HMM隐马尔科夫模型
隐马尔科夫(Hidden Markov Model,以下简称HMM)是比较经典的机器学习模型模型了,它在语言识别,自然语言处理,模式识别等领域得到广泛的应用,当然,随着目前深度学习的崛起,尤其是RNN、LSTM等神经网络模型的火热,HMM的地位有所下降。但是作为一个经典的模型,学习HMM的模型和对应算法,对我们解决问题建模的能力提高以及算法思路的拓展还是很好的。
什么样的问题需要HMM模型
首先我们来看看什么样的问题可以用HMM模型。使用HMM模型时我们的问题一般有这两个特征:
1)我们的问题是基于序列的,比如时间序列,或者状态序列。
2)我们的问题中有两类数据,一类序列数据是可以观测到的,即观测序列;而另一类数据是不能观察到的,即隐藏状态序列,简称状态序列。
有了这两个特征,那么这个问题一般可以用HMM模型来尝试解决。这样的问题在实际生活中是很多的。比如:我现在在打字写博客,我在键盘上敲出来的一系列字符就是观测序列,而我实际想写的一段话就是隐藏序列,输入法的任务就是从敲入的一系列字符尽可能的猜测我要写的一段话,并把最可能的词语放在最前面让我选择,这就可以看做是一个HMM模型了。再举一个,我在和你说话,我发出的一串连续的声音就是观测序列,而我实际要表达的一段话就是状态序列,你大脑的任务,就是从这一串连续的声音中判断出我最可能要表达的话的内容。
从这些例子中,我们可以发现,HMM模型可以无处不在。但是上面的描述还不精确,下面我们用精确的数学符号来表述我们的HMM模型。
HMM模型的定义
对于HMM的模型,首先我们假设 Q Q Q是所有可能的隐藏状态的集合, V V V是所有可能的观测状态的集合,即:
Q = { q 1 , q 2 , … , q N } , V = { v 1 , v 2 , … v M } Q=\left\{q_{1}, q_{2}, \ldots, q_{N}\right\}, V=\left\{v_{1}, v_{2}, \ldots v_{M}\right\} Q={q1,q2,…,qN},V={v1,v2,…vM}
其中, N N N是可能的隐藏状态数, M M M是所有的可能的观察状态数。
对于一个长度为 T T T的序列, I I I是对应的状态序列, O O O是对应的观察序列,即:
I = { i 1 , i 2 , … , i T } , O = { o 1 , o 2 , … o T } I=\left\{i_{1}, i_{2}, \ldots, i_{T}\right\}, O=\left\{o_{1}, o_{2}, \ldots o_{T}\right\} I={i1,i2,…,iT},O={o1,o2,…oT}
其中,任意一个隐藏状态 i t ∈ Q i_{t} \in Q it∈Q,任意一个观察状态 o t ∈ V o_{t} \in V ot∈V
HMM模型做了两个很重要的假设如下:
1)齐次马尔科夫链假设。即任意时刻的隐藏状态只依赖于它前一个隐藏状态。当然这样假设有点极端,因为很多时候我们的某一个隐藏状态不仅仅只依赖于前一个隐藏状态,可能是前两个或者前三个。但是这样假设的好处就是模型机简单,便于求解。如果在时刻 t t t的隐藏状态是 i t = q i i_{t}=q_{i} it=qi,在时刻 t + 1 t+1 t+1的隐藏状态是 i t + 1 = q j i_{t+1}=q_{j} it+1=qj,则从时刻 t t t到时刻 t + 1 t+1 t+1的HMM状态转移概率 a i j a_{ij} aij可以表示为:
a i j = P ( i t + 1 = q j ∣ i t = q i ) a_{i j}=P\left(i_{t+1}=q_{j} \mid i_{t}=q_{i}\right) aij=P(it+1=qj∣it=qi)
这样 a i j a_{ij} aij可以组成马尔科夫链的状态转移矩阵 A A A:
A = [ a i j ] N × N A=\left[a_{i j}\right]_{N \times N} A=[aij]N×N
2)观测独立性假设。即任意时刻的观察状态只仅仅依赖于当前时刻的隐藏状态,这也是一个为了简化模型的假设。如果在时刻 t t t的隐藏状态是 i t = q j i_{t}=q_{j} it=qj,而对应的观察状态为 o t = v k o_{t}=v_{k} ot=vk,即该时刻观察状态 v k v_{k} vk在隐藏状态 q j q_{j} qj下生成的概率为 b j ( k ) b_{j}(k) bj(k),满足:
b j ( k ) = P ( o t = v k ∣ i t = q j ) b_{j}(k)=P\left(o_{t}=v_{k} \mid i_{t}=q_{j}\right) bj(k)=P(ot=vk∣it=qj)
这样 b j ( k ) b_{j}(k) bj(k)可以组成观测状态生成的概率矩阵 B B B:
B = [ b j ( k ) ] N × M B=\left[b_{j}(k)\right]_{N \times M} B=[bj(k)]N×M
除此之外,我们需要一组在时刻 t = 1 t=1 t=1的隐藏状态概率分布 Π \Pi Π:
Π = [ π ( i ) ] N \Pi=[\pi(i)]_{N} Π=[π(i)]N
其中, π ( i ) = P ( i 1 = q i ) \pi(i)=P\left(i_{1}=q_{i}\right) π(i)=P(i1=qi)
一个HMM模型,可以由隐藏状态初始概率分布 Π \Pi Π,状态转移概率矩阵 A A A和观测状态概率矩阵 B B B决定。 Π , A \Pi,A Π,A决定状态序列, B B B决定观测序列。因此,HMM模型可以有一个三元组表示如下:
λ = ( A , B , Π ) \lambda=(A, B, \Pi) λ=(A,B,Π)
一个HMM模型实例
下面我们用一个简单的实例来描述上面抽象出的HMM模型。这是一个盒子与球的模型,例子来源于李航的《统计学习方法》。
假设我们有3个盒子,每个盒子里都有红色和白色两种球,这三个盒子里球的数量分别是:
| 盒子 | 1 | 2 | 3 |
|---|---|---|---|
| 红球数 | 5 | 4 | 7 |
| 白球数 | 5 | 6 | 3 |
按照下面的方法从盒子里抽球,开始的时候,从第一个盒子抽球的概率是0.2,从第二个盒子抽球的概率是0.4,从第三个盒子抽球的概率是0.4.以这个概率抽一次球后,将球放回。然后从当前盒子转移到下一个盒子进行抽球。规则是:
如果当前抽球的盒子是第一个盒子,则以0.5的概率仍然留在第一个盒子继续抽球,以0.2的概率去第二个盒子抽球,以0.3的概率去第三个盒子抽球。
如果当前抽球的盒子是第二个盒子,则以0.5的概率仍然留在第二个盒子继续抽球,以0.3的概率去第一个盒子抽球,以0.2的概率去第三个盒子抽球。
如果当前抽球的盒子是第三个盒子,则以0.5的概率仍然留在第三个盒子继续抽球,以0.2的概率去第一个盒子抽球,以0.3的概率去第二个盒子抽球。
如此下去,直到重复三次,得到一个球的颜色的观测序列:
O = { O=\{ O={ 红,白,红 } \} }
注意在这个过程中,观察者只能看到球的颜色序列,却不能看到球是从哪个盒子里取出来的。
那么按照我们上一节对HMM模型的定义,我们的观察集合是:
V = { V=\{ V={ 红, 白 } , M = 2 \}, M=2 },M=2
我们的状态集合是:
Q = { Q=\{ Q={ 盒子1,盒子2,盒子3 } , N = 3 \}, N=3 },N=3
而观察序列和状态序列的长度为3
初始状态分布为:
Π = ( 0.2 , 0.4 , 0.4 ) T \Pi=(0.2,0.4,0.4)^{T} Π=(0.2,0.4,0.4)T
状态转移概率分布矩阵为:
A = ( 0.5 0.2 0.3 0.3 0.5 0.2 0.2 0.3 0.5 ) A=\left(\begin{array}{lll} 0.5 & 0.2 & 0.3 \\ 0.3 & 0.5 & 0.2 \\ 0.2 & 0.3 & 0.5 \end{array}\right) A=⎝⎛0.50.30.20.20.50.30.30.20.5⎠⎞
