XGB算法梳理
1CART树
CART全称为Classification And Regression Tree,分类和回归即是该算法的核心。分类算法在于生成决策树,CART为递归算法,总是将当前样本(not pure)分为两个子样本集,使得生成的每个非叶子节点都有两个分支,最终得到二叉树形式的决策树。
分类回归树是一棵二叉树,且每个非叶子节点都有两个孩子,所以对于第一棵子树其叶子节点数比非叶子节点数多1
分类树两个基本思想:第一个是将训练样本进行递归地划分自变量空间进行建树的想法,也就是当前用来分类的属性的选取;第二个想法是用验证数据进行剪枝。
算法流程:
以下是算法描述:其中T代表当前样本集,当前候选属性集用T_attributelist表示。
(1)创建根节点N
(2)为N分配类别
(3)if T都属于同一类别or T中只剩下一个样本则返回N为叶节点,为其分配属性
(4)for each T_attributelist中属性执行该属性上的一个划分,计算此划分的GINI系数
(5)N的测试属性test_attribute=T_attributelist中最小GINI系数的属性
(6)划分T得到T1 T2子集
(7)对于T1重复(1)-(6)
(8)对于T2重复(1)-(6)
参考:https://blog.csdn.net/xiaqunfeng123/article/details/34820095
2算法原理
既然xgboost就是一个监督模型,那么我们的第一个问题就是:xgboost对应的模型是什么?
答案就是一堆CART树。
此时,可能我们又有疑问了,CART树是什么?这个问题请查阅其他资料,我的博客中也有相关文章涉及过。然后,一堆树如何做预测呢?答案非常简单,就是将每棵树的预测值加到一起作为最终的预测值,可谓简单粗暴。
下图就是CART树和一堆CART树的示例,用来判断一个人是否会喜欢计算机游戏:
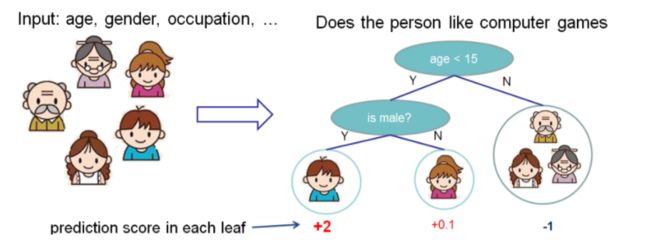
predict1.PNG

predict2.PNG
第二图的底部说明了如何用一堆CART树做预测,就是简单将各个树的预测分数相加。
xgboost为什么使用CART树而不是用普通的决策树呢?
简单讲,对于分类问题,由于CART树的叶子节点对应的值是一个实际的分数,而非一个确定的类别,这将有利于实现高效的优化算法。xgboost出名的原因一是准,二是快,之所以快,其中就有选用CART树的一份功劳。
知道了xgboost的模型,我们需要用数学来准确地表示这个模型,如下所示:
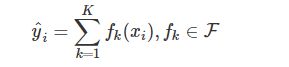
predict3.PNG
这里的K就是树的棵数,F表示所有可能的CART树,f表示一棵具体的CART树。这个模型由K棵CART树组成。模型表示出来后,我们自然而然就想问,这个模型的参数是什么?因为我们知道,“知识”蕴含在参数之中。第二,用来优化这些参数的目标函数又是什么?
