英伟达A100 Tensor Core GPU架构深度讲解
计算机视觉研究院专栏
作者:Edison_G
现代云数据中心运行的计算密集型应用的多样性推动了NVIDIA GPU加速云计算的爆发。这种密集的应用包括人工智能深度学习训练和推理、数据分析、科学计算、基因组学、边缘视频分析和5G服务、图形渲染、云游戏等。从扩展AI训练和科学计算,toscaling-out inference applications,启用实时会话AI,NVIDIA GPU提供了必要的马力,以加速许多复杂和不可预测的工作负载运行在今天的云数据中心。
NVIDIA®GPU是推动人工智能革命的主要计算引擎,为人工智能训练和推理工作负载提供了巨大的加速。此外,NVIDIA GPU加速了许多类型的HPC和数据分析应用程序和系统,使客户能够有效地分析、可视化和将数据转化为洞察力。NVIDIA的加速计算平台是世界上许多最重要和增长最快的行业的核心。

1、简要
HPC已经超越了运行计算密集型应用的超级计算机,如天气预报、油气勘探和金融建模。今天,数以百万计的NVIDIA GPU正在加速运行在云数据中心、服务器、边缘系统甚至桌面工作站中的许多类型的HPC应用程序,为数百个行业和科学领域服务。
人工智能网络的规模、复杂性和多样性继续增长,基于人工智能的应用程序和服务的使用正在迅速扩大。NVIDIA GPU加速了许多人工智能系统和应用,包括:深度学习推荐系统、自动驾驶机器(自动驾驶汽车、工业机器人等),自然语言处理(会话AI,实时语言翻译等)、智能城市视频分析、5G网络(可以在边缘提供基于AI的服务)、分子模拟、无人机控制、医学图像分析等。
现代云数据中心的多样化和计算密集型工作负载需要NVIDIA GPU加速。
2、NVIDIA A100 Tensor Core GPU——第八代数据中心GPU的灵活计算时代
新的NVIDIA®A100 Tensor Core GPU建立在以前的NVIDIA Tesla V100 GPU的能力之上,增加了许多新的功能,同时为HPC、AI和数据分析工作负载提供了更快的性能。由基于NVIDIA安培架构的GA100 GPU驱动,A100为GPU计算和深度学习应用程序提供了非常强大的扩展,这些应用程序运行在单个和多GPU工作站、服务器、集群、云数据中心、边缘系统和超级计算机中。A100GPU可以建立灵活、多功能和高吞吐量的数据中心。
该A100 GPU包括一个革命性的新的“Multi-Instance GPU”(或MIG)虚拟化和GPU分区能力,特别有利于云服务提供商(CSP)。当配置为MIG操作时,A100允许CSP提高其GPU服务器的利用率,提供多达7倍的GPU实例,而不需要额外的成本。鲁棒的故障隔离允许客户安全可靠地划分单个A100 GPU。
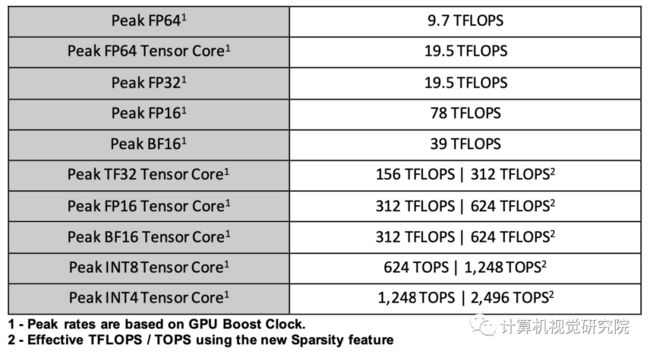
A100增加了一个强大的新的第三代Tensor Core,它在V100之上提高了吞吐量,同时增加了对DL和HPC数据类型的全面支持,以及一个新的稀疏特性,以实现吞吐量的进一步翻倍。

在A100中的新Tensor Float-32(TF32)TensorCore操作提供了一条简单的路径来加速DL框架和HPC中的FP32输入/输出数据,运行速度比V100 FP32 FMA操作快10倍或稀疏20倍。对于FP16/FP32混合精度DL,相比于V100,A100 Tensor Core提供2.5倍的性能,增加到5倍的稀疏性。
新的Bfloat16(BF16)/FP32混合精度Tensor Core操作以与FP16/FP32混合精度相同的速度运行。INT8、INT4和二进制舍入的张量核心加速支持DL推理,A100稀疏的INT8比V100 INT8运行更快,快20倍。对于HPC,A100 Tensor Core包括新的IEEE兼容FP64处理,比V100的FP64性能快2.5倍。

A100 GPU是为广泛的性能可伸缩性而设计的。客户可以使用MIG GPU分区技术共享单个A100,也可以使用新的第三代NVIDIA NVLink连接多个A100 GPU®强大的新NVIDIA DGXTM、NVIDIA HGXTM和NVIDIAEGXTM。由新的NVIDIA NVSwitchTM和Mellanox连接的基于A100的系统®最先进的InfiniBand和以太网解决方案可以扩展到计算集群、云实例或巨大的超级计算机中的几十、数百或数千个A100,以加速许多类型的应用程序和工作负载。此外,A100 GPU革命性的新硬件能力得到了新的CUDA 11功能的增强,这些功能提高了可编程性,降低了AI和HPC软件的复杂性。