观测状态概率矩阵为:
B = ( 0.5 0.5 0.4 0.6 0.7 0.3 ) B=\left(\begin{array}{ll} 0.5 & 0.5 \\ 0.4 & 0.6 \\ 0.7 & 0.3 \end{array}\right) B=⎝⎛0.50.40.70.50.60.3⎠⎞
HMM观测序列的生成
从上一节的例子,我们也可以抽象出HMM观测序列生成的过程。
输入的是HMM的模型 λ = ( A , B , Π ) \lambda=(A, B, \Pi) λ=(A,B,Π),观测序列的长度 T T T
输出是观测序列 O = { o 1 , o 2 , … o T } O=\left\{o_{1}, o_{2}, \ldots o_{T}\right\} O={o1,o2,…oT}
生成的过程如下:
1)根据初始状态概率分布 Π \Pi Π生成隐藏状态 i 1 i_{1} i1
2) for t from 1 to T
- a.按照隐藏状态 i t i_{t} it的观测状态分布 b i t ( k ) b_{i_{t}}(k) bit(k)生成观察状态 o t o_{t} ot
- b.按照隐藏状态 i t i_{t} it的状态转移概率分布 a i a_{i} ai, i t + 1 i_{t+1} it+1产生隐藏状态 i t + 1 i_{t+1} it+1
所有的 o t o_{t} ot一起形成观测序列 O = { o 1 , o 2 , … , o T } O=\left\{o_{1}, o_{2}, \ldots, o_{T}\right\} O={o1,o2,…,oT}
HMM模型的三个基本问题
HMM模型一共有三个经典的问题需要解决:
1)评估观察序列概率。即给定模型 λ = ( A , B , Π ) \lambda=(A, B, \Pi) λ=(A,B,Π)和观测序列 O = { o 1 , o 2 , … o T } O=\left\{o_{1}, o_{2}, \ldots o_{T}\right\} O={o1,o2,…oT},计算在模型 λ \lambda λ下观测序列 O O O出现的概率 P ( O ∣ λ ) P(O \mid \lambda) P(O∣λ)。这个问题的求解需要用到前后向算法,我们会在后面详细讲解。这个问题是HMM模型三个问题中最简单的。
2)模型参数学习问题。即给定观测序列 O = { o 1 , o 2 , … o T } O=\left\{o_{1}, o_{2}, \ldots o_{T}\right\} O={o1,o2,…oT},估计模型 λ = ( A , B , Π ) \lambda=(A, B, \Pi) λ=(A,B,Π)的参数,使该模型下观测序列的条件概率 P ( O ∣ λ ) P(O \mid \lambda) P(O∣λ)最大。这个问题的求解需要用到基于EM算法的鲍姆-韦尔奇算法,我们后面会详细讲解。这个问题是HMM模型三个问题中最复杂的。
3)预测问题,也称为解码问题。即给定 λ = ( A , B , Π ) \lambda=(A, B, \Pi) λ=(A,B,Π)和观测序列 O = { o 1 , o 2 , … o T } O=\left\{o_{1}, o_{2}, \ldots o_{T}\right\} O={o1,o2,…oT},求给定观测序列条件下,最可能出现的对应的状态序列,这个问题的求解需要用到基于动态规划的维特比算法,这个也会详细讲解。这个问题是HMM模型三个问题中复杂度居中的算法。
回顾HMM问题:求观测序列的概率
首先我们回顾下HMM模型的问题。这个问题是这样的。我们已知HMM模型的参数 λ = ( A , B , Π ) \lambda=(A, B, \Pi) λ=(A,B,Π)。其中 A A A是隐藏状态转移概率的矩阵, B B B是观测状态生成概率的矩阵, Π \Pi Π是隐藏状态的初始概率分布。同时我们也已经得到了观测序列 O = { o 1 , o 2 , … o T } O=\left\{o_{1}, o_{2}, \ldots o_{T}\right\} O={o1,o2,…oT},现在我们要求观测序列 O O O在模型 λ \lambda λ下出现的条件概率 P ( O ∣ λ ) P(O \mid \lambda) P(O∣λ)。
乍一看,这个问题很简单。因为我们知道所有的隐藏状态之间的转移概率和所有从隐藏状态到观测状态生成概率,那么我们是可以暴力求解的。
我们可以列举出所有可能出现的长度为 T T T的隐藏序列 I = { i 1 , i 2 , … , i T } I=\left\{i_{1}, i_{2}, \ldots, i_{T}\right\} I={i1,i2,…,iT},分布求出这些隐藏序列与观测序列 O = { o 1 , o 2 , … o T } O=\left\{o_{1}, o_{2}, \ldots o_{T}\right\} O={o1,o2,…oT}的联合概率分布 P ( O , I ∣ λ ) P(O, I \mid \lambda) P(O,I∣λ),这样我们就可以很容易的求出边缘分布 P ( O ∣ λ ) P(O \mid \lambda) P(O∣λ)了。
具体暴力求解的方法是这样的:首先,任意一个隐藏序列 I = { i 1 , i 2 , … , i T } I=\left\{i_{1}, i_{2}, \ldots, i_{T}\right\} I={i1,i2,…,iT}出现的概率是:
P ( I ∣ λ ) = π i 1 a i 1 i 2 a i 2 i 3 … a i T − 1 P(I \mid \lambda)=\pi_{i_{1}} a_{i_{1} i_{2}} a_{i_{2} i_{3}} \ldots a_{i_{T-1}} P(I∣λ)=πi1ai1i2ai2i3…aiT−1
对于固定的状态序列 I = { i 1 , i 2 , … , i T } I=\left\{i_{1}, i_{2}, \ldots, i_{T}\right\} I={i1,i2,…,iT},我们要求的观察序列 O = { o 1 , o 2 , … o T } O=\left\{o_{1}, o_{2}, \ldots o_{T}\right\} O={o1,o2,…oT}出现的概率是:
P ( O ∣ I , λ ) = b i 1 ( o 1 ) b i 2 ( o 2 ) … b i T ( o T ) P(O \mid I, \lambda)=b_{i_{1}}\left(o_{1}\right) b_{i_{2}}\left(o_{2}\right) \ldots b_{i_{T}}\left(o_{T}\right) P(O∣I,λ)=bi1(o1)bi2(o2)…biT(oT)
则 O O O和 I I I联合出现的概率是:
P ( O , I ∣ λ ) = P ( I ∣ λ ) P ( O ∣ I , λ ) = π i 1 b i 1 ( o 1 ) a i 1 i 2 b i 2 ( o 2 ) … a i T − 1 i T b i T ( o T ) P(O, I \mid \lambda)=P(I \mid \lambda) P(O \mid I, \lambda)=\pi_{i_{1}} b_{i_{1}}\left(o_{1}\right) a_{i_{1} i_{2}} b_{i_{2}}\left(o_{2}\right) \ldots a_{i_{T-1}} \quad i_{T} b_{i_{T}}\left(o_{T}\right) P(O,I∣λ)=P(I∣λ)P(O∣I,λ)=πi1bi1(o1)ai1i2bi2(o2)…aiT−1iTbiT(oT)
然后求边缘概率分布,即可得到观测序列 O O O在模型 λ \lambda λ下出现的条件概率 P ( O ∣ λ ) P(O \mid \lambda) P(O∣λ):
