目标
保护数据免受意外或故意的丢失、破坏或滥用。
9.1.2 数据库安全的威胁
安全计划需要考虑:可用性损失,机密性数据损失,私密性数据损失,偷窃和欺诈,意外的损害。
9.1.3 安全控制模型
包括四阶段:
- 身份验证(用户)
- 操作权限控制(数据库应用程序与数据库管理系统)
- 文件操作控制(操作系统)
- 加密存储与冗余(数据库)
9.1.4 授权和认证
认证是一种鉴定用户身份的机制。授权是将合法访问数据库或数据库对象的权限授予用户的过程。包括认证用户对对象的访问请求。
DBMS通常采用自主存取控制和强制存储控制两种方案来解决安全控制问题。
9.2 存取控制
9.2.1 自主存取控制
又称自主安全模式, 通过SQL的GRANT,REVOKE,DENY语句来实现。
权限种类:维护权限与操作权限(语句权限与对象权限)
用户分类:系统管理员(sa)、数据库对象拥有者、普通用户。
9.2.2 强制存取控制
为避免自主存取模式下数据的“无意泄露”,采取强制存取控制。
DBMS将全部实体分为主体和客体两大类。
- 主体:系统活动实体,实际用户和进程。
- 客体:被动实体,受主体操纵,包括文件、基本表、视图。
敏感度标记被分为若干级别,例如绝密,秘密,可信和公开。
主体的敏感度标记被称为许可证级别,客体的敏感度标记被称为密级
- 仅当主体的许可证级别大于或等于客体的密级时,该主体才能读取相应的客体。
- 仅当主体的许可证级别等于客体密级时,该主体才能写相应的客体。
通用安全性分级模式:D类最小保护,C类自主保护,B类强制保护,A类验证保护
自主保护:C类分为两个子类C1和C2,C1安全级别低于C2
- C1子类对所有权和存储权限区分,虽然它允许用户拥有自己的私有数据,但仍然支持共享数据的概念
- C2子类还需要通过注册、审计以及资源隔离以支持安全责任说明
强制保护:B类分为三个子类B1 B2 B3,B1安全级别最低,B3最高
- B1要求标识化安全保护,并要求每个数据对象都标以一定的密级,同时还要求安全策略的非形式化说明
- B2要求安全策略的形式化说明,能够识别并消除隐蔽通道(隐蔽通道的例子有从合法查询结果推断不合法查询结果)
- B3子类要求支持审计和恢复以及指定安全管理者
验证保护:A类要求安全机制是可靠的且足够支持对指定安全策略给出严格的数学证明。
9.3 审计跟踪
审计跟踪实质上是一种特殊的文件或数据库。系统自动记录用户对常规数据的所有操作。
审计跟踪对数据安全有辅助作用。
9.4 统计数据库的安全性
统计数据库提供基于各种不同标准的统计信息或汇总数据。
统计数据库安全系统用于控制对统计数据库的访问。
统计数据库允许用户查询聚合类型的信息,如总和、平均等,但不允许查询个人信息。
9.5 SQL Server 的安全控制
9.5.1 身份验证模式
- Windows身份验证模式:SQL Server通过Windows操作系统获得用户信息,验证登录名和密码,一般推荐。
- 混合身份验证模式;Windows授权用户和SQL授权用户可以登录。
9.5.2 登录帐户
- SQL Server自身负责身份验证的账户,内置系统账户与用户自己创建。
- 登录到SQL Server的Windows网络账户,可以是组账户或用户账户。
1.建立登录账户
例1:创建SQL server 身份验证的登录账户
create login SQL_User1 with password = '12345678'
例2:创建Windows身份验证的登录账户,从Windows域账户创建[TEST\Win_User2]登录账户
create login [TEST\Win_User2] from windows
例3:创建SQL server身份验证的登录账户。要求该用户首次连接服务器时必须更改密码
create login SQL_User3 with password = '123456789'
must_change
2.修改登录账户属性
例4:启用或禁用的登录账户
alter login SQL_User1 enable
例5:修改登录账户的密码
alter login SQL_User1 with password='12345'
例6:更改账户名
alter login SQL_User3 with name = 'NewUser'
3. 删除登录账户
例7:删除登录账户
drop login SQL_User2
9.5.3 数据库用户
用户有了登录帐户,只能连接到SQL服务器,并不具有访问数据库的权限。
