用NVIDIA A100 GPUs提高计算机视觉
用NVIDIA A100 GPUs提高计算机视觉
Improving Computer Vision with NVIDIA A100 GPUs
在2020年英伟达GPU技术会议的主题演讲中,英伟达创始人兼首席执行官黄延森介绍了基于英伟达安培GPU架构的新英伟达A100 GPU。
在这篇文章中,我们详细介绍了A100的令人兴奋的新特性,这些特性使NVIDIA GPU成为计算机视觉工作负载的一个更好的动力。我们还展示了NVIDIA最近的两个CV研究项目:语义分割的层次多尺度注意和Bi3D:通过二元分类的立体深度估计,并展示了它们如何受益于A100。
NVIDIA A100是有史以来最大的7nm芯片,由54B晶体管、40gb的HBM2 GPU存储器和1.5tb/s的GPU存储器带宽组成。A100为深度学习(DL)训练提供了高达624 TF的FP16算术吞吐量,为DL推理提供了多达1248个INT8算术吞吐量的TOP。在高水平上,英伟达A100配备了一套令人兴奋的新功能:
多实例GPU(MIG)允许将A100 Tensor-Core GPU安全地划分为多达七个单独的GPU实例,用于CUDA应用程序
使用TensorFloat 32(TF32)指令加速FP32数据处理的第三代张量核
第三代NVLink的互连速度是PCIe gen 4的10倍
对于CV工作负载,与V100上的一个视频解码器相比,A100中的视频解码器数量急剧增加到5个。它还包括五个新的硬件JPEG解码器引擎和新的改进硬件光流。
要深入了解NVIDIA安培体系结构,请参阅NVIDIA安培体系结构深度和A100白皮书。
CV research at NVIDIA
在CVPR 2020年,NVIDIA的研究人员发表了15篇研究论文。在这篇文章中,我们展示了英伟达最近的两个研究项目:
分层多尺度注意在语义分割中的应用
NVIDIA A100 Tensor核心GPU体系结构
Hierarchical Multi-Scale Attention for Semantic Segmentation
在自动驾驶、医学成像甚至变焦虚拟背景中,有一项重要的技术是常用的:语义分割。这是将图像中的像素标记为属于N个类(N是任意数量的类)之一的过程,其中类可以是汽车、道路、人或树等。对于医学图像,类对应于不同的器官或解剖结构。
NVIDIA是一种应用广泛的语义分割技术。我们还认为,改进语义分割的技术也可能有助于改进许多其他密集预测任务,如光流预测(预测物体运动)、图像超分辨率等。
多尺度推理是提高语义分割效果的常用方法。多个图像尺度通过一个网络,然后将结果与平均值或最大池相结合。
在分层多尺度注意语义分割中,提出了一种基于注意的多尺度预测方法。我们表明,在一定尺度下的预测能够更好地解决某些失效模式,并且网络学会在这种情况下支持这些尺度,以便生成更好的预测。我们的注意机制是分层的,这使得它的训练内存效率比其他最近的方法高出大约4倍。除了加快训练速度之外,这还允许我们训练更大的作物尺寸,从而提高模型精度。
我们在两个数据集:城市景观和地图景观上展示了我们的方法的结果。对于具有许多弱标记图像的城市景观,我们还利用自动标记来提高泛化能力。使用这种方法,我们在地图(61.1 IOU val)和城市景观(85.1 IOU测试)中都获得了最新的结果。
Bi3D: Stereo Depth Estimation via Binary Classifications
基于立体的深度估计是计算机视觉的基石,最先进的方法可以提供精确的结果。有些应用,如自主导航,并不总是需要厘米级的精确深度,但有严格的延迟要求。
事实上,深度估计所需的准确度、延迟和感兴趣的范围因手头的任务而异。例如,高速公路行驶需要在极低的延迟下进行更长的测量范围,但可以处理粗略量化的深度。更重要的是在毫秒内探测到一个大约80米的障碍物,而不是在10毫秒后发现它正好在81.2米之外。另一方面,平行停车不需要非常快的结果,但对误差的容忍度要低得多。因此,需要一种灵活的立体深度估计方法,以便在推断时进行权衡。
Bi3D为这个问题提供了一个解决方案。给定一个严格的时间预算,Bi3D可以在短短几毫秒内检测到比给定距离更近的物体(图1(b))。这种二进制深度以极低的延迟产生1位信息。将多个深度的二进制决策组合起来,可以使用任意粗略量化(图1(c))来估计深度,并且复杂性与量化级别的数量成线性关系。Bi3D还可以使用量化级别的预算来获得特定深度范围内的连续(高质量深度)(图1(d))。对于标准立体声(即,整个范围内的连续深度,图1(e)),Bi3D接近或等同于最先进的微调立体声方法。
 Figure 1. Given the plane at depth D, overlaid on the left image (a), Bi3D can estimate a binary depth in just a few milliseconds (b). It can estimate a quantized depth with arbitrary quantization, and complexity linear with the number of levels ©. It can also produce continuous depth either for the full range (e), or for a selective range of interest while detecting out of range objects (d).
