python requests
requests是一个很实用的Python HTTP客户端库,编写爬虫和测试服务器响应数据时经常会用到。可以说,Requests 完全满足如今网络的需求
网站分析
爬虫的必备第一步,分析目标网站。这里使用谷歌浏览器的开发者者工具分析。
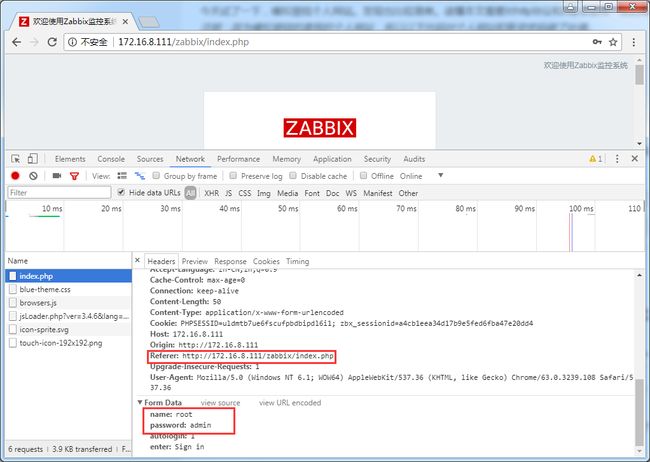
通过登陆抓取,看到这样一个请求。
上方部分为请求头,下面部分为请求是传的参数。由图片可以看出,页面通过表单提交了三个参数。分别为_csrf,name,password。
其中csrf是为了预防跨域脚本伪造。原理很简单,就是每一次请求,服务器生成一串加密字符串。放在隐藏的input表单中。再一次请求的时候,把这个字符串一起传过去,为了验证是否为同一个用户的请求。
# -*-coding:UTF-8 -*-
import requests
s = requests.session()
data = {
'name':'Admin',
'password':'zabbix',
'autologin':'1',
'enter':'Sign in'
}
s.post('http://172.16.8.17/zabbix/index.php',data)
r = s.get("http://172.16.8.17/zabbix/zabbix.php?action=problem.view&ddreset=1")
print r.text
执行结果如下: