TASK1 线性回归-Linear_regression
线性回归的概念
1、线性回归的原理
2、线性回归损失函数、代价函数、目标函数
3、优化方法(梯度下降法、牛顿法、拟牛顿法等)
4、线性回归的评估指标
5、sklearn参数详解
1、线性回归的原理
进入一家房产网,可以看到房价、面积、厅室呈现以下数据:
| 面积($x_1$) | 厅室数量($x_2)$ | 价格(万元)(y) |
|---|---|---|
| 64 | 3 | 225 |
| 59 | 3 | 185 |
| 65 | 3 | 208 |
| 116 | 4 | 508 |
| …… | …… | …… |
我们可以将价格和面积、厅室数量的关系习得为 f ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 f(x)=\theta_0+\theta_1x_1+\theta_2x_2 f(x)=θ0+θ1x1+θ2x2,使得 f ( x ) ≈ y f(x)\approx y f(x)≈y,这就是一个直观的线性回归的样式。
小练习:这是国内一个房产网站上任意搜的数据,有兴趣可以找个网站观察一下,还可以获得哪些可能影响到房价的因素?可能会如何影响到实际房价呢?线性回归的一般形式:
有数据集 { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) } \{(x_1,y_1),(x_2,y_2),...,(x_n,y_n)\} {(x1,y1),(x2,y2),...,(xn,yn)},其中, x i = ( x i 1 ; x i 2 ; x i 3 ; . . . ; x i d ) , y i ∈ R x_i = (x_{i1};x_{i2};x_{i3};...;x_{id}),y_i\in R xi=(xi1;xi2;xi3;...;xid),yi∈R
其中n表示变量的数量,d表示每个变量的维度。
可以用以下函数来描述y和x之间的关系:
f ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ d x d = ∑ i = 0 d θ i x i f(x) = \theta_0 + \theta_1x_1 + \theta_2x_2 +... + \theta_dx_d = \sum_{i=0}^{d}\theta_ix_i f(x)=θ0+θ1x1+θ2x2+...+θdxd=i=0∑dθixi
如何来确定 θ \theta θ的值,使得 f ( x ) f(x) f(x)尽可能接近y的值呢?均方误差是回归中常用的性能度量,即:
J ( θ ) = 1 2 ∑ j = 1 n ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta)=\frac{1}{2}\sum_{j=1}^{n}(h_{\theta}(x^{(i)})-y^{(i)})^2 J(θ)=21j=1∑n(hθ(x(i))−y(i))2
我们可以选择 θ \theta θ,试图让均方误差最小化:
极大似然估计(概率角度的诠释)
下面我们用极大似然估计,来解释为什么要用均方误差作为性能度量
我们可以把目标值和变量写成如下等式:
y ( i ) = θ T x ( i ) + ϵ ( i ) y^{(i)} = \theta^T x^{(i)}+\epsilon^{(i)} y(i)=θTx(i)+ϵ(i)
ϵ \epsilon ϵ表示我们未观测到的变量的印象,即随机噪音。我们假定 ϵ \epsilon ϵ是独立同分布,服从高斯分布(就是正态分布)。(根据中心极限定理)
p ( ϵ ( i ) ) = 1 2 π σ e x p ( − ( ϵ ( i ) ) 2 2 σ 2 ) p(\epsilon^{(i)}) = \frac{1}{\sqrt{2\pi}\sigma}exp\left(-\frac{(\epsilon^{(i)})^2}{2\sigma^2}\right) p(ϵ(i))=2πσ1exp(−2σ2(ϵ(i))2)
因此,( y ( i ) = θ T x ( i ) + ϵ ( i ) y^{(i)} = \theta^T x^{(i)}+\epsilon^{(i)} y(i)=θTx(i)+ϵ(i),移项得 ϵ ( i ) = y ( i ) − θ T x ( i ) \epsilon^{(i)} = y^{(i)}-\theta^T x^{(i)} ϵ(i)=y(i)−θTx(i))
p ( y ( i ) ∣ x ( i ) ; θ ) = 1 2 π σ e x p ( − ( y ( i ) − θ T x ( i ) ) 2 2 σ 2 ) p(y^{(i)}|x^{(i)};\theta) = \frac{1}{\sqrt{2\pi}\sigma}exp\left(-\frac{(y^{(i)}-\theta^T x^{(i)})^2}{2\sigma^2}\right) p(y(i)∣x(i);θ)=2πσ1exp(−2σ2(y(i)−θTx(i))2)
-
Notice:这个 p ( y ( i ) ∣ x ( i ) ; θ ) p(y^{(i)}|x^{(i)};\theta) p(y(i)∣x(i);θ)的意思是,在参数为 θ \theta θ时候, x ( i ) x^{(i)} x(i)属于 y ( i ) y^{(i)} y(i)的概率
-
极大似然估计:离散型和连续性,即 L ( θ ) = { ∏ i = 1 n p ( X i , θ ) ∏ i = 1 n f ( X i , θ ) L(\theta)=\begin{cases}\prod\limits_{i=1}^n p(X_i,\theta)\\\prod\limits_{i=1}^n f(X_i,\theta)\end{cases} L(θ)=⎩⎪⎨⎪⎧i=1∏np(Xi,θ)i=1∏nf(Xi,θ),当 θ \theta θ取多少时,概率最大
-
举例:运动员射箭,运动员分1和2级运动员,射箭成绩为 ( 10 , 9 , 10 , 10 ) (10,9,10,10) (10,9,10,10),所以我们可以推测这个是1级运动员,换句话说,在他为1级运动员时,射出 ( 10 , 9 , 10 , 10 ) (10,9,10,10) (10,9,10,10)的成绩的概率最大,即 p ( 10 , 9 , 10 , 10 ∣ 1 ) = max p(10,9,10,10 | 1)=\max p(10,9,10,10∣1)=max,就是参数为多少时,观测值出现的概率最大, p ( 10 , 9 , 10 , 10 ∣ ? ) = max p(10,9,10,10 | ?)=\max p(10,9,10,10∣?)=max, ? ? ?处就是我们要算的 θ \theta θ.