Figure 1. Given the plane at depth D, overlaid on the left image (a), Bi3D can estimate a binary depth in just a few milliseconds (b). It can estimate a quantized depth with arbitrary quantization, and complexity linear with the number of levels ©. It can also produce continuous depth either for the full range (e), or for a selective range of interest while detecting out of range objects (d).
该方法的核心是Bi3DNet,它以左图像和右图像以及候选视差d{i}作为输入(图2)。输出是一个二进制分割概率图,它将范围分割为两个:大于或小于d{i}的差异。即使测试一个视差d{i}也会告诉您任何像素处的视差是否小于或大于d{i}。通过测试多个这样的差异,您可以估计像素从前到后的转换深度,即该像素的深度。有关更多信息,请参阅NVlabs/Bi3D GitHub repo。
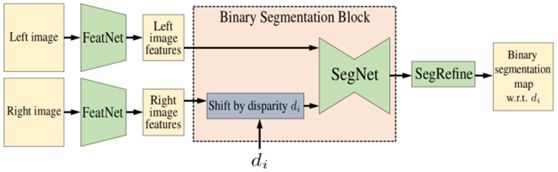
Figure 2. Bi3DNet takes as input the stereo image pair and a candidate disparity to segment the left image into two: disparities that are larger or smaller than . The first module, FeatNet, extracts features from the left and right images. SegNet, a 2D encoder-decoder architecture with skip connections, takes as input the left image features and the right image features shifted by disparity . It generates a binary segmentation probability map that we further refine with the help of the input left image using the SegRefine module.
A100 training results
在本节中,我们将讨论语义分割和Bi3D网络的训练性能:
· TF32: speeding up FP32 effortlessly
· Automatic mixed precision training
TF32: Speeding up FP32 effortlessly
安培第三代张量核支持一种新的数学模式:TF32。TF32是一种混合格式,用于以更高的效率处理FP32的工作。具体地说,由于使用了8位指数,TF32使用与FP16相同的10位尾数来确保精度,同时与FP32具有相同的范围。通过在精度和效率之间取得平衡,与Volta GPU上的单精度浮点数学(FP32)相比,A100 GPU上运行在Tensor核上的TF32可以提供高达10倍的吞吐量。
在安培张量核上,TF32是所有DL工作负载的默认数学模式,而不是Volta/Turing gpu上的FP32。在内部,当在TF32模式下工作时,安培张量磁芯接受两个FP32矩阵作为输入,但在内部执行TF32中的矩阵乘法。结果被添加到FP32累加器中。
要在A100上使用TF32,请像通常使用FP32数据类型那样编写和运行代码。其余的由DL框架自动处理。从20.06版开始,TensorFlow,ythorch和MXNet的NVIDIA DL框架容器支持A100上的TF32,可以从NVIDIA
NGC免费下载。
在图3中,我们展示了训练多尺度注意语义分割网络和Bi3D网络时的吞吐量,其中V100上有FP32,A100上有TF32。在没有任何代码更改的情况下,TF32分别提供了1.6倍和1.4倍的加速。
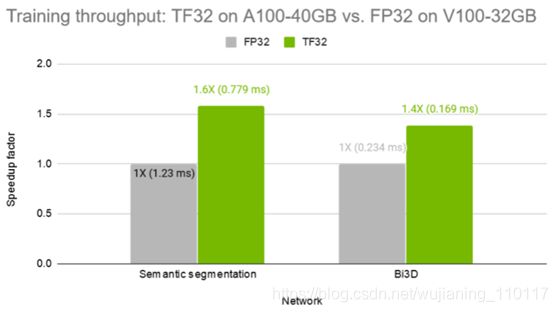
Figure 3. Training throughput of TF32 on A100-40GB vs. FP32 on V100-32GB GPU. Semantic segmentation: batch size 2 on Cityscapes dataset. Bi3D: batch size 8 on SceneFlow dataset. Numbers in parentheses denotes average time for processing 1 training batch. Bars represent speedup factor vs. FP32 on V100-32GB GPU. The higher, the better.