P ( O ∣ λ ) = ∑ I P ( O , I ∣ λ ) = ∑ i 1 , i 2 , … , i T π i 1 b i 1 ( o 1 ) a i 1 i 2 b i 2 ( o 2 ) … a i T − 1 i T b i T ( o T ) P(O \mid \lambda)=\sum_{I} P(O, I \mid \lambda)=\sum_{i_{1}, i_{2}, \ldots, i_{T}} \pi_{i_{1}} b_{i_{1}}\left(o_{1}\right) a_{i_{1} i_{2}} b_{i_{2}}\left(o_{2}\right) \ldots a_{i_{T-1}} i_{T} b_{i_{T}}\left(o_{T}\right) P(O∣λ)=I∑P(O,I∣λ)=i1,i2,…,iT∑πi1bi1(o1)ai1i2bi2(o2)…aiT−1iTbiT(oT)
虽然上述方法有效,但是如果我们的隐藏状态数 N N N非常多的那就麻烦了,此时我们预测状态有 N T N^{T} NT种组合,算法的时间复杂度是 O ( T N T ) O(TN^{T}) O(TNT)阶的。
因此对于一些隐藏状态数极少的模型,我们可以用暴力求解法来得到观测序列出现的概率,但是如果隐藏状态多,则上述算法太耗时,我们需要寻找其他简洁的算法。
前向后向算法就是来帮助我们在较低的时间复杂度情况下求解这个问题的。
用前向算法求HMM观测序列的概率
前向后向算法是前向算法和后向算法的统称,这两个算法都可以用来求HMM观测序列的概率。我们先来看看前向算法是如何求解这个问题的。
前向算法本质上属于动态规划的算法,也就是我们要通过找到局部状态递推的公式,这样一步步的从子问题的最优解拓展到整个问题的最优解。
在前向算法中,通过定义“前向概率”来定义动态规划的这个局部状态。什么是前向概率呢, 其实定义很简单:定义时刻 t t t时隐藏状态为 q i q_{i} qi, 观测状态的序列为 O 1 , O 2 , … , O t O_{1}, O_{2}, \ldots, O_{t} O1,O2,…,Ot的概率为前向概率。记为:
α t ( i ) = P ( o 1 , o 2 , … o t , i t = q i ∣ λ ) \alpha_{t}(i)=P\left(o_{1}, o_{2}, \ldots o_{t}, i_{t}=q_{i} \mid \lambda\right) αt(i)=P(o1,o2,…ot,it=qi∣λ)
既然是动态规划,我们就要递推了,现在我们假设我们已经找到了在时刻 t t t时各个隐藏状态的前向概率,现在我们需要递推出时刻 t + 1 t+1 t+1时各个隐藏状态的前向概率。
从下图可以看出,我们可以基于时刻 t t t时各个隐藏状态的前向概率,再乘以对应的状态转移概率,即 α t ( j ) a j i \alpha_{t}(j) a_{j i} αt(j)aji就是在时刻 t t t观测到 O 1 , O 2 , … , O t O_{1}, O_{2}, \ldots, O_{t} O1,O2,…,Ot,并且时刻 t t t隐藏状态 q j q_{j} qj, 时刻 t + 1 t+1 t+1隐藏状态 q i q_{i} qi的概率。
如果将想下面所有的线对应的概率求和,即 ∑ i = 1 N α t ( j ) a j i \sum_{i=1}^{N} \alpha_{t}(j) a_{j i} ∑i=1Nαt(j)aji就是在时刻 t t t观测到 O 1 , O 2 , … , O t O_{1}, O_{2}, \ldots, O_{t} O1,O2,…,Ot,并且时刻 t + 1 t+1 t+1隐藏状态 q i q_{i} qi的概率。继续一步,由于观测状态 o t + 1 o_{t+1} ot+1只依赖于 t + 1 t+1 t+1时刻隐藏状态 q i q_{i} qi, 这样 [ ∑ j = 1 N α t ( j ) a j i ] b i ( o t + 1 ) \left[\sum_{j=1}^{N} \alpha_{t}(j) a_{j i}\right] b_{i}\left(o_{t+1}\right) [∑j=1Nαt(j)aji]bi(ot+1)就是在在时刻 t + 1 t+1 t+1观测到 O 1 , O 2 , … , O t , O t + 1 O_{1}, O_{2}, \ldots, O_{t},O_{t+1} O1,O2,…,Ot,Ot+1,并且时刻 t + 1 t+1 t+1隐藏状态 q i q_{i} qi的概率。而这个概率,恰恰就是时刻 t + 1 t+1 t+1对应的隐藏状态的前向概率,这样我们得到了前向概率的递推关系式如下:
α t + 1 ( i ) = [ ∑ j = 1 N α t ( j ) a j i ] b i ( o t + 1 ) \alpha_{t+1}(i) = \Big[\sum\limits_{j=1}^N\alpha_t(j)a_{ji}\Big]b_i(o_{t+1}) αt+1(i)=[j=1∑Nαt(j)aji]bi(ot+1)
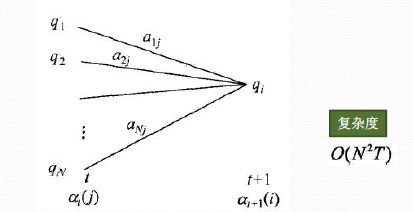
我们的动态规划从时刻1开始,到时刻 T T T结束,由于 α T ( i ) \alpha_T(i) αT(i)表示在时刻观测序列为 o 1 , o 2 , . . . o T o_1,o_2,...o_T o1,o2,...oT,并且时刻 T T T隐藏状态 q i q_{i} qi的概率,我们只要将所有隐藏状态对应的概率相加,即 ∑ i = 1 N α T ( i ) \sum\limits_{i=1}^N\alpha_T(i) i=1∑NαT(i)就得到了在时刻 T T T观测序列为 o 1 , o 2 , . . . o T o_1,o_2,...o_T o1,o2,...oT的概率。
下面总结下前向算法。
输入:HMM模型=(,,Π),观测序列 O = ( o 1 , o 2 , . . . o T ) O=(o_1,o_2,...o_T) O=(o1,o2,...oT)
输出:观测序列概率(|)
- 计算时刻1的各个隐藏状态前向概率:
α 1 ( i ) = π i b i ( o 1 ) , i = 1 , 2 , . . . N \alpha_1(i) = \pi_ib_i(o_1),\; i=1,2,...N α1(i)=πibi(o1),i=1,2,...N - 递推时刻2,3,…时刻的前向概率:
α t + 1 ( i ) = [ ∑ j = 1 N α t ( j ) a j i ] b i ( o t + 1 ) , i = 1 , 2 , . . . N \alpha_{t+1}(i) = \Big[\sum\limits_{j=1}^N\alpha_t(j)a_{ji}\Big]b_i(o_{t+1}),\; i=1,2,...N αt+1(i)=[j=1∑Nαt(j)aji]bi(ot+1),i=1,2,...N - 计算最终结果:
P ( O ∣ λ ) = ∑ i = 1 N α T ( i ) P(O|\lambda) = \sum\limits_{i=1}^N\alpha_T(i) P(O∣λ)=i=1∑NαT(i)
从递推公式可以看出,我们的算法时间复杂度是 O ( T N 2 ) O(TN^2) O(TN2),比暴力解法的时间复杂度 O ( T N T ) O(TN^T) O(TNT)少了几个数量级。
HMM前向算法求解实例
这里我们用上面HMM模型中盒子与球的例子来显示前向概率的计算。
我们的观察集合是:
V = { 红 , 白 } , M = 2 V=\{红,白\},M=2 V={红,白},M=2
我们的状态集合是:
Q = { 盒 子 1 , 盒 子 2 , 盒 子 3 } , N = 3 Q =\{盒子1,盒子2,盒子3\}, N=3 Q={盒子1,盒子2,盒子3},N=3
而观察序列和状态序列的长度为3.