-
计算步骤,一般取对数,令 d log L ( θ ) d θ = 0 \frac{d\log L(\theta)}{d\theta}=0 dθdlogL(θ)=0,得出 θ ^ \hat\theta θ^,此处 log \log log就是 ln \ln ln,取对数为什么可以求出 θ ^ \hat\theta θ^,是因为对数函数严格单调增;也可以不取对数,直接求导;如果 L ( θ ) L(\theta) L(θ)关于 θ \theta θ单调,直接定义法,取两端,一般是样本的 max \max max或者 m i n min min。Notice:对于连续性的,要根据分布函数先求出概率密度, X X X ~ F ( x , θ ) F(x,\theta) F(x,θ)求导得 X X X ~ f ( x , θ ) f(x,\theta) f(x,θ)
我们建立极大似然函数,即描述数据遵从当前样本分布的概率分布函数。由于样本的数据集独立同分布,因此可以写成
L ( θ ) = p ( y ⃗ ∣ X ; θ ) = ∏ i = 1 n 1 2 π σ e x p ( − ( y ( i ) − θ T x ( i ) ) 2 2 σ 2 ) L(\theta) = p(\vec y | X;\theta) = \prod^n_{i=1}\frac{1}{\sqrt{2\pi}\sigma}exp\left(-\frac{(y^{(i)}-\theta^T x^{(i)})^2}{2\sigma^2}\right) L(θ)=p(y∣X;θ)=i=1∏n2πσ1exp(−2σ2(y(i)−θTx(i))2)
选择 θ \theta θ,使得似然函数最大化,这就是极大似然估计的思想。
为了方便计算,我们计算时通常对对数似然函数求最大值:
l ( θ ) = l o g L ( θ ) = l o g ∏ i = 1 n 1 2 π σ e x p ( − ( y ( i ) − θ T x ( i ) ) 2 2 σ 2 ) = ∑ i = 1 n l o g 1 2 π σ e x p ( − ( y ( i ) − θ T x ( i ) ) 2 2 σ 2 ) = n l o g 1 2 π σ − 1 σ 2 ⋅ 1 2 ∑ i = 1 n ( ( y ( i ) − θ T x ( i ) ) 2 l(\theta) = log L(\theta) = log \prod^n_{i=1}\frac{1}{\sqrt{2\pi}\sigma}exp\left(-\frac{(y^{(i)}-\theta^T x^{(i)})^2} {2\sigma^2}\right) \\ = \sum^n_{i=1}log\frac{1}{\sqrt{2\pi}\sigma}exp\left(-\frac{(y^{(i)}-\theta^T x^{(i)})^2}{2\sigma^2}\right) \\ = nlog\frac{1}{{\sqrt{2\pi}\sigma}} - \frac{1}{\sigma^2} \cdot \frac{1}{2}\sum^n_{i=1}((y^{(i)}-\theta^T x^{(i)})^2 l(θ)=logL(θ)=logi=1∏n2πσ1exp(−2σ2(y(i)−θTx(i))2)=i=1∑nlog2πσ1exp(−2σ2(y(i)−θTx(i))2)=nlog2πσ1−σ21⋅21i=1∑n((y(i)−θTx(i))2
显然,最大化 l ( θ ) l(\theta) l(θ)即最小化 1 2 ∑ i = 1 n ( ( y ( i ) − θ T x ( i ) ) 2 \frac{1}{2}\sum\limits^n_{i=1}((y^{(i)}-\theta^T x^{(i)})^2 21i=1∑n((y(i)−θTx(i))2。(这部分对 θ \theta θ求导)
这一结果即均方误差,因此用这个值作为代价函数来优化模型在统计学的角度是合理的。
- 补充:
-
正态分布:随机误差都随了正态分布, X ∼ f ( x ) = 1 2 π σ e x p ( − ( x − μ ) 2 2 σ 2 ) X \sim{f(x)}=\frac{1}{\sqrt{2\pi}\sigma}exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right) X∼f(x)=2πσ1exp(−2σ2(x−μ)2)( − ∞ < x < + ∞ -\infty< x<+\infty −∞<x<+∞, x = μ x=\mu x=μ为对称轴, max = 1 2 π σ \max=\frac{1}{\sqrt{2\pi}\sigma} max=2πσ1, μ \mu μ为均值(期望), σ \sigma σ为标准差, σ 2 \sigma^2 σ2为方差), ∼ \sim ∼表示服从,即可以写作 X ∼ N ( μ , σ 2 ) X\sim N(\mu,\sigma^2) X∼N(μ,σ2)
-
Notice:若 μ = 0 , σ 2 = 1 \mu=0,\sigma^2=1 μ=0,σ2=1,则 X ∼ N ( 0 , 1 ) X\sim N(0,1) X∼N(0,1),则 X ∼ φ ( x ) = 1 2 π e x p ( − x 2 2 ) X\sim \varphi(x)=\frac{1}{\sqrt{2\pi}}exp\left(-\frac{x^2}{2}\right) X∼φ(x)=2π1exp(−2x2)关于 y y y轴对称, φ ( x ) \varphi(x) φ(x)为标准正态的概率密度(概率密度在全区间积分=1,归一性), X ∼ Φ ( x ) = ∫ − ∞ x 1 2 π e x p ( − t 2 2 ) d t X\sim \Phi(x)=\int_{-\infty}^{x} \frac{1}{\sqrt{2\pi}}exp\left(-\frac{t^2}{2}\right)\, dt X∼Φ(x)=∫−∞x2π1exp(−2t2)dt, Φ ( x ) \Phi(x) Φ(x)为标准正态分布函数

-
中心极限定理是说:
样本的平均值约等于总体的平均值。
不管总体是什么分布,任意一个总体的样本平均值都会围绕在总体的整体平均值周围,并且呈正态分布。(原来的标准差公式是除以 n n n,为了用样本估计总体标准差,现在是除以 n − 1 n-1 n−1。这样就是的标准略大。一般用 s s s表示用样本估计出的总体标准差。)
-
2、线性回归损失函数、代价函数、目标函数
- 损失函数(Loss Function):度量单样本预测的错误程度,损失函数值越小,模型就越好。
- 代价函数(Cost Function):度量全部样本集的平均误差。
- 目标函数(Object Function):代价函数和正则化函数,最终要优化的函数。
- 补充:
-
损失函数和代价函数是同一个东西,目标函数是一个与他们相关但更广的概念,对于目标函数来说在有约束条件下的最小化就是损失函数(loss function)。
-
举个例子解释一下:(图片来自Andrew Ng Machine Learning公开课视频)
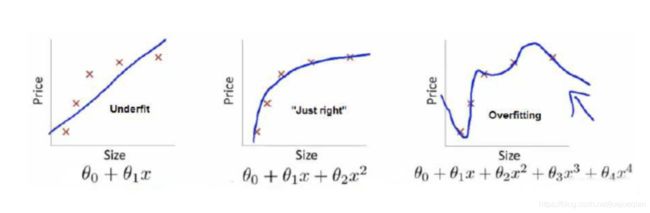
-
上面三个图的函数依次为 f 1 ( x ) , f 2 ( x ) , f 3 ( x ) f_1(x),f_2(x),f_3(x) f1(x),f2(x),f3(x)。我们是想用这三个函数分别来拟合Price,而Price的真实值记为 Y Y Y。
-
我们给定 x x x,这三个函数都会输出一个 f ( X ) f(X) f(X),这个输出的 f ( X ) f(X) f(X)与真实值 Y Y Y可能是相同的,也可能是不同的,为了表示我们拟合的好坏,我们就用一个函数来度量拟合的程度,比如: L ( Y , f ( X ) ) = ( Y − f ( X ) ) 2 L(Y, f(X))=(Y-f(X))^2 L(Y,f(X))=(Y−f(X))2,这个函数就称为损失函数(loss function),或者叫代价函数(cost function)。损失函数越小,就代表模型拟合的越好。
-
那是不是我们的目标就只是让loss function越小越好呢?还不是。
这个时候还有一个概念叫风险函数(risk function)。风险函数是损失函数的期望,这是由于我们输入输出的 ( X , Y ) (X,Y) (X,Y)遵循一个联合分布,但是这个联合分布是未知的,所以无法计算。但是我们是有历史数据的,就是我们的训练集, f ( X ) f(X) f(X)关于训练集的平均损失称作经验风险(empirical risk),即 1 N ∑ i = 1 N L ( y i , f ( x i ) ) \frac{1}{N}\sum\limits_{i=1}^NL(y_i,f(x_i)) N1i=1∑NL(yi,f(xi)),所以我们的目标就是最小化 1 N ∑ i = 1 N L ( y i , f ( x i ) ) \frac{1}{N}\sum\limits_{i=1}^NL(y_i,f(x_i)) N1i=1∑NL(yi,f(xi)),称为经验风险最小化。 -
到这里完了吗?还没有。
-
如果到这一步就完了的话,那我们看上面的图,那肯定是最右面的 f 3 ( x ) f_3(x) f3(x)的经验风险函数最小了,因为它对历史的数据拟合的最好嘛。但是我们从图上来看 f 3 ( x ) f_3(x) f3(x)肯定不是最好的,因为它过度学习历史数据,导致它在真正预测时效果会很不好,这种情况称为过拟合(over-fitting)。
-
为什么会造成这种结果?
