【Python爬虫教学】百度篇·手把手教你抓取百度搜索关键词后的页面源代码
【开门见山】
最近整理了下之前做过的项目,学的东西不少,乱七八糟。打算写点关于 Python 爬虫的东西,新人一枚,还望大佬们多多担待,别把我头给打歪了。
前面我先磨叽磨叽些基础的东西,对爬虫新人友好些,总代码在最后,直接 Ctrl + C就好。
工具篇:
我们需要两个工具,分别是这两个玩意:PyCharm和Google 浏览器


PyCharm
Google 浏览器
我用的版本是PyCharm 5.0.3和Python 3.6.6
教学开始!
第一步,打开 PyCharm
第二步,打开 Google 浏览器
第三步,开始分析
…
抓取百度搜索关键词后的页面源代码分为五步走:
1、获取想要抓取的信息
2、如果想获取的信息为中文,则需要进行url编码
3、进行拼接页面的真实 url (url指的是网址,后面就直接写url了)
4、通过下载器模块抓取网页信息
5、将获取的网页源代码保存为 html 文件存储到本地
一、Python爬虫的下载器
分为两种urllib.request和requests
urllib.request——python2版本中的升级版
requests——python3中的新版本
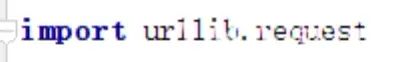
这里直接使用 import语句导入就好,轻松方便,多省事
二、使用 urllib.request
讲讲几个比较常用的玩意:
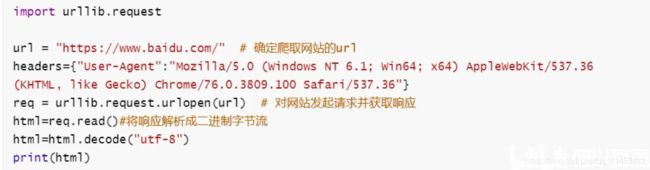
1)urllib.request.urlopen(url):对网页发起请求并获取响应
示例代码:
2)urllib.request.Request(url,headers)创建请求对象
示例代码:

三、理智分析
我们来尝试用百度搜索点东西,比如:
![]()
![]()
我们来复制下会看到
Bilibili:
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=Bilibili&oq=%25E7%25AF%25AE%25E7%2590%2583&rsv_pq=83f19419001be70a&rsv_t=4115%2F8nYNTS0ycM92Jyo7EyG93G5SsWNuSPyrV5xFkZ2RPcEpqYZWJVokzM&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=11&rsv_sug1=8&rsv_sug7=100&rsv_sug2=0&inputT=7505&rsv_sug4=7789
b站:
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=B%E7%AB%99&oq=Bilibili&rsv_pq=a2665be400255edc&rsv_t=5c8aBmClupFcVXiNpBa79qMXk3UM6qIj614z6VmEmtJHhkeIvp7hddX9oio&rqlang=cn&rsv_enter=1&rsv_dl=tb&inputT=7100&rsv_sug3=22&rsv_sug1=17&rsv_sug7=100&rsv_sug2=0&rsv_sug4=7455
我们仔细一瞅···


这特喵的一毛一样,关键在哪里?
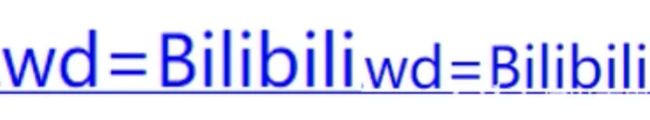
和

没错,它把‘站’字进行 url编码了,这就好办了
四、url编码模块 urllib.parse
我们用这玩意来干掉它。还是来讲讲常用的玩意
1)urllib.parse.urlencode() url编码
示例代码:

运行结果:
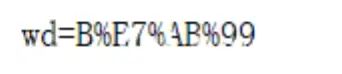
2)urllib.parse.quote(字符串) url编码
示例代码:

运行结果:
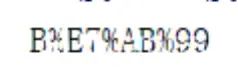
3)urllib.parse.unquote(url编码) 对url编码进行反编码
示例代码:

运行结果:
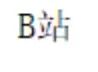
五、最后一步
看到这相信大部分人都懂了,问题迎刃而解。我们要搜索 “B站” 无非就是 https://www.baidu.com/s?&wd=B站 同理也就是https://www.baidu.com/s?&wd=B%E7%AB%99
抓取百度搜索关键词后的页面源代码程序代码:
import urllib.request
import urllib.parse
key=input("请输入您要查询的内容:") # 获取想要搜索的信息
key={"wd":key}
data=urllib.parse.urlencode(key) # 对关键字进行url编码
base_url="https://www.baidu.com/s?" #搜索网页的默认url
url=base_url+data #拼接得到真实的url
headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
req=urllib.request.Request(url,headers=headers) #创建请求对象
res=urllib.request.urlopen(req) #对网页发起请求并获取响应
html=res.read().decode("utf-8")
with open("百度.html","w",encoding="utf-8") as f:
f.write(html)
总结:
我们把这个项目分为了五步:
一、获取想要抓取的信息
key=input("请输入您要查询的内容:")
二、如果想获取的信息为中文,则需要进行 url编码
key={"wd":key}
data=urllib.parse.urlencode(key)
三、进行拼接页面的真实 url
base_url="https://www.baidu.com/s?" #搜索网页的默认url
url=base_url+data #拼接得到真实的url
四、通过下载器模块抓取网页信息
headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
req=urllib.request.Request(url,headers=headers) #创建请求对象
res=urllib.request.urlopen(req) #对网页发起请求并获取响应
五、将获取的网页源代码保存为 html 文件存储到本地
html=res.read().decode("utf-8")
with open("百度.html","w",encoding="utf-8") as f:
f.write(html)
新人报道,互相讨教,其乐融融,妙妙妙