让登录账户成为数据库用户的操作是映射 。一个登录账户可以映射为多个数据库中的用户。 默认情况下,新建立的数据库只有一个用户dbo,他是数据库的拥有者
1.建立数据库用户
例8 使SQL_User2登录账户成为某数据库中的用户,并且用户名同登录名
create user SQL_User2
例9 首先创建名为SQL_JWC且具有密码的SQL Server身份验证的服务器登录名,然后在test数据库中创建与此登录名对应的数据库用户JWC 、
create login SQL_JWC with password='123456'
go
use test
go
create user JWC for login SQL_JWC
go
2.Guest用户
--启用guest用户
grant connect to guest
--禁用guest用户
revoke connect to guest
3.删除数据库用户
drop user user_name
9.5.4 权限管理
登录账户成为合法用户后没有任何操作权限,就需要为用户授予数据库数据及其对象的操作权限。
1.对象级别的权限
| 操作权限 | 使用说明 |
|---|---|
| select | 允许用户查询数据 |
| insert | 允许用户插入数据 |
| update | 允许用户修改数据 |
| delete | 允许用户删除数据 |
| references | 如果用户要插入数据的表上有外键约束,而用户在外键所引用的表上没有select权限,则拥有该权限的用户能够向这样的表插入数据 |
| execute | 允许用户具有执行存储过程和标量函数的权限 |
1.1 授权语句
例10:授予用户RosaQdm对Address表具有select权限
grant select on Address to RoseQdm
例11:授予用户 RosaQdM 对 HumanResources. EmployeeInfo 存储过程具有 EXECUTE 权限
GRANT EXECUTE ON OBJECT :: HumanResources. EmployeeInfo To RosaQdm
例12:使用 GRANT OPTION 选项,授予用户 Wanida 对 vEmployee 视图中 EmployeeID 列具有 REFERENCES 权限。
GRANT REFERENCES ( EmployeeID)ON vEmployee
To Wanida WITH GRANT OPTION
1.2 拒绝语句
例13:拒绝用户 RosaQdm 对 Person. Address 表具有 select 权限
DENY select ON OBJECT :: Person. Address to RoseQdm
例14:拒绝用户 RosaQdM 对 HumanResources. EmployeeInfo 存储过程具有 EXECUTE 权限
DENY EXECUTE ON HumanResources. EmployeeInfo To RosaQdm
例15:拒绝 GRANT OPTION 选项,授予用户 Wanida 对 HumanResources. vEmployee 视图中 EmployeeID 列具有 REFERENCES 权限。
DENY REFERENCES ( EmployeeID)ON OBJECT :: HumanResources. vEmployee
To Wanida CASCADE;
1.3 收权语句
例16:撤销用户 RosaQdm 对 Person. Address 表具有 select 权限
REVOKE select ON OBJECT :: Person.Address to RoseQdm
例17:撤销用户 RosaQdM 对 HumanResources. EmployeeInfo 存储过程具有 EXECUTE 权限
REVOKE EXECUTE ON HumanResources. EmployeeInfo FROM To RosaQdm
2.语句级别的权
2.1 授权语句
例18:授权用户 RosaQdM 具有创建表的权限。
GRANT CREATE TABLE TO RosaQdM
例19: 授权用户 user1 和 user2 都具有创建表和视图权限。
GRANT CREATE TABLE, CREATE VIEW TO user1,user2