NVIDIA A100 GPU是第一个Elastic GPU体系结构,能够使用NVLink、NVSwitch和InfiniBand扩展到巨型GPU,或扩展到支持多个独立用户的MIG,每GPU实例同时实现伟大的性能和最低的成本。
NVIDIA A100 Tensor Core GPU提供了NVIDIA GPU加速计算有史以来最大的时代飞跃。
3、人工智能、HPC和数据分析的行业领先性能
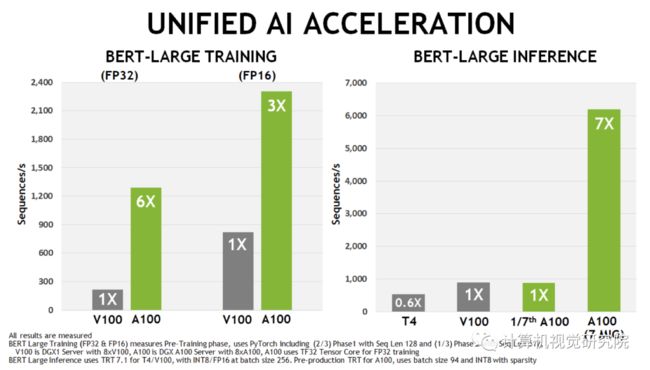
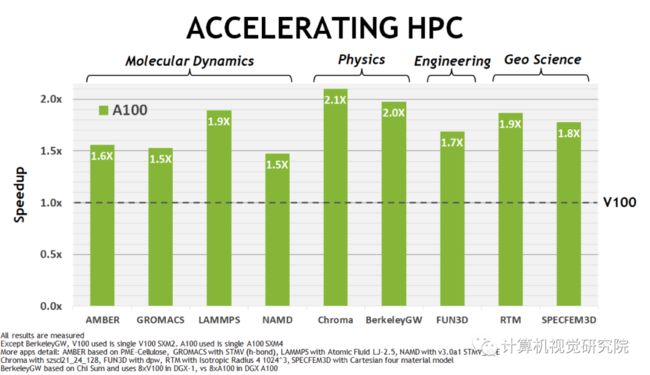
NVIDIA A100 GPU为AI训练和推理工作负载提供了V100上的特殊加速,如上图所示。同样,下图显示了不同HPC应用程序的实质性性能改进。
4、A100GPU关键特性概述
NVIDIA A100 Tensor Core GPU是世界上最快的云和数据中心GPU加速器,旨在为计算密集型AI、HPC和数据分析应用提供动力。
在台积电的7nmN7制造过程中,基于NVIDIA安培结构的GA100 GPU为A100提供动力,包括542亿个晶体管,芯片尺寸为826平方毫米。
下面提供了A100关键特性的高级别摘要,以便快速了解重要的新A100技术和性能水平。深入的架构信息将在后期分享中介绍。
5、A100 GPU Streaming Multiprocessor (SM)
NVIDIA安培体系结构中的新的SM基于A100 Tensor Core GPU显著提高了性能,建立在Volta和Turing SM体系结构中引入的特性基础上,并增加了许多新功能。A100第三代Tensor Core增强了操作数共享和效率,并添加了强大的新数据类型,包括:
加速处理FP32数据的TF32张量核心指令 ;
符合IEEE标准的HPC FP64张量核指令 ;
与FP16吞吐量相同的BF16张量核心指令。
在A100 Tensor Core中,新的稀疏支持可以利用深度学习网络中的细粒度结构的稀疏性,使TensorCore操作的吞吐量增加一倍。稀疏性特征在下面“A100 Introduces Fine-Grained Structured Sparsity“部分中作了详细描述。
在A100中,更大更快的L1缓存和共享内存单元提供的每SM聚合容量是V100的1.5倍,(192KB vs 128KB per SM)为许多HPC和AI工作负载提供了额外的加速。其他一些新的SM特性提高了可编程性,降低了软件的复杂性。
40 GB HBM2 and 40 MB L2 cache
为了满足巨大的计算吞吐量,NVIDIA A100 GPU拥有40gb的高速HBM2内存,其内存带宽达到1555gb/s,比Tesla V100提高了73%。此外,A100 GPU的片上内存显著增加,包括一个比V100大近7倍的40MB二级(L2)缓存,以最大限度地提高计算性能。A100二级缓存采用了一种新的分区交叉结构,提供了V100二级缓存读取带宽的2.3倍。
为了优化容量利用率,NVIDIA安培体系结构为您提供了二级缓存驻留控制,用于管理要保留或从缓存中收回的数据。A100还增加了计算数据压缩,使DRAM带宽和二级带宽提高了4倍,二级容量提高了2倍。
Multi-Instance GPU
Multi-InstanceGPU(MIG)功能允许A100 Tensor Core GPU安全地划分为多达七个单独的GPU实例,用于CUDA应用程序,为多个用户提供单独的GPU资源以加速其应用程序。使用MIG,每个实例的处理器在整个内存系统中都有独立的路径。片上纵横端口、二级缓存组、内存控制器和DRAM地址总线都是唯一分配给单个实例的。这确保了单个用户的工作负载可以在相同的二级缓存分配和DRAM带宽下以可预测的吞吐量和延迟运行,即使其他任务正在冲击自己的缓存或使DRAM接口饱和。