初始状态分布为:
Π = ( 0.2 , 0.4 , 0.4 ) T \Pi = (0.2,0.4,0.4)^T Π=(0.2,0.4,0.4)T
状态转移概率分布矩阵为:
A = ( 0.5 0.2 0.3 0.3 0.5 0.2 0.2 0.3 0.5 ) A = \left( \begin{array} {ccc} 0.5 & 0.2 & 0.3 \\ 0.3 & 0.5 & 0.2 \\ 0.2 & 0.3 &0.5 \end{array} \right) A=⎝⎛0.50.30.20.20.50.30.30.20.5⎠⎞
观测状态概率矩阵为:
B = ( 0.5 0.5 0.4 0.6 0.7 0.3 ) B = \left( \begin{array} {ccc} 0.5 & 0.5 \\ 0.4 & 0.6 \\ 0.7 & 0.3 \end{array} \right) B=⎝⎛0.50.40.70.50.60.3⎠⎞
球的颜色的观测序列:
O = { 红 , 白 , 红 } O=\{红,白,红\} O={红,白,红}
按照我们上一节的前向算法。
首先计算时刻1三个状态的前向概率:
-
时刻1是红色球,隐藏状态是盒子1的概率为:
α 1 ( 1 ) = π 1 b 1 ( o 1 ) = 0.2 × 0.5 = 0.1 \alpha_1(1) = \pi_1b_1(o_1) = 0.2 \times 0.5 = 0.1 α1(1)=π1b1(o1)=0.2×0.5=0.1 -
隐藏状态是盒子2的概率为:
α 1 ( 2 ) = π 2 b 2 ( o 1 ) = 0.4 × 0.4 = 0.16 \alpha_1(2) = \pi_2b_2(o_1) = 0.4 \times 0.4 = 0.16 α1(2)=π2b2(o1)=0.4×0.4=0.16 -
隐藏状态是盒子3的概率为:
α 1 ( 3 ) = π 3 b 3 ( o 1 ) = 0.4 × 0.7 = 0.28 \alpha_1(3) = \pi_3b_3(o_1) = 0.4 \times 0.7 = 0.28 α1(3)=π3b3(o1)=0.4×0.7=0.28
现在我们可以开始递推了,首先递推时刻2三个状态的前向概率:
- 时刻2是白色球,隐藏状态是盒子1的概率为:
α 2 ( 1 ) = [ ∑ i = 1 3 α 1 ( i ) a i 1 ] b 1 ( o 2 ) = [ 0.1 ∗ 0.5 + 0.16 ∗ 0.3 + 0.28 ∗ 0.2 ] × 0.5 = 0.077 \alpha_2(1) = \Big[\sum\limits_{i=1}^3\alpha_1(i)a_{i1}\Big]b_1(o_2) = [0.1*0.5+0.16*0.3+0.28*0.2 ] \times 0.5 = 0.077 α2(1)=[i=1∑3α1(i)ai1]b1(o2)=[0.1∗0.5+0.16∗0.3+0.28∗0.2]×0.5=0.077 - 隐藏状态是盒子2的概率为:
α 2 ( 2 ) = [ ∑ i = 1 3 α 1 ( i ) a i 2 ] b 2 ( o 2 ) = [ 0.1 ∗ 0.2 + 0.16 ∗ 0.5 + 0.28 ∗ 0.3 ] × 0.6 = 0.1104 \alpha_2(2) = \Big[\sum\limits_{i=1}^3\alpha_1(i)a_{i2}\Big]b_2(o_2) = [0.1*0.2+0.16*0.5+0.28*0.3 ] \times 0.6 = 0.1104 α2(2)=[i=1∑3α1(i)ai2]b2(o2)=[0.1∗0.2+0.16∗0.5+0.28∗0.3]×0.6=0.1104 - 隐藏状态是盒子3的概率为:
α 2 ( 3 ) = [ ∑ i = 1 3 α 1 ( i ) a i 3 ] b 3 ( o 2 ) = [ 0.1 ∗ 0.3 + 0.16 ∗ 0.2 + 0.28 ∗ 0.5 ] × 0.3 = 0.0606 \alpha_2(3) = \Big[\sum\limits_{i=1}^3\alpha_1(i)a_{i3}\Big]b_3(o_2) = [0.1*0.3+0.16*0.2+0.28*0.5 ] \times 0.3 = 0.0606 α2(3)=[i=1∑3α1(i)ai3]b3(o2)=[0.1∗0.3+0.16∗0.2+0.28∗0.5]×0.3=0.0606
继续递推,现在我们递推时刻3三个状态的前向概率:
- 时刻3是红色球,隐藏状态是盒子1的概率为:
α 3 ( 1 ) = [ ∑ i = 1 3 α 2 ( i ) a i 1 ] b 1 ( o 3 ) = [ 0.077 ∗ 0.5 + 0.1104 ∗ 0.3 + 0.0606 ∗ 0.2 ] × 0.5 = 0.04187 \alpha_3(1) = \Big[\sum\limits_{i=1}^3\alpha_2(i)a_{i1}\Big]b_1(o_3) = [0.077*0.5+0.1104*0.3+0.0606*0.2 ] \times 0.5 = 0.04187 α3(1)=[i=1∑3α2(i)ai1]b1(o3)=[0.077∗0.5+0.1104∗0.3+0.0606∗0.2]×0.5=0.04187 - 隐藏状态是盒子2的概率为:
α 3 ( 2 ) = [ ∑ i = 1 3 α 2 ( i ) a i 2 ] b 2 ( o 3 ) = [ 0.077 ∗ 0.2 + 0.1104 ∗ 0.5 + 0.0606 ∗ 0.3 ] × 0.4 = 0.03551 \alpha_3(2) = \Big[\sum\limits_{i=1}^3\alpha_2(i)a_{i2}\Big]b_2(o_3) = [0.077*0.2+0.1104*0.5+0.0606*0.3 ] \times 0.4 = 0.03551 α3(2)=[i=1∑3α2(i)ai2]b2(o3)=[0.077∗0.2+0.1104∗0.5+0.0606∗0.3]×0.4=0.03551 - 隐藏状态是盒子3的概率为:
α 3 ( 3 ) = [ ∑ i = 1 3 α 2 ( i ) a i 3 ] b 3 ( o 3 ) = [ 0.077 ∗ 0.3 + 0.1104 ∗ 0.2 + 0.0606 ∗ 0.5 ] × 0.7 = 0.05284 \alpha_3(3) = \Big[\sum\limits_{i=1}^3\alpha_2(i)a_{i3}\Big]b_3(o_3) = [0.077*0.3+0.1104*0.2+0.0606*0.5 ] \times 0.7 = 0.05284 α3(3)=[i=1∑3α2(i)ai3]b3(o3)=[0.077∗0.3+0.1104∗0.2+0.0606∗0.5]×0.7=0.05284
最终我们求出观测序列:={红,白,红}的概率为:
P ( O ∣ λ ) = ∑ i = 1 3 α 3 ( i ) = 0.13022 , P(O|\lambda) = \sum\limits_{i=1}^3\alpha_3(i) = 0.13022, P(O∣λ)=i=1∑3α3(i)=0.13022,
用后向算法求HMM观测序列的概率
熟悉了用前向算法求HMM观测序列的概率,现在我们再来看看怎么用后向算法求HMM观测序列的概率。
后向算法和前向算法非常类似,都是用的动态规划,唯一的区别是选择的局部状态不同,后向算法用的是“后向概率”,那么后向概率是如何定义的呢?