Automatic mixed precision training
TF32旨在将NVIDIA Tensor核心技术的处理能力带到所有DL工作负载中,而无需开发人员进行任何代码更改。
然而,对于那些希望解锁最高吞吐量的更精明的研究人员来说,混合精度训练仍然是最有效的选择,它主要使用FP16,但在必要时也使用FP32数据类型。
NVIDIA gpu上的自动混合精度(AMP)培训可以很容易地启用,无需更改代码(使用NVIDIA NGC TensorFlow容器时)或只需几行额外代码。在FP16模式下工作时,安培张量磁芯接受FP16矩阵,并累积在FP32矩阵中。安培的FP16模式提供的吞吐量是TF32的两倍。
图4显示了在V100和A100上以混合精度训练多尺度注意语义分割网络和Bi3D网络时的吞吐量。A100上的AMP与V100 32 GB GPU上的AMP相比,速度分别提高了1.6倍和1.4倍。

Figure 4. AMP training throughput on A100 vs. V100-32GB GPUs. Semantic segmentation: batch size 4 on Cityscapes dataset. Bi3D: batch size 8 on SceneFlow dataset. Numbers in parentheses denotes average time for processing one training batch. Bars represent speedup factor vs. mixed precision training on V100-32GB GPU. The higher, the better.
Multi-instance GPU for training
多实例GPU(MIG)将单个NVIDIA A100 GPU划分为多达七个独立的GPU实例。它们同时运行,每个都有自己的内存、缓存和流式多处理器(SM)。这使得A100 GPU能够以比以前的GPU高7倍的利用率提供有保证的服务质量(QoS)。
对于多尺度注意力语义分割和Bi3D网络训练等繁重的训练工作,可以创建两个所谓的MIG 3g.20gb实例,每个实例都有20gb的GPU内存和42sms。这使得两位研究人员可以独立进行研究,而不必担心在内存和计算方面相互干扰。
在本节中,我们将在配置为2x MIG 3g.20gb实例的A100 GPU上测试两个并行训练工作负载。一个用于训练多尺度注意语义分割网络,另一个用于Bi3D网络。
图5显示,在并行训练的同时,MIG实例分别为语义分割和Bi3D两个网络保持了完整A100的71%和54%的吞吐量。
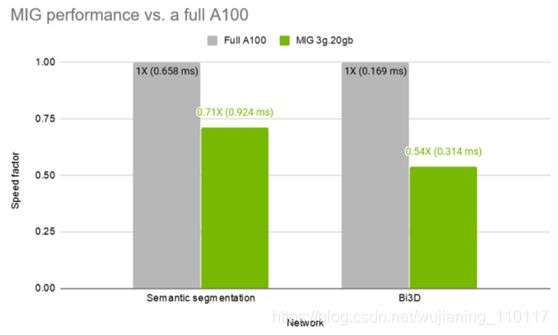
Figure 5. MIG instances training performance vs. a full A100 GPU. Semantic segmentation: batch size 2 on Cityscapes dataset with AMP. Bi3D: batch size 8 on SceneFlow dataset. Numbers in parentheses denotes average time for processing 1 training batch. Bars represent MIG instance performance as a fraction of a full A100 performance. The higher, the better.
Speeding up the CV input pipeline with NVJPG, NVDEC, and NVIDIA DALI
NVIDIA A100 GPU增加了几个加速CV输入管道的功能:
· NVJPG: Image decoder for DL training
· NVDEC: Video decoder for DL training
· NVIDIA Data Loading Library
NVJPG: Image decoder for DL training
A100 GPU增加了一个新的基于硬件的JPEG解码功能。JPEG解码的输入瓶颈是实现图像DL训练/推理高吞吐量的根本问题之一。CPU和GPU对JPEG解码的效率不是很高,这是因为用于处理图像位的串行操作。此外,如果即使JPEG解码的一部分在CPU中完成,PCIe也会成为另一个瓶颈。
A100通过添加硬件JPEG解码引擎来解决这些问题。A100包括一个五核硬件JPEG解码引擎,可通过nvJPEG库访问。虽然解码器一次处理五个样本,但您可以提交任意数量的样本。批处理由nvJPEG库在内部处理。尽管如此,我们还是建议在请求中提供具有相似大小和相同色度格式的样本。这样,它们被成批地放在一起,从而使每个JPEG解码器核心的利用率相等,从而获得最佳性能。
NVDEC: Video decoder for DL training
在DL平台中,输入视频以行业标准格式压缩,如H264/HEVC/VP9等。在DL平台上实现高端到端吞吐量的一个重要挑战是能够保持输入视频解码性能与训练/推理性能相匹配。否则,无法利用GPU的完整DL性能。
A100在这方面有了很大的飞跃,它增加了五个NVDEC(NVIDIA解码)单元,而在V100中只有一个NVDEC。通过NVIDIA显示驱动程序管理所有nvdec的负载,现有应用程序可以在不做任何更改的情况下获得附加解码功能的好处。
NVJPG和NVDEC解码器都是独立于CUDA核心的,允许加速的数据预处理任务与GPU上的网络训练任务并行运行。
NVIDIA Data Loading Library
DALI是一个高度优化的构建块集合,是一个执行引擎,用于加速DL应用程序输入数据的预处理。对于DL工作负载的数据预处理直到最近才引起人们的注意,被训练复杂模型所需的巨大计算资源所掩盖。因此,预处理任务通常在CPU上运行,这是由于OpenCV或Pillow等库的简单性、灵活性和可用性。GPU体系结构和软件的最新进展显著提高了DL任务中的GPU吞吐量,因此您可以比处理框架提供的数据更快地训练模型,从而使GPU缺少数据。
DALI是我们努力为前面提到的数据管道问题找到可伸缩和可移植解决方案的结果。这个库可以很容易地集成到不同的DL训练和推理应用程序中。DALI自动利用A100的JPEG和视频解码硬件功能,显著加快CV输入管道。
图6显示了一个典型的类似ResNet50的图像分类管道。

Figure 6. ResNet50-like image classification pipeline.