我们先来看第二个问题,模型的目标函数,如下所示:
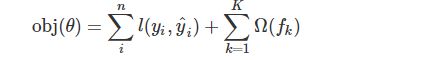
predict4.PNG
这个目标函数同样包含两部分,第一部分就是损失函数,第二部分就是正则项,这里的正则化项由K棵树的正则化项相加而来,你可能会好奇,一棵树的正则化项是什么?可暂时保持住你的好奇心,后面会有答案。现在看来,它们都还比较抽象,不要着急,后面会逐一将它们具体化。
参考:https://www.jianshu.com/p/7467e616f227
3损失函数
目标函数=训练损失+正则化

常用的损失函数有以下两种:
1、平方损失

2、逻辑回归损失

参考 https://blog.csdn.net/MIKASA3/article/details/82919755
4分裂结点算法
这一章算是这篇文章的核心章节,也是xgb之所以能跑的这么快的原因之一(最重要的原因在第四章),我觉得比第二章的公式都要重要。
传统算法就是暴力地遍历所有可能的分割点,xgb也支持这种做法:
当数据量过大,传统算法就不好用了,因为要遍历每个分割点,甚至内存都放不下,所以,xgb提出了额外一种近似算法能加快运行时间:
这个算法根据特征的分布情况,然后做个proposal,然后这一列的分割点就从这几个proposed candidate points里选,能大大提高效率。这里有两种proposal的方式,一种是global的,一种是local的,global的是在建树之前就做proposal然后之后每次分割都要更新一下proposal,local的方法是在每次split之后更新proposal。通常发现local的方法需要更少的candidate,而global的方法在有足够的candidate的时候效果跟local差不多。我们的系统能充分支持exact greedy跑在单台机器或多台机器上,也支持这个proposal的近似算法,并且都能设定global还是local的proposal方式(这个算法的参数我没有在一般的API里看到,可能做超大型数据的时候才会用这个吧,因为前者虽然费时间但是更准确,通常我们跑的小数据用exact greedy就行)
这里算法在研究特征分布然后做proposal的时候,用到了加权分位数略图(weighted quantile sketch),原文说不加权的分位数略图有不少了,但是支持加权的以前没人做,我对这个东西不太了解,百度了一下相关的关键词:
构造略图(sketching)是指使用随机映射(Random projections)将数据流投射在一个小的存储空间内作为整个数据流的概要,这个小空间存储的概要数据称为略图,可用于近似回答特定的查询。不同的略图可用于对数据流的不同Lp范数的估算,进而这些Lp范数可用于回答其它类型的查询。如L0范数可用于估算数据流的不同值(distinct count);L1范数可用于计算分位数(quantile)和频繁项(frequent items);L2范数可用于估算自连接的长度等等。
另外,在分割的时候,这个系统还能感知稀疏值,我们给每个树的结点都加了一个默认方向,当一个值是缺失值时,我们就把他分类到默认方向,每个分支有两个选择,具体应该选哪个?这里提出一个算法,枚举向左和向右的情况,哪个gain大选哪个:
参考:https://blog.csdn.net/qdbszsj/article/details/79615712
5正则化
对于一个含n个训练样本,m个features的结定数据集:,所使用的tree ensemble model使用K次求和函数来预测输出:
…… (1)
其中,,是回归树(CART)的空间。q表示每棵树的结构,它会将一个训练样本实例映射到相对应的叶子索引上。T是树中的叶子数。每个对应于一个独立的树结构q和叶子权重w。与决策树不同的是,每棵回归树包含了在每个叶子上的一个连续分值,我们使用来表示第i个叶子上的分值。对于一个给定样本实例,我们会使用树上的决策规则(由q给定)来将它分类到叶子上,并通过将相应叶子上的分值(由w给定)做求和,计算最终的预测值。为了在该模型中学到这些函数集合,我们会对下面的正则化目标函数做最小化:
……(2)
其中:
其中,是一个可微凸loss函数(differentiable convex loss function),可以计算预测值与目标值间的微分。第二项会惩罚模型的复杂度。正则项可以对最终学到的权重进行平滑,避免overfitting。相类似的正则化技术也用在RGF模型(正则贪婪树)上。XGBoost的目标函数与相应的学习算法比RGF简单,更容易并行化。当正则参数设置为0时,目标函数就相当于传统的gradient tree boosting方法。
参考 https://blog.csdn.net/hqr20627/article/details/79410751
6对缺失值处理
通常情况下,我们人为在处理缺失值的时候大多会选用中位数、均值或是二者的融合来对数值型特征进行填补,使用出现次数最多的类别来填补缺失的类别特征。
