深度强化学习(王树森)笔记07
深度强化学习(DRL)
本文是学习笔记,如有侵权,请联系删除。本文在ChatGPT辅助下完成。
参考链接
Deep Reinforcement Learning官方链接:https://github.com/wangshusen/DRL
源代码链接:https://github.com/DeepRLChinese/DeepRL-Chinese
B站视频:【王树森】深度强化学习(DRL)
豆瓣: 深度强化学习
文章目录
- 深度强化学习(DRL)
-
- Random Permutation(随机排列)
- Q学习算法
- 同策略 (On-policy) 与异策略 (Off-policy)
- SARSA 算法
-
- 表格形式的 SARSA
- 神经网络形式的 SARSA
- 多步 TD 目标
- 蒙特卡洛与自举
- 后记
Random Permutation(随机排列)
What is uniform random permutation?
排列数等于n!

“uniform random permutation”(均匀随机排列)是指生成一个排列,其中每个可能的排列都以相等的概率出现。具体来说,对于含有n个元素的集合,它的所有n!个排列中的每一个都有相同的概率被选中。
实现均匀随机排列的一种简单方法是 Fisher-Yates 洗牌算法。该算法基于迭代,从最后一个元素开始,每次随机选择当前位置及之前的一个位置,并将它们的元素交换。通过不断重复这个过程,最终得到一个均匀随机排列。
这种排列方法在各种应用中都很有用,例如在随机化算法、模拟实验和密码学中。在实际应用中,均匀随机排列通常要求具有良好的随机性质,以确保生成的排列满足统计学上的随机性要求。

Fisher-Yates Shuffle
Fisher-Yates Shuffle,又称为洗牌算法,是一种用于随机排列数组元素的有效且简单的算法。其目标是生成一个均匀随机的排列,即每个元素在排列中出现的概率相等。下面是Fisher-Yates Shuffle的详细步骤:
-
初始化: 算法开始时,数组中的元素按照其原始顺序排列。
-
迭代: 从数组的最后一个元素开始,依次向前迭代到第一个元素。
-
随机选择: 对于当前迭代的位置(假设为i),生成一个[0, i]范围内的随机整数 j。
-
交换元素: 将当前位置(i)的元素与随机选择位置(j)的元素进行交换。
-
递减迭代: 继续迭代,减小当前位置,直到第一个元素。
通过这个过程,每个元素都有机会被选择到任何一个位置,而且每个位置被选择的概率是相等的。因此,经过足够的迭代次数后,数组中的元素将被洗牌成一个均匀随机的排列。
Fisher-Yates Shuffle是一种简单而强大的洗牌算法,广泛应用于计算机科学领域,尤其在实现随机算法、模拟实验和游戏开发等方面。
以下是使用Python实现Fisher-Yates Shuffle的简单代码:
import random
def fisher_yates_shuffle(arr):
# 从最后一个元素开始迭代
for i in range(len(arr) - 1, 0, -1):
# 生成随机索引,范围是 [0, i]
j = random.randint(0, i)
# 交换当前位置的元素与随机选择位置的元素
arr[i], arr[j] = arr[j], arr[i]
# 示例用法
my_array = [1, 2, 3, 4, 5]
fisher_yates_shuffle(my_array)
print(my_array)
这段代码使用了Python的random模块中的randint函数来生成随机整数。通过调用fisher_yates_shuffle函数,可以对任意数组进行Fisher-Yates Shuffle。在示例用法中,数组 [1, 2, 3, 4, 5] 被洗牌,打印结果可能是类似 [3, 5, 1, 4, 2] 的随机排列。
range(len(arr) - 1, 0, -1) 是一个用于生成迭代索引的 Python 内置函数 range 的调用。具体来说,这个函数的参数是起始值、结束值和步长。
len(arr) - 1: 这是起始值,表示从数组的最后一个元素开始。0: 这是结束值(不包含在范围内),表示索引递减至 0。-1: 这是步长,表示递减的步长为 1。
因此,range(len(arr) - 1, 0, -1) 生成了一个逆序的索引序列,从数组的最后一个元素开始递减到第一个元素。这个逆序的索引序列用于在 Fisher-Yates Shuffle 算法中迭代数组的位置。在每次迭代中,会随机选择一个之前的位置,并与当前位置的元素交换,从而完成洗牌的过程。
Fisher-Yates Shuffle 的时间复杂度是 O(n),其中 n 是数组的长度。这是因为算法需要对数组中的每个元素进行一次迭代,并在每次迭代中进行一次交换。
Q学习算法
Q \mathbb{Q} Q学习算法上一节用 TD 算法训练 DQN(介绍DQN的笔记在这里:深度强化学习(王树森)笔记02), 更准确地说,我们用的 TD 算法叫做 Q 学习算法 (Q- learning)。TD 算法是一大类算法,常见的有 Q 学习和 SARSA。Q 学习的目的是学到最优动作价值函数 Q ⋆ Q_\star Q⋆,而 SARSA 的目的是学习动作价值函数 Q π Q_\mathrm{\pi} Qπ。下一章会介绍 SARSA 算法。
Q 学习是在 1989 年提出的,而 DQN 则是 2013 年才提出。从 DQN 的名字 (深度 Q 网络)就能看出 DQN 与 Q 学习的联系。最初的 Q 学习都是以表格形式出现的。虽然表格形式的 Q 学习在实践中不常用,但还是建议读者有所了解。
用表格表示 Q ⋆ : Q_{\star}: Q⋆:
假设状态空间 S S S 和动作空间 A \mathcal{A} A 都是有限集,即集合中元素数量有限。 比如, S \mathcal{S} S中一共有3 种状态, A \mathcal{A} A中一共有 4 种动作。那么最优动作价值函数 Q ⋆ ( s , a ) Q_\star(s,a) Q⋆(s,a) 可以表示为一个 3 × 4 3\times4 3×4 的表格,比如右边的表格。基于当前状态 s t s_t st,做决策时使用的公式
a t = a r g m a x a ∈ A Q ⋆ ( s t , a ) a_{t}\:=\:\mathop{\mathrm{argmax}}_{a\in\mathcal{A}}Q_{\star}(s_{t},a) at=argmaxa∈AQ⋆(st,a)
的意思是找到 s t s_t st 对应的行(3 行中的某一行),找到该行最大的价值,返回该元素对应的动作。举个例子,当前状态 s t s_t st 是第 2 种状态,那么我们查看第 2 行,发现该行最大的价值是 210, 对应第 4 种动作。那么应当执行的动作 a t a_t at 就是第 4 种动作。
该如何通过智能体的轨迹来学习这样一个表格呢?答案是用一个表格 Q ~ \tilde{Q} Q~ 来近似 Q ⋆ Q_{\star} Q⋆。
首先初始化 Q ~ \tilde{Q} Q~,可以让它是全零的表格。然后用表格形式的 Q \mathbb{Q} Q学习算法更新 Q ~ \tilde{Q} Q~,每次更新表格的一个元素。最终 Q ~ \tilde{Q} Q~ 会收敛到 Q ⋆ Q^\star Q⋆。

算法推导:
首先复习一下最优贝尔曼方程:
Q ⋆ ( s t , a t ) = E S t + 1 ∼ p ( ⋅ ∣ s t , a t ) [ R t + γ ⋅ max A ∈ A Q ⋆ ( S t + 1 , A ) ∣ S t = s t , A t = a t ] . Q_\star(s_t,a_t)\:=\:\mathbb{E}_{S_{t+1}\sim p(\cdot|s_t,a_t)}\Big[R_t+\gamma\cdot\max_{A\in\mathcal{A}}Q_\star(S_{t+1},A)\:\Big|\:S_t=s_t,A_t=a_t\Big]. Q⋆(st,at)=ESt+1∼p(⋅∣st,at)[Rt+γ⋅A∈AmaxQ⋆(St+1,A) St=st,At=at].