- 大白话说就是它的函数太复杂了,都有四次方了,这就引出了下面的概念,我们不仅要让经验风险最小化,还要让结构风险最小化。这个时候就定义了一个函数 j ( f ) j(f) j(f),这个函数专门用来度量模型的复杂度,在机器学习中也叫正则化(regularization)。常用的有 L 1 , L 2 L_1,L_2 L1,L2范数。
-
到这一步我们就可以说我们最终的优化函数是: min 1 N ∑ i = 1 N L ( y i , f ( x i ) ) + λ J ( f ) \min \frac{1}{N}\sum\limits_{i=1}^N L(y_i,f(x_i))+\lambda J(f) minN1i=1∑NL(yi,f(xi))+λJ(f),即最优化经验风险和结构风险,而这个函数就被称为目标函数。
-
结合上面的例子来分析:最左面的 f 1 ( x ) f_1(x) f1(x)结构风险最小(模型结构最简单),但是经验风险最大(对历史数据拟合的最差);最右面的 f 3 ( x ) f_3(x) f3(x)经验风险最小(对历史数据拟合的最好),但是结构风险最大(模型结构最复杂);而 f 2 ( x ) f_2(x) f2(x)达到了二者的良好平衡,最适合用来预测未知数据集。
-
- 来自:https://www.zhihu.com/question/52398145/answer/209358209
常用的损失函数包括:0-1损失函数、平方损失函数、绝对损失函数、对数损失函数等;常用的代价函数包括均方误差、均方根误差、平均绝对误差等。
思考题:既然代价函数已经可以度量样本集的平均误差,为什么还要设定目标函数?回答:
当模型复杂度增加时,有可能对训练集可以模拟的很好,但是预测测试集的效果不好,出现过拟合现象,这就出现了所谓的“结构化风险”。结构风险最小化即为了防止过拟合而提出来的策略,定义模型复杂度为 J ( F ) J(F) J(F),目标函数可表示为:
m i n f ∈ F 1 n ∑ i = 1 n L ( y i , f ( x i ) ) + λ J ( F ) \underset{f\in F}{min}\, \frac{1}{n}\sum^{n}_{i=1}L(y_i,f(x_i))+\lambda J(F) f∈Fminn1i=1∑nL(yi,f(xi))+λJ(F)
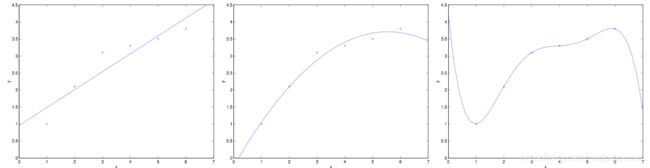
例如有以上6个房价和面积关系的数据点,可以看到,当设定 f ( x ) = ∑ j = 0 5 θ j x j f(x)=\sum\limits_{j=0}^{5}\theta_jx^j f(x)=j=0∑5θjxj时,可以完美拟合训练集数据,但是,真实情况下房价和面积不可能是这样的关系,出现了过拟合现象。当训练集本身存在噪声时,拟合曲线对未知影响因素的拟合往往不是最好的。
通常,随着模型复杂度的增加,训练误差会减少;但测试误差会先增加后减小。我们的最终目的时试测试误差达到最小,这就是我们为什么需要选取适合的目标函数的原因。
3、线性回归的优化方法
1、梯度下降法
- 方向导数与梯度:
-
背景:以二元举例

-
∂ u ∂ l ∣ P 0 \left.\dfrac{\partial u}{\partial l}\right|_{P_0} ∂l∂u∣∣∣∣P0
= u x ′ ( P 0 ) cos α + u y ′ ( P 0 ) cos β + u z ′ ( P 0 ) cos γ =u_x^{'}(P_0)\cos\alpha+u_y^{'}(P_0)\cos\beta+u_z^{'}(P_0)\cos\gamma =ux′(P0)cosα+uy′(P0)cosβ+uz′(P0)cosγ
= ( u x ′ ( P 0 ) , u y ′ ( P 0 ) , u z ′ ( P 0 ) ) ⋅ ( cos α , cos β , cos γ ) =(u_x^{'}(P_0),u_y^{'}(P_0),u_z^{'}(P_0))\cdot(\cos\alpha,\cos\beta,\cos\gamma) =(ux′(P0),uy′(P0),uz′(P0))⋅(cosα,cosβ,cosγ)
= ∣ ( u x ′ ( P 0 ) , u y ′ ( P 0 ) , u z ′ ( P 0 ) ) ∣ ∣ ( cos α , cos β , cos γ ) ∣ cos θ =|(u_x^{'}(P_0),u_y^{'}(P_0),u_z^{'}(P_0))||(\cos\alpha,\cos\beta,\cos\gamma)|\cos \theta =∣(ux′(P0),uy′(P0),uz′(P0))∣∣(cosα,cosβ,cosγ)∣cosθ
= ∣ ( u x ′ ( P 0 ) , u y ′ ( P 0 ) , u z ′ ( P 0 ) ) ∣ cos θ =|(u_x^{'}(P_0),u_y^{'}(P_0),u_z^{'}(P_0))|\cos \theta =∣(ux′(P0),uy′(P0),uz′(P0))∣cosθ -
其中第二步中的第一项 ( u x ′ ( P 0 ) , u y ′ ( P 0 ) , u z ′ ( P 0 ) ) (u_x^{'}(P_0),u_y^{'}(P_0),u_z^{'}(P_0)) (ux′(P0),uy′(P0),uz′(P0))是固定向量,与 l l l的方向无关;第二项 ( cos α , cos β , cos γ ) (\cos\alpha,\cos\beta,\cos\gamma) (cosα,cosβ,cosγ)为单位向量,方向与 l l l相同;
-
第二步的第一项记为梯度:记 g r a d u ∣ P 0 \left.grad\ u\right|_{P_0} grad u∣P0,即梯度为固定向量,与 l l l无关
-
θ \theta θ为 g r a d u ∣ P 0 \left.grad\ u\right|_{P_0} grad u∣P0与 l l l的夹角,方向导数是小于等于梯度的
-
当 θ = 0 \theta=0 θ=0时, ∂ u ∂ l ∘ ∣ P 0 \left.\dfrac{\partial u}{\partial l^{\circ}}\right|_{P_0} ∂l∘∂u∣∣∣∣P0有最大值,即当 l l l的方向与梯度方向一致,此时方向导数为最大或者函数增长最快,换句话说:从一点出发,沿各个方向的变化率,哪个方向的变化率最大呢哪个方向最快呢,我们称其为梯度。

-
梯度下降就是让梯度中所有偏导函数(梯度的分量)都下降到最低点的过程,都下降到最低点了,那每个未知数(或者叫维度)的最优解就得到了,所以他是解决函数最优化问题的算法,梯度下降,下降的是 θ \theta θ,梯度下降中的下降,意思是让函数的未知数随着梯度的方向运动,什么是梯度的方向呢?把这一点带入到梯度函数中,结果为正,那就把这一点的值变小一些,同时就是让梯度变小些;当这一点带入梯度函数中的结果为负的时候,就给这一点的值增大一些.