图7显示了当使用DALI将解码从CPU切换到各种基于GPU的方法时,可以预期的性能提升。对不同批量的CPU-libjpeg-turbo解决方案、Volta-CUDA解码、A100硬件JPEG解码器、A100双硬件CUDA解码器进行了测试。
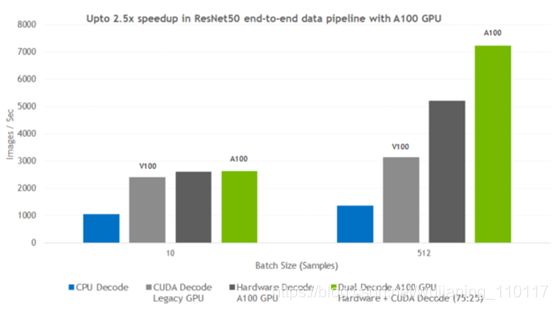
Figure 7: End-to-end data processing pipeline throughput comparison between CPU, CUDA, A100 hardware-accelerated, and dual CUDA and hardware-accelerated JPEG image decoding for a ResNet50-like image classification model. CPU – Platinum 8168@2GHz 3.7GHz
Turbo (Skylake) HT On; NVIDIA V100-16GB GPU with E5-2698 v4@2GHz 3.6GHz Turbo (Broadwell) HT On; NVIDIA A100 GPU with Platinum 8168@2GHz 3.7GHz Turbo (Skylake) HT On; Dataset: training set of ImageNet.
Optical flow accelerator
光流和立体视差是计算机视觉中两种基本的图像分析方法。光流测量两幅图像之间点的视运动,立体视差测量两个平行校准相机系统中物体的(逆)深度。如图8所示。

Figure 8. Illustration of optical flow and stereo disparity.
光流和立体视差被广泛应用于计算机视觉任务中,包括汽车和机器人导航、电影制作、视频分析和理解、增强和虚拟现实等。
光流和立体视差的测量已经研究了几十年,但是尽管目前的技术有了很大的进步,但它们仍然是一个挑战性的问题,特别是要以现代相机的像素速率获得实时、密集的数据,这种速度通常超过50兆像素/秒,而且很容易达到10倍。
A100包括一个新的改进的光流引擎,它提供了更高的精度,每像素流矢量,和感兴趣的区域。该模块支持4K时高达300fps的光流和立体视差估计,该硬件加速器独立于CUDA核,能够高精度、高性能地计算给定帧对之间的光流矢量。可以通过参数选择来调整质量和性能。
光流硬件可以使用NVIDIA光流SDK编程,也可以通过DALI和OpenCV访问,这是一个流行的开源计算机视觉库,带有跟踪算法,可以利用NVIDIA gpu上的光流硬件计算运动矢量。
已经利用光流SDK的应用程序通过即将到来的驱动程序更新在A100上获得更高的性能和更高的精度。在即将发布的光流SDK中,将提供利用感兴趣区域和每像素流向量等新功能的api。
结论
新的A100 GPU配备了用于计算机视觉工作负载的新功能:
用于JPEG和视频解码器的专用硬件,以加快数据输入管道
新一代光流加速硬件
提高FP32数据处理速度的新张量核指令
提高了FP16的吞吐量
允许更好地共享和隔离工作负载的多实例GPU