我们对方程左右两边做近似:
-方程左边的 Q ⋆ ( s t , a t ) Q_\star(s_t,a_t) Q⋆(st,at) 可以近似成 Q ~ ( s t , a t ) \tilde{Q}(s_t,a_t) Q~(st,at)。 Q ~ ( s t , a t ) \tilde{Q}(s_t,a_t) Q~(st,at) 是表格在 t t t 时刻对 Q ⋆ ( s t , a ι ) Q_\star(s_t,a_\iota) Q⋆(st,aι) 做出的估计。
-方程右边的期望是关于下一时刻状态 S t + 1 S_{t+1} St+1求的。给定当前状态 s t s_t st, 智能体执行动作 a t a_t at,环境会给出奖励 r t r_t rt 和新的状态 s t + 1 s_{t+1} st+1。用观测到的 r t r_t rt 和 s t + 1 s_{t+1} st+1 对期望做蒙特卡洛近似,得到:
r t + γ ⋅ max a ∈ A Q ⋆ ( s t + 1 , a ) . ( 4.4 ) r_{t}+\gamma\cdot\max_{a\in{\mathcal A}}Q_{\star}\big(s_{t+1},a\big). \quad{(4.4)} rt+γ⋅a∈AmaxQ⋆(st+1,a).(4.4)
-进一步把公式 (4.4) 中的 Q ⋆ Q_{\star} Q⋆ 近似成 Q ~ \widetilde{Q} Q , 得到
y ^ t ≜ r t + γ ⋅ max a ∈ A Q ~ ( s t + 1 , a ) . \widehat{y}_{t}\triangleq r_{t}+\gamma\cdot\max_{a\in\mathcal{A}}\widetilde{Q}\big(s_{t+1},a\big). y t≜rt+γ⋅a∈AmaxQ (st+1,a).
把它称作 TD 目标。它是表格在 t + 1 t+1 t+1 时刻对 Q ⋆ ( s t , a t ) Q_\star(s_t,a_t) Q⋆(st,at) 做出的估计。
Q ~ ( s t , a t ) \widetilde{Q}(s_t,a_t) Q (st,at) 和 y ^ t \widehat{y}_t y t 都是对最优动作价值 Q ⋆ ( s t , a t ) Q_\star(s_t,a_t) Q⋆(st,at) 的估计。由于 y ^ t \widehat{y}_t y t 部分基于真实观测到的奖励 r t r_t rt,我们认为 y ^ t \widehat{y}_t y t 是更可靠的估计,所以鼓励 Q ~ ( s t , a t ) \tilde{Q}(s_t,a_t) Q~(st,at) 更接近 y ^ t \widehat{y}_t y t。更新表格 Q ~ \tilde{Q} Q~中 ( s t , a t ) (s_t,a_t) (st,at) 位置上的元素:
Q ~ ( s t , a t ) ← ( 1 − α ) ⋅ Q ~ ( s t , a t ) + α ⋅ y ^ t . \tilde{Q}(s_{t},a_{t})\leftarrow(1-\alpha)\cdot\tilde{Q}(s_{t},a_{t})+\alpha\cdot\widehat{y}_{t}. Q~(st,at)←(1−α)⋅Q~(st,at)+α⋅y t.
这样可以使得 Q ~ ( s t , a t ) \tilde{Q}(s_t,a_t) Q~(st,at) 更接近 y ^ t \widehat{y}_t y t。Q 学习的目的是让 Q ~ \tilde{Q} Q~ 逐渐趋近于 Q ⋆ Q_{\star} Q⋆。
收集训练数据:
Q \mathbb{Q} Q学习更新 Q ~ \tilde{Q} Q~ 的公式不依赖于具体的策略。我们可以用任意策略控
制智能体,与环境交互,把得到的轨迹划分成 ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1) 这样的四元组,存入经验回放数组。这个控制智能体的策略叫做行为策略(behavior policy), 比较常用的行为策略是 ϵ \epsilon ϵ-greedy:
a t = { argmax a Q ~ ( s t , a ) , 以概率 ( 1 − ϵ ) ; 均匀抽取 A 中的一个动作 , 以概率 ϵ . \left.a_t\:=\:\left\{\begin{array}{ll}\operatorname{argmax}_a\widetilde{Q}(s_t,a),&\text{以概率}\:(1-\epsilon);\\\\\text{均匀抽取}\:\mathcal{A}\:\text{中的一个动作},&\text{以概率}\:\epsilon.\end{array}\right.\right. at=⎩ ⎨ ⎧argmaxaQ (st,a),均匀抽取A中的一个动作,以概率(1−ϵ);以概率ϵ.
事后用经验回放更新表格 Q ~ \tilde{Q} Q~,可以重复利用收集到的四元组。
经验回放更新表格 Q ~ : \widetilde{Q}: Q :
随机从经验回放数组中抽取一个四元组,记作 ( s j , a j , r j , s j + 1 ) (s_j,a_j,r_j,s_{j+1}) (sj,aj,rj,sj+1)。
设当前表格为 Q ~ n o w \tilde{Q}_\mathrm{now} Q~now。更新表格中 ( s j , a j ) (s_j,a_j) (sj,aj)位置上的元素,把更新之后的表格记作 Q ~ n e w \tilde{Q}_\mathrm{new} Q~new。
- 把表格 Q ~ n o w \tilde{Q}_\mathrm{now} Q~now 中第 ( s j , a j ) (s_j,a_j) (sj,aj) 位置上的元素记作:
q ^ j = Q ~ n o w ( s j , a j ) . \widehat q_{j}\:=\:\widetilde Q_{\mathrm{now}}(s_{j},a_{j}). q j=Q now(sj,aj).
- 查看表格 Q ~ n o w \tilde{Q}_\mathrm{now} Q~now 的第 s j + 1 s_{j+1} sj+1 行,把该行的最大值记作:
q ^ j + 1 = max a Q ~ n o w ( s j + 1 , a ) . \widehat q_{j+1}\:=\:\max_{a}\:\widetilde Q_{\mathrm{now}}\left(s_{j+1},a\right). q j+1=amaxQ now(sj+1,a).
- 计算 TD 目标和 TD 误差:
y ^ j = r j + γ ⋅ q ^ j + 1 , δ j = q ^ j − y ^ j . \widehat y_{j}\:=\:r_{j}+\gamma\cdot\widehat q_{j+1},\quad\delta_{j}\:=\:\widehat q_{j}-\widehat y_{j}. y j=rj+γ⋅q j+1,δj=q j−y j.
- 更新表格中 ( s j , a j ) (s_j,a_j) (sj,aj) 位置上的元素:
Q ~ n e w ( s j , a j ) ← Q ~ n o w ( s j , a j ) − α ⋅ δ j . \tilde{Q}_{\mathrm{new}}(s_{j},a_{j})\:\leftarrow\:\tilde{Q}_{\mathrm{now}}\big(s_{j},a_{j}\big)\:-\:\alpha\cdot\delta_{j}. Q~new(sj,aj)←Q~now(sj,aj)−α⋅δj.
收集经验与更新表格 Q ~ \tilde{Q} Q~可以同时进行。每当智能体执行一次动作,我们可以用经验回放对 Q ~ \tilde{Q} Q~做几次更新。也可以每当完成一局游戏,对 Q ~ \tilde{Q} Q~做几次更新。
同策略 (On-policy) 与异策略 (Off-policy)
在强化学习中经常会遇到两个专业术语:同策略(on-policy) 和异策略 (off-policy)。
为了解释同策略和异策略,我们要从行为策略 (behavior policy) 和目标策略 (target policy) 讲起。
在强化学习中,我们让智能体与环境交互,记录下观测到的状态、动作、奖励,用这些经验来学习一个策略函数。在这一过程中,控制智能体与环境交互的策略被称作行为策略。行为策略的作用是收集经验(experience),即观测的状态、动作、奖励。
强化学习的目的是得到一个策略函数,用这个策略函数来控制智能体。这个策略函数就叫做目标策略。在本章中,目标策略是一个确定性的策略,即用 DQN 控制智能体:
a t = argmax a Q ( s t , a ; w ) . a_{t}\:=\:\underset{a}{\operatorname*{argmax}}\:Q\big(s_{t},a;\:\boldsymbol{w}\big). at=aargmaxQ(st,a;w).