-
设定初始参数 θ \theta θ,不断迭代,使得 J ( θ ) J(\theta) J(θ)最小化( J ( θ ) J(\theta) J(θ)为最小二乘函数):
θ j : = θ j − α ∂ J ( θ ) ∂ θ \theta_j:=\theta_j-\alpha\frac{\partial{J(\theta)}}{\partial\theta} θj:=θj−α∂θ∂J(θ)
∂ J ( θ ) ∂ θ = ∂ ∂ θ j 1 2 ∑ i = 1 n ( f θ ( x ) ( i ) − y ( i ) ) 2 = 2 ∗ 1 2 ∑ i = 1 n ( f θ ( x ) ( i ) − y ( i ) ) ∗ ∂ ∂ θ j ( f θ ( x ) ( i ) − y ( i ) ) = ∑ i = 1 n ( f θ ( x ) ( i ) − y ( i ) ) ∗ ∂ ∂ θ j ( ∑ j = 0 d θ j x j ( i ) − y ( i ) ) ) = ∑ i = 1 n ( f θ ( x ) ( i ) − y ( i ) ) x j ( i ) \frac{\partial{J(\theta)}}{\partial\theta} = \frac{\partial}{\partial\theta_j}\frac{1}{2}\sum_{i=1}^{n}(f_\theta(x)^{(i)}-y^{(i)})^2 \\ = 2*\frac{1}{2}\sum_{i=1}^{n}(f_\theta(x)^{(i)}-y^{(i)})*\frac{\partial}{\partial\theta_j}(f_\theta(x)^{(i)}-y^{(i)}) \\ = \sum_{i=1}^{n}(f_\theta(x)^{(i)}-y^{(i)})*\frac{\partial}{\partial\theta_j}(\sum_{j=0}^{d}\theta_jx_j^{(i)}-y^{(i)}))\\ = \sum_{i=1}^{n}(f_\theta(x)^{(i)}-y^{(i)})x_j^{(i)} ∂θ∂J(θ)=∂θj∂21i=1∑n(fθ(x)(i)−y(i))2=2∗21i=1∑n(fθ(x)(i)−y(i))∗∂θj∂(fθ(x)(i)−y(i))=i=1∑n(fθ(x)(i)−y(i))∗∂θj∂(j=0∑dθjxj(i)−y(i)))=i=1∑n(fθ(x)(i)−y(i))xj(i)
即:
θ j = θ j + α ∑ i = 1 n ( y ( i ) − f θ ( x ) ( i ) ) x j ( i ) \theta_j = \theta_j + \alpha\sum_{i=1}^{n}(y^{(i)}-f_\theta(x)^{(i)})x_j^{(i)} θj=θj+αi=1∑n(y(i)−fθ(x)(i))xj(i)
注:下标j表示第j个参数,上标i表示第i个数据点。
将所有的参数以向量形式表示,可得:
θ = θ + α ∑ i = 1 n ( y ( i ) − f θ ( x ) ( i ) ) x ( i ) \theta = \theta + \alpha\sum_{i=1}^{n}(y^{(i)}-f_\theta(x)^{(i)})x^{(i)} θ=θ+αi=1∑n(y(i)−fθ(x)(i))x(i)
由于这个方法中,参数在每一个数据点上同时进行了移动,因此称为批梯度下降法(对所有样本进行计算处理)。
- 优点:
- 1.一次迭代是对所有样本进行计算,此时利用矩阵进行操作,实现了并行。
- 2.由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向,且迭代次数少。当目标函数为凸函数时,BGD一定能够得到全局最优。
- 缺点:
- 1.当样本数目 m m m很大时,每迭代一步都需要对所有样本计算,训练过程会很慢。
对应的,我们可以每一次让参数只针对一个数据点(样本)进行移动,即:
θ = θ + α ( y ( i ) − f θ ( x ) ( i ) ) x ( i ) \theta = \theta + \alpha(y^{(i)}-f_\theta(x)^{(i)})x^{(i)} θ=θ+α(y(i)−fθ(x)(i))x(i)
这个算法成为随机梯度下降法,随机梯度下降法的好处是,当数据点很多时,运行效率更高;缺点是,因为每次只针对一个样本更新参数,未必找到最快路径达到最优值,甚至有时候会出现参数在最小值附近徘徊而不是立即收敛。但当数据量很大的时候,随机梯度下降法经常优于批梯度下降法。
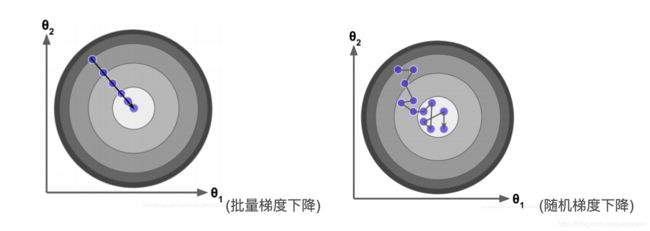
mini-bach-GD:随机抽取小批量数据来做下降
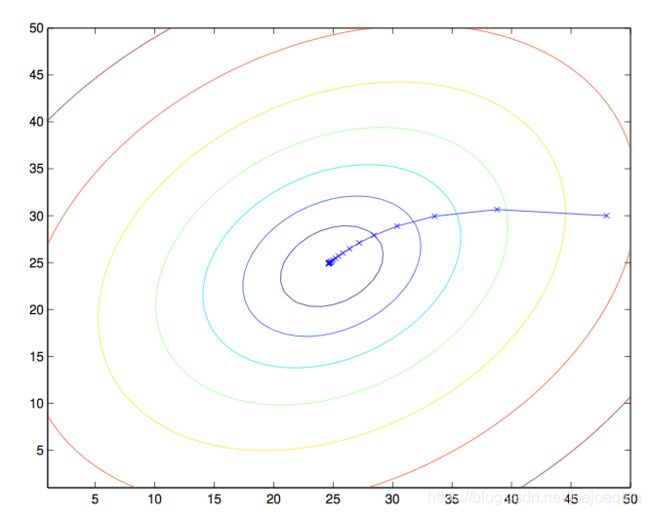
当J为凸函数时,梯度下降法相当于让参数 θ \theta θ不断向J的最小值位置移动
梯度下降法的缺陷:如果函数为非凸函数,有可能找到的并非全局最优值,而是局部最优值。
学习率 α \alpha α:让点沿着梯度方向下降慢慢求得最优解的过程我们叫做学习,学习率就是用来限制他每次学习别太过"用功"的,因为机器学习也存在书呆子:
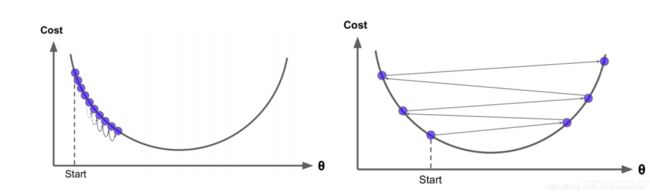
左图是我们所期望的,一个点按照梯度方向下降,慢慢逼近最低点,右图中展示的就是那个书呆子.模型每次下降都是减去梯度的值,当这个梯度值过大的时候,点下降的step就过大了,一次性迈过了最低点,导致函数无法找到最优解.