2.2 拒绝语句
例20:拒绝用户 user1 具有创建表的权限。
DEMY CREATE TABLE TO user1
2.3 收权语句
例21:收回用户 RosaQdM 具有创建表的权限。
REVOKE CREATE TABLE FROM RosaQdM
9.5.5 角色
定义:一组具有相同权限的用户就是角色。
SQL Server 2008中,角色分为预定义的系统角色和用户角色两种。
- 系统角色又分为固定服务器角色(服务器级角色)和固定数据库角色(数据库级角色)。
- 用户角色均是数据库级角色。
1.固定服务器角色
- Bulkadmin:执行BULK INSERT语句权限。
- Dbcreator:创建、修改、删除还原数据库权限。
- Diskadmin:具有管理磁盘文件的权限
- Processadmin管理运行进程权限。
- Securtyadmin:专门管理登录账户、读取错误日志执行CREATE DATABASE 权限的账户,便捷。
- Serveradmin:服务器级别的配置选项和关闭服务器权限。
- Setupadmin:添加删除链接服务器。
- Sysadmin:系统管理员 ,Windows超级用户自动映射为系统管理员。
- Public:系统预定义服务器角色,每个登录名都是这个角色的成员。没有授予或拒绝特定权限,则将具有这个角色权限。
2.固定数据库角色
定义在数据库级别上,存在于每个数据库中。用户加入固定数据库角色就具有数据库角色权限。
- Db_accessadmin:添加或删除数据库权限
- Db_backupoperator:备份数据库、日志权限
- Db_datareader:查询数据库数据权限
- Db_datawriter:具有插入、删除、更改权限
- Db_ddladmin:执行数据定义的权限
- Db_denydatareader:不允许具有查询数据库中所有用户数据的权限。
- Db_denydatawriter:不允许具有插入、删除、更改数据库中所有用户数据权限。
- Db_owner:具有全部操作权限,包括配置、维护、删除数据库。
- Db_securityadmin:具有管理数据库角色、角色成员以及数据库中语句和对象的权限。
3.用户定义的角色
- 用户定义的角色属于数据库一级。
- 用来简化使用数据库时的权限管理。
- 用户定义的角色成员可以是用户定义角色或数据库用户。注意: 角色中的成员拥有的权限=成员自身权限+所在角色权限。但若某个权限在角色中被拒绝,则成员不再拥有。
3.1创建用户定义的角色
CREATE ROLE
实例:
CREATE ROLE MathDept [AUTHORIZATION Software]
注意:为用户定义角色授权、添加、删除用户定义的角色中的成员与固定数据库角色一致。
3.2删除用户定义角色
DROP ROLE
实例:
DROP ROLE MathDept
9.6 Oracle的安全管理
Oracle的安全机制分为数据库级的安全控制、表级、列级、行级的安全控制。
数据库级的安全性通过用户身份认证和授予用户相应系统权限来保证;
表级、列级、行级的安全性通过授予或回收对象权限保证。支持集中式、分布式、跨平台应用。
Oracle系统通常设置两级安全管理员:
- 全局级:负责管理、协调,维护全局数据一致性和安全性;
- 场地级:负责本结点数据库安全性,用户管理、系统特权与角色管理。
9.6.1 用户与资源管理
按权限大小划分为DBA用户和普通用户。
- DBA用户由DBMS自动创建,sys与system用户,拥有全部系统特权。
- 普通用户:由DBA用户或有相应特权的用户创建,并授予系统特权。
1.建立用户:
例32:建立一个Oracle 数据库用户 user1.
CREATE USER use1 IDENTIFIED BY u66771
DEFAULT TABLESPACE student(存储在student表空间)
QUOTA 5M ON student(限制使用空间为5M)
2.管理用户和资源:
例33:将user1用户对student表空间的空间使用额增至60MB
ALTER USER user1
QUOTA 60M ON student
将自己的密码修改为w12345
ALTER USER user
1 IDENTIFIED BY w12345
3.删除用户
例34:从数据库中删除USER1用户及其所拥有的全部数据库对象。
DROP USER user1 CASCADE