MIG提高了GPU硬件利用率,同时提供了定义的QoS和不同客户端(如VMs、容器和进程)之间的隔离。MIG对于拥有多租户用例的云服务提供商尤其有利。它确保了一个客户机不会影响其他客户机的工作或调度,此外还提供了增强的安全性并允许为客户机提供GPU利用率保证。
Third-generation NVIDIA NVLink
第三代NVIDIA高速NVLink互连在A100 GPUs和新NVIDIA NVSwitch中实现,显著提高了多GPU的可扩展性、性能和可靠性。由于每个GPU和交换机有更多的链路,新的NVLink提供了更高的GPU-GPU通信带宽,并改进了错误检测和恢复功能。
第三代NVLink每个信号对的数据速率为50Gbit/sec,几乎是V100中25.78Gbit/sec速率的两倍。一个A100 NVLink在每个方向上提供25GB/s的带宽,与V100类似,但每个链路使用的信号对数仅为V100的一半。链路总数在A100中增加到12个,而在V100中增加到6个,从而产生600GB/s的总带宽,而在V100中为300GB/秒。
Support for NVIDIA Magnum IO and Mellanox interconnect solutions
A100 Tensor Core GPU与NVIDIA Magnum IO和Mellanox最先进的InfiniBand和以太网互连解决方案完全兼容,可加速多节点连接。
Magnum IO API集成了计算、网络、文件系统和存储,以最大限度地提高多GPU、多节点加速系统的I/O性能。它与CUDA-X库接口,以加速从人工智能和数据分析到可视化等各种工作负载的I/O。
PCIe Gen 4 with SR-IOV
A100 GPU支持PCI Express Gen 4(PCIe Gen 4),通过提供31.5GB/s而不是15.75GB/s的x16连接,PCIe 3.0/3.1的带宽翻了一番。更快的速度特别有利于连接到PCIe4.0能力CPU的A100 GPU,并支持快速的网络接口,如200Gbit/sec InfiniBand尤其有利。
A100还支持Single Root Input/Output Virtualization(SR-IOV),允许为多个进程或虚拟机共享和虚拟化单个PCIe连接。
Improved error and fault detection, isolation, and containment
通过detecting, containing, and often correcting errors and faults,而不是强制GPU重置,最大化GPU正常运行时间和可用性至关重要。在大型多GPU集群和单GPU、多租户环境(如MIG配置)中尤其如此。A100 Tensor Core GPU包括新技术,用于改进错误/故障属性、隔离和遏制。
Asynchronous copy
A100 GPU包括一个新的异步复制指令,该指令将数据直接从全局内存加载到SM共享内存中,从而消除了使用中间寄存器文件(RF)的需要。异步复制减少了寄存器文件带宽,更有效地使用了内存带宽,并降低了功耗。顾名思义,异步复制可以在后台完成,而SM正在执行其他计算。
Asynchronous barrier
A100 GPU在共享内存中提供硬件加速屏障。这些障碍是使用CUDA 11的形式,ISO C++符合标准的障碍对象。异步屏障将屏障到达和等待操作分开,可用于将从全局内存到共享内存的异步副本与SM中的计算重叠。它们可用于使用CUDA线程实现producer-consumer模型。屏障还提供了同步不同粒度的CUDA线程的机制,而不仅仅是扭曲或块级别。
Task graph acceleration
CUDA Task graph为向GPU提交工作提供了一个更有效的模型。Task graph由一系列操作组成,如内存拷贝和内核启动,这些操作通过依赖关系连接起来。Task graph允许定义一次并重复运行执行流。预定义的Task graph允许在单个操作中启动任意数量的内核,极大地提高了应用程序的效率和性能。A100增加了新的硬件特性,使Task graph中网格之间的路径明显更快。
下一期我们更加深入去讲解NVIDIA A100 Tensor Core GPU Architecture!