定义时刻 t t t时隐藏状态为 q i q_{i} qi, 从时刻 t + 1 t+1 t+1到最后时刻 T T T的观测状态的序列为 o t + 1 , o t + 2 , . . . o T o_{t+1},o_{t+2},...o_T ot+1,ot+2,...oT的概率为后向概率。记为:
β t ( i ) = P ( o t + 1 , o t + 2 , . . . o T ∣ i t = q i , λ ) \beta_t(i) = P(o_{t+1},o_{t+2},...o_T| i_t =q_i , \lambda) βt(i)=P(ot+1,ot+2,...oT∣it=qi,λ)
后向概率的动态规划递推公式和前向概率是相反的。现在我们假设我们已经找到了在时刻 t + 1 t+1 t+1时各个隐藏状态的后向概率 β t + 1 ( j ) \beta_{t+1}(j) βt+1(j),现在我们需要递推出时刻 t t t时各个隐藏状态的后向概率。
如下图,我们可以计算出观测状态的序列为 o t + 2 , o t + 3 , . . . o T o_{t+2},o_{t+3},...o_T ot+2,ot+3,...oT, t t t时隐藏状态为 q i q_{i} qi, 时刻 t + 1 t+1 t+1隐藏状态为 q j q_{j} qj的概率为 a i j β t + 1 ( j ) a_{ij}\beta_{t+1}(j) aijβt+1(j), 接着可以得到观测状态的序列为 o t + 1 , o t + 2 , . . . o T o_{t+1},o_{t+2},...o_T ot+1,ot+2,...oT, t t t时隐藏状态为 q i q_{i} qi, 时刻 t + 1 t+1 t+1隐藏状态为 q j q_{j} qj的概率为 a i j b j ( o t + 1 ) β t + 1 ( j ) a_{ij}b_j(o_{t+1})\beta_{t+1}(j) aijbj(ot+1)βt+1(j), 则把下面所有线对应的概率加起来,我们可以得到观测状态的序列为 o t + 1 , o t + 2 , . . . o T o_{t+1},o_{t+2},...o_T ot+1,ot+2,...oT, t t t时隐藏状态为 q i q_{i} qi的概率为 ∑ j = 1 N a i j b j ( o t + 1 ) β t + 1 ( j ) \sum\limits_{j=1}^{N}a_{ij}b_j(o_{t+1})\beta_{t+1}(j) j=1∑Naijbj(ot+1)βt+1(j),这个概率即为时刻 t t t的后向概率。
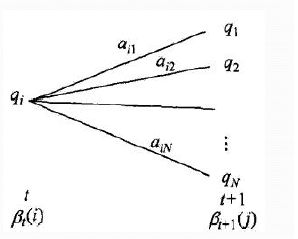
这样我们得到了后向概率的递推关系式如下:
β t ( i ) = ∑ j = 1 N a i j b j ( o t + 1 ) β t + 1 ( j ) \beta_{t}(i) = \sum\limits_{j=1}^{N}a_{ij}b_j(o_{t+1})\beta_{t+1}(j) βt(i)=j=1∑Naijbj(ot+1)βt+1(j)
现在我们总结下后向算法的流程,注意下和前向算法的相同点和不同点:
- 输入:HMM模型 λ = ( A , B , Π ) \lambda = (A, B, \Pi) λ=(A,B,Π),观测序列 O = ( o 1 , o 2 , . . . o T ) O=(o_1,o_2,...o_T) O=(o1,o2,...oT)
- 输出:观测序列概率 P ( O ∣ λ ) P(O|\lambda) P(O∣λ)
- 1.初始化时刻 T T T的各个隐藏状态后向概率:
β T ( i ) = 1 , i = 1 , 2 , . . . N \beta_T(i) = 1,\; i=1,2,...N βT(i)=1,i=1,2,...N - 2.递推时刻 T − 1 , T − 2 , . . . 1 T-1,T-2,...1 T−1,T−2,...1时刻的后向概率:
β t ( i ) = ∑ j = 1 N a i j b j ( o t + 1 ) β t + 1 ( j ) , i = 1 , 2 , . . . N \beta_{t}(i) = \sum\limits_{j=1}^{N}a_{ij}b_j(o_{t+1})\beta_{t+1}(j),\; i=1,2,...N βt(i)=j=1∑Naijbj(ot+1)βt+1(j),i=1,2,...N - 3.计算最终结果:
P ( O ∣ λ ) = ∑ i = 1 N π i b i ( o 1 ) β 1 ( i ) P(O|\lambda) = \sum\limits_{i=1}^N\pi_ib_i(o_1)\beta_1(i) P(O∣λ)=i=1∑Nπibi(o1)β1(i)
此时我们的算法时间复杂度仍然是 O ( T N 2 ) O(TN^2) O(TN2)。
HMM常用概率的计算
利用前向概率和后向概率,我们可以计算出HMM中单个状态和两个状态的概率公式。
1)给定模型 λ \lambda λ和观测序列 O O O在时刻 t t t处于状态 q i q_{i} qi的概率记为:
γ t ( i ) = P ( i t = q i ∣ O , λ ) = P ( i t = q i , O ∣ λ ) P ( O ∣ λ ) \gamma_t(i) = P(i_t = q_i | O,\lambda) = \frac{P(i_t = q_i ,O|\lambda)}{P(O|\lambda)} γt(i)=P(it=qi∣O,λ)=P(O∣λ)P(it=qi,O∣λ)
利用前向概率和后向概率的定义可知:
P ( i t = q i , O ∣ λ ) = α t ( i ) β t ( i ) P(i_t = q_i ,O|\lambda) = \alpha_t(i)\beta_t(i) P(it=qi,O∣λ)=αt(i)βt(i)
于是我们得到:
γ t ( i ) = α t ( i ) β t ( i ) ∑ j = 1 N α t ( j ) β t ( j ) \gamma_t(i) = \frac{ \alpha_t(i)\beta_t(i)}{\sum\limits_{j=1}^N \alpha_t(j)\beta_t(j)} γt(i)=j=1∑Nαt(j)βt(j)αt(i)βt(i)
2)给定模型 λ \lambda λ和观测序列 O O O,在时刻 t t t处于状态 q i q_{i} qi,且时刻 t + 1 t+1 t+1处于状态 q j q_{j} qj的概率记为:
ξ t ( i , j ) = P ( i t = q i , i t + 1 = q j ∣ O , λ ) = P ( i t = q i , i t + 1 = q j , O ∣ λ ) P ( O ∣ λ ) \xi_t(i,j) = P(i_t = q_i, i_{t+1}=q_j | O,\lambda) = \frac{ P(i_t = q_i, i_{t+1}=q_j , O|\lambda)}{P(O|\lambda)} ξt(i,j)=P(it=qi,it+1=qj∣O,λ)=P(O∣λ)P(it=qi,it+1=qj,O∣λ)