α \alpha α就是来限制这种情况的.我们让梯度乘以一个很小的数,虽然增加了它到达最低点的step数,但是可以让右图这种情况发生概率降低.
2、最小二乘法矩阵求解(正规方程)
令
X = [ ( x ( 1 ) ) T ( x ( 2 ) ) T … ( x ( n ) ) T ] X = \left[ \begin{array} {cccc} (x^{(1)})^T\\ (x^{(2)})^T\\ \ldots \\ (x^{(n)})^T \end{array} \right] X=⎣⎢⎢⎡(x(1))T(x(2))T…(x(n))T⎦⎥⎥⎤
其中,
x ( i ) = [ x 1 ( i ) x 2 ( i ) … x d ( i ) ] x^{(i)} = \left[ \begin{array} {cccc} x_1^{(i)}\\ x_2^{(i)}\\ \ldots \\ x_d^{(i)} \end{array} \right] x(i)=⎣⎢⎢⎢⎡x1(i)x2(i)…xd(i)⎦⎥⎥⎥⎤
由于
Y = [ y ( 1 ) y ( 2 ) … y ( n ) ] Y = \left[ \begin{array} {cccc} y^{(1)}\\ y^{(2)}\\ \ldots \\ y^{(n)} \end{array} \right] Y=⎣⎢⎢⎡y(1)y(2)…y(n)⎦⎥⎥⎤
h θ ( x ) h_\theta(x) hθ(x)可以写作
h θ ( x ) = X θ h_\theta(x)=X\theta hθ(x)=Xθ
对于向量来说,有
z T z = ∑ i z i 2 z^Tz = \sum_i z_i^2 zTz=i∑zi2
因此可以把损失函数写作
J ( θ ) = 1 2 ( X θ − Y ) T ( X θ − Y ) J(\theta)=\frac{1}{2}(X\theta-Y)^T(X\theta-Y) J(θ)=21(Xθ−Y)T(Xθ−Y)
为最小化 J ( θ ) J(\theta) J(θ),对 θ \theta θ求导可得:
∂ J ( θ ) ∂ θ = ∂ ∂ θ 1 2 ( X θ − Y ) T ( X θ − Y ) = 1 2 ∂ ∂ θ ( θ T X T X θ − Y T X θ − θ T X T Y − Y T Y ) \frac{\partial{J(\theta)}}{\partial\theta} = \frac{\partial}{\partial\theta} \frac{1}{2}(X\theta-Y)^T(X\theta-Y) \\ = \frac{1}{2}\frac{\partial}{\partial\theta} (\theta^TX^TX\theta - Y^TX\theta-\theta^T X^TY - Y^TY) ∂θ∂J(θ)=∂θ∂21(Xθ−Y)T(Xθ−Y)=21∂θ∂(θTXTXθ−YTXθ−θTXTY−YTY)
中间两项互为转置,由于求得的值是个标量,矩阵与转置相同,因此可以写成
∂ J ( θ ) ∂ θ = 1 2 ∂ ∂ θ ( θ T X T X θ − 2 θ T X T Y − Y T Y ) \frac{\partial{J(\theta)}}{\partial\theta} = \frac{1}{2}\frac{\partial}{\partial\theta} (\theta^TX^TX\theta - 2\theta^T X^TY - Y^TY) ∂θ∂J(θ)=21∂θ∂(θTXTXθ−2θTXTY−YTY)
令偏导数等于零,由于最后一项和 θ \theta θ无关,偏导数为0。
因此,
∂ J ( θ ) ∂ θ = 1 2 ∂ ∂ θ θ T X T X θ − ∂ ∂ θ θ T X T Y \frac{\partial{J(\theta)}}{\partial\theta} = \frac{1}{2}\frac{\partial}{\partial\theta} \theta^TX^TX\theta - \frac{\partial}{\partial\theta} \theta^T X^TY ∂θ∂J(θ)=21∂θ∂θTXTXθ−∂θ∂θTXTY
利用矩阵求导性质(这里主要用到标量对向量求导,一般是分母布局,因为损失函数是一个实值函数),
∂ x ⃗ T α ∂ x ⃗ = α \frac{\partial \vec x^T\alpha}{\partial \vec x} =\alpha ∂x∂xTα=α
和 和 和
∂ A T B ∂ x ⃗ = ∂ A T ∂ x ⃗ B + ∂ B T ∂ x ⃗ A \frac{\partial A^TB}{\partial \vec x} = \frac{\partial A^T}{\partial \vec x}B + \frac{\partial B^T}{\partial \vec x}A ∂x∂ATB=∂x∂ATB+∂x∂BTA
∂ ∂ θ θ T X T X θ = ∂ ∂ θ ( X θ ) T X θ = ∂ ( X θ ) T ∂ θ X θ + ∂ ( X θ ) T ∂ θ X θ = 2 X T X θ \frac{\partial}{\partial\theta} \theta^TX^TX\theta = \frac{\partial}{\partial\theta}{(X\theta)^TX\theta}\\ = \frac{\partial (X\theta)^T}{\partial\theta}X\theta + \frac{\partial (X\theta)^T}{\partial\theta}X\theta \\ = 2X^TX\theta ∂θ∂θTXTXθ=∂θ∂(Xθ)TXθ=∂θ∂(Xθ)TXθ+∂θ∂(Xθ)TXθ=2XTXθ
此步求导用微分法: d ( t r ( θ T X T X θ ) ) = t r ( d ( θ T ) X T X θ + θ T X T X d ( θ ) ) = t r ( d ( θ T ) X T X θ ) + t r ( θ T X T X d ( θ ) ) = t r ( ( d θ ) T X T X θ ) + t r ( θ T X T X d θ ) = t r ( θ T X X T d θ ) + t r ( θ T X T X d θ ) = t r ( 2 θ T X X T d θ ) d(tr(\theta^TX^TX\theta)) = tr(d(\theta^T)X^TX\theta+\theta^TX^TXd(\theta))=tr(d(\theta^T)X^TX\theta)+tr(\theta^TX^TXd(\theta))=tr((d\theta)^TX^TX\theta)+tr(\theta^TX^TXd\theta)=tr(\theta^TXX^Td\theta)+tr(\theta^TX^TXd\theta)=tr(2\theta^TXX^Td\theta) d(tr(θTXTXθ))=tr(d(θT)XTXθ+θTXTXd(θ))=tr(d(θT)XTXθ)+tr(θTXTXd(θ))=tr((dθ)TXTXθ)+tr(θTXTXdθ)=tr(θTXXTdθ)+tr(θTXTXdθ)=tr(2θTXXTdθ),即 ∂ ∂ θ ( θ T X T X θ ) = ( 2 θ T X X T ) T = 2 X T X θ \frac{\partial}{\partial\theta} (\theta^TX^TX\theta)=(2\theta^TXX^T)^T=2X^TX\theta ∂θ∂(θTXTXθ)=(2θTXXT)T=2XTXθ
第二个等于用到了微分转置 d ( X T ) = ( d X ) T d(X^T)=(dX)^T d(XT)=(dX)T,第三个等于用到了迹的转置不变 t r ( A T ) = t r ( A ) tr(A^T)=tr(A) tr(AT)=tr(A)
向量,矩阵之间求导可以参考:https://www.cnblogs.com/pinard/p/10750718.html
∂ J ( θ ) ∂ θ = X T X θ − X T Y \frac{\partial{J(\theta)}}{\partial\theta} = X^TX\theta - X^TY ∂θ∂J(θ)=XTXθ−XTY
令导数等于零,
X T X θ = X T Y X^TX\theta = X^TY XTXθ=XTY
θ = ( X T X ) ( − 1 ) X T Y \theta = (X^TX)^{(-1)}X^TY θ=(XTX)(−1)XTY
注:CS229视频中吴恩达的推导利用了矩阵迹的性质,可自行参考学习。
3、牛顿法
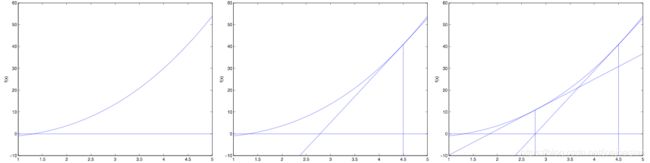
通过图例可知(参考吴恩达CS229),
f ( θ ) ′ = f ( θ ) Δ , Δ = θ 0 − θ 1 f(\theta)' = \frac{f(\theta)}{\Delta},\Delta = \theta_0 - \theta_1 f(θ)′=Δf(θ),Δ=θ0−θ1
可 求 得 , θ 1 = θ 0 − f ( θ 0 ) f ( θ 0 ) ′ 可求得,\theta_1 = \theta_0 - \frac {f(\theta_0)}{f(\theta_0)'} 可求得,θ1=θ0−f(θ0)′f(θ0)
重复迭代,可以让逼近取到 f ( θ ) f(\theta) f(θ)的最小值
当我们对损失函数 l ( θ ) l(\theta) l(θ)进行优化的时候,实际上是想要取到 l ′ ( θ ) l'(\theta) l′(θ)的最小值,因此迭代公式为:
θ : = θ − l ′ ( θ ) l ′ ′ ( θ ) \theta :=\theta-\frac{l'(\theta)}{l''(\theta)} θ:=θ−l′′(θ)l′(θ)
当 θ 是 向 量 值 的 时 候 , θ : = θ − H − 1 Δ θ l ( θ ) 当\theta是向量值的时候,\theta :=\theta - H^{-1}\Delta_{\theta}l(\theta) 当θ是向量值的时候,θ:=θ−H−1Δθl(θ)
其中, Δ θ l ( θ ) \Delta_{\theta}l(\theta) Δθl(θ)是 l ( θ ) l(\theta) l(θ)对 θ i \theta_i θi的偏导数, H H H是 J ( θ ) J(\theta) J(θ)的海森矩阵,
H i j = ∂ 2 l ( θ ) ∂ θ i ∂ θ j H_{ij} = \frac{\partial ^2l(\theta)}{\partial\theta_i\partial\theta_j} Hij=∂θi∂θj∂2l(θ)
问题:请用泰勒展开法推导牛顿法公式。
Answer:将 f ( x ) f(x) f(x)用泰勒公式在 x 0 x_0 x0处展开到第二阶,
f ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) + 1 2 f ′ ′ ( x 0 ) ( x − x 0 ) 2 f(x) = f(x_0) + f'(x_0)(x - x_0)+\frac{1}{2}f''(x_0)(x - x_0)^2 f(x)=f(x0)+f′(x0)(x−x0)+21f′′(x0)(x−x0)2
写成定义中的形式就是: f ( x ) = f ( x ( k ) ) + g k T ( x − x ( k ) ) + 1 2 ( x − x ( k ) ) T H ( x ( x ) ) ( x − x ( k ) ) f(x)=f(x^{(k)})+g_k^T(x-x^{(k)})+\frac{1}{2}(x-x^{(k)})^TH(x^{(x)})(x-x^{(k)}) f(x)=f(x(k))+gkT(x−x(k))+21(x−x(k))TH(x(x))(x−x(k)),其中 g k T g_k^T gkT就是 f ( x ) f(x) f(x)梯度向量在 x ( k ) x^{(k)} x(k)处的值, H ( x ( x ) ) H(x^{(x)}) H(x(x))就是海森矩阵,要想让 f ( x ) f(x) f(x)有极小值的必要条件就是:1.有使得一阶导数等于0的点,2.二阶导数在该点大于0(极小值的原因,微积分中判定方法之一),重点就在于解第一个条件:使 f ( x ) f(x) f(x)梯度为0的点,即 ∇ f ( x ) = g k + H ( x ( k ) ) ( x − x ( k ) ) = 0 \nabla f(x)=g_k+H(x^{(k)})(x-x^{(k)})=0 ∇f(x)=gk+H(x(k))(x−x(k))=0,各项维度为 n ∗ 1 , n ∗ n , n ∗ 1 n*1 , n*n , n*1 n∗1,n∗n,n∗1,得 x = x ( k ) − H k − 1 g k = x ( k ) + p k x=x^{(k)}-H_k^{-1}g_k=x^{(k)}+p_k x=x(k)−Hk−1gk=x(k)+pk,即可以写成 x ( k + 1 ) = x ( k ) − H k − 1 g k = x ( k ) + p k x^{(k+1)}=x^{(k)}-H_k^{-1}g_k=x^{(k)}+p_k x(k+1)=x(k)−Hk−1gk=x(k)+pk,这里的 x ( k + 1 ) x^{(k+1)} x(k+1)就是 x x x
对上式求导,并令导数等于0,求得x值
f ′ ( x ) = f ′ ( x 0 ) + f ′ ′ ( x 0 ) x − f ′ ′ ( x 0 ) x 0 = 0 f'(x) = f'(x_0) + f''(x_0)x -f''(x_0)x_0 = 0 f′(x)=f′(x0)+f′′(x0)x−f′′(x0)x0=0
可以求得,
x = x 0 − f ′ ( x 0 ) f ′ ′ ( x 0 ) x = x_0 - \frac{f'(x_0)}{f''(x_0)} x=x0−f′′(x0)f′(x0)
牛顿法的收敛速度非常快,但海森矩阵的计算较为复杂,尤其当参数的维度很多时,会耗费大量计算成本。我们可以用其他矩阵替代海森矩阵,用拟牛顿法进行估计,
牛顿法算法步骤:
输入:目标函数 f ( x ) f(x) f(x),梯度 g ( x ) = ∇ f ( x ) g(x)=\nabla f(x) g(x)=∇f(x),海森矩阵 H ( x ) H(x) H(x),精度要求 ϵ \epsilon ϵ
输出: f ( x ) f(x) f(x)的极小点 x ∘ x^{\circ} x∘
1.取初始点 x ( 0 ) x^{(0)} x(0),置 k = 0 k=0 k=0
2.计算 g k = g ( x ( k ) ) g_k=g(x^{(k)}) gk=g(x(k)),(直接算,代入到梯度中,不是到那个推导极小值点的式子里)
3.若 ∣ ∣ g k ∣ ∣ < ϵ ||g_k||<\epsilon ∣∣gk∣∣<ϵ,则停止计算,得近似解 x ∘ = x ( k ) x^{\circ}=x^{(k)} x∘=x(k)
4.计算 H k = H ( x ( k ) ) H_k=H(x^{(k)}) Hk=H(x(k)),并求 p k p_k pk, H k p k = − g k H_kp_k=-g_k Hkpk=−gk
5.置 x ( k + 1 ) = x ( k ) + p k x^{(k+1)}=x^{(k)}+p_k x(k+1)=x(k)+pk
6.置 k = k + 1 k=k+1 k=k+1,转2
4、拟牛顿法
拟牛顿法的思路是用一个矩阵替代计算复杂的海森矩阵H,因此要找到符合H性质的矩阵。