9.6.2 权限管理
1.系统特权
三种默认特权:
- Connect: 不能建立任何对象,可以查询数据字典及访问数据库对象。
- Recource :可建立数据库对象(表、视图、索引……)
- DBA :拥有预定义的全部权限 。
2.对象特权
用于维护表级、行级、列级数据的安全性。
实例:
GRANT all ON dep TO user1
GRANT select(tno,tname,sal) ON teacher TO
user2
第十章 数据库运行维护与优化
10.1 数据库运行维护基本工作
DBAS进入运行维护阶段的主要任务:
- 保证数据库系统安全、可靠且高效率地运行。
- 数据库的运行除了DBMS与数据库外,还需要各种系统部件协同工作。
首先必须有各种相应的应用程序,其次各应用程序与DBMS都需要在操作系统(OS)支持下工作。
维护工作包括:
- 数据库转储与恢复
- 数据库安全性、完整性控制
- 检测并改善数据库性能
- 数据库的重组和重构
重组不修改数据库原有设计的逻辑结构和物理结构,重构部分修改模式和内模式
10.2 运行状态监控与分析
数据库的监控分析:指管理员借助工具监测DBMS的运行情况,掌握系统当前或以往的负荷、配置、应用等信息,并分析监测数据的性能参数和环境信息,评估DBMS的整体运行状态。
根据监控分析实现不同,分为:
- 数据库系统建立的自动监控机制
- 由DBMS自动监测数据库的运行情况。
- 管理员手动实施的监控机制
根据监控对象不同,分为:
- 数据库构架体系的监控:监控空间基本信息、空间使用率与剩余空间大小等。
- 数据库性能监控:监控数据缓冲区命中率、库缓冲、用户锁、索引使用、等待事件等。
10.3 数据库存储空间管理
空间使用情况变化带来的问题:
- 降低数据库系统服务性能
- 空间溢出导致灾难停机事故
SQL Server数据库中 一个逻辑上的数据库直接和一组物理上的数据文件对应,没有表空间概念。
DBMS对空间的管理包括:创建数据库空间、更改空间大小、删除空间、修改空间状态,新建、移动、关联数据文件等。
10.4 数据库性能优化
数据库性能优化是DBAS系统上线后最常见的运行维护任务之一。
进行数据库性能优化时,首先要确定优化目标,一般从数据库运行环境、参数调整、模式调整、数据库存储优化、查询优化几个方面考虑。
10.4.1 数据库运行环境与参数调整
一般来说,可以从外部环境、调整内存分配、调整磁盘I/O、调整资源竞争等几个方面着手改变数据库参数,提高其性能。
1.外部调整
外部调整:数据库性能和外部环境有很大关系,主要外部条件包括:CPU(CPU的处理能力是衡量计算机性能的一个标志)、网络(大量的SQL数据在网络上传输会导致网速变慢)。
CPU使用情况判断依据:对于一台数据库服务器,如业务空闲时使用率超过90%。说明服务器缺乏CPU资源,如高峰时CPU使用率仍然低,说明服务器CPU资源充足。
解决方案;增加CPU数量或者终止需要许多资源的进程。
2.调整内存分配
调整内存分配:调整相关参数控制数据库内存分配,很大程度改善数据库系统性能。
3.调整磁盘I/O
调整磁盘I/O:数据库性能优劣的重要度量是响应时间。
改善方法:令I/O时间最小化,减少磁盘上文件竞争带来的瓶颈。
4.调整竞争
调整竞争:
- 修改参数以控制连接到数据库的最大进程数。
- 减少调度进程的竞争
- 减少多线程服务进程竞争
- 减少重做日志缓冲区竞争
- 减少回滚段竞争。
10.4.2 模式调整与优化
数据库的规范化过程:高效率利用存储空间,减少数据的冗余,减少数据的不一致性。
问题:规范化关系解决了数据维护的异常,并使数据冗余最小化,但会导致数据处理性能下降。
反规范化:将规范化关系转换为非规范化的关系的过程。
反规范化方法:增加派生冗余列、增加冗余列、重新组表、分割表和新增汇总表等方法。都会破坏数据完整性。
采用反规范化技术从实际出发均衡利弊。
1.增加派生性冗余列
增加的列由表中的一些数据项经过计算生成。
作用:查询时减少连接操作,避免使用聚合函数。
例如:销售单据明细表(单据编号,商品编号,单价,数量,总价),总价=单价*数量,属于派生性增加冗余列。
2.增加冗余列
在多个表中增加具有相同语义的列,常用来在查询时避免连接操作。(外码不属于这种情况)
3.重新组表
当用户经常查看的某些数据是由多个表连接之后才能得到,就可以考虑先把这些数据重新组成一个表,这样在查询时会减少连接提高效率。
4.分割表(重点)
