【图论】基于数据集生成的演员合作网络图的简单分析(结果有彩蛋)
刚刚做完图论课的大作业,从中收获了很多东西,最终结果也很有意思。
背景:
2005年的时候开展了一次图像绘制会议(Graph Drawing conference),期间展示了用互联网电影资料库(IMDb)提供的数据集生成的演员合作网络图。即把每个演员看成一个顶点,如果两个演员在1995年至2005年之间合作拍摄过两次以上的电影,则将他们用一条无向边连接起来,再将不同类型的电影用不同颜色加以区分,从而得出了下面这幅“演员合作网络图”(很是复杂啊!)。

当然,为了降低难度,提供给我们使用的是两个经过简化过的数据集:
1.imdb_actor_edges.tsv
2.imdb_actors_key.tsv
第一个数据集里面包含了演员1的ID和演员2的ID,以及它们之间在十年内合作拍摄过的电影的数量num_movies。
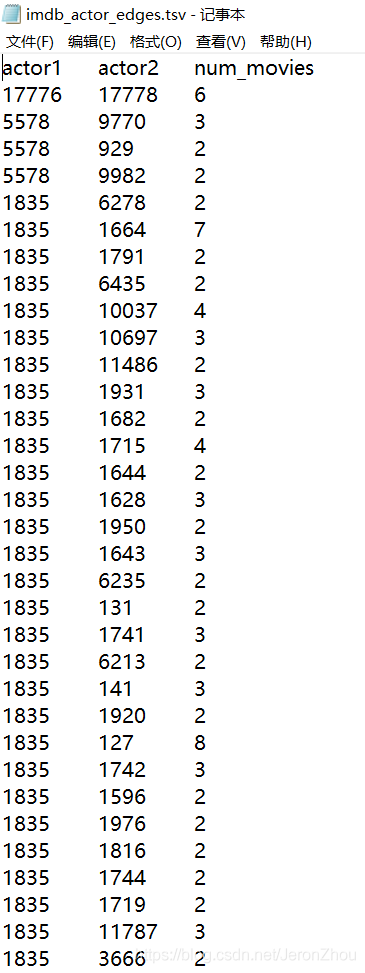
这个数据集有多庞大呢?
我用Excel打开并排序之后发现其中总共有28万余条这种关联数据。
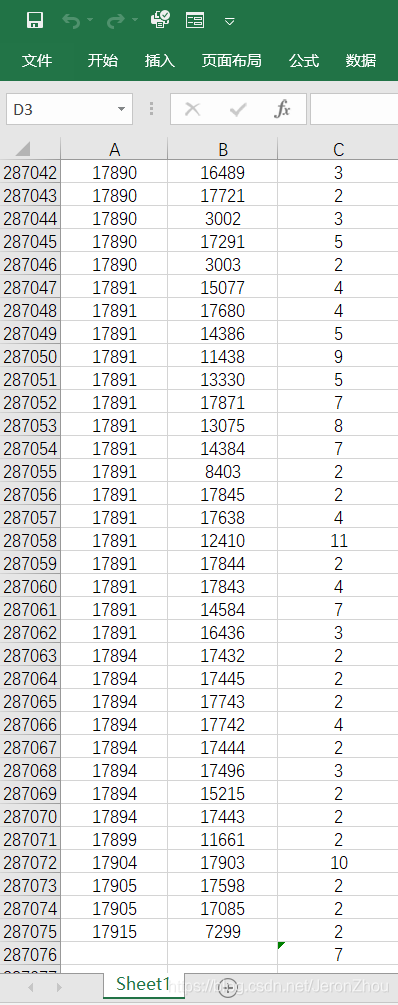
第二个数据集里面包含了每个演员的信息,包括ID、姓名name、十年间拍摄过的电影的数量movies_95_04、主要参演电影类型main_genre以及每种类型的具体数量。

再用Excel打开之后发现总共有一万七千多的演员数据。
至此,我对这项工程的数据规模有了初步的了解:
我需要处理的是一个含有17000余个顶点,280000余条边的无向图!
虽然心中有一万头奔腾的羊驼,我还是硬着头皮查看了这个project的要求:
- 计算每个节点的度数,输出度数最大的前20个节点及其度数(如果末位有并列,则全部输出,即:最终输出节点数可多于20)
- 计算节点度数的分布并作图:横坐标为度数degrees,纵坐标为拥有该度数的节点数nodes。
- [加分项]针对上述数据集,选择任何你感兴趣的点进行分析。
还好,还好,原来只是写个程序啊 (喝口快乐水压压惊。。。。。)
那么问题来了:怎么写???