要求得海森矩阵符合的条件,同样对泰勒公式求导 f ′ ( x ) = f ′ ( x 0 ) + f ′ ′ ( x 0 ) x − f ′ ′ ( x 0 ) x 0 f'(x) = f'(x_0) + f''(x_0)x -f''(x_0)x_0 f′(x)=f′(x0)+f′′(x0)x−f′′(x0)x0
令 x = x 1 x = x_1 x=x1,即迭代后的值,代入可得:
f ′ ( x 1 ) = f ′ ( x 0 ) + f ′ ′ ( x 0 ) x 1 − f ′ ′ ( x 0 ) x 0 f'(x_1) = f'(x_0) + f''(x_0)x_1 - f''(x_0)x_0 f′(x1)=f′(x0)+f′′(x0)x1−f′′(x0)x0
更一般的,
f ′ ( x k + 1 ) = f ′ ( x k ) + f ′ ′ ( x k ) x k + 1 − f ′ ′ ( x k ) x k f'(x_{k+1}) = f'(x_k) + f''(x_k)x_{k+1} - f''(x_k)x_k f′(xk+1)=f′(xk)+f′′(xk)xk+1−f′′(xk)xk
f ′ ( x k + 1 ) − f ′ ( x k ) = f ′ ′ ( x k ) ( x k + 1 − x k ) = H ( x k + 1 − x k ) f'(x_{k+1}) - f'(x_k) = f''(x_k)(x_{k+1}- x_k)= H(x_{k+1}- x_k) f′(xk+1)−f′(xk)=f′′(xk)(xk+1−xk)=H(xk+1−xk)
x k x_k xk为第k个迭代值
即找到矩阵G,使得它符合上式。
常用的拟牛顿法的算法包括DFP,BFGS等,作为选学内容,有兴趣者可自行查询材料学习。
DFP:用 G k G_k Gk代替 H − 1 H^-1 H−1
BFGS:用 G k G_k Gk代替 H H H
DFP
∇ f ( x ) = g k + H ( x ( k ) ) ( x − x ( k ) ) \nabla f(x)=g_k+H(x^{(k)})(x-x^{(k)}) ∇f(x)=gk+H(x(k))(x−x(k))
当 x = x ( k + 1 ) x=x^{(k+1)} x=x(k+1),即 g k + 1 = g k + H k ( x ( k + 1 ) − x ( k ) ) g_{k+1}=g_k+H_k(x^{(k+1)}-x^{(k)}) gk+1=gk+Hk(x(k+1)−x(k))
记: y k = g k + 1 − g k y_k = g_{k+1}-g_k yk=gk+1−gk
σ k = x ( k + 1 ) − x ( k ) \sigma_k=x^{(k+1)}-x^{(k)} σk=x(k+1)−x(k)
得: y k = H k σ k y_k=H_k\sigma_k yk=Hkσk
H k − 1 y k = σ k H_k^{-1}y_k=\sigma_k Hk−1yk=σk,则称其为拟牛顿条件, G k G_k Gk代替 H k H_k Hk还需要满足一个条件就是正定
所以,就是要找一个 G k G_k Gk满足正定和拟牛顿法的两个条件,每次迭代代入就可以了
设 G k + 1 = G k + p k + Q k G_{k+1}=G_k+p_k+Q_k Gk+1=Gk+pk+Qk
两边同乘 y k y_k yk得: G k + 1 y k = G k y k + p k y k + Q k y k G_{k+1}y_k=G_ky_k+p_ky_k+Q_ky_k Gk+1yk=Gkyk+pkyk+Qkyk
令: p k y k = σ k , Q k y k = − G k y k p_ky_k=\sigma_k,Q_ky_k=-G_ky_k pkyk=σk,Qkyk=−Gkyk
得: p k = σ k σ k t σ k T y k , Q k = − G k y k y k T G k y k T G k y k p_k=\frac{\sigma_k \sigma_k^t}{\sigma_k^T y_k},Q_k=-\frac{G_k y_ky_k^TG_k}{y_k^TG_ky_k} pk=σkTykσkσkt,Qk=−ykTGkykGkykykTGk
即: G k + 1 = G k + σ k σ k t σ k T y k − G k y k y k T G k y k T G k y k G_{k+1}=G_k+\frac{\sigma_k \sigma_k^t}{\sigma_k^T y_k}-\frac{G_k y_ky_k^TG_k}{y_k^TG_ky_k} Gk+1=Gk+σkTykσkσkt−ykTGkykGkykykTGk
若初始矩阵 G 0 G_0 G0是正定,可得 G k G_k Gk都是正定的
算法流程:
输入:目标函数 f ( x ) f(x) f(x),梯度 g ( x ) = ∇ f ( x ) g(x)=\nabla f(x) g(x)=∇f(x),海森矩阵 H ( x ) H(x) H(x),精度要求 ϵ \epsilon ϵ
输出: f ( x ) f(x) f(x)的极小点 x ∘ x^{\circ} x∘
1.初始点 x ( 0 ) x^{(0)} x(0), G 0 G_0 G0为正定矩阵, k = 0 k=0 k=0
2.计算 g k g_k gk
3.若 ∣ ∣ g k ∣ ∣ < ϵ ||g_k||<\epsilon ∣∣gk∣∣<ϵ,则停止计算,得近似解 x ∘ = x ( k ) x^{\circ}=x^{(k)} x∘=x(k)
4.计算 p k = − G k g k p_k=-G_kg_k pk=−Gkgk,一维搜索: f ( x ( k ) + λ k p k ) = min λ ≥ 0 f ( x ( k ) + λ k p k ) f(x^{(k)}+\lambda_kp_k)=\min\limits_{\lambda \geq 0}f(x^{(k)}+\lambda_kp_k) f(x(k)+λkpk)=λ≥0minf(x(k)+λkpk),用正定对称矩阵近似海森矩阵时,只知道下降方向是对的,但是不知道下降多少,所以进行一维搜索,虽然带来时间复杂度,但也比远远小于直接求逆
5.置 x ( k + 1 ) = x ( k ) + λ k p k x^{(k+1)}=x^{(k)}+\lambda_kp_k x(k+1)=x(k)+λkpk
6.置 k = k + 1 k=k+1 k=k+1,转2
BFGS:
用 B k → H B_k \rightarrow H Bk→H,拟牛顿条件就是 B k + 1 σ k = y k B_{k+1}\sigma_k=y_k Bk+1σk=yk
B k + 1 = B k + p k σ k + Q k σ k B_{k+1}={B_k}+p_k\sigma_k+Q_k\sigma_k Bk+1=Bk+pkσk+Qkσk
p k σ k = y k , Q k σ k = − B k σ k p_k\sigma_k=y_k,Q_k\sigma_k=-B_k\sigma_k pkσk=yk,Qkσk=−Bkσk代入上面式子
B k + 1 = B k + y k y k T y k T σ k − B k σ k σ k T B k σ k T b k σ k B_{k+1}=B_k+\frac{y_k y_k^T}{y_k^T\sigma_k}-\frac{B_k \sigma_k\sigma_k^TB_k}{\sigma_k^Tb_k\sigma_k} Bk+1=Bk+ykTσkykykT−σkTbkσkBkσkσkTBk
若 B 0 B_0 B0正定, B k B_k Bk都是正定的
4、线性回归的评价指标
均方误差(MSE): 1 m ∑ i = 1 m ( y ( i ) − y ^ ( i ) ) 2 \frac{1}{m}\sum^{m}_{i=1}(y^{(i)} - \hat y^{(i)})^2 m1∑i=1m(y(i)−y^(i))2