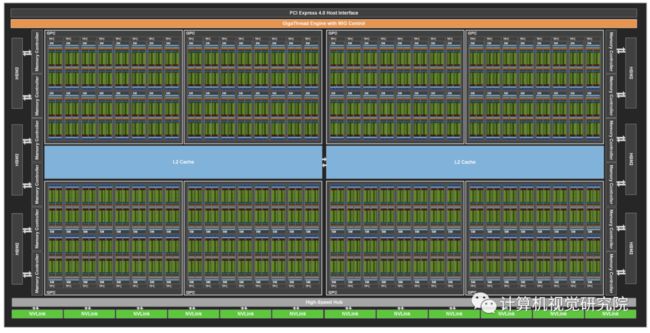
GA100 Full GPU with 128 SMs
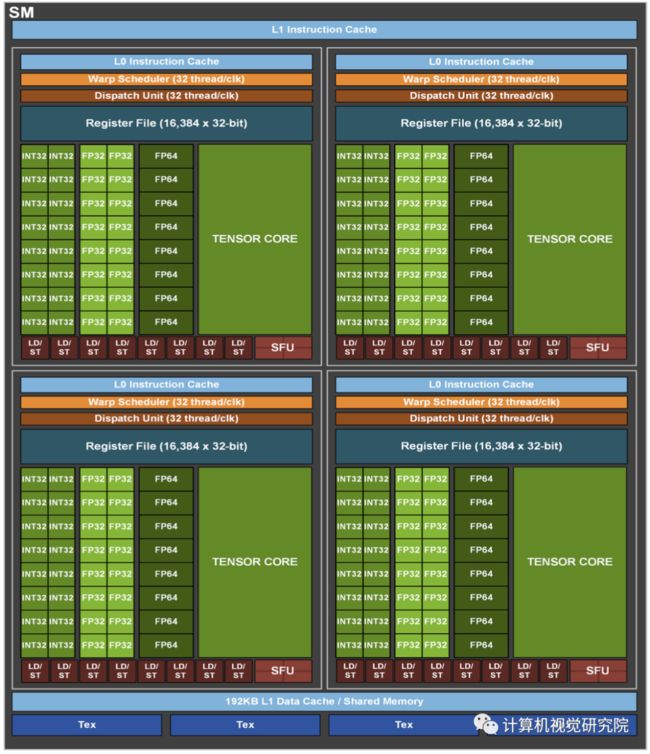
GA100 Streaming Multiprocessor (SM)
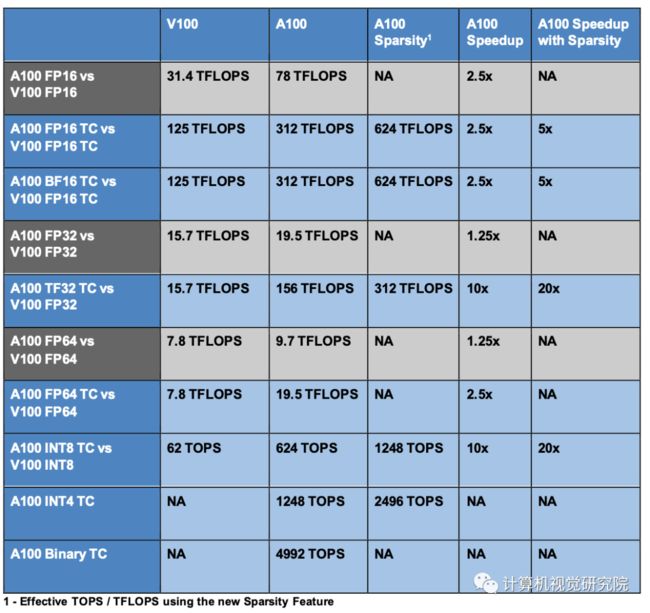
A100和V100加速比对比
敬请关注下一期深入讲解!
✄-----------------------------------
如果想加入我们“计算机视觉研究院”,请扫二维码加入我们。我们会按照你的需求将你拉入对应的学习群!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注我们
公众号 : 计算机视觉研究院