大数据学习——jdk安装和hadoop安装
1、centos 7 修改主机文件:master slave1 slave2
vim /etc/hosts
192.168.58.10 master
192.168.58.11 slave1
192.168.58.12 slave2
检测是否能ping通: ping master ping slave1 ping slave1 (三台机子分别执行)
2、centos 7 SSH互信配置:master slave1 slave2
ssh-keygen -t rsa #一路回车 生成密钥
ls ./.ssh
netstat -lanput | grep 22
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
验证是否互信:
ssh master hostname
ssh slave1 hostname
ssh slave2 hostname
3、安装jdk
使用SecureCRT远程桌面工具连接虚拟机
安装上传下载工具:yum install -y lrzsz
进入到root目录安装:cd
rz (选jdk jdk-8u....tar.gz文件) 上传jdk hadoop2.6.5
tar -zxvf jdk-8u....(解压) (tar xf 你的jdk文件 名)
rm -rf jdk-8....tar.gz (解压完之后可以删除)
建立一个快捷方式:ln -sv /root/jdk1.8.0_172 /root/java (升级jdk版本,只需要重新建立快捷方式,不需要再修改环境变量)
vim ~/.bashrc (文末添加下面一段环境变量)
export JAVA_HOME=/root/java
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
source ~/.bashrc(使环境变量生效)
java -version(检查java版本)
复制jdk到节点1 节点2
scp -r ./jdk1.8.0_172 slave1:`pwd`
scp -r ./jdk1.8.0_172 slave1:`pwd`
复制完之后去配置环境变量。。。。
4、安装hadoop
上传 解压了hadoop
同样建立一个快捷方式:ln -sv /root/hadoop-2.6.5 /root/hadoop
配置环境变量:
vim ~/.bashrc
export HADOOP_HOME=/root/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source ~/.bashrc
注意:要配置好了再复制,以免出错 节点之间的配置文件要保持一致
cd /root/hadoop/etc/hadoop
vim core-site.xml (hadoop的核心文件 hadoop启动会直接优先加载)
备注:/root/hadoop/temp 存放临时文件 没有需要创建这个文件夹
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
vim yarn-site.xml
vim workers
slave1
slave2
创建配置文件中的临时文件:
cd /root/hadoop/
mkdir temp
mkdir -pv dfs/name ( 递归创建目录)
mkdir -pv dfs/data
mkdir -pv dfs/namesecondary
复制到节点1 2
scp -r ./hadoop-2.6.5 slave1:`pwd`
scp -r ./hadoop-2.6.5 slave2:`pwd`
在主节点上操作:
初始化文件系统:hadoop namenode -format (在第一次使用文件系统或者需要恢复文件系统的时候才需要使用,并不是每次启动都要初始化)
启动 start-all.sh
jps
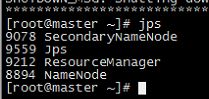


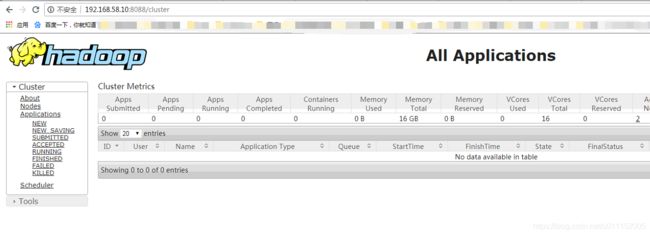
web页面:http://master:8088
停止:stop-all.sh
补充:
vim快速操作:(非插入模式下)
dd 删除 (ndd n是数字 删除几行 eg: 1dd 2dd 3dd)
u 撤销
yy 复制 (nyy n是数字)
p 粘贴