我:emmmm…emmmmm…
在经过苦(询)思(问)冥(大)想(佬)之后,
得到了如下Python代码:
# 这段代码需要满足以下两个要求:
# 1.计算每个节点的度数,输出度数最大的前20个节点及其度数(允许并列存在)
# 2.计算节点度数的分布并作出一个线性图表:其中x轴代表了度数(合作过的次数),y轴代表了节点数(演员数)
edge = {"actor1": None, "actor2": None, "num_movies": None}
# 将边edge表示成字典型,其有三个键值对,分别代表边的三个属性
node = {"id": None, "name": None, "movies_95_04": None, "main_genre": None, "genres": None}
# 将节点node表示成字典型,其有五个键值对,分别代表节点(演员)的五个属性
node_xy = {"degree": None, "node_number": None}
# 将节点度数和节点数表示成字典型,其中degree在图像中为x轴,node_number在图像中为y轴
# 定义一个将边edge的数据储存在数组中的函数read_edge,实现读取录入的操作
def read_edge(file):
edge_list = list()
with open(file, 'r', encoding='utf-8') as f: # 以只读模式,用utf-8编码方式打开文件
line = f.readline()
while line:
line = f.readline()
if line:
a = line.split('\t')
edge_list.append({"actor1": a[0], "actor2": a[1], "num_movies": a[2]})
return edge_list
# 定义一个将节点node的数据储存在集合中的函数read_node,实现读取录入的操作
def read_node(file):
nodes = dict()
with open(file, 'r', encoding='utf-8') as f: # 以只读模式、用utf-8编码方式打开文件
line = f.readline()
while line:
line = f.readline()
if line:
a = line.split('\t')
nodes[a[0]] = {"name": a[1], "movies_95_04": a[2], "main_genre": a[3], "genres": a[4], "degree": 0}
return nodes
# 定义将所得度数进行排序的函数sort
def sort(nodes: dict):
node_degree = list()
for node_id, value in nodes.items():
node_degree.append({'ID': node_id, 'degree': value['degree']})
node_degree.sort(key=lambda node : node['degree'], reverse=True)
t = list()
num = 0
for n in node_degree: # 筛选出度数最大的20个节点
if num < 20:
t.append(n)
else:
if n['degree'] == t[19]['degree'] :
t.append(n)
num = num + 1
return t
# 计算单个点度数的函数degree
def degree(e, n):
for edge in e:
actor1 = edge['actor1']
actor2 = edge['actor2']
n[actor1]['degree'] = n[actor1]['degree'] + 1
n[actor2]['degree'] = n[actor2]['degree'] + 1
return n
# 定义计算所有点度数的函数count
def count(file: dict):
t = dict()
for node_id, value in file.items():
degree = value['degree']
t[degree] = 0
for node_id, value in file.items():
degree = value['degree']
t[degree] = t[degree] + 1
return t
# 执行脚本
if __name__ == "__main__":
Edge = read_edge(r"C:\Users\86188\Desktop\project\imdb_actor_edges.tsv")
# 用read_edge函数读取相应路径的文件并将数据存储在Edge中,具体路径可以灵活变更
Node = read_node(r"C:\Users\86188\Desktop\project\imdb_actors_key.tsv")
