损失函数(loss function)或代价函数(cost function)的事情
In the theory of point estimation, a loss function quantifies the losses associated to the errors committed while estimating a parameter. Often the expected value of the loss, called statistical risk, is used to compare two or more estimators: in such comparisons, the estimator having the least expected loss is usually deemed preferable.

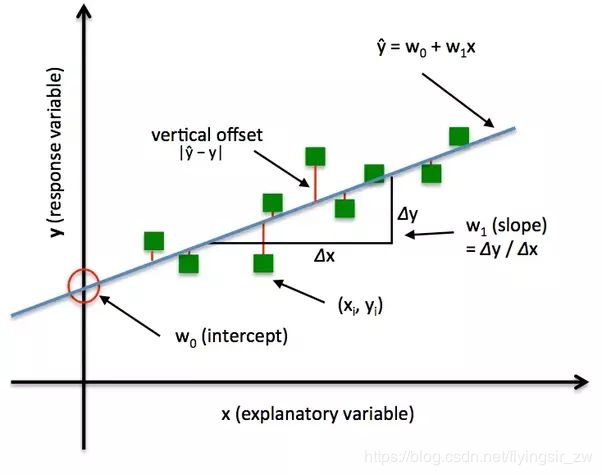
最小二乘法是线性回归的一种,OLS将问题转化成了一个凸优化问题。在线性回归中,它假设样本和噪声都服从高斯分布(为什么假设成高斯分布呢?其实这里隐藏了一个小知识点,就是中心极限定理,可以参考【central limit theorem】),最后通过极大似然估计(MLE)可以推导出最小二乘式子。最小二乘的基本原则是:最优拟合直线应该是使各点到回归直线的距离和最小的直线,即平方和最小。换言之,OLS是基于距离的,而这个距离就是我们用的最多的欧几里得距离。为什么它会选择使用欧式距离作为误差度量呢(即Mean squared error, MSE),主要有以下几个原因:
简单,计算方便;
欧氏距离是一种很好的相似性度量标准;
在不同的表示域变换后特征性质不变。
平方损失(Square loss)的标准形式如下:
?(?,?(?))=(?−?(?))2
当样本个数为n时,此时的损失函数变为:
L ( Y , f ( X ) ) = ∑ i = 1 n ( Y − f ( X ) ) 2 L(Y, f(X)) = \sum _{i=1}^{n}(Y - f(X))^2 L(Y,f(X))=i=1∑n(Y−f(X))2
Y-f(X)表示的是残差,整个式子表示的是残差的平方和,而我们的目的就是最小化这个目标函数值(注:该式子未加入正则项),也就是最小化残差的平方和(residual sum of squares,RSS)。
而在实际应用中,通常会使用均方差(MSE)作为一项衡量指标,公式如下:
???=1?∑?=1?(??~−??)2
上面提到了线性回归,这里额外补充一句,我们通常说的线性有两种情况,一种是因变量y是自变量x的线性函数,一种是因变量y是参数?的线性函数。在机器学习中,通常指的都是后一种情况。
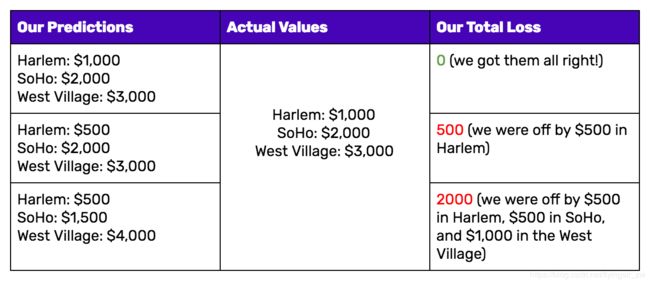
Notice how in the loss function we defined, it doesn’t matter if our predictions were too high or too low. All that matters is how incorrect we were, directionally agnostic. This is not a feature of all loss functions: in fact, your loss function will vary significantly based on the domain and unique context of the problem that you’re applying machine learning to. In your project, it may be much worse to guess too high than to guess too low, and the loss function you select must reflect that.
程序实现
#!/usr/bin/env python
# -*- coding: utf8 -*-
# y_true: list, the true labels of input instances
# y_pred: list, the probability when the predicted label of input instances equals to 1
def logloss(y_true, y_pred, eps=1e-15):
import numpy as np
# Prepare numpy array data
y_true = np.array(y_true)
y_pred = np.array(y_pred)
assert (len(y_true) and len(y_true) == len(y_pred))
# Clip y_pred between eps and 1-eps
p = np.clip(y_pred, eps, 1-eps)
loss = np.sum(- y_true * np.log(p) - (1 - y_true) * np.log(1-p))
return loss / len(y_true)
def unitest():
y_true = [0, 0, 1, 1]
y_pred = [0.1, 0.2, 0.7, 0.99]
print ("Use self-defined logloss() in binary classification, the result is {}".format(logloss(y_true, y_pred)))
from sklearn.metrics import log_loss
print ("Use log_loss() in scikit-learn, the result is {} ".format(log_loss(y_true, y_pred)))
if __name__ == '__main__':
unitest()