【MDS算法】—— Multiple Dimensional Scaling降维算法简介
在高维情形下出现的数据样本稀疏、距离计算困难等问题,是所有机器学习方法共同面临的严重障碍,被称为“维数灾难” (curse ofdimensionality)。
缓解维数灾难的一个重要途径是降维 (dimension reduction),亦称“维数约简”,即通过某种数学变换将原始高维属性空间转变为一个低维“子空间”(subspace), 在这个子空间中样本密度大幅提高,距离计算也变得更为容易.为什么能进行降维?这是因为在很多时候,人们观测或收集到的数据样本虽是高维的,但与学习任务密切相关的也许仅是某个低维分布,即高维空间中的一个低维“ 嵌入” (embedding)。下图给出了一个直观的例子。原始高维空间中的样本点,在这个低维嵌入子空间中更容易进行学习。
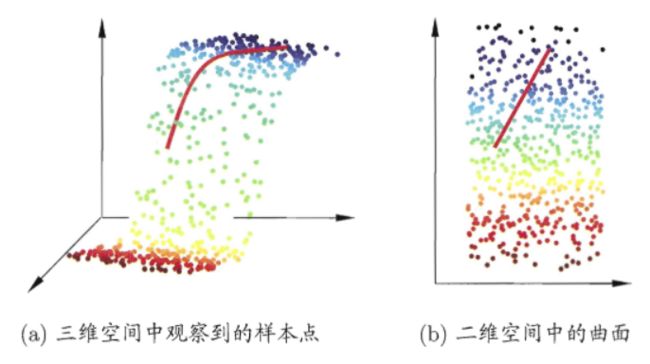
若要求原始空间中样本之间的距离在低维空间中得以保持,如上图所示,即得到“多维缩放” (Multiple Dimensional Scaling,简称 M D S MDS MDS ) 这样一种经典的降维方法。下面做一个简单的介绍。
假定 m m m 个样本在原始空间的距离矩阵为 D ∈ R m × m D∈\mathbb{R}^{m×m} D∈Rm×m,其第 i i i 行 j j j 列的元素 d i s t i j dist_{ij} distij 为样本 x i x_i xi 到 x j x_j xj 的距离。我们的目标是获得样本在 d ′ d' d′ 维空间的表示 Z ∈ R d ′ × m , d ′ ≤ d Z∈\mathbb{R}^{d'×m},d'≤d Z∈Rd′×m,d′≤d,且任意两个样本在 d ′ d' d′ 维空间中的欧氏距离等于原始空间中的距离,即 ∣ ∣ z i − z j ∣ ∣ = d i s t i j ||z_i-z_j||=dist_{ij} ∣∣zi−zj∣∣=distij。
令 B = Z T Z ∈ R m x m B=Z^TZ∈\mathbb{R}^{mxm} B=ZTZ∈Rmxm,其中 B B B 为降维后样本的内积矩阵, b i j = z i T z j b_{ij}=z_i^Tz_j bij=ziTzj,有

0 ∈ R d ′ 0∈\mathbb{R}^{d'} 0∈Rd′ 为全零向量。
为便于讨论,令降维后的样本 Z Z Z 被中心化,即 ∑ i = 1 m z i = 0 \sum^m_{i=1}z_i=0 ∑i=1mzi=0。显然,矩阵 B B B 的行与列之和均为零,即 ∑ i = 1 m b i j = ∑ j = 1 m b i j 0 \sum^m_{i=1}b_{ij}=\sum^m_{j=1}b_{ij}0 ∑i=1mbij=∑j=1mbij0。易知
∑ i = 1 m d i s t i j 2 = t r ( B ) + m b j j , (4) \sum^m_{i=1}dist^2_{ij}=tr(B)+mb_{jj}\,\,,\tag{4} i=1∑mdistij2=tr(B)+mbjj,(4)
∑ j = 1 m d i s t i j 2 = t r ( B ) + m b i i , (5) \sum^m_{j=1}dist^2_{ij}=tr(B)+mb_{ii}\,\,,\tag{5} j=1∑mdistij2=tr(B)+mbii,(5)
∑ i = 1 m ∑ j = 1 m d i s t i j 2 = 2 m t r ( B ) , (6) \sum^m_{i=1}\sum^m_{j=1}dist^2_{ij}=2m\,tr(B)\,\,,\tag{6} i=1∑mj=1∑mdistij2=2mtr(B),(6)
其中 t r ( ⋅ ) tr(·) tr(⋅) 表示矩阵的迹 (trace), t r ( B ) = ∑ i = 1 m ∣ ∣ z i ∣ ∣ 2 tr(B)=\sum^m_{i=1}||z_i||^2 tr(B)=∑i=1m∣∣zi∣∣2。令
d i s t i . 2 = 1 m ∑ j = 1 m d i s t i j 2 , (7) dist_{i.}^2=\frac{1}{m}\sum^m_{j=1}dist_{ij}^2\,\,,\tag{7} disti.2=m1j=1∑mdistij2,(7)
d i s t . j 2 = 1 m ∑ j = 1 m d i s t i j 2 , (8) dist_{.j}^2=\frac{1}{m}\sum^m_{j=1}dist_{ij}^2\,\,,\tag{8} dist.j2=m1j=1∑mdistij2,(8)
d i s t . . 2 = 1 m 2 ∑ i = 1 m ∑ j = 1 m d i s t i j 2 , (9) dist_{..}^2=\frac{1}{m^2}\sum^m_{i=1}\sum^m_{j=1}dist_{ij}^2\,\,,\tag{9} dist..2=m21i=1∑mj=1∑mdistij2,(9)