均方根误差(RMSE): M S E = 1 m ∑ i = 1 m ( y ( i ) − y ^ ( i ) ) 2 \sqrt{MSE} = \sqrt{\frac{1}{m}\sum^{m}_{i=1}(y^{(i)} - \hat y^{(i)})^2} MSE=m1∑i=1m(y(i)−y^(i))2
平均绝对误差(MAE):$\frac{1}{m}\sum^{m}_{i=1} | (y^{(i)} - \hat y^{(i)} | $
但以上评价指标都无法消除量纲不一致而导致的误差值差别大的问题,最常用的指标是 R 2 R^2 R2,可以避免量纲不一致问题
R 2 : = 1 − ∑ i = 1 m ( y ( i ) − y ^ ( i ) ) 2 ∑ i = 1 m ( y ˉ − y ^ ( i ) ) 2 = 1 − 1 m ∑ i = 1 m ( y ( i ) − y ^ ( i ) ) 2 1 m ∑ i = 1 m ( y ˉ − y ^ ( i ) ) 2 = 1 − M S E V A R R^2: = 1-\frac{\sum^{m}_{i=1}(y^{(i)} - \hat y^{(i)})^2}{\sum^{m}_{i=1}(\bar y - \hat y^{(i)})^2} =1-\frac{\frac{1}{m}\sum^{m}_{i=1}(y^{(i)} - \hat y^{(i)})^2}{\frac{1}{m}\sum^{m}_{i=1}(\bar y - \hat y^{(i)})^2} = 1-\frac{MSE}{VAR} R2:=1−∑i=1m(yˉ−y^(i))2∑i=1m(y(i)−y^(i))2=1−m1∑i=1m(yˉ−y^(i))2m1∑i=1m(y(i)−y^(i))2=1−VARMSE
我们可以把 R 2 R^2 R2理解为,回归模型可以成功解释的数据方差部分在数据固有方差中所占的比例, R 2 R^2 R2越接近1,表示可解释力度越大,模型拟合的效果越好。
5、sklearn.linear_model参数详解:
fit_intercept : 默认为True,是否计算该模型的截距。如果使用中心化的数据,可以考虑设置为False,不考虑截距。注意这里是考虑,一般还是要考虑截距
normalize: 默认为false. 当fit_intercept设置为false的时候,这个参数会被自动忽略。如果为True,回归器会标准化输入参数:减去平均值,并且除以相应的二范数。当然啦,在这里还是建议将标准化的工作放在训练模型之前。通过设置sklearn.preprocessing.StandardScaler来实现,而在此处设置为false
copy_X : 默认为True, 否则X会被改写
n_jobs: int 默认为1. 当-1时默认使用全部CPUs ??(这个参数有待尝试)
可用属性:
coef_:训练后的输入端模型系数,如果label有两个,即y值有两列。那么是一个2D的array
intercept_: 截距
可用的methods:
fit(X,y,sample_weight=None):
X: array, 稀疏矩阵 [n_samples,n_features]
y: array [n_samples, n_targets]
sample_weight: 权重 array [n_samples]
在版本0.17后添加了sample_weight
get_params(deep=True): 返回对regressor 的设置值
predict(X): 预测 基于 R^2值
score: 评估
参考https://blog.csdn.net/weixin_39175124/article/details/79465558
生成数据
#生成数据
import numpy as np
#生成随机数
np.random.seed(1234)
x = np.random.rand(500,2) # 生成500*3的每个元素不超过1的正小数
# 构建映射关系,模拟真实的数据待预测值,映射关系为y = 4.2 + 5.7*x1 + 10.8*x2,可自行设置值进行尝试
# 原文件这里有错误
y = x.dot(np.array([5.7,10.8])) + 4.2
x.shape, y.shape
((500, 2), (500,))
np中矩阵乘法
# 一维向量和一维向量
e = np.array([1, 2, 3])
f = np.array([4, 5, 6])
print(e * f) # 对应位置相乘但不相加求和
print(np.inner(e, f)) # 算内积为32 对应位置的元素相乘相加求和
# 对于两个一维向量相当于求内积
print(np.dot(e, f)) # 32
print(np.dot(e, f.T)) # 32
print(np.dot(e.T, f)) # 32
print(np.dot(e.T, f.T)) # 32
# 对于两个一维向量相当于求内积
print(e @ f) # 32
print(e @ f.T) # 32
print(e.T @ f) # 32
print(e.T @ f.T) # 32
# 下面来解释一下为什么.T和没有都是一样,是因为直接用.T并没有将行向量转为列向量
print(e.T) # 没变
print(np.array([e]).T) # 先变二维,再转置,ok
print(e.reshape(1, -1).T) # ok
[ 4 10 18]
32
32
32
32
32
32
32
32
32
[1 2 3]
[[1]
[2]
[3]]
[[1]
[2]
[3]]
二维矩阵和一维向量
m = np.array([[1, 2], [3, 4]])
n = np.array([1, 2])
# 每一行对应的元素与向量相乘求和,作为结果各元素,组成行向量
print(np.inner(m, n)) # [ 5 11] 其实就是将n转置,然后m乘以n的转置,最后再转置为行
# dot()相当于inner()
print(m.dot(n)) # [ 5 11] 相当于把向量转置变成2*1,按矩阵乘法规则,最后再转置变成1*2
# 相当于inner()
print(m @ n) # [ 5 11] 同上
# 每一行对应的元素与向量相乘求但不求和,分别作为结果各元素,组成行向量
print(m * n) # [[1, 4], [3, 8]]
# 反过来
print(np.inner(n, m)) # 还是求内积 将m转置,和之前一样,结果为行,就不需要转置
print(n.dot(m)) # 矢量乘法,此时是 1*2的向量和2*2的矩阵相乘,所以结果为1*2,[ 7 10]
print(n @ m) # 矢量乘法,同上
print(n * m) # 这个还是数量积 [[1, 4], [3, 8]]
[ 5 11]
[ 5 11]
[ 5 11]
[[1 4]
[3 8]]
[ 5 11]
[ 7 10]
[ 7 10]
[[1 4]
[3 8]]
二维矩阵和二维矩阵
a = np.array([[1, 2], [3, 4]])
b = np.array([[4, 3], [2, 1]])
# array
print(a * b) # 各位置相乘 数量积(即对应位置元素相乘)
print(np.multiply(a, b)) # 数量积
print(a @ b) # 按矩阵规则乘 矢量乘法
print(a.dot(b)) # 按矩阵规则乘 矢量乘法
print(np.inner(a, b)) # [[10 4], [24 10]] 将b转置,得到的结果
# matrix
c = np.matrix([[1,2],[3,4]])
d = np.matrix([[4,3],[2,1]])
print(np.multiply(c, d)) # 各位置相乘 数量积(即对应位置元素相乘后的积相加)
print(c * d) # 矢量乘法
print(c @ d) # 按矩阵规则乘
print(c.dot(d)) # 按矩阵规则乘 矢量