而 P ( i t = q i , i t + 1 = q j , O ∣ λ ) P(i_t = q_i, i_{t+1}=q_j , O|\lambda) P(it=qi,it+1=qj,O∣λ)可以由前向后向概率来表示为:
P ( i t = q i , i t + 1 = q j , O ∣ λ ) = α t ( i ) a i j b j ( o t + 1 ) β t + 1 ( j ) P(i_t = q_i, i_{t+1}=q_j , O|\lambda) = \alpha_t(i)a_{ij}b_j(o_{t+1})\beta_{t+1}(j) P(it=qi,it+1=qj,O∣λ)=αt(i)aijbj(ot+1)βt+1(j)
从而最终我们得到 ξ t ( i , j ) \xi_t(i,j) ξt(i,j)的表达式如下:
ξ t ( i , j ) = α t ( i ) a i j b j ( o t + 1 ) β t + 1 ( j ) ∑ r = 1 N ∑ s = 1 N α t ( r ) a r s b s ( o t + 1 ) β t + 1 ( s ) \xi_t(i,j) = \frac{\alpha_t(i)a_{ij}b_j(o_{t+1})\beta_{t+1}(j)}{\sum\limits_{r=1}^N\sum\limits_{s=1}^N\alpha_t(r)a_{rs}b_s(o_{t+1})\beta_{t+1}(s)} ξt(i,j)=r=1∑Ns=1∑Nαt(r)arsbs(ot+1)βt+1(s)αt(i)aijbj(ot+1)βt+1(j)
3) 将 γ t ( i ) \gamma_t(i) γt(i)和 ξ t ( i , j ) \xi_t(i,j) ξt(i,j)在各个时刻 t t t求和,可以得到:
在观测序列 O O O下状态 i i i出现的期望值 ∑ t = 1 T γ t ( i ) \sum\limits_{t=1}^T\gamma_t(i) t=1∑Tγt(i)
在观测序列 O O O下由状态 i i i转移的期望值 ∑ t = 1 T − 1 γ t ( i ) \sum\limits_{t=1}^{T-1}\gamma_t(i) t=1∑T−1γt(i)
在观测序列 O O O下由状态 i i i转移到状态 j j j的期望值 ∑ t = 1 T − 1 ξ t ( i , j ) \sum\limits_{t=1}^{T-1}\xi_t(i,j) t=1∑T−1ξt(i,j)
上面这些常用的概率值在求解HMM问题二,即求解HMM模型参数的时候需要用到。
接下来我们会讨论HMM模型参数求解的问题,这个问题在HMM三个问题里算是最复杂的。在李航的《统计学习方法》中,这个算法的讲解只考虑了单个感测序列的求解,因此无法用于实际多样本观测序列的模型求解,本文关注于如何使用多个观测序列来求解HMM模型参数。
HMM模型参数求解概述
HMM模型参数求解根据已知的条件可以分为两种情况。
第一种情况较为简单,就是我们已知 D D D个长度为 T T T的观测序列和对应的隐藏状态序列,即 { ( O 1 , I 1 ) , ( O 2 , I 2 ) , . . . ( O D , I D ) } \{(O_1, I_1), (O_2, I_2), ...(O_D, I_D)\} {(O1,I1),(O2,I2),...(OD,ID)}是已知的,此时我们可以很容易的用最大似然来求解模型参数。
假设样本从隐藏状态 q i q_{i} qi转移到 q j q_{j} qj的频率计数是 A i j A_{ij} Aij,那么状态转移矩阵求得为:
A = [ a i j ] , 其 中 a i j = A i j ∑ s = 1 N A i s A = \Big[a_{ij}\Big], \;其中a_{ij} = \frac{A_{ij}}{\sum\limits_{s=1}^{N}A_{is}} A=[aij],其中aij=s=1∑NAisAij
假设样本隐藏状态为 q j q_{j} qj且观测状态为 v k v_{k} vk的频率计数是 B j k B_{jk} Bjk,那么观测状态概率矩阵为:
B = [ b j ( k ) ] , 其 中 b j ( k ) = B j k ∑ s = 1 M B j s B= \Big[b_{j}(k)\Big], \;其中b_{j}(k) = \frac{B_{jk}}{\sum\limits_{s=1}^{M}B_{js}} B=[bj(k)],其中bj(k)=s=1∑MBjsBjk
假设所有样本中初始隐藏状态为 q i q_{i} qi的频率计数为 C i C_{i} Ci,那么初始概率分布为:
Π = π ( i ) = C ( i ) ∑ s = 1 N C ( s ) \Pi = \pi(i) = \frac{C(i)}{\sum\limits_{s=1}^{N}C(s)} Π=π(i)=s=1∑NC(s)C(i)
可见第一种情况下求解模型还是很简单的。但是在很多时候,我们无法得到HMM样本观察序列对应的隐藏序列,只有 D D D个长度为 T T T的观测序列,即 { ( O 1 ) , ( O 2 ) , . . . ( O D ) } \{(O_1), (O_2), ...(O_D)\} {(O1),(O2),...(OD)}是已知的,此时我们能不能求出合适的HMM模型参数呢?
这就是我们的第二种情况,也是我们本文要讨论的重点。
它的解法最常用的是鲍姆-韦尔奇算法,其实就是基于EM算法的求解,只不过鲍姆-韦尔奇算法出现的时代,EM算法还没有被抽象出来,所以我们本文还是说鲍姆-韦尔奇算法。
下面我们先举一个例子对鲍姆-韦尔奇算法进行介绍。
详细例子介绍姆-韦尔奇算法Baum–Welch algorithm
下面将以“抓捕行动”这个故事的形式,详解介绍鲍姆-韦尔奇算法Baum–Welch algorithm
臭名昭著的犯罪团伙落脚在一个小镇上,负隅顽抗着。此犯罪团伙的反侦查意识极强,武警部长再也坐不下去了,每让这个犯罪团伙多存在一天,就多一份对公民的威胁。于是你以特派专家的身份,被武警部长邀请去计划搜捕行动。
武警部长告诉你,犯罪团伙的每天的防卫状态,只可能是“防卫严密”或“防卫松懈”两种状态一种,而且今天的防卫状态只和昨天的防卫状态相关。即如果今天“防卫严密”的话,明天有一定的概率“防卫松懈”。

武警部长对你说:”组织抓捕,当然是要在防卫松懈时去抓捕了,但问题在于,并不容易知道他们究竟什么时候会防卫松懈。也不知道今天防卫严密后,明天防卫松懈的概率。如果知道了将容易很多”,说完,拿出来一份文件。

作为特派专家,你似乎意识到什么,于是询问部长:“你们虽然不能直接知道他们的防卫状态,但你们每天都会密切观察他们的举动,有什么别的信息呢?”