- 水平分割:根据行的使用特点进行分割,分割之后所有表的结构都相同。而存储的数据不同。使用并(Union)操作。
- 垂直分割:根据列的特点分割,分割后所得表除了都包含主码外其他列都不相同。通常将常用列与不常用列分别放在不同表中,查询减少I/O次数。缺点是使用连接(Join)操作
5.新增汇总表
大量执行报表等汇总操作会影响性能。
为降低汇总操作的时间,将频繁使用的统计中间结果或最终结果存储在汇总表中,从而降低数据访问量和汇总操作的CPU计算量。
如:日销售额统计表
10.4.3 存储优化
1.物化视图(索引视图)
定义:包括一个查询结果的数据库对象,是预先计算并保存表连接或聚集等耗时较多的操作结果。(一个定期刷新数据的视图,自动刷新或人工刷新)
适用于多个数据量较大的表进行连接操作及分布式数据库中在多站点的表进行连接时使用。
物化视图还可以进行远程数据的本地复制(物化视图的存储也称为快照),用于实施数据库间的同步。
2.聚集
聚集是物理存储表中数据的可选择的方法。
一个聚集是一组表,将经常一起使用的具有同一公共列值的多个表中的数据行存储在一起,由公共列构成聚集码。
作用:最小化必须执行的I/O次数。
注意:将记录插入聚集的表之前,必须建立聚集索引,且按聚集码进行索引;对于剧集中的多个表,聚集值只存储一次。
劣势:聚集表的插入、更新、删除性能差,具体使用要权衡。
10.4.4 查询优化
效率低下的SQL语句常常是系统效率不佳的主要原因。常用优化方法如下:
1.合理使用索引
权衡:索引提高查询效率,索引增加系统开销。
建立索引原则:
- 是否为一个属性建索引:该属性是码或存在某个查询中被使用。
- 在哪些属性建立索引:若一个关系的多个属性共同出现在若干个查询中,一般会采用多属性索引。
- 是否建立聚簇索引:聚簇索引适合范围查询,可建立多属性索引。优点体现在数据记录存取过程中。
- 使用散列还是树索引:散列适合等值查询;关系数据库多使用B+索引,支持作为搜索码的属性上的等值查询和范围查询。
索引使用原则:
- 经常在查询中作为条件被使用的列,应为其建立索引。
- 频繁进行排序或分组的列,应为其建立索引。
- 一个列的值域很大时,应为其建立索引。
- 如果待排列的列有多个,建复合索引。
- 可以使用系统工具来检查索引完整性,必要时进行修复。当数据表更新大量数据后,删除并重建索引以提高查询。
索引建立完成后,运行期间还需调优。
调优的目的:动态地评估需求。
索引调整和修改的原因:
- 由于缺少索引,某些查询语句执行时间过长。
- 某些索引自始至终没有使用,却占用了较多磁盘空间。
- 某些索引建立在被频繁改变的属性上,导致系统开销过大。
2.避免或简化排序
ORDER BY和GROUP BY语句的执行涉及排序,磁盘排序开销很大,应利用索引自动以适当的次序产生输出。
影响优化器的因素:
- 由于现有索引不足,导致排序索引中不包括一个或几个待排序的列。
- Group by和order by子句中列的次序与索引次序不一致。
- 排列的列来自不同的表。
- 为避免不必要的排序,要正确地增建索引,合理合并数据库表,如排序不可避免,则简化它,如缩小排序列的范围。
3.消除对大型表数据的顺序存取
嵌套查询中,对表的顺序存取严重影响查询效率。
优化方法:对连接列进行索引,或使用并集来避免顺序存取。
4.避免复杂正则表达式
原因:消耗较多CPU资源进行字符串匹配。
5.使用临时表加速查询
将表的一个子集进行排序并创建临时表。
6.用排序来取代非顺序磁盘存取
原因:非顺序磁盘存取最慢。使用以数据库排序功能为基础的SQL替代非顺序存取。
7.不充分的连接条件。
原因:左(右)外连接包含与NULL数据匹配,相比内连接,代价可能很高。
8.存储过程
尽量使用自带返回参数,而非自定义返回参数,减少不必要参数,避免数据冗余。
9.不要随意使用游标
原因:占用较多系统资源。尤其是大规模并发情况下,很容易使得系统资源耗尽而崩溃。
10.事务处理
一旦将多个处理放入事务,会降低系统处理速度。将频繁操作的多个可分割的处理过程放入多个存储过程中,这样就大大提高系统响应速度。
10.4.5 SQL Server 性能工具
1.SQL Server Profiler
用来监视SQL Server事件的多用途监控工具(性能、存储过程、T-SQL语句运行等监控)。结果存储在一个跟踪文件中,可通过分析文件诊断问题。
2.数据库引擎优化顾问
测试数据库工作负荷(一组在数据库中执行的T-SQL语句),给出优化建议。