本章的 Q 学习算法用任意的行为策略收集 ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1) 这样的四元组,然后拿它们训练目标策略,即 DQN。介绍DQN的笔记在这里:深度强化学习(王树森)笔记02
行为策略和目标策略可以相同,也可以不同。同策略是指用相同的行为策略和目标策略,后面章节会介绍同策略。异策略是指用不同的行为策略和目标策略,本章的 DQN 属于异策略。同策略和异策略如图 4.6、4.7 所示。

由于DQN 是异策略,行为策略可以不同于目标策略,可以用任意的行为策略收集经验,比如最常用的行为策略是 ϵ \epsilon ϵ-greedy:
a t = { argmax a Q ( s t , a ; w ) , 以概率 ( 1 − ϵ ) ; 均匀抽取 A 中的一个动作 , 以概率 ϵ . \left.a_t\:=\:\left\{\begin{array}{ll}\operatorname{argmax}_aQ(s_t,a;\boldsymbol{w}),&\quad\text{以概率 }(1-\epsilon);\\\text{均匀抽取 }\mathcal{A}\:\text{中的一个动作},&\quad\text{以概率 }\epsilon.\end{array}\right.\right. at={argmaxaQ(st,a;w),均匀抽取 A中的一个动作,以概率 (1−ϵ);以概率 ϵ.
让行为策略带有随机性的好处在于能探索更多没见过的状态。在实验中,初始的时候让 ϵ \epsilon ϵ 比较大 (比如 ϵ = 0.5 ) \epsilon=0.5) ϵ=0.5); 在训练的过程中,让 ϵ \epsilon ϵ逐渐衰减,在几十万步之后衰减到较小的值(比如 ϵ = 0.01 ) \epsilon=0.01) ϵ=0.01), 此后固定住 ϵ = 0.01 \epsilon=0.01 ϵ=0.01 。
异策略的好处是可以用行为策略收集经验,把 ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1) 这样的四元组记录到一个数组里,在事后反复利用这些经验去更新目标策略。这个数组被称作经验回放数组(replay buffer), 这种训练方式被称作经验回放 (experience replay)。注意,经验回放只适用于异策略,不适用于同策略,其原因是收集经验时用的行为策略不同于想要训练出的目标策略。
总结
DQN 是对最优动作价值函数 Q ⋆ Q_{\star} Q⋆的近似。DQN 的输入是当前状态 s t s_t st, 输出是每个动作的 Q 值。DQN 要求动作空间 A A A 是离散集合,集合中的元素数量有限。如果动作空间 A A A的大小是 k k k,那么 DQN 的输出就是 k k k 维向量。DQN 可以用于做决策,智能体执行 Q 值最大的动作。
TD 算法的目的在于让预测更接近实际观测。以驾车问题为例,如果使用 TD 算法,无需完成整个旅途就能做梯度下降更新模型。请读者理解并记忆 TD 目标、TD 误差的定义,它们将出现在所有价值学习的章节中。
Q 学习算法是 TD 算法的一种,可以用于训练 DQN。Q 学习算法由最优贝尔曼方程推导出。Q 学习算法属于异策略,允许使用经验回放。由任意行为策略收集经验, 存入经验回放数组。事后做经验回放,用 TD 算法更新 DQN 参数。
如果状态空间 S S S、动作空间 A A A 都是较小的有限离散集合,那么可以用表格形式的Q学习算法学习 Q ⋆ Q_{\star} Q⋆。如今表格形式的 Q 学习已经不常用。
SARSA 算法
TD 算法是一大类算法的总称。Q 学习是一种 TD 算法,Q 学习的目的是学习最优动作价值函数 Q ⋆ Q_{\star} Q⋆。这里介绍 SARSA, 它也是一种 TD 算法,SARSA 的目的是学习动作价值函数 Q π ( s , a ) s Q_\pi(s,a)_s Qπ(s,a)s
表格形式的 SARSA
假设状态空间 S S S 和动作空间 A \mathcal{A} A 都是有限集,即集合中元素数量有限。比如, S S S 中一共有 3 种状态, A \mathcal{A} A 中一共有 4 种动作。那么动作价值函数 Q π ( s , a ) Q_\pi(s,a) Qπ(s,a) 可以表示为一个 3 × 4 3\times4 3×4 的表格,比如右边的表格。该表格与一个策略函数 π ( a ∣ s ) \pi(a|s) π(a∣s) 相关联;如果 π 发生变化, 表格 Q π Q_{\pi} Qπ 也会发生变化。
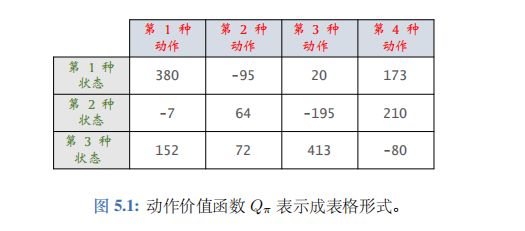
我们用表格 q q q 近似 Q π Q_\pi Qπ。该如何通过智能体与环境的交互来学习表格 q q q呢?首先初始化 q q q,可以让它是全零的表格。然后用表格形式的 SARSA 算法更新 q q q, 每次更新表格的一个元素。最终 q q q 收敛到 Q π Q_\mathrm{\pi} Qπ。
推导表格形式的 SARSA 学习算法 :
SARSA 算法由下面的贝尔曼方程推导出:
Q π ( s t , a t ) = E S t + 1 , A t + 1 [ R t + γ ⋅ Q π ( S t + 1 , A t + 1 ) ∣ S t = s t , A t = a t ] Q_{\pi}\big(s_{t},a_{t}\big)\:=\:\mathbb{E}_{S_{t+1},A_{t+1}}\big[R_{t}+\gamma\cdot Q_{\pi}\big(S_{t+1},A_{t+1}\big)\:\big|\:S_{t}=s_{t},A_{t}=a_{t}\big] Qπ(st,at)=ESt+1,At+1[Rt+γ⋅Qπ(St+1,At+1) St=st,At=at]
我们对贝尔曼方程左右两边做近似:
-方程左边的 Q π ( s t , a t ) Q_\pi(s_t,a_t) Qπ(st,at) 可以近似成 q ( s t , a t ) q(s_t,a_t) q(st,at)。 q ( s t , a t ) q(s_t,a_t) q(st,at) 是表格在 t t t 时刻对 Q π ( s t , a t ) Q_\pi(s_t,a_t) Qπ(st,at) 做出的估计。
-方程右边的期望是关于下一时刻状态 S t + 1 S_{t+1} St+1 和动作 A t + 1 A_{t+1} At+1 求的。给定当前状态 s t s_t st, 智能体执行动作 a t a_t at,环境会给出奖励 r t r_t rt 和新的状态 s t + 1 s_{t+1} st+1。然后基于 s t + 1 s_{t+1} st+1做随机抽样, 得到新的动作
a ~ t + 1 ∼ π ( ⋅ ∣ s t + 1 ) . \tilde{a}_{t+1}\:\sim\:\pi\big(\:\cdot\:\big|\:s_{t+1}\big). a~t+1∼π(⋅ st+1).
