深度强化学习(5)策略梯度(Policy Gradient)
Policy Gradient
直接策略搜索方法是强化学习中一类很重要的方法。策略搜索是将策略进行参数化即 π θ ( s ) \pi_{\theta}(s) πθ(s),利用参数化的线性或非线性函数(如神经网络)表示策略,寻找最优的参数 θ \theta θ使得强化学习的目标——累积回报的期望 E [ ∑ t = 0 H R ( s t ) ∣ π θ ] E\left[\sum_{t=0}^{H} R\left(s_{t}\right) | \pi_{\theta}\right] E[∑t=0HR(st)∣πθ]最大。
本篇讨论的策略梯度(Policy Gradient),它是Policy Based的强化学习方法,基于策略来学习。
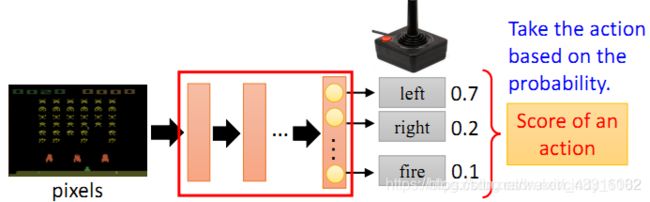
如下图所示, π θ ( s ) \pi_{\theta}(s) πθ(s)可以理解为一个包含参数 θ \theta θ的神经网络,该网络将观察到的变量作为模型的输入,基于概率输出对应的行动action。
从似然率的视角推导策略梯度
用 τ \tau τ表示一组状态-行为序列 s 0 , u 0 , ⋯ , s H , u H s_{0}, u_{0}, \cdots, s_{H}, u_{H} s0,u0,⋯,sH,uH。
符号 R ( τ ) = ∑ t = 0 H R ( s t , u t ) R(\tau)=\sum_{t=0}^{H} R\left(s_{t}, u_{t}\right) R(τ)=∑t=0HR(st,ut)表示轨迹 τ \tau τ的回报, P ( τ ; θ ) P(\tau ; \theta) P(τ;θ)表示轨迹 τ \tau τ出现的概率;则强化学习的目标函数可表示为:
U ( θ ) = E ( ∑ t = 0 H R ( s t , u t ) ; π θ ) = ∑ τ P ( τ ; θ ) R ( τ ) U(\theta)=E\left(\sum_{t=0}^{H} R\left(s_{t}, u_{t}\right) ; \pi_{\theta}\right)=\sum_{\tau} P(\tau ; \theta) R(\tau) U(θ)=E(∑t=0HR(st,ut);πθ)=∑τP(τ;θ)R(τ)
强化学习的目标是找到最优参数 θ \theta θ,使得
max θ U ( θ ) = max θ ∑ τ P ( τ ; θ ) R ( τ ) \max _{\theta} U(\theta)=\max _{\theta} \sum_{\tau} P(\tau ; \theta) R(\tau) maxθU(θ)=maxθ∑τP(τ;θ)R(τ)
这时,策略搜索方法,实际上变成了一个优化问题。我们使用最速下降法即
θ new = θ old + α ∇ θ U ( θ ) \theta_{\text {new}}=\theta_{\text {old}}+\alpha \nabla_{\theta} U(\theta) θnew=θold+α∇θU(θ)
我们对目标函数进行求导:
∇ θ U ( θ ) = ∇ θ ∑ τ P ( τ ; θ ) R ( τ ) \nabla_{\theta} U(\theta)=\nabla_{\theta} \sum_{\tau} P(\tau ; \theta) R(\tau) ∇θU(θ)=∇θ∑τP(τ;θ)R(τ)
= ∑ τ ∇ θ P ( τ ; θ ) R ( τ ) \quad=\sum_{\tau} \nabla_{\theta} P(\tau ; \theta) R(\tau) =∑τ∇θP(τ;θ)R(τ)
= ∑ τ P ( τ ; θ ) P ( τ ; θ ) ∇ θ P ( τ ; θ ) R ( τ ) =\sum_{\tau} \frac{P(\tau ; \theta)}{P(\tau ; \theta)} \nabla_{\theta} P(\tau ; \theta) R(\tau) =∑τP(τ;θ)P(τ;θ)∇θP(τ;θ)R(τ)
= ∑ τ P ( τ ; θ ) ∇ θ P ( τ ; θ ) R ( τ ) P ( τ ; θ ) =\sum_{\tau} P(\tau ; \theta) \frac{\nabla_{\theta} P(\tau ; \theta) R(\tau)}{P(\tau ; \theta)} =∑τP(τ;θ)P(τ;θ)∇θP(τ;θ)R(τ)
= ∑ τ P ( τ ; θ ) ∇ θ log P ( τ ; θ ) R ( τ ) =\sum_{\tau} P(\tau ; \theta) \nabla_{\theta} \log P(\tau ; \theta) R(\tau) =∑τP(τ;θ)∇θlogP(τ;θ)R(τ)
最终策略梯度变成了求 ∇ θ log P ( τ ; θ ) R ( τ ) \nabla_{\theta} \log P(\tau ; \theta) R(\tau) ∇θlogP(τ;θ)R(τ)的期望。我们可以利用经验平均来进行估算。因此,当利用当前策略 π θ \pi \theta πθ采样m条轨迹后,可以利用这m条轨迹的经验平均对策略梯度进行逼近:
∇ θ U ( θ ) ≈ g ^ = 1 m ∑ i = 1 m ∇ θ log P ( τ ; θ ) R ( τ ) \nabla_{\theta} U(\theta) \approx \hat{g}=\frac{1}{m} \sum_{i=1}^{m} \nabla_{\theta} \log P(\tau ; \theta) R(\tau) ∇θU(θ)≈g^=m1∑i=1m∇θlogP(τ;θ)R(τ)
其中第一项 ∇ θ log P ( τ ; θ ) \nabla_{\theta}\log P\left(\tau ;\theta\right) ∇θlogP(τ;θ) 是轨迹 τ \tau τ的概率随参数 θ \theta θ变化最大的方向,即最陡的方向。参数在该方向进行更新时,若沿着正方向,则该轨迹 τ \tau τ的概率会变大,而沿着负方向进行更新时,该轨迹 τ \tau τ的概率会变小。
再看第二项 R ( τ ) R\left(\tau\right) R(τ),该项控制了参数更新的方向和步长。 R ( τ ) R\left(\tau\right) R(τ)为正且越大则参数更新后该轨迹的概率越; R ( τ ) R\left(\tau\right) R(τ)为负,则降低该轨迹的概率,抑制该轨迹的发生。
因此,策略梯度从直观上进行理解时,我们发现策略梯度会增加高回报路径的概率,减小低回报路径的概率。
现在,我们解决如何求似然率的梯度: ∇ θ log P ( τ ; θ ) ? \nabla_{\theta}\log P\left(\tau ;\theta\right)\textrm{?} ∇θlogP(τ;θ)?
已知 τ = s 0 , u 0 , ⋯ , s H , u H \tau =s_0,u_0,\cdots ,s_H,u_H τ=s0,u0,⋯,sH,uH,则轨迹的似然率可写为:
P ( τ ( i ) ; θ ) = ∏ t = 0 H P ( s t + 1 ( i ) ∣ s t ( i ) , u t ( i ) ) ⋅ π θ ( u t ( i ) ∣ s t ( i ) ) P\left(\tau^{\left(i\right)};\theta\right)=\prod_{t=0}^H{P\left(s_{t+1}^{\left(i\right)}|s_{t}^{\left(i\right)},u_{t}^{\left(i\right)}\right)}\cdot\pi_{\theta}\left(u_{t}^{\left(i\right)}|s_{t}^{\left(i\right)}\right) P(τ(i);θ)=∏t=0HP(st+1(i)∣st(i),ut(i))⋅πθ(ut(i)∣st(i))
式中, P ( s t + 1 ( i ) ∣ s t ( i ) , u t ( i ) ) P\left(s_{t+1}^{\left(i\right)}|s_{t}^{\left(i\right)},u_{t}^{\left(i\right)}\right) P(st+1(i)∣st(i),ut(i))表示动力学,式中无参数 θ \theta θ,因此可在求导过程中消掉。具体推导如下:
∇ θ log P ( τ ( i ) ; θ ) = ∇ θ log [ ∏ t = 0 H P ( s t + 1 ( i ) ∣ s t ( i ) , u t ( i ) ) ⋅ π θ ( u t ( i ) ∣ s t ( i ) ) ] \nabla_{\theta} \log P\left(\tau^{(i)} ; \theta\right)=\nabla_{\theta} \log \left[\prod_{t=0}^{H} P\left(s_{t+1}^{(i)} | s_{t}^{(i)}, u_{t}^{(i)}\right) \cdot \pi_{\theta}\left(u_{t}^{(i)} | s_{t}^{(i)}\right)\right] ∇θlogP(τ(i);θ)=∇θlog[∏t=0HP(st+1(i)∣st(i),ut(i))⋅πθ(ut(i)∣st(i))]
= ∇ θ [ ∑ t = 0 H log P ( s t + 1 ( i ) ∣ s t ( i ) , u t ( i ) ) + ∑ t = 0 H log π θ ( u t ( i ) ∣ s t ( i ) ) ] =\nabla_{\theta}\left[\sum_{t=0}^{H} \log P\left(s_{t+1}^{(i)} | s_{t}^{(i)}, u_{t}^{(i)}\right)+\sum_{t=0}^{H} \log \pi_{\theta}\left(u_{t}^{(i)} | s_{t}^{(i)}\right)\right] =∇θ[∑t=0HlogP(st+1(i)∣st(i),ut(i))+∑t=0Hlogπθ(ut(i)∣st(i))]
= ∇ θ [ ∑ t = 0 H log π θ ( u t ( i ) ∣ s t ( i ) ) ] =\nabla_{\theta}\left[\sum_{t=0}^{H} \log \pi_{\theta}\left(u_{t}^{(i)} | s_{t}^{(i)}\right)\right] =∇θ[∑t=0Hlogπθ(ut(i)∣st(i))]