# 用read_node函数读取相应路径的文件并将数据存储在Node中,具体路径可以灵活变更
temp = degree(Edge, Node)
# 用count_degree函数计算每个节点的度数,并储存在temp中
MAX = sort(temp)
# 用sort函数给所得度数temp进行排序,并计算出拥有最大度数的20个节点,并储存在MAX中
degree_number = count(Node)
# 用count_degree_numbers函数计算每个节点的度数,并储存在degree_number中
print("\n度数最大的前20个节点的ID及其度数为:")
print(MAX) # 输出度数最大的前20个节点的相应数据
x=list()
y=list()
for node_degree, i in degree_number.items():
x.append(node_degree)
y.append(i)
# 至此,我们已经得到了度数最大的前20个节点的ID以及它们对应的度数
# 它们将按照[{'node_id':'id-number', 'degree':degree-number},{...},{...}.......{...}]的格式输出
# 开始图像绘制,这里需要用到matplotlib库(已预先导入)
# 需要注意的是matplotlib库对中文不太支持,容易出现显示不出来的情况,所以此图表里的文字一律使用英文
import matplotlib.pyplot as plt # 引入matplotlib库,用于绘制图像
plt.figure(figsize=(10, 6), facecolor='pink') # 定义图表属性,长10英寸,宽6英寸,背景颜色为粉色
plt.plot(x, y, color='c', linestyle='-.', marker='*') # 定义线条属性,颜色为青色,线条风格为点划线,标记点风格为星型
plt.xlabel('degree number (co-star-movie-number)') # 显示x轴的表示含义——度数(合作次数)
plt.ylabel('nodes number (actors)') # 显示y轴的表示含义——节点数(演员数)
plt.title('Node Degree Distribution Diagram') # 显示图表的标题
plt.show() # 将图表show出来
大概思路:先把节点和边转化成字典型的数据,方便索引。之后通过两个函数来实现对数据集文件的数据导入,再提取出来各个节点的度数,然后利用排序函数对由这些度数组成的新的集合进行排序,从而筛选出度数最大的前20个节点。
结果:
可以得出度数最大的前20个节点的ID及其度数degree为:
[{'ID': '162', 'degree': 784}, {'ID': '1743', 'degree': 610},
{'ID': '1754', 'degree': 599}, {'ID': '1802', 'degree': 584},
{'ID': '407', 'degree': 561}, {'ID': '164', 'degree': 555},
{'ID': '179', 'degree': 545},{'ID': '176', 'degree': 533},
{'ID': '175', 'degree': 500}, {'ID': '160', 'degree': 493},
{'ID': '127', 'degree': 490},{'ID': '1626', 'degree': 475},
{'ID': '131', 'degree': 471},{'ID': '2108', 'degree': 471},
{'ID': '163', 'degree': 463}, {'ID': '701', 'degree': 457},
{'ID': '1778', 'degree': 451}, {'ID': '177', 'degree': 450},
{'ID': '1688', 'degree': 438}, {'ID': '1804', 'degree': 428}]
之后,由于需要绘制图表,故需要引入第三方的matplotlib库。
得到的折线图如下:
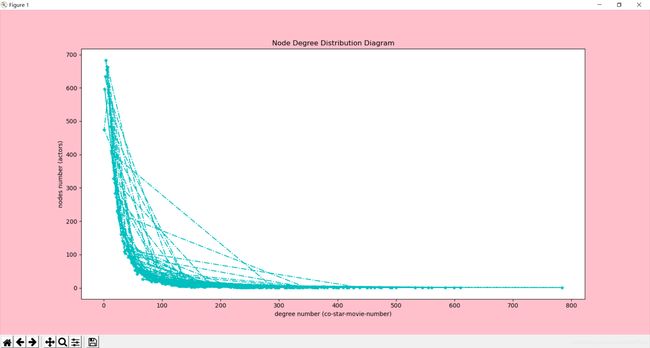
以为这就完了?
别走,说好了有彩蛋的
我出于好奇还分析了度数最多的前20名的参演电影类型。毕竟这些演员与其他演员“合作”参演的电影实在是太多了,直觉告诉我这很不寻常,有必要分析一下!
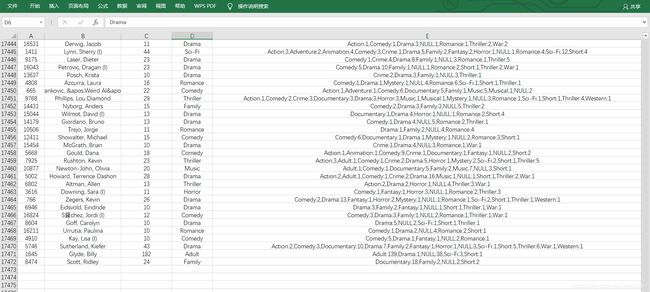
于是我按照ID用Excel筛选出了这些演员的信息:

结果出人意料但又在情理之中:
20个演员当中除了ID为701的Hanks,Tom(清流)参演的主要类型为家庭片Family,其余19人参演的主要类型均为Adult。这或许也解释了他们的度数如此之多的原因。
另外,我也对我所得到的结果的正确性有了足够的信心。