第十一章 故障管理
11.1 故障管理概述
11.1.1 故障类型及其解决方案
1.事务内部的故障
事务内部故障:事务故障导致数据不一致,分为预期的(大部分)和非预期的。
- 预期的事务内部故障:可通过事务过程本身发现的。解决办法:事务回滚
- 非预期的事务内部故障:不能由事务程序处理的故障,如运算溢出等。事务故障的恢复由系统自动完成。
2.系统故障
又称软故障,运行期间,由于硬件故障、数据库软件及OS漏洞、突然断电等故障,导致数据不一致。
解决办法:重启后,撤销(UNDO)所有未提交的事务;重做(REDO)所有已提交的事务;
3.介质故障
又称硬故障,运行期间由于磁头碰撞、磁盘损坏、强磁干扰、天灾人祸等,使得数据丢失的一类故障。导致物理存储设计损坏,数据文件及数据全部丢失,破坏性最大。
容错策略:软件容错及硬件容错。
4.软件容错:
使用数据库备份及事务日志文件,通过恢复技术,恢复数据库到备份结束时的状态。若故障导致事务日志文件丢失,则不能完全恢复。
5.硬件容错:
一种方案是使用双物理存储设备,如双硬盘镜像。缺点:自然灾害或机房水灾、火灾导致双硬盘同时损坏,则失去保护作用。
另一种方案是设计两套相同的数据库系统,通过数据库软件机制,同步变化数据。
6.计算机病毒故障
病毒是恶意的计算机程序,破坏OS及数据库系统(破坏数据文件为主)。
解决办法:防火墙、杀毒软件、数据库备份文件。
11.1.2 数据库恢复技术概述
无论哪种故障,恢复的基本原理是冗余。
数据库恢复:把数据库从错误状态恢复到某一已知的正确状态。
在DBMS中,数据库恢复子系统占10%以上。
恢复机制涉及两个问题:如何建立冗余数据;如何利用这些冗余数据实施数据库恢复。
建立冗余据的技术:
数据备份、登记日志文件、数据库复制、数据库镜像、为段设立保存点以及使用后备段与现行页表来支持对段的保存等。最常用的是数据备份和登记日志文件。
11.2 数据转储
数据转储即数据备份:指DBA或DBMS定期复制数据库,并将其存放到其他介质的过程。这些保存的副本被称为后援副本或后备副本。
11.2.1 静态转储和动态转储
1.静态转储
静态转储:期间系统不能运行其他事务,不允许任何存取、修改活动。
静态转储保证数据的一致性,但降低了数据库的可用性。转储和事务是互斥的。
2.动态转储
动态转储:即允许转储和事务并发执行。
动态转储不能保证转储数据的一致性。
动态转储+日志文件(记录转储期间各事务对数据库的修改活动记录):既保证数据一致性又提高了数据库的可用性。
11.2.2 数据转储机制
- 完全转储:对数据库中所有数据进行转储。占据较多时间和空间,但恢复时间短。
- 增量转储:只复制上次转储后发生变化的文件或数据块。 所需时间及空间短,但只能和完全转储配合才能对数据库进行恢复。
- 差量转储:对最近一次数据库完全转储以来发生的数据变化进行转储。
11.2.3 多种转储方法结合使用
- 仅使用完全转储:占据时间和空间多,代价大。
- 完全转储+增量转储:恢复时间较长。
- 完全转储+差量转储:恢复时间短。
11.3 日志文件
11.3.1 日志文件的概念
DBMS运行中,将所有事务的修改操作登记到日志文件。
作用:事务故障恢复和系统故障恢复必须使用日志文件。
在动态转储方式中必须建立日志文件。
在静态转储方式中也可使用日志文件。
11.3.2 日志文件的格式与内容
两种格式:
1.以记录为单位的日志文件
需要记录的内容:
- 各个事务的开始标记 BEGIN TRANSACTION
- 各个事务的结束标记 COMMIT OR ROLLBACK
- 各个事务的所有更新操作
2.以数据块为单位的日志文件
日志记录的内容包括:事务标识和被更新的数据块
11.3.3 登记日志文件的原则
- 登记的次序严格按并行事务执行的时间次序。保证事务对数据库的操作的可再现性和正确性。
- 必须先写日志文件,后写数据库。 先后顺序导致必然性。
11.3.4 检查点
1.检查点的作用
检查点的作用:最大限度地减少数据完全恢复时必须执行的日志部分。
2.检查点的引入
在日志中增加检查点记录,增加一个“重新开始文件”。
检查点记录的内容:建立检查点时刻正执行的事务清单;这些事务最近一个日志记录的地址。
重新开始文件记录的内容:各个检查点记录在日志中的地址。
3.基于检查点的恢复步骤
- 从“重新开始文件”中找到最后一个检查点记录在日志文件中的地址,从而找到最后一个检查点记录。
- 由该检查点记录得到执行的事务清单ACTIVE_LIST。