用观测到的 r t r_t rt、 s t + 1 s_{t+1} st+1 和计算出的 a ~ t + 1 \tilde{a}_{t+1} a~t+1 对期望做蒙特卡洛近似,得到:
r t + γ ⋅ Q π ( s t + 1 , a ~ t + 1 ) . ( 5.1 ) r_{t}+\gamma\cdot Q_{\pi}(s_{t+1},\tilde{a}_{t+1}).\quad{(5.1)} rt+γ⋅Qπ(st+1,a~t+1).(5.1)
-进一步把公式 (5.1) 中的 Q π Q_{\pi} Qπ 近似成 q q q, 得到
y ^ t ≜ r t + γ ⋅ q ( s t + 1 , a ~ t + 1 ) . \widehat y_{t}\triangleq r_{t}+\gamma\cdot q\big(s_{t+1},\tilde{a}_{t+1}\big). y t≜rt+γ⋅q(st+1,a~t+1).
把它称作 TD 目标。它是表格在 t + 1 t+1 t+1 时刻对 Q π ( s t , a t ) Q_\pi(s_t,a_t) Qπ(st,at) 做出的估计。
q ( s t , a t ) q(s_t,a_t) q(st,at) 和 y ^ t \widehat{y}_t y t 都是对动作价值 Q π ( s t , a t ) Q_\pi(s_t,a_t) Qπ(st,at) 的估计。
由于 y ^ t \widehat{y}_t y t 部分基于真实观测到的奖励 r t r_t rt , 我们认为 y ^ t \widehat{y}_t y t 是更可靠的估计,所以鼓励 q ( s t , a t ) q(s_t,a_t) q(st,at) 趋近 y ^ t \widehat{y}_t y t。更新表格 ( s t , a t ) (s_t,a_t) (st,at) 位置上的元素:
q ( s t , a t ) ← ( 1 − α ) ⋅ q ( s t , a t ) + α ⋅ y ^ t . q(s_t,a_t)\leftarrow(1-\alpha)\cdot q(s_t,a_t)+\alpha\cdot\widehat{y}_t. q(st,at)←(1−α)⋅q(st,at)+α⋅y t.
这样可以使得 q ( s t , a t ) q(s_t,a_t) q(st,at) 更接近 y ^ t \widehat{y}_t y t。
SARSA 是 State-Action-Reward-State-Action 的缩写,原因是 SARSA 算法用到了这个五元组 : ( s t , a t , r t , s t + 1 , a ~ t + 1 ) :(s_t,a_t,r_t,s_{t+1},\tilde{a}_{t+1}) :(st,at,rt,st+1,a~t+1)。SARSA 算法学到的 q q q 依赖于策略 π, 这是因为五元组中的 a ~ t + 1 \tilde{a}_{t+1} a~t+1 是根据 π ( ⋅ ∣ s t + 1 ) \pi(\cdot|s_{t+1}) π(⋅∣st+1) 抽样得到的。
训练流程:
设当前表格为 q n o w q_\mathrm{now} qnow, 当前策略为 π n o w \pi_\mathrm{now} πnow。每一轮更新表格中的一个元素, 把更新之后的表格记作 q n e w q_\mathrm{new} qnew。
- 观测到当前状态 s t s_t st,根据当前策略做抽样 : a t ∼ π n o w ( ⋅ ∣ s t ) :a_t\sim\pi_{\mathrm{now}}(\cdot|s_t) :at∼πnow(⋅∣st)。
- 把表格 q n o w q_\mathrm{now} qnow 中第 ( s t , a t ) (s_t,a_t) (st,at) 位置上的元素记作:
q ^ t = q m o w ( s t , a t ) . \widehat q_{t}\:=\:q_{\mathrm{mow}}(s_{t},a_{t})\:. q t=qmow(st,at).
-
智能体执行动作 a t a_t at之后,观测到奖励 r t r_t rt 和新的状态 s t + 1 s_{t+1} st+1。
-
根据当前策略做抽样 : a ~ t + 1 ∼ π n o w ( ⋅ ∣ s t + 1 ) :\tilde{a}_{t+1}\sim\pi_{\mathrm{now}}(\cdot|s_{t+1}) :a~t+1∼πnow(⋅∣st+1)。注意, a ~ t + 1 \tilde{a}_{t+1} a~t+1 只是假想的动作,智能体不予执行。
-
把表格 q n o w q_\mathrm{now} qnow 中第 ( s t + 1 , a ~ t + 1 ) (s_{t+1},\tilde{a}_{t+1}) (st+1,a~t+1) 位置上的元素记作:
q ^ t + 1 = q n o w ( s t + 1 , a ~ t + 1 ) . \widehat q_{t+1}\:=\:q_{\mathrm{now}}\left(s_{t+1},\tilde{a}_{t+1}\right). q t+1=qnow(st+1,a~t+1).
- 计算 TD 目标和 TD 误差:
y ^ t = r t + γ ⋅ q ^ t + 1 , δ t = q ^ t − y ^ t . \widehat y_{t}\:=\:r_{t}+\gamma\cdot\widehat q_{t+1},\quad\delta_{t}\:=\:\widehat q_{t}-\widehat y_{t}. y t=rt+γ⋅q t+1,δt=q t−y t.
- 更新表格中 ( s t , a t ) (s_t,a_t) (st,at) 位置上的元素:
q n e w ( s t , a t ) ← q n o w ( s t , a t ) − α ⋅ δ t . q_{\mathrm{new}}\big(s_{t},a_{t}\big)\:\leftarrow\:q_{\mathrm{now}}\big(s_{t},a_{t}\big)\:-\:\alpha\cdot\delta_{t}. qnew(st,at)←qnow(st,at)−α⋅δt.
- 用某种算法更新策略函数。该算法与 SARSA 算法无关。
Q 学习与 SARSA 的对比:
Q \mathbb{Q} Q 学习不依赖于 π, 因此 Q \mathbb{Q} Q 学习属于异策略 (off-policy), 可以用经验回放。而 SARSA 依赖于 π, 因此 SARSA 属于同策略(on-policy), 不能用经验回放。两种算法的对比如图 5.2 所示。
Q 学习的目标是学到表格 Q ~ \tilde{Q} Q~, 作为最优动作价值函数 Q ⋆ Q_{\star} Q⋆ 的近似。因为 Q ⋆ Q_{\star} Q⋆ 与 π \pi π 无关,所以在理想情况下,不论收集经验用的行为策略 π \pi π 是什么,都不影响 Q 学习得到的最优动作价值函数。因此, Q \mathbb{Q} Q学习属于异策略(off-policy),允许行为策略区别于目标策略。Q 学习允许使用经验回放,可以重复利用过时的经验。
SARSA 算法的目标是学到表格 q q q,作为动作价值函数 Q π Q_\mathrm{\pi} Qπ 的近似。 Q π Q_\mathrm{\pi} Qπ 与一个策略 π \pi π相对应,用不同的策略 π \pi π, 对应 Q π Q_\mathrm{\pi} Qπ 就会不同。策略 π \pi π 越好, Q π Q_\mathrm{\pi} Qπ 的值越大。经验回放数组里的经验 ( s j , a j , r j , s j + 1 ) (s_j,a_j,r_j,s_{j+1}) (sj,aj,rj,sj+1) 是过时的行为策略 π o l d \pi_\mathrm{old} πold 收集到的,与当前策略 π n o w \pi_\mathrm{now} πnow 应的价值 Q π n o w Q_\mathrm{\pi_\mathrm{now}} Qπnow 对应不上。想要学习 Q π Q_\mathrm{\pi} Qπ的话,必须要用与当前策略 π n o w \pi_\mathrm{now} πnow 收集到的经验,而不能用过时的 π o l d \pi_\mathrm{old} πold收集到的经验。这就是为什么 SARSA 不能用经验回放的原因。

神经网络形式的 SARSA
价值网络:
如果状态空间 S S S 是无限集,那么我们无法用一张表格表示 Q π Q_\mathrm{\pi} Qπ, 否则表格的行数是无穷。一种可行的方案是用一个神经网络 q ( s , a ; w ) q(s,a;\boldsymbol{w}) q(s,a;w) 来近似 Q π ( s , a ) Q_\pi(s,a) Qπ(s,a); 理想情况下,
q ( s , a ; w ) = Q π ( s , a ) , ∀ s ∈ S , a ∈ A . q(s,a;\boldsymbol{w})\:=\:Q_{\pi}(s,a),\quad\forall s\in\mathcal{S},\:a\in\mathcal{A}. q(s,a;w)=Qπ(s,a),∀s∈S,a∈A.