由式 (3) 和式 (4)~(9) 可得
b i j = − 1 2 ( d i s t i j 2 − d i s t i . 2 − d i s t . j 2 + d i s t . . 2 ) , (10) b_{ij}=-\frac{1}{2}(dist_{ij}^2-dist^2_{i.}-dist^2_{.j}+dist^2_{..})\,\,,\tag{10} bij=−21(distij2−disti.2−dist.j2+dist..2),(10)
由此即可通过降维前后保持不变的距离矩阵 D D D 求取内积矩阵 B B B。
对矩阵 B B B 做特征值分解 (eigenvalue decomposition), B = Ⅴ Λ Ⅴ T B=Ⅴ\Lambda Ⅴ^T B=ⅤΛⅤT,其中 Λ = d i a g ( λ 1 , λ 2 , . . . , λ d ) \Lambda= diag(λ_1,λ_2,...,\lambda_d) Λ=diag(λ1,λ2,...,λd) 为特征值构成的对角矩阵, λ 1 ≥ λ 2 ≥ . . . ≥ λ d λ_1≥\lambda_2≥...≥\lambda_d λ1≥λ2≥...≥λd, V V V 为特征向量矩阵。假定其中有 d ∗ d^* d∗ 个非零特征值,它们构成对角矩阵 Λ ∗ = d i a g ( λ 1 , λ 2 , . . . , λ d ∗ ) \Lambda_*=diag(\lambda_1,\lambda_2,...,\lambda_{d^*}) Λ∗=diag(λ1,λ2,...,λd∗)。令 Ⅴ ∗ Ⅴ_* Ⅴ∗ 表示相应的特征向量矩阵,则 Z Z Z 可表达为
Z = Λ ∗ 1 / 2 Ⅴ ∗ T ∈ R d ∗ × m . (11) Z=\Lambda_*^{1/2}Ⅴ^T_*∈\mathbb{R}^{d^*×m}\,\,.\tag{11} Z=Λ∗1/2Ⅴ∗T∈Rd∗×m.(11)
在现实应用中为了有效降维,往往仅需降维后的距离与原始空间中的距离尽可能接近,而不必严格相等。此时可取 d ′ ≪ d d'\ll d d′≪d 个最大特征值构成对角矩阵 Λ ~ = d i a g ( λ 1 , λ 2 , . . . , λ d ′ ) \tilde{\Lambda}=diag(\lambda_1,\lambda_2,...,\lambda_{d'}) Λ~=diag(λ1,λ2,...,λd′),令 Ⅴ ~ \tilde{Ⅴ} Ⅴ~ 表示相应的特征向量矩阵,则 Z Z Z 可表达为
Z = Λ ~ 1 / 2 Ⅴ ~ T ∈ R d ′ × m . (12) Z=\tilde{\Lambda}^{1/2}\tilde{Ⅴ}^T∈\mathbb{R}^{d'×m}\,\,.\tag{12} Z=Λ~1/2Ⅴ~T∈Rd′×m.(12)
下图给出了 M D S MDS MDS 算法的描述:

一般来说,欲获得低维子空间,最简单的是对原始高维空间进行线性变换。给定 d d d 维空间中的样本 X = ( x 1 , x 2 , . . . , x m ) ∈ R d × m X=(x_1,x_2,...,x_m)∈\mathbb{R}^{d×m} X=(x1,x2,...,xm)∈Rd×m,变换之后得到 d ′ ≤ d d'≤d d′≤d 维空间中的样本
Z = W T X , (13) Z=W^TX\,\,,\tag{13} Z=WTX,(13)
通常令 d ′ ≪ d d'\ll d d′≪d。
其中 W ∈ R d × d ′ W∈\mathbb{R}^{d×d'} W∈Rd×d′ 变换矩阵,Z∈Rd"xm是样本在新空间中的表达。
变换矩阵 W W W 可视为 d ′ d' d′ 个 d d d 维基向量, z i = W T x i z_i=W^Tx_i zi=WTxi 是第 i i i 个样本与这 d ′ d' d′ 个基向量分别做内积而得到的 d ′ d' d′ 维属性向量。换言之, z i z_i zi 是原属性向量 x i x_i xi 在新坐标系 { w 1 , w 2 , . . . , w d ′ } \{w_1,w_2,...,w_{d'}\} {w1,w2,...,wd′} 中的坐标向量。若 w i w_i wi 与 w j ( i ≠ j ) w_j(i≠j) wj(i=j) 正交,则新坐标系是一个正交坐标系,此时 W W W 为正交变换。显然,新空间中的属性是原空间中属性的线性组合。
基于线性变换来进行降维的方法称为线性降维方法,它们都符合式 (13) 的基本形式,不同之处是对低维子空间的性质有不同的要求,相当于对 W W W 施加了不同的约束。在下一节我们将会看到,若要求低维子空间对样本具有最大可分性,则将得到一种极为常用的线性降维方法。
对降维效果的评估,通常是比较降维前后学习器的性能,若性能有所提高则认为降维起到了作用。若将维数降至二维或三维,则可通过可视化技术来直观地判断降维效果。
Reference:《机器学习》