- 从检查点开始正向扫描文件。
- 对UNDO-LIST中的事务执行UNDO, 对REDO-LIST中的事务执行REDO。
11.4 硬件容错方案
11.4.1 概述
由于数据库运行的硬件故障、机房电力故障、机房自然灾害等,要求从硬件级别对DBMS进行保护。
从DBMS运行所需要的各种环境出发,分析支撑数据库系统运行的环节。
相关度最紧密的技术:数据库存储保护技术,服务器容错技术及数据库镜像与容灾技术。
11.4.2 磁盘保护技术
RAID:廉价冗余磁盘阵列,多块磁盘构成的一个整体。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ROnrtopg-1581906147983)(en-resource://database/2053:0)]
RAID依靠冗余技术 数据保护:
-
镜像冗余
即把所有的数据复制到其他设备。
额外开销大:更多的磁盘、控制器、电缆。 -
校验冗余
对成员磁盘的数据执行异或(XOR)操作,得到其校验值,并存放在另外的校验盘上。
实现复杂,但比镜像冗余占据的空间小。
RAID根据所采用的方法不同,分为RAID-0,RAID-1,RAID-1E,RAID-5,RAID-6, RAID-7,RAID-10,RAID-50,RAID-60。
- RAID-0:将多个磁盘合并成一个大的磁盘,不具有冗余,并行I/O,速度最快。
- RAID-1:两组以上的N个磁盘相互作镜像,在一些多线程操作系统中能有很好的读取速度,理论上读取速度等于硬盘数量的倍数,另外写入速度有微小的降低。只要一个磁盘正常即可维持运作,可靠性最高。
- RAID-5:RAID Level 5是一种储存性能、数据安全和存储成本兼顾的存储解决方案。它使用的是Disk Striping(硬盘分区)技术。RAID 5至少需要三颗硬盘,RAID 5不是对存储的数据进行备份,而是把数据和相对应的奇偶校验信息存储到组成RAID5的各个磁盘上,并且奇偶校验信息和相对应的数据分别存储于不同的磁盘上。
- RAID-10:RAID0与RAID-1的组合体,继承了前者的快速,后者的安全。 RAID-10冗余度为50%。
11.4.3 服务器容错技术
引入服务器容错原因
解决服务器硬件异常问题。
服务器容错技术简介
采用两台相同的服务器,共享存储设备。(双机热备,Active-Standby)
两台服务器之间会有私有网络进行心跳检测。
服务器接管过程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DJztPdnJ-1581906147984)(en-resource://database/2057:0)]
其他服务器容错技术
硬件级别:自行设计制造的专用软硬件架构。
软件级别:专门的服务器级别容错技术,如Oracle提供了RAC架构。
11.4.4 数据库镜像与数据库容灾
引入数据库镜像原因
前面几种恢复技术都必须及时正确地转储数据库。
数据库镜像简介
是一种用于提高数据库可用性的解决方案,它根据DBA的要求,自动把整个数据库或关键数据复制到另一个磁盘上。
数据库镜像分类
- 双机互备援模式:两台机器均为工作机。正常状况下均为系统提供支持,互相监视对方的运行情况。
- 双机热备份模式:一台为工作机,一台为备份机。工作机为系统提供支持,备份机监视工作机的运行情况。
工作方式
“数据库镜像会话”中,主体服务器和镜像服务器作为“伙伴”进行通信和协作。在会话中扮演互补角色。一旦出现故障,使用“角色切换”过程来互换主体服务器和镜像服务器。
SQL Server数据库镜像简介
SQL Server数据库镜像是将数据库事务处理从一个SQL Server数据库移到不同的SQL Server数据库。
镜像的复制是一个备用的复制,不能直接访问,只用来进行错误恢复。
“见证服务器”使镜像服务器自动识别。
两种运行模式 :“高安全性模式”及运行模式。
SQL Server数据库镜像提供三种实现方式:
高可用性。两台服务器同步事务写入,支持自动错误恢复。
高保护性。两台服务器同步事务写入,手工错误恢复。
高性能。两台服务器写入不同步,手工错误恢复。
附录 参考文献
[1] 何玉洁,刘乃嘉. 全国计算机等级考试三级教程——数据库技术. 2019版. 北京:高等教育出版社,2019.
[2] 小贤贤233. 计算机三级数据库技术笔记. CSDN, 2020.
[3] 233网校. 计算机三级数据库技术. 233网校,2020.