神经网络 q ( s , a ; w ) q(s,a;\boldsymbol{w}) q(s,a;w) 被称为价值网络 (value network), 其中的 w w w 表示神经网络中可训练的参数。神经网络的结构是人预先设定的 (比如有多少层,每一层的宽度是多少),而参数 w w w 需要通过智能体与环境的交互来学习。首先随机初始化 w w w,然后用 SARSA 算法更新 w w w。
神经网络的结构见图 5.3。价值网络的输入是状态 s s s。如果 s s s 是矩阵或张量 (tensor), 那么可以用卷积网络处理 s s s (如图 5.3)。如果 s s s 是向量,那么可以用全连接层处理 s s s。价值网络的输出是每个动作的价值。动作空间 A A A 中有多少种动作,则价值网络的输出就是多少维的向量,向量每个元素对应一个动作。举个例子,动作空间是 $A= { 左,右,上 左,右,上 左,右,上} , $ 价值网络的输出是
q ( s , 左; w ) = 219 , q ( s , 右; w ) = − 73 , q ( s , 上; w ) = 580. \begin{aligned}&q(s,\text{ 左; }\boldsymbol{w})&=&219,\\&q(s,\text{ 右; }\boldsymbol{w})&=&-73,\\&q(s,\text{ 上; }\boldsymbol{w})&=&580.\end{aligned} q(s, 左; w)q(s, 右; w)q(s, 上; w)===219,−73,580.

算法推导:
给定当前状态 s t s_t st, 智能体执行动作 a t a_t at, 环境会给出奖励 r t r_t rt 和新的状态 s t + 1 s_{t+1} st+1。然后基于 s t + 1 s_{t+1} st+1 做随机抽样,得到新的动作 a ~ t + 1 ∼ π ( ⋅ ∣ s t + 1 ) \tilde{a}_{t+1}\sim\pi(\cdot|s_{t+1}) a~t+1∼π(⋅∣st+1)。定义 TD 目标:
y t ^ ≜ r t + γ ⋅ q ( s t + 1 , a ~ t + 1 ; w ) . \widehat{y_{t}}\:\triangleq\:r_{t}+\gamma\cdot q(s_{t+1},\tilde{a}_{t+1};\:\boldsymbol{w}). yt ≜rt+γ⋅q(st+1,a~t+1;w).
我们鼓励 q ( s t , a t ; w ) q(s_t,a_t;\boldsymbol{w}) q(st,at;w) 接近 TD 目标 y ^ t \widehat{y}_t y t, 所以定义损失函数:
L ( w ) ≜ 1 2 [ q ( s t , a t ; w ) − y ^ t ] 2 . L(\boldsymbol{w})\:\triangleq\:\frac{1}{2}\Big[q\big(s_{t},a_{t};\boldsymbol{w}\big)\:-\widehat{y}_{t}\Big]^{2}. L(w)≜21[q(st,at;w)−y t]2.
损失函数的变量是 w w w,而 y ^ t \widehat{y}_t y t 被视为常数。(尽管 y ^ t \widehat{y}_t y t 也依赖于参数 w w w,但这一点被忽略掉。) 设 q ^ t = q ( s t , a t ; w ) \widehat{q}_t=q(s_t,a_t;\boldsymbol{w}) q t=q(st,at;w)。损失函数关于 w w w 的梯度是:
∇ w L ( w ) = ( q ^ t − y ^ t ) ⏟ TD 误差 δ t ⋅ ∇ w q ( s t , a t ; w ) . \begin{array}{rcl}\nabla_{\boldsymbol{w}}\:L(\boldsymbol{w})&=&\underbrace{\left(\widehat{q}_{t}-\widehat{y}_{t}\right)}_{\text{TD 误差 }\delta_{t}}\cdot\nabla_{\boldsymbol{w}}\:q\big(s_{t},a_{t};\:\boldsymbol{w}\big).\end{array} ∇wL(w)=TD 误差 δt (q t−y t)⋅∇wq(st,at;w).
做一次梯度下降更新 w : w: w:
w ← w − α ⋅ δ t ⋅ ∇ w q ( s t , a t ; w ) . \boldsymbol{w}\:\leftarrow\:\boldsymbol{w}\:-\:\alpha\cdot\delta_{t}\cdot\nabla_{\boldsymbol{w}}\:q(s_{t},a_{t};\:\boldsymbol{w}). w←w−α⋅δt⋅∇wq(st,at;w).
这样可以使得 q ( s t , a t ; w ) q(s_t,a_t;\boldsymbol{w}) q(st,at;w) 更接近 y ^ t \widehat{y}_t y t。此处的 α \alpha α 是学习率,需要手动调整。
训练流程:
设当前价值网络的参数为 w n o w w_\mathrm{now} wnow, 当前策略为 π n o w \pi_\mathrm{now} πnow。每一轮训练用五元组 ( s t , a t , r t , s t + 1 , a ~ t + 1 ) (s_t,a_t,r_t,s_{t+1},\tilde{a}_{t+1}) (st,at,rt,st+1,a~t+1) 对价值网络参数做一次更新。
- 观测到当前状态 s t s_t st,根据当前策略做抽样: a t ∼ π n o w ( ⋅ ∣ s t ) a_t\sim\pi_{\mathrm{now}}(\cdot|s_t) at∼πnow(⋅∣st)。
- 用价值网络计算 ( s t , a t ) (s_t,a_t) (st,at) 的价值:
q t ^ = q ( s t , a t ; w n o w ) . \widehat{q_{t}}\:=\:q(s_{t},a_{t};\:\boldsymbol{w_{\mathrm{now}}}). qt =q(st,at;wnow).
- 智能体执行动作 a t a_t at 之后,观测到奖励 r t r_t rt 和新的状态 s t + 1 s_{t+1} st+1。
4.根据当前策略做抽样 : a ~ t + 1 ∼ π n o w ( ⋅ ∣ s t + 1 ) :\tilde{a}_{t+1}\sim\pi_{\mathrm{now}}(\cdot|s_{t+1}) :a~t+1∼πnow(⋅∣st+1)。注意, a ~ t + 1 \tilde{a}_{t+1} a~t+1 只是假想的动作,智能体不予执行。 - 用价值网络计算 ( s t + 1 , a ~ t + 1 ) (s_{t+1},\tilde{a}_{t+1}) (st+1,a~t+1) 的价值:
q ^ t + 1 = q ( s t + 1 , a ~ t + 1 ; w n o w ) . \widehat q_{t+1}\:=\:q\big(s_{t+1},\tilde{a}_{t+1};\:\boldsymbol{w_{\mathrm{now}}}\big). q t+1=q(st+1,a~t+1;wnow).
- 计算 TD 目标和 TD 误差:
y ^ t = r t + γ ⋅ q ^ t + 1 , δ t = q ^ t − y ^ t . \widehat y_{t}\:=\:r_{t}+\gamma\cdot\widehat q_{t+1},\quad\delta_{t}\:=\:\widehat q_{t}-\widehat y_{t}. y t=rt+γ⋅q t+1,δt=q t−y t.