很多的机器学习算法都无法提供缺失值的自动处理,都需要人为地去处理,但是xgboost模型却能够处理缺失值,也就是说模型允许缺失值存在。
原是论文中关于缺失值的处理将其看与稀疏矩阵的处理看作一样。在寻找split point的时候,不会对该特征为missing的样本进行遍历统计,只对该列特征值为non-missing的样本上对应的特征值进行遍历,通过这个技巧来减少了为稀疏离散特征寻找split point的时间开销。在逻辑实现上,为了保证完备性,会分别处理将missing该特征值的样本分配到左叶子结点和右叶子结点的两种情形,计算增益后选择增益大的方向进行分裂即可。可以为缺失值或者指定的值指定分支的默认方向,这能大大提升算法的效率。如果在训练中没有缺失值而在预测中出现缺失,那么会自动将缺失值的划分方向放到右子树。
原文的伪代码如下:

参考:https://www.jianshu.com/p/5b8fbbb7e754
7优缺点
xgBoosting在传统Boosting的基础上,利用cpu的多线程,引入正则化项,加入剪纸,控制了模型的复杂度。
与GBDT相比,xgBoosting有以下进步:
1)GBDT以传统CART作为基分类器,而xgBoosting支持线性分类器,相当于引入L1和L2正则化项的逻辑回归(分类问题)和线性回归(回归问题);
2)GBDT在优化时只用到一阶导数,xgBoosting对代价函数做了二阶Talor展开,引入了一阶导数和二阶导数;
3)当样本存在缺失值是,xgBoosting能自动学习分裂方向;
4)xgBoosting借鉴RF的做法,支持列抽样,这样不仅能防止过拟合,还能降低计算;
5)xgBoosting的代价函数引入正则化项,控制了模型的复杂度,正则化项包含全部叶子节点的个数,每个叶子节点输出的score的L2模的平方和。从贝叶斯方差角度考虑,正则项降低了模型的方差,防止模型过拟合;
6)xgBoosting在每次迭代之后,为叶子结点分配学习速率,降低每棵树的权重,减少每棵树的影响,为后面提供更好的学习空间;
7)xgBoosting工具支持并行,但并不是tree粒度上的,而是特征粒度,决策树最耗时的步骤是对特征的值排序,xgBoosting在迭代之前,先进行预排序,存为block结构,每次迭代,重复使用该结构,降低了模型的计算;block结构也为模型提供了并行可能,在进行结点的分裂时,计算每个特征的增益,选增益最大的特征进行下一步分裂,那么各个特征的增益可以开多线程进行;
8)可并行的近似直方图算法,树结点在进行分裂时,需要计算每个节点的增益,若数据量较大,对所有节点的特征进行排序,遍历的得到最优分割点,这种贪心法异常耗时,这时引进近似直方图算法,用于生成高效的分割点,即用分裂后的某种值减去分裂前的某种值,获得增益,为了限制树的增长,引入阈值,当增益大于阈值时,进行分裂;
然而,与LightGBM相比,又表现出了明显的不足:
1)xgBoosting采用预排序,在迭代之前,对结点的特征做预排序,遍历选择最优分割点,数据量大时,贪心法耗时,LightGBM方法采用histogram算法,占用的内存低,数据分割的复杂度更低;
2)xgBoosting采用level-wise生成决策树,同时分裂同一层的叶子,从而进行多线程优化,不容易过拟合,但很多叶子节点的分裂增益较低,没必要进行跟进一步的分裂,这就带来了不必要的开销;LightGBM采用深度优化,leaf-wise生长策略,每次从当前叶子中选择增益最大的结点进行分裂,循环迭代,但会生长出更深的决策树,产生过拟合,因此引入了一个阈值进行限制,防止过拟合.
参考 https://blog.csdn.net/u013363120/article/details/80195471
Xgboost第一感觉就是防止过拟合+各种支持分布式/并行,所以一般传言这种大杀器效果好(集成学习的高配)+训练效率高(分布式),与深度学习相比,对样本量和特征数据类型要求没那么苛刻,适用范围广。
说下GBDT:有两种描述版本,把GBDT说成一个迭代残差树,认为每一棵迭代树都在学习前N-1棵树的残差;把GBDT说成一个梯度迭代树,使用梯度迭代下降法求解,认为每一棵迭代树都在学习前N-1棵树的梯度下降值。有说法说前者是后者在loss function为平方误差下的特殊情况。这里说下我的理解,仍然举个例子:第一棵树形成之后,有预测值y^i
,真实值(label)为yi,前者版本表示下一棵回归树根据样本(xi,yi−y^i)进行学习,后者的意思是计算loss function在第一棵树预测值附近的梯度负值作为新的label,也就是对应xgboost中的−gi
这里真心有个疑问:
Xgboost在下一棵树拟合的是残差还是负梯度,还是说是一阶导数+二阶导数,−gi(1+hi)
?可能人蠢,没看太懂,换句话说GBDT残差树群有一种拟合的(输入样本)是(xi,yi−y^i),还一种拟合的是(xi,−gi)
,Xgboost呢?