= ∑ t = 0 H ∇ θ log π θ ( u t ( i ) ∣ s t ( i ) ) =\sum_{t=0}^{H} \nabla_{\theta} \log \pi_{\theta}\left(u_{t}^{(i)} | s_{t}^{(i)}\right) =∑t=0H∇θlogπθ(ut(i)∣st(i))
从上式的结果来看,似然率梯度转化为动作策略的梯度,与动力学无关。
由此,推导出了策略梯度的计算公式:
∇ θ U ( θ ) ≈ g ^ = 1 m ∑ i = 1 m ( ∑ t = 0 H ∇ θ log π θ ( u t ( i ) ∣ s t ( i ) ) R ( τ ( i ) ) ) \nabla_{\theta}U\left(\theta\right)\approx\hat{g}=\frac{1}{m}\sum_{i=1}^m{\left(\sum_{t=0}^H{\nabla_{\theta}\log\pi_{\theta}\left(u_{t}^{\left(i\right)}|s_{t}^{\left(i\right)}\right)}R\left(\tau^{\left(i\right)}\right)\right)} ∇θU(θ)≈g^=m1∑i=1m(∑t=0H∇θlogπθ(ut(i)∣st(i))R(τ(i)))
上式给出的策略梯度是无偏的,但是方差很大。
Tip(1) 添加基线
我们在回报中引入常数基线(baseline)b来减小方差。引入基线后,策略梯度公式变为:
∇ θ U ( θ ) ≈ 1 m ∑ i = 1 m ( ∑ t = 0 H ∇ θ log π θ ( u t ( i ) ∣ s t ( i ) ) ( R ( τ ( i ) ) − b ) ) \nabla_{\theta}U\left(\theta\right)\approx\frac{1}{m}\sum_{i=1}^m{\left(\sum_{t=0}^H{\nabla_{\theta}\log\pi_{\theta}\left(u_{t}^{\left(i\right)}|s_{t}^{\left(i\right)}\right)}\left(R\left(\tau^{\left(i\right)}\right)-b\right)\right)} ∇θU(θ)≈m1∑i=1m(∑t=0H∇θlogπθ(ut(i)∣st(i))(R(τ(i))−b))
对基线的理解:
我们在训练时,总是希望当reward为正时,增大采取该行动的概率;当reward为负时,减小采取该行动的概率。在实际环境里(如游戏),有时reward总为正,在理想情况下(每个行动都会被采样到)是可以的。但训练过程中采样是随机的,可能会出现某个较好行动不被采样的情况,这会导致采取该行动的概率下降,而较差行动的概率相对上升。因此需要引入一个基线 b 。
Tip(2) 进一步考虑各个时间点的累积收益计算方式
考虑到在时间t采取的行动action与t时期之前的收益reward无关,因此只需要将t时刻开始到结束的reward进行加总。并且,由于行动action对随后各时间点的reward的影响会随着时间的推移而减小,因此加入折旧因子 γ \gamma γ 。
R ( τ ( i ) ) R\left(\tau^{\left(i\right)}\right) R(τ(i)) → \rightarrow → ∑ t ′ = t H r t ′ \sum_{t^{\prime}=t}^{H} r_{t^{\prime}}^{} ∑t′=tHrt′ → \rightarrow → ∑ t ′ = t H γ t ′ − t r t ′ \sum_{t^{\prime}=t}^{H} \gamma^{t^{\prime}-t} r_{t^{\prime}}^{} ∑t′=tHγt′−trt′ ( γ < 1 \gamma<1 γ<1)
策略梯度公式变为:
∇ θ U ( θ ) ≈ 1 m ∑ i = 1 m ( ∑ t = 0 H ∇ θ log π θ ( u t ( i ) ∣ s t ( i ) ) ( ∑ t ′ = t H γ t ′ − t r t ′ − b ) ) \nabla_{\theta}U\left(\theta\right)\approx\frac{1}{m}\sum_{i=1}^m{\left(\sum_{t=0}^H{\nabla_{\theta}\log\pi_{\theta}\left(u_{t}^{\left(i\right)}|s_{t}^{\left(i\right)}\right)}\left(\sum_{t^{\prime}=t}^{H} \gamma^{t^{\prime}-t} r_{t^{\prime}}^{}-b\right)\right)} ∇θU(θ)≈m1∑i=1m(∑t=0H∇θlogπθ(ut(i)∣st(i))(∑t′=tHγt′−trt′−b))
参考文献:
[1]https://zhuanlan.zhihu.com/p/26174099
[2]https://blog.csdn.net/cindy_1102/article/details/87905272#Policy_Gradient_9