武警部长答道:“这倒是有一些。比如我已经排了专人去监视那个犯罪团体的活跃状况。大致可以分为“活跃”和“不活跃”。活跃的时候人来人往,车流量很大,不活跃则几乎没人进出他们的老巢。我们发现他们的活跃状态和防卫状态有一定关系,但又没法确定。”
你狡黠地一笑:“这就好办了。”
你找来一张纸,写下了如下的关系
- 我们知道犯罪团伙每天的活跃的状态,即可见层
- 我们知道犯罪团伙每天的防卫状态一共有哪些
- 我们不知道今天的防卫状态与昨天的防卫状态关系是怎样的。即不知道隐藏层的转移关系
- 我们不知道每天的防卫状态是怎样的,即不知道隐藏层
- 我们也不知道每天的防卫状态,与活跃状态之间的关系,即由隐藏层某个元素可以推出可见层某个元素的概率,即表现(emission)概率。
你说:“现在不知道,并不代表以后也不可能知道,所以我们现在要大胆尝试。”
武警部长说:“说人话。”
你道:“好啦,就是不知道的猜一遍。虽然猜的并不准确,但有办法让它逐渐符合实际。”
假设昨天的防卫状态与今天的防卫状态的关系是,即如下表格 A A A
| 假设的隐藏层状态转移 | 今天防卫严密 | 今天防卫松懈 |
|---|---|---|
| 昨天防卫严密 | 0.5 | 0.5 |
| 昨天防卫松懈 | 0.3 | 0.7 |
或者是
设 x t x_{t} xt是隐藏层的某个时间的状态,并且从状态 x t − 1 x_{t-1} xt−1转移到状态 x t x_{t} xt的概率 P ( x t ∣ x t − 1 ) P\left(x_{t} \mid x_{t-1}\right) P(xt∣xt−1)与时间 t t t无关。于是就有状态转移方程
A = { a i j } = P ( x t = j ∣ x t − 1 = i ) A=\left\{a_{i j}\right\}=P\left(x_{t}=j \mid x_{t-1}=i\right) A={aij}=P(xt=j∣xt−1=i)
设某一天为初始状态,假设那天犯罪团体防卫严密的概率是0.2,防卫松懈的概率是0.8即如下表格 π \pi π
| 初始状态 | 概率 |
|---|---|
| 防卫严密 | 0.2 |
| 防卫松懈 | 0.8 |
或者
初始状态为:
π i = P ( X 1 = i ) \pi_{i}=P\left(X_{1}=i\right) πi=P(X1=i)
再假设防卫的状态到活跃状态的表现关系,比如今天 防卫 严密,则活跃的概率是0.3。得到表格 B B B
| 假设的表现关系 | 活跃 | 不活跃 |
|---|---|---|
| 防卫严密 | 0.3 | 0.7 |
| 防卫松懈 | 0.8 | 0.2 |
可见层的元素 Y t Y_{t} Yt可能有 k k k个不同的值。那么由可见层在时间 t t t的某个元素 y i y_{i} yi可以推出隐藏层某个元素 j j j的概率是
b j ( y i ) = P ( Y t = y i ∣ X t = j ) b_{j}\left(y_{i}\right)=P\left(Y_{t}=y_{i} \mid X_{t}=j\right) bj(yi)=P(Yt=yi∣Xt=j)
至此,准备工作已经完成了。然后你把这三张表放在一起,并装入一个文件袋θ里

武警部长道:“我还是看不出你接下来会怎么做。”
你不慌不忙地起身热了两壶茶,又坐下对部长说道:“部长,最近观察到的那犯罪团伙的活跃状态是怎么样的?”
部长又拿出一份报告,这是上个星期对那个犯罪团伙的观察情况。
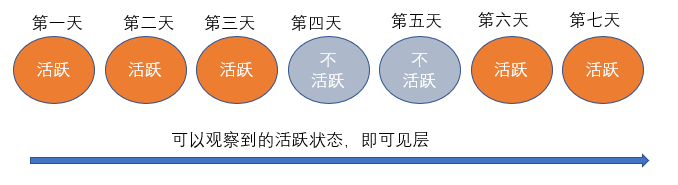
于是你说:“这是真实观察到的结果,我们就叫他“结果 X X X”好了。不同的犯罪团伙的防卫状态和转移概率以及表现矩阵,也就是有不同的表格 A A A, B B B, π π π,也就是不同的文件档案 θ θ θ。不同的文件档案 θ θ θ,代表着可能观测到的不同结果。”

“我们现在确实不知道文件档案里的内容和数据应该是什么。但肯定有某个我们期待得到的文件档案 θ θ θ,记录了那犯罪团伙的准确信息,并且会导致“结果 X X X的出现概率最大,让我们有很大机会碰上“结果 X X X”。这样就符合了我们所观察的实际情况。毕竟在我们看来,我们确实观察到的“结果 X X X””
部长若有所思,说“嗯,这个方法太精彩了。只是我以前好像在哪儿见到过类似的东西?”
你道:“部长应该了解过概率论,这个思想和似然是一样的,都是不知道概率,只知道结果,而要从结果反推出概率。”
部长把茶给你和他斟上,接着问道:“那么接下来应该怎么办呢?”
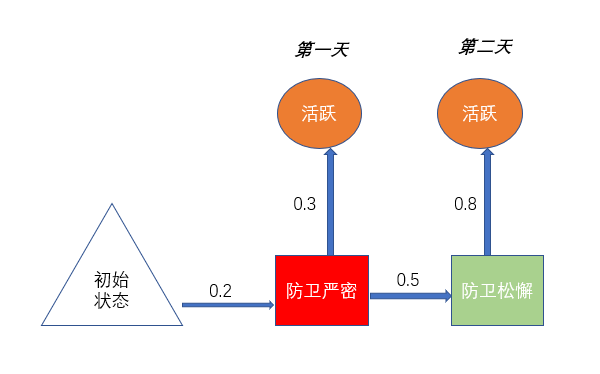
用两天的数据更新表格A
你道:“例如想更新表格A上的内容,比如知第一天为“防卫严密”到第二天为“ 防卫 松懈”的转移概率,并且要符合实际观察到的情况,即第一天活跃,第二天活跃。我们来计算这种情况的出现概率。
你拿出文件袋θ,计算到:
- 1.根据表格 π π π,第一天为“防卫严密”的概率为0.2
- 2.根据表格 B B B,第一天为“ 防卫严密”,则第一天为“活跃”的概率为0.3
- 3.根据表格 A A A,第一天为“ 防卫 严密”,第二天为“ 防卫松懈”的概率为0.5
- 4.根据表格 B B B,第二天为“防卫松懈”,第二天为“ 活跃”的概率为0.8
- 5.相乘得到新的,第一天为“ 活跃”并且第二天为“ 活跃”这种情况的概率是0.024
0.20.30.5*0.8=0.024
根据原猜测结果,计算符合实际(第一天活跃,第二天活跃)的转移概率,即计算
ξ i j ( t ) = P ( X t = i , X t ⊣ 1 = j ∣ Y , θ ) = P ( X t = i , X t + 1 = j , Y ∣ θ ) P ( Y ∣ θ ) = α i ( t ) a i j β j ( t + 1 ) b j ( y t + 1 ) ∑ i = 1 N ∑ j = 1 N α i ( t ) a i j β j ( t + 1 ) b j ( y t + 1 ) \xi_{i j}(t)=P\left(X_{t}=i, X_{t \dashv 1}=j \mid Y, \theta\right)=\frac{P\left(X_{t}=i, X_{t+1}=j, Y \mid \theta\right)}{P(Y \mid \theta)}=\frac{\alpha_{i}(t) a_{i j} \beta_{j}(t+1) b_{j}\left(y_{t+1}\right)}{\sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i}(t) a_{i j} \beta_{j}(t+1) b_{j}\left(y_{t+1}\right)} ξij(t)=P(Xt=i,Xt⊣1=j∣Y,θ)=P(Y∣θ)P(Xt=i,Xt+1=j,Y∣θ)=∑i=1N∑j=1Nαi(t)aijβj(t+1)bj(yt+1)αi(t)aijβj(t+1)bj(yt+1)
