自然语言处理怎么最快入门?
首页 发现 话题
登录 加入知乎
自然语言处理怎么最快入门?
关注问题 写回答
28 个回答
默认排序

微软亚洲研究院
收录于 编辑推荐、知乎圆桌 ·
539 人赞同了该回答

编辑于 2017-03-06
539 23 条评论
收藏 感谢
收起
分享

刘知远
收录于 知乎圆桌 ·
470 人赞同了该回答
编辑于 2015-07-16
470 17 条评论
收藏 感谢
收起
分享

知乎用户
收录于 编辑推荐 ·
1275 人赞同了该回答
编辑于 2015-10-06
1.3K 29 条评论
收藏 感谢
收起
分享
知乎用户
230 人赞同了该回答
编辑于 2014-12-19
230 21 条评论
收藏 感谢
收起
分享

何史提
10 人赞同了该回答
发布于 2014-07-08
10 4 条评论
收藏 感谢
分享

机器之心
51 人赞同了该回答
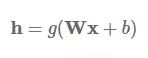
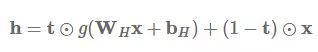

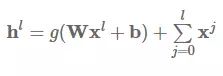
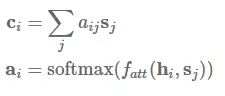
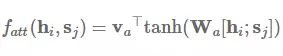
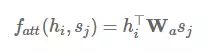
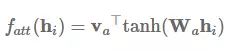
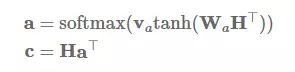
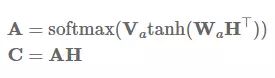
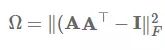
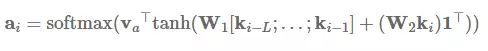
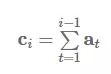
发布于 2017-07-26
51 1 条评论
收藏 感谢
收起
分享

陈见耸
24 人赞同了该回答

发布于 2017-05-10
24 2 条评论
收藏 感谢
收起
分享

杨智
44 人赞同了该回答
发布于 2016-05-15
44 5 条评论
收藏 感谢
分享

秋天的松鼠
29 人赞同了该回答
发布于 2016-07-04
29 1 条评论
收藏 感谢
分享
知乎用户
54 人赞同了该回答
编辑于 2011-12-09
54 8 条评论
收藏 感谢
分享

weizier
26 人赞同了该回答
发布于 2015-02-03
26 2 条评论
收藏 感谢
收起
分享
柯子烜
8 人赞同了该回答
发布于 2016-08-25
8 添加评论
收藏 感谢
分享
知乎用户
1 人赞同了该回答
编辑于 2013-02-01
1 5 条评论
收藏 感谢
分享

眉大侠
6 人赞同了该回答
发布于 2013-12-03
6 添加评论
收藏 感谢
分享

Don Juan
6 人赞同了该回答
发布于 2015-10-01
6 1 条评论
收藏 感谢
分享

尔多
3 人赞同了该回答
发布于 2017-03-06
3 1 条评论
收藏 感谢
分享

陈科伟
3 人赞同了该回答
发布于 2013-11-03
3 添加评论
收藏 感谢
分享
知乎用户
4 人赞同了该回答
发布于 2016-04-06
4 2 条评论
收藏 感谢
分享
知乎用户
2 人赞同了该回答
发布于 2017-03-17
2 添加评论
收藏 感谢
分享

匿名用户
1 人赞同了该回答
编辑于 2016-12-19
1 1 条评论
收藏 感谢
分享
更多
下载知乎客户端
与世界分享知识、经验和见解
淘宝的评论归纳是如何做到的? 11 个回答
如何判断一段声音是不是自然语言? 30个回答
如何向文科同学科普自然语言处理(NLP)? 13 个回答
Python 在网页爬虫、数据挖掘、机器学习和自然语言处理领域的应用情况如何?15 个回答
金融市场计算机化的交易程序是如何根据新闻进行自动交易的?目前这种技术的应用广泛吗? 16 个回答
侵权举报 网上有害信息举报专区
联系我们 © 2017 知乎