
查看文件路径
当我们需要导入文件时,如果直接输入当前的绝对路径,那么在更换运行环境时,就需要手动设置新的路径。利用os模块的自带函数,我们可以轻松解决这一问题。
#当我们需要获取文件的当前地址,可以用 __file__
current_file = __file__
#输出结果为: c:\python\code\program.py
#要获取根目录的地址,可以输入
root_path = os.path.abspath(os.path.join(current_file, os.pardir, os.pardir))
#其中 os.path.abspath(path) 可返回绝对路径
os.path.abspath(os.path.join(current_file, os.pardir, os.pardir))
# current_file是c:\python\code\program.py,那么os.path.abspath(os.path.join(current_file, os.pardir, os.pardir))是c:\
#获得根目录的变量
root_path = os.path.abspath(os.path.join(current_file, os.pardir, os.pardir))
#然后可以按需指定目录的地址,例如
input_data_path = os.path.abspath(os.path.join(root_path, 'data', 'input_data'))
# input_data_path 的路径是根目录下的\data\input_data
# 绝对地址就是c:\python\\data\input_data
调用简单函数的方法
假设我们写了一个自定义函数:
def addone(x):
return x+1
要调用这个函数时,可使用apply函数,也可以使用lambda函数进行调用。
#apply的方式
print df[['涨跌幅']].apply(addone)
#lambda的方式
print df[['涨跌幅']].apply(lambda x: x+1)
补全数据
有时候获得的股票行情数据,会出现非交易日缺失的情况,这时就需要基于指数交易日的数据,用merge函数对其进行补全。

还有个参数是indecator,等于True时增加merge列,表明该行数据的出处,源自哪一张表,有left、right、both的区分。
如果是堆砌,可用concat函数,相关参数如下:

import pandas as pd
s1 = pd.Series([0,1,2],index = ['a','b','c'])
s2 = pd.Series([2,3,4],index = ['c','f','e'])
s3 = pd.Series([4,5,6],index = ['c','f','g'])
series = pd.concat([s1,s2,s3])#默认并集、纵向连接
series

series = pd.concat([s1,s2,s3],ignore_index = True) # 生成纵轴上的并集,索引会自动生成新的一列
series
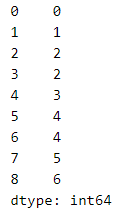
series = pd.concat([s1,s2,s3],axis = 1,join = 'inner')
series
# 纵向取交集,注意该方法对对象表中有重复索引时失效

series = pd.concat([s1,s2,s3],axis = 1,join = 'outer')
series
# 横向索引取并集,纵向索引取交集,注意该方法对对象表中有重复索引时失效

resample函数
通常我们获得的数据是日线数据,需要转化成周数据或月数据时,可用resample函数获得。
当索引为时间格式时,可用resample函数将时间序列数据自动分割为周、月、季、年等块,然后再进行相应的处理。这里需要用到参数rule,参数rule='w'代表转化为周,'m'代表月,'q'代表季度,'y'代表年份。'5min'代表5分钟,'1min'代表1分钟。
week_df = df.resample(rule='w').last() # 意思是展现每周最后一个交易日的数据
week_df['开盘价'] = df['开盘价'].resample(rule='w').first() # 获得开盘价数据
week_df['成交量'] = df['成交量'].resample(rule='w').sum() # 获得成交总量数据
week_df['最高价'] = df['最高价'].resample(rule='w').max() # 获得最高价数据
week_df['最低价'] = df['最低价'].resample(rule='w').min() # 获得最低价数据
#若要获得周涨幅,一般可用公式【(最后一天的收盘价 - 第一天的开盘价) / 第一天的开盘价 】进行计算,也可以用lambda函数直接获得
week_df['涨跌幅'] = df['涨跌幅'].resample(rule='w').apply(lambda x: (x+1.0).prod() - 1.0 )
用os.walk导入数据
当输入os.walk(data_path)时,会返回root、dirs和files的数据,root是文件的路径,dir是路径下有什么文件夹(返回列表),files是路径下有什么文件(返回列表)。
然后程序会到第一个文件夹里面,继续返回相应的root、dirs和files……直至全部遍历。
有了这个系统自带函数,后面就好办了。
首先,我们要获得想要导入的股票的代码的列表。
list = []
data_path = config.data_path + '/data'
for root, dirs, files in os.walk(data_path):
if files: # 当files不为空
for i in files: #对files的每一个文件
if i.endswith('.csv'): # 选取以csv为后缀的文件
list.append(i[:8]) #将该文件的前8个字符加入到列表中
print list
第二步,开始根据列表来导入数据
alldata = pd.DataFrame()
for stock in list:
print stock
df = importcode.import(stock)
alldata = alldata.append(df, ignore_index = True)
print alldata
CSV的替代——HDF
一般储存数据是用csv格式,但pandas提供了一种更高效率的方式,那就是hdf格式。
想象一张Excel表,sheetname这里称作KEY,参数mode可以是w新建,也可以是a,append。更多参数如下:

保存的命令为:
#alldata.to_hdf(path, key='',mode='')
alldata.to_hdf(config.output_data_path + '/alldata.h5', key='all_stock_data', mode='w'))
# 在前面的例子中,读取的股票数据df,可以这样保存
# h5[stock] = df
# 或者
# df.to_hdf(path, key = code, mode='a')
#保存完数据之后,记得关闭h5文件,否则容易报错
h5.close()
要读取的时候,可以用 pd.read_hdf(path, key='')

#读取某个stock的数据有两种方式
print h5.get('sz000006')
print h5['sz000007']
#查询有多少张表,可以用keys()
print h5.keys()
分组统计的groupby函数
一张超大的数据表中,我们想要看某只股票的平均价格,可用groupby函数来实现。
1、基本的groupby用法
print stock_data.groupby('交易日期') #按交易日期来分组
print stock_data.groupby('交易日期') .size() #显示每天交易股票的数量
print stock_data.groupby('股票代码') .size() #显示每只股票累计交易的天数
#分组后想看某只股票的数据,可用get_group()
print stock_data.groupby('股票代码').get_group('002466')
#只会输出天齐锂业的数据
除此之外,还可以
print stock_data.groupby('股票代码').describe()
print stock_data.groupby('股票代码').first()
print stock_data.groupby('股票代码').last()
print stock_data.groupby('股票代码').head()
print stock_data.groupby('股票代码').tail()
print stock_data.groupby('股票代码').nth(n) 表示该组的第n行数据
输出的时候,默认group的变量,即股票代码为index,不想这样的话,可以用as_index=False, 例如:
print stock_data.groupby('股票代码',as_index=False)
还可以
print stock_data.groupby('股票代码')['收盘价', '涨跌幅'].mean() 取某列数据算均值
.max()
.sum()
都是可以的。
还可以输出排名,用rank()
print stock_data.groupby('股票代码')['成交量'].rank() 输出组内的算数排名
print stock_data.groupby('股票代码')['成交量'].rank(pct=True) 输出百分比
还可以
print stock_data.groupby(stock_data['交易日期'].dt.year).size() # 计算该年共有多少个交易数据
还可以先groupby一个,然后再在其中groupby另一个参数,例如:
stock_data.groupby(['股票代码’, stock_data['交易日期'].dt.year]).size() # 按照股票代码分组,然后求该证券每年有多少个交易日
2、进阶的groupby用法
前面介绍的resample、apply、fillna等函数,都可以嵌入到groupby函数里面。
当然,也可以用笨办法,用for key, group in df.groupby('列名称'): 将所需功能遍历一遍,以达到相同的效果。key是列名,列的每一个内容,group是该列的内容。
遍历的时候,对group进行单独操作即可,例如group.apply()或group.fillna()。
然后只要将每个group append起来即可。
结语
上述回顾的函数和功能,在量化投资的实际操作中会经常用到,必须熟练掌握。
刺猬偷腥
2018年10月8日