同样可得

部长道:“按照我们观察到的真实结果 X X X,和猜测的文件档案 θ θ θ,对于这四种情况,显然第四种情况,即第一天“防卫松懈“第二天也”防卫松懈”的概率最高,最有可能发生啊。”
你道:“对,但那并不代表另外三种情况不可能发生。若是让第一种情况除以第四种情况,就得到了从第一天“防卫严密”到第二天“防卫松懈”的新转移概率,
0.0240/0.3584 = 0.6696
在归一化后,要比我们之前的推测更加符合我们的观察。
新的隐藏层状态转移
| 新的隐藏层状态转移(未归一化) | 今天防卫严密 | 今天防卫松懈 |
|---|---|---|
| 昨天防卫严密 | 0.1785 | 0.0446 |
| 昨天防卫松懈 | 0.1607 | 1 |
归一化后,就是根据我们所观察到的结果 X X X的一部分,即第一天活跃,第二天活跃所计算出的,比之前推测更加靠谱的表格 A A A。也就是说,在更新表格 A A A后,文件档案 θ θ θ所代表的的犯罪团伙的信息,会让“第一天活跃第二天活跃”这种情况出现的概率更加增大。
新的隐藏层状态转移
| 新的隐藏层状态转移(归一化后) | 今天防卫严密 | 今天防卫松懈 |
|---|---|---|
| 昨天防卫严密 | 0.8000 | 0.2000 |
| 昨天防卫松懈 | 0.1385 | 0.8615 |
根据最有可能的隐藏层,计算隐藏层元素间转移概率比例就是计算下面的式子:
γ i ( t ) = P ( X t = i ∣ Y , θ ) = P ( X t = i , Y ∣ θ ) P ( Y ∣ θ ) = α i ( t ) β i ( t ) ∑ j = 1 N α j ( t ) β j ( t ) \gamma_{i}(t)=P\left(X_{t}=i \mid Y, \theta\right)=\frac{P\left(X_{t}=i, Y \mid \theta\right)}{P(Y \mid \theta)}=\frac{\alpha_{i}(t) \beta_{i}(t)}{\sum_{j=1}^{N} \alpha_{j}(t) \beta_{j}(t)} γi(t)=P(Xt=i∣Y,θ)=P(Y∣θ)P(Xt=i,Y∣θ)=∑j=1Nαj(t)βj(t)αi(t)βi(t)
更新表格 A A A的过程,就是计算下面的式子,即隐藏层状态转移关系
a i j ∗ = ∑ t = 1 T − 1 ξ i j ( t ) ∑ t = 1 T − 1 γ i ( t ) a_{i j}^{*}=\frac{\sum_{t=1}^{T-1} \xi_{i j}(t)}{\sum_{t=1}^{T-1} \gamma_{i}(t)} aij∗=∑t=1T−1γi(t)∑t=1T−1ξij(t)
部长拿起纸笔验算了一番:

“神了”,部长非常惊喜,“相比于我们之前的猜测,更新后的猜测更加符合实际,也就是说那些犯罪团伙的信息更加符合更新后的。”
你非常自豪,说道:“这还只是仅使用了两天的数据,如果把7天观测数据全部用上又如何呢?
完整的一遍更新流程
首先仍然是更新表格 A A A

然后根据原来的表格更新防卫状态的转换概率,下面是从“防卫严密”到“防卫松懈”的计算

- 新的 从“防卫严密”到“防卫松懈”的转移概率0.148/1.3482 = 0.1098。
- 新的 从“防卫严密”到“防卫严密”的转移概率0.118/1.3482 = 0.0875。
- 新的 从“防卫松懈”到“防卫严密”的转移概率0.3552/1.3482 = 0.2612。
- 新的 从“防卫松懈”到“防卫松懈”的转移概率1.2768/1.3482 = 0.9470。
归一化后得到新的表格 A A A
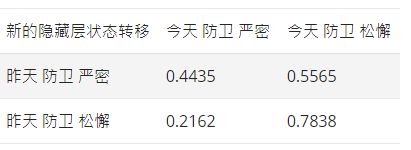
接下来更新,表格 B B B,首先更新由“防卫严密”表现出“不活跃”的概率

- 新的 从“防卫严密”到“活跃”的表现概率0.177/1.2992 = 0.1098。
- 新的 从“防卫严密”到“不活跃”的表现概率0.2394/0.2730 = 0.8749。
- 新的 从“防卫松懈”到“活跃”的表现概率1.2240/1.2992 = 0.9421。
- 新的 从“防卫松懈”到“不活跃”的表现概率0.376/0.2730 = 0.1370。
归一化后得到更新后的表格 B B B:

同理,更新表格 B B B即更新隐藏层到可见层的表现矩阵,即
b i ∗ ( v k ) = ∑ t = 1 T 1 y t = v k γ i ( t ) ∑ t = 1 T γ i ( t ) b_{i}^{*}\left(v_{k}\right)=\frac{\sum_{t=1}^{T} 1_{y_{t}=v_{k}} \gamma_{i}(t)}{\sum_{t=1}^{T} \gamma_{i}(t)} bi∗(vk)=∑t=1Tγi(t)∑t=1T1yt=vkγi(t)
其中
1 y i = v k = { 1 if y t = v k 0 otherwise \mathbf{1}_{y_{i}=v_{k}}=\left\{\begin{array}{ll} 1 & \text { if } y_{t}=v_{k} \\ 0 & \text { otherwise } \end{array}\right. 1yi=vk={10 if yt=vk otherwise
即,假设“不活跃”这个状态全部是由“防卫严密”导致的,那么我们在计算时只需要考虑那些包含着“不活跃”的两天连续观察,例如第三四天。而不包含的全部去掉,例如第一二天。
然后更新表 π π π

归一化后得:

更新表格 π π π,即更新第一天隐藏层的初始状态,即
∙ π i ∗ = γ i ( 1 ) \bullet \pi_{i}^{*}=\gamma_{i}(1) ∙πi∗=γi(1)
我们更新完了第一波表格 A A A, B B B, π π π,但这还不够,我们可能仍然有更合适的文件档案 θ θ θ等待我们去计算。于是我们就以这一次更新后的表格,作为下一次的起始表格,再更新一遍。如此循环下去,直到表格中的数据稳定下来,就得到了我们想要得到的文件档案 θ θ θ,这样的文件档案能够保证出现“结果 X X X”的概率最大。
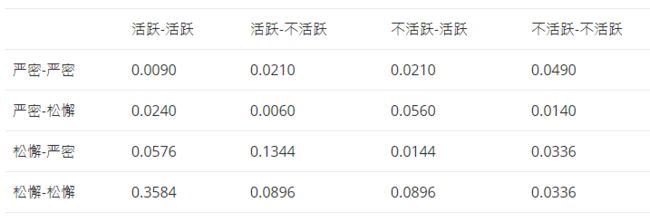
表格
为了方便各位计算,我把根据最开始所猜测的 θ θ θ对应的转换表格贴出,对应了所有可能的情况。表中数字加起来即为总概率1。第一行第一列意思为,如果第一天防守严密,第二天防守严密,那么第一天活跃且第二天活跃的概率
参考文献
- https://zhuanlan.zhihu.com/p/94480486
- https://www.cnblogs.com/pinard/p/6972299.html