Xgboost和深度学习的关系,陈天奇在Quora上的解答如下:
不同的机器学习模型适用于不同类型的任务。深度神经网络通过对时空位置建模,能够很好地捕获图像、语音、文本等高维数据。而基于树模型的XGBoost则能很好地处理表格数据,同时还拥有一些深度神经网络所没有的特性(如:模型的可解释性、输入数据的不变性、更易于调参等)。
这两类模型都很重要,并广泛用于数据科学竞赛和工业界。举例来说,几乎所有采用机器学习技术的公司都在使用tree boosting,同时XGBoost已经给业界带来了很大的影响。
---------------------
参考 https://blog.csdn.net/github_38414650/article/details/76061893
8应用场景
可以用于分类和回归问题。在数据挖掘等相关竞赛以及实际工程中都有应用。
9sklearn参数
1. eta [默认 0.3]
和 GBM 中的 learning rate 参数类似。 通过减少每一步的权重,可以提高模型的稳定性。 典型值为 0.01-0.2。
2. min_child_weight [默认 1]
决定最小叶子节点样本权重和。和 GBM 的 min_child_leaf 参数类似,但不完全一样。XGBoost 的这个参数是最小样本权重的和,而 GBM 参数是最小样本总数。这个参数用于避免过拟合。当它的值较大时,可以避免模型学习到局部的特殊样本。但是如果这个值过高,会导致欠拟合。这个参数需要使用 CV 来调整。
3. max_depth [默认 6]
和 GBM 中的参数相同,这个值为树的最大深度。这个值也是用来避免过拟合的。max_depth 越大,模型会学到更具体更局部的样本。需要使用 CV 函数来进行调优。 典型值:3-10
4. max_leaf_nodes
树上最大的节点或叶子的数量。 可以替代 max_depth 的作用。因为如果生成的是二叉树,一个深度为 n 的树最多生成 n2 个叶子。 如果定义了这个参数,GBM 会忽略 max_depth 参数。
5. gamma [默认 0]
在节点分裂时,只有分裂后损失函数的值下降了,才会分裂这个节点。Gamma 指定了节点分裂所需的最小损失函数下降值。 这个参数的值越大,算法越保守。这个参数的值和损失函数息息相关,所以是需要调整的。
6、max_delta_step[默认 0]
这参数限制每棵树权重改变的最大步长。如果这个参数的值为 0,那就意味着没有约束。如果它被赋予了某个正值,那么它会让这个算法更加保守。 通常,这个参数不需要设置。但是当各类别的样本十分不平衡时,它对逻辑回归是很有帮助的。 这个参数一般用不到,但是你可以挖掘出来它更多的用处。
7. subsample [默认 1]
和 GBM 中的 subsample 参数一模一样。这个参数控制对于每棵树,随机采样的比例。 减小这个参数的值,算法会更加保守,避免过拟合。但是,如果这个值设置得过小,它可能会导致欠拟合。 典型值:0.5-1
8. colsample_bytree [默认 1]
和 GBM 里面的 max_features 参数类似。用来控制每棵随机采样的列数的占比 (每一列是一个特征)。 典型值:0.5-1
9. colsample_bylevel [默认 1]
用来控制树的每一级的每一次分裂,对列数的采样的占比。 我个人一般不太用这个参数,因为 subsample 参数和 colsample_bytree 参数可以起到相同的作用。但是如果感兴趣,可以挖掘这个参数更多的用处。
10. lambda [默认 1]
权重的 L2 正则化项。(和 Ridge regression 类似)。 这个参数是用来控制 XGBoost 的正则化部分的。虽然大部分数据科学家很少用到这个参数,但是这个参数在减少过拟合上还是可以挖掘出更多用处的。
11. alpha [默认 1]
权重的 L1 正则化项。(和 Lasso regression 类似)。 可以应用在很高维度的情况下,使得算法的速度更快。
12. scale_pos_weight [默认 1]
在各类别样本十分不平衡时,把这个参数设定为一个正值,可以使算法更快收敛。
学习目标参数
这个参数用来控制理想的优化目标和每一步结果的度量方法。
1. objective [默认 reg:linear]
这个参数定义需要被最小化的损失函数。最常用的值有:
binary:logistic 二分类的逻辑回归,返回预测的概率 (不是类别)。 multi:softmax 使用 softmax 的多分类器,返回预测的类别 (不是概率)。
在这种情况下,你还需要多设一个参数:num_class(类别数目)。 multi:softprob 和 multi:softmax 参数一样,但是返回的是每个数据属于各个类别的概率。
2. eval_metric [默认值取决于 objective 参数的取值]
对于有效数据的度量方法。对于回归问题,默认值是 rmse,对于分类问题,默认值是 error。 典型值有:
rmse 均方根误差、mae 平均绝对误差、logloss 负对数似然函数值、error 二分类错误率 (阈值为 0.5)、merror 多分类错误率、mlogloss 多分类 logloss 损失函数、auc 曲线下面积
3. seed [默认 0]
随机数的种子设置它可以复现随机数据的结果,也可以用于调整参数。
参考:https://www.jianshu.com/p/8346d4f80ab0