7.对价值网络 q q q 做反向传播,计算 q q q 关于 w w w 的梯度: ∇ w q ( s t , a t ; w n o w ) \nabla_{\boldsymbol{w} }q(s_t,a_t;\boldsymbol{w_\mathrm{now}}) ∇wq(st,at;wnow) 。
- 更新价值网络参数:
w n e w ← w n o w − α ⋅ δ t ⋅ ∇ w q ( s t , a t ; w n o w ) . w_{\mathrm{new}}\:\leftarrow\:w_{\mathrm{now}}\:-\:\alpha\cdot\delta_{t}\cdot\nabla_{\boldsymbol{w}}q\big(s_{t},a_{t};\:\boldsymbol{w}_{\mathrm{now}}\big). wnew←wnow−α⋅δt⋅∇wq(st,at;wnow).
- 用某种算法更新策略函数。该算法与 SARSA 算法无关。
多步 TD 目标
首先回顾一下 SARSA 算法。给定五元组 ( s t , a t , r t , s t + 1 , a t + 1 ) (s_t,a_t,r_t,s_{t+1},a_{t+1}) (st,at,rt,st+1,at+1), SARSA 计算 TD 目标:
y t ^ = r t + γ ⋅ q ( s t + 1 , a t + 1 ; w ) . \widehat{y_{t}}\:=\:r_{t}\:+\:\gamma\cdot q(s_{t+1},a_{t+1};\:\boldsymbol{w}). yt =rt+γ⋅q(st+1,at+1;w).
公式中只用到一个奖励 r t r_t rt,这样得到的 y ^ t \widehat{y}_t y t 叫做单步 TD 目标。多步 TD 目标用 m m m 个奖励可以视作单步 TD 目标的推广。下面我们推导多步 TD 目标。
数学推导:
设一局游戏的长度为 n n n。根据定义, t t t 时刻的回报 U t U_t Ut 是 t t t 时刻之后的所有奖励的加权和:
U t = R t + γ R t + 1 + γ 2 R t + 2 + ⋯ + γ n − t R n . U_{t}~=~R_{t}~+~\gamma R_{t+1}~+~\gamma^{2}R_{t+2}~+~\cdots~+~\gamma^{n-t}R_{n}. Ut = Rt + γRt+1 + γ2Rt+2 + ⋯ + γn−tRn.
同理, t + m t+m t+m 时刻的回报可以写成:
U t + m = R t + m + γ R t + m + 1 + γ 2 R t + m + 2 + ⋯ + γ n − t − m R n . U_{t+m}\:=\:R_{t+m}\:+\:\gamma R_{t+m+1}\:+\:\gamma^{2}R_{t+m+2}\:+\:\cdots\:+\:\gamma^{n-t-m}R_{n}. Ut+m=Rt+m+γRt+m+1+γ2Rt+m+2+⋯+γn−t−mRn.
下面我们推导两个回报的关系。把 U t U_t Ut 写成:
U t = ( R t + γ R t + 1 + ⋯ + γ m − 1 R t + m − 1 ) + ( γ m R t + m + ⋯ + γ n − t R n ) = ( ∑ i = 0 m − 1 γ i R t + i ) + γ m ( R t + m + γ R t + m + 1 + ⋯ + γ n − t − m R n ) ⏟ 等于 U t + m . \begin{array}{rcl}U_t&=&\left(R_t+\gamma R_{t+1}+\cdots+\gamma^{m-1}R_{t+m-1}\right)+\left(\gamma^mR_{t+m}+\cdots+\gamma^{n-t}R_n\right)\\&=&\left(\sum_{i=0}^{m-1}\gamma^iR_{t+i}\right)+\gamma^m\underbrace{\left(R_{t+m}+\gamma R_{t+m+1}+\cdots+\gamma^{n-t-m}R_n\right)}_{\text{等于}U_{t+m}}.\end{array} Ut==(Rt+γRt+1+⋯+γm−1Rt+m−1)+(γmRt+m+⋯+γn−tRn)(∑i=0m−1γiRt+i)+γm等于Ut+m (Rt+m+γRt+m+1+⋯+γn−t−mRn).
因此,回报可以写成这种形式:
U t = ( ∑ i = 0 m − 1 γ i R t + i ) + γ m U t + m . ( 5.2 ) U_{t}~=~\left(\sum_{i=0}^{m-1}\gamma^{i}R_{t+i}\right)~+~\gamma^{m}U_{t+m}. \quad{(5.2)} Ut = (i=0∑m−1γiRt+i) + γmUt+m.(5.2)
动作价值函数 Q π ( s t , a t ) Q_\pi(s_t,a_t) Qπ(st,at) 是回报 U t U_t Ut 的期望,而 Q π ( s t + m , a t + m ) Q_\pi(s_{t+m},a_{t+m}) Qπ(st+m,at+m)是回报 U t + m U_{t+m} Ut+m的期望。利用公式 (5.2), 再按照贝尔曼方程的证明 , 不难得出下面的定理:

设 R k R_{k} Rk 是 S k , A k . S_{k},\:A_{k}\:. Sk,Ak. S k + 1 S_{k+1} Sk+1 的函数, ∀ k = 1 , ⋯ , n \forall k=1,\cdots,n ∀k=1,⋯,n。那么
Q π ( s t , a t ) ⏟ U t 的期望 = E [ ( ∑ i = 0 m − 1 γ i R t + i ) + γ m ⋅ Q π ( S t + m , A t + m ) ⏟ U t + m 的期望 ∣ S t = s t , A t = a t ] . \underbrace{Q_{\pi}\left(s_{t},a_{t}\right)}_{U_{t}\text{的期望}} \quad = \mathbb{E}\Big[ \left( \sum_{i=0}^{m-1}\gamma^{i}R_{t+i}\right)+\gamma^{m}\cdot\underbrace{Q_{\pi}\left(S_{t+m},A_{t+m}\right)}_{U_{t+m}\text{的期望}} \bigg | S_{t}=s_{t},A_{t}=a_{t}\Big]. Ut的期望 Qπ(st,at)=E[(i=0∑m−1γiRt+i)+γm⋅Ut+m的期望 Qπ(St+m,At+m) St=st,At=at].
公式中的期望是关于随机变量 S t + 1 , A t + 1 , ⋯ , S t + m , A t + m S_{t+1},A_{t+1},\cdots,S_{t+m},A_{t+m} St+1,At+1,⋯,St+m,At+m求的。
注 回报 U t U_t Ut 的随机性来自于 t t t 到 n n n 时刻的状态和动作:
S t , A t , S t + 1 , A t + 1 , ⋯ , S t + m , A t + m , S t + m + 1 , A t + m + 1 , ⋯ , S n , A n . S_t,A_t,\quad S_{t+1},A_{t+1},\cdots,S_{t+m},A_{t+m},\quad S_{t+m+1},A_{t+m+1},\cdots,S_n,A_n. St,At,St+1,At+1,⋯,St+m,At+m,St+m+1,At+m+1,⋯,Sn,An.
定理中把 S t = s t S_t=s_t St=st 和 A t = a t A_t=a_t At=at看做是观测值,用期望消掉 S t + 1 , A t + 1 , ⋯ , S t + m , A t + m S_{t+1},A_{t+1},\cdots,S_{t+m},A_{t+m} St+1,At+1,⋯,St+m,At+m,而 Q π ( S t + m , A t + m ) Q_{\pi}(S_{t+m},A_{t+m}) Qπ(St+m,At+m) 则消掉了剩余的随机变量 S t + m + 1 , A t + m + 1 , ⋯ , S n , A n S_{t+m+1},A_{t+m+1},\cdots,S_n,A_n St+m+1,At+m+1,⋯,Sn,An。
多步 TD目标:
我们对定理 5.1 中的期望做蒙特卡洛近似,然后再用价值网络 q ( s , a ; w ) q(s,a;\boldsymbol{w}) q(s,a;w) 近似动作价值函数 Q π ( s , a ) Q_\pi(s,a) Qπ(s,a)。具体做法如下:
-
在 t t t 时刻,价值网络做出预测 q ^ t = q ( s t , a t ; w ) \widehat{q}_t=q(s_t,a_t;\boldsymbol{w}) q t=q(st,at;w),它是对 Q π ( s t , a t ) Q_\pi(s_t,a_t) Qπ(st,at) 的估计。
-
已知当前状态 s t s_t st,用策略 π \pi π控制智能体与环境交互 m m m 次,得到轨迹
r t , s t + 1 , a t + 1 , r t + 1 , ⋯ , s t + m − 1 , a t + m − 1 , r t + m − 1 , s t + m , a t + m . r_{t},\quad s_{t+1},a_{t+1},r_{t+1},\quad\cdots,\quad s_{t+m-1},a_{t+m-1},r_{t+m-1},\quad s_{t+m},a_{t+m}. rt,st+1,at+1,rt+1,⋯,st+m−1,at+m−1,rt+m−1,st+m,at+m.
在 t + m t+m t+m 时刻,用观测到的轨迹对定理 5.1 中的期望做蒙特卡洛近似,把近似的结果记作:
( ∑ i = 0 m − 1 γ i r t + i ) + γ m ⋅ Q π ( s t + m , a t + m ) . \left(\sum_{i=0}^{m-1}\gamma^{i}r_{t+i}\right)\:+\:\gamma^{m}\cdot Q_{\pi}\left(s_{t+m},a_{t+m}\right). (∑i=0m−1γirt+i)+γm⋅Qπ(st+m,at+m).
- 进一步用 q ( s t + m , a t + m ; w ) q(s_{t+m},a_{t+m};\boldsymbol{w}) q(st+m,at+m;w)近似 Q π ( s t + m , a t + m ) Q_\pi(s_{t+m},a_{t+m}) Qπ(st+m,at+m),得到:
y t ^ ≜ ( ∑ i = 0 m − 1 γ i r t + i ) + γ m ⋅ q ( s t + m , a t + m ; w ) . \widehat{y_t}\triangleq\left(\sum_{i=0}^{m-1}\gamma^ir_{t+i}\right)+\gamma^m\cdot q(s_{t+m},a_{t+m};\boldsymbol{w}). yt ≜(i=0∑m−1γirt+i)+γm⋅q(st+m,at+m;w).
把 y ^ t \widehat{y}_t y t 称作 m m m 步TD 目标。
q ^ t = q ( s t , a t ; w ) \widehat{q}_t=q(s_t,a_t;\boldsymbol{w}) q t=q(st,at;w) 和 y ^ t \widehat{y}_t y t 分别是价值网络在 t t t 时刻和 t + m t+m t+m 时刻做出的预测,两者都是对 Q π ( s t , a t ) Q_\pi(s_t,a_t) Qπ(st,at) 的估计值。 q ^ t \widehat{q}_t q t 是纯粹的预测,而 y ^ t \widehat{y}_t y t 则基于 m m m 组实际观测,因此 y ^ t \widehat{y}_t y t 比 q ^ t \widehat{q}_t q t 更可靠。我们鼓励 q ^ t \widehat{q}_t q t 接近 y ^ t \widehat{y}_t y t。设损失函数为
L ( w ) ≜ 1 2 [ q ( s t , a t ; w ) − y ^ t ] 2 . ( 5.3 ) L(\boldsymbol{w})\:\triangleq\:\frac{1}{2}\Big[q\big(s_{t},a_{t};\boldsymbol{w}\big)\:-\:\widehat{y}_{t}\Big]^{2}. \quad{(5.3)} L(w)≜21[q(st,at;w)−y t]2.(5.3)
做一步梯度下降更新价值网络参数 w w w:
w ← w − α ⋅ ( q ^ t − y ^ t ) ⋅ ∇ w q ( s t , a t ; w ) . \boldsymbol{w}\:\leftarrow\:\boldsymbol{w}-\alpha\cdot\left(\widehat{q}_{t}\:-\widehat{y}_{t}\right)\cdot\nabla_{\boldsymbol{w}}q(s_{t},a_{t};\boldsymbol{w}). w←w−α⋅(q t−y t)⋅∇wq(st,at;w).
训练流程:
设当前价值网络的参数为 w n o w w_\mathrm{now} wnow, 当前策略为 π n o w \pi_\mathrm{now} πnow。执行以下步骤更新价值网络和策略。
- 用策略网络 π n o w \pi_\mathrm{now} πnow 控制智能体与环境交互,完成一个回合,得到轨迹:
s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , ⋯ , s n , a n , r n . \begin{aligned}s_{1},a_{1},r_{1},\:s_{2},a_{2},r_{2},\:\cdots,\:s_{n},a_{n},r_{n}.\end{aligned} s1,a1,r1,s2,a2,r2,⋯,sn,an,rn.
- 对于所有的 t = 1 , ⋯ , n − m t=1,\cdots,n-m t=1,⋯,n−m, 计算
q ^ t = q ( s t , a t ; w n o w ) . \widehat q_{t}\:=\:q(s_{t},a_{t};\boldsymbol{w_{\mathrm{now}}}). q t=q(st,at;wnow).
3.对于所有的 t = 1 , ⋯ , n − m t=1,\cdots,n-m t=1,⋯,n−m,计算多步 TD 目标和 TD 误差:
y t ^ = ∑ i = 0 m − 1 γ i r t + i + γ m q ^ t + m , δ t = q ^ t − y ^ t . \widehat{y_{t}}\:=\:\sum_{i=0}^{m-1}\gamma^{i}r_{t+i}\:+\:\gamma^{m}\widehat{q}_{t+m},\quad\delta_{t}\:=\:\widehat{q}_{t}-\widehat{y}_{t}. yt =i=0∑m−1γirt+i+γmq t+m,δt=q t−y t.
- 对于所有的 t = 1 , ⋯ , n − m t=1,\cdots,n-m t=1,⋯,n−m, 对价值网络 q q q 做反向传播,计算 q q q 关于 w w w 的梯度:
∇ w q ( s t , a t ; w n o w ) . \nabla_{\boldsymbol{w}}q(s_{t},a_{t};\:\boldsymbol{w_{now}}). ∇wq(st,at;wnow).
- 更新价值网络参数:
w n e w ← w n o w − α ⋅ ∑ t = 1 n − m δ t ⋅ ∇ w q ( s t , a t ; w n o w ) . w_{\mathrm{new}}\:\leftarrow\:w_{\mathrm{now}}\:-\:\alpha\cdot\sum_{t=1}^{n-m}\delta_{t}\cdot\nabla_{\boldsymbol{w}}q\big(s_{t},a_{t};\:\boldsymbol{w_{\mathrm{now}}}\big). wnew←wnow−α⋅t=1∑n−mδt⋅∇wq(st,at;wnow).
- 用某种算法更新策略函数 π \pi π。该算法与 SARSA 算法无关。
蒙特卡洛与自举
上一节介绍了多步 TD 目标。单步 TD 目标、回报是多步 TD 目标的两种特例。如下图所示,如果设 m = 1 m=1 m=1,那么多步 TD 目标变成单步 TD 目标。如果设 m = n − t + 1 m=n-t+1 m=n−t+1,那么多步 TD 目标变成实际观测的回报 u t u_t ut 。

蒙特卡洛
训练价值网络 q ( s , a ; w ) q(s,a;\boldsymbol{w}) q(s,a;w) 的时候,我们可以将一局游戏进行到底,观测到所有的奖励 r 1 , ⋯ , r n r_1,\cdots,r_n r1,⋯,rn,然后计算回报 u t = ∑ i = 0 n − t γ i r t + i u_t=\sum_{i=0}^{n-t}\gamma^ir_{t+i} ut=∑i=0n−tγirt+i。拿 u t u_t ut 作为目标,鼓励价值网络 q ( s t , a t ; w ) q(s_t,a_t;\boldsymbol{w}) q(st,at;w) 接近 u t u_t ut。定义损失函数:
L ( w ) = 1 2 [ q ( s t , a t ; w ) − u t ] 2 . L(\boldsymbol{w})\:=\:\frac12\left[\:q(s_{t},a_{t};\boldsymbol{w})\:-\:u_{t}\:\right]^{2}. L(w)=21[q(st,at;w)−ut]2.
然后做一次梯度下降更新 w w w:
w ← w − α ⋅ ∇ w L ( w ) , w\:\leftarrow\:w-\alpha\cdot\nabla_{\boldsymbol{w}}L(\boldsymbol{w}), w←w−α⋅∇wL(w),
这样可以让价值网络的预测 q ( s t , a t ; w ) q(s_t,a_t;\boldsymbol{w}) q(st,at;w) 更接近 u t u_t ut。这种训练价值网络的方法不是 TD。
在强化学习中,训练价值网络的时候以 u t u_t ut作为目标,这种方式被称作“蒙特卡洛”。原因是这样的,动作价值函数可以写作 Q π ( s t , a t ) = E [ U t ∣ S t = s t , A t = a t ] Q_\pi(s_t,a_t)=\mathbb{E}[U_t|S_t=s_t,A_t=a_t] Qπ(st,at)=E[Ut∣St=st,At=at],而我们用实际观测 u t u_t ut 去近似期望,这就是典型的蒙特卡洛近似。
蒙特卡洛的好处是无偏性 : u t :u_t :ut 是 Q π ( s t , a t ) Q_\pi(s_t,a_t) Qπ(st,at) 的无偏估计。由于 u t u_t ut 的无偏性,拿 u t u_t ut 作为目标训练价值网络,得到的价值网络也是无偏的。
蒙特卡洛的坏处是方差大。随机变量 U t U_t Ut 依赖于 S t + 1 , A t + 1 , ⋯ , S n , A n S_{t+1},A_{t+1},\cdots,S_n,A_n St+1,At+1,⋯,Sn,An 这些随机变量,其中不确定性很大。观测值 u t u_t ut 虽然是 U t U_t Ut 的无偏估计,但可能实际上离 E { U t } \mathbb{E}\{U_t\} E{Ut} 很远。
因此,拿 u t u_t ut 作为目标训练价值网络,收敛会很慢。
自举
在介绍价值学习的自举之前,先解释一下什么叫自举。大家可能经常在强化学习和统计学的文章里见到 bootstrapping 这个词。它的字面意思是“拔自己的鞋带,把自己举起来”。所以 bootstrapping 翻译成“自举”, 即自己把自己举起来。自举听起来很荒谬。即使你“力拔山兮气盖世”,你也没办法拔自己的鞋带,把自己举起来。虽然自举乍看起来不现实,但是在统计和机器学习是可以做到自举的;自举在统计和机器学习里面非常常用。
在强化学习中,“自举”的意思是“用一个估算去更新同类的估算”,类似于“自己把自己给举起来”。SARSA 使用的单步 TD 目标定义为:
SARSA 鼓励 q ( s t , a t ; w ) q(s_t,a_t;w) q(st,at;w) 接近 y ^ t \widehat{y}_t y t, 所以定义损失函数
y ^ t = r t + γ ⋅ q ( s t + 1 , a t + 1 ; w ) ⏟ 价值网络做出的估计 . \widehat{y}_{t}\:=\:r_{t}\:+\:\underbrace{\gamma\cdot q(s_{t+1},a_{t+1};\boldsymbol{w})}_{\text{价值网络做出的估计}}\:. y t=rt+价值网络做出的估计 γ⋅q(st+1,at+1;w).
L ( w ) = 1 2 [ q ( s t , a t ; w ) − y ^ t ⏟ 让价值网络拟合 y ^ t ] 2 . \begin{array}{rcl}L(\boldsymbol{w})&=&\frac{1}{2}\Big[\underbrace{q(s_t,a_t;\boldsymbol{w})-\widehat{y}_t}_{\text{让价值网络拟合 }\widehat{y}t}\Big]^2.\end{array} L(w)=21[让价值网络拟合 y t q(st,at;w)−y t]2.
TD 目标 y ^ t \widehat{y}_t y t 的一部分是价值网络做出的估计 γ ⋅ q ( s t + 1 , a t + 1 ; w ) \gamma\cdot q(s_{t+1},a_{t+1};\boldsymbol{w}) γ⋅q(st+1,at+1;w),然后 SARSA 让 q ( s t , a t ; w ) q(s_t,a_t;\boldsymbol{w}) q(st,at;w) 去拟合 y ^ t \widehat{y}_t y t。这就是用价值网络自己做出的估计去更新价值网络自己,这属于“自举”。(严格地说,TD 目标 y ^ t \widehat{y}_t y t 中既有自举的成分,也有蒙特卡洛的成分。TD 目标中的 γ ⋅ q ( s t + 1 , a t + 1 ; w ) \gamma\cdot q(s_{t+1},a_{t+1};w) γ⋅q(st+1,at+1;w) 是自举, 因为它拿价值网络自己的估计作为目标。TD 目标中的 r t r_t rt 是实际观测,它是对 E [ R t ] \mathbb{E}[R_t] E[Rt] 的蒙特卡洛。)
自举的好处是方差小。单步 TD 目标的随机性只来自于 S t + 1 S_{t+1} St+1 和 A t + 1 A_{t+1} At+1, 而回报 U t U_t Ut 的随机性来自于 S t + 1 , A t + 1 , ⋯ , S n , A n S_{t+1},A_{t+1},\cdots,S_n,A_n St+1,At+1,⋯,Sn,An。很显然,单步 TD 目标的随机性较小,因此方差较小。用自举训练价值网络,收敛比较快。
自举的坏处是有偏差。价值网络 q ( s , a ; w ) q(s,a;\boldsymbol{w}) q(s,a;w) 是对动作价值 Q π ( s , a ) Q_\pi(s,a) Qπ(s,a) 的近似。最理想的情况下, q ( s , a ; w ) = Q π ( s , a ) q(s,a;\boldsymbol{w})=Q_\pi(s,a) q(s,a;w)=Qπ(s,a), ∀ s , a \forall s,a ∀s,a。假如碰巧 q ( s j + 1 , a j + 1 ; w ) q(s_{j+1},a_{j+1};\boldsymbol{w}) q(sj+1,aj+1;w)低估(或高估)真实价值 Q π ( s j + 1 , a j + 1 ) Q_{\pi}(s_{j+1},a_{j+1}) Qπ(sj+1,aj+1),则会发生下面的情况:
q ( s j + 1 , a j + 1 ; w ) 低估(或高估) Q π ( s j + 1 , a j + 1 ) ⟹ y j ^ 低估(或高估) Q π ( s j , a j ) ⟹ q ( s j , a j ; w ) 低估(或高估) Q π ( s j , a j ) . \begin{array}{cccc}&q(s_{j+1},a_{j+1};\boldsymbol{w})&\text{低估(或高估)}&Q_{\pi}(s_{j+1},a_{j+1})\\\implies&\widehat{y_j}&\text{低估(或高估)}&Q_{\pi}(s_j,a_j)\\\implies&q(s_j,a_j;\boldsymbol{w})&\text{低估(或高估)}&Q_{\pi}(s_j,a_j).\end{array} ⟹⟹q(sj+1,aj+1;w)yj q(sj,aj;w)低估(或高估)低估(或高估)低估(或高估)Qπ(sj+1,aj+1)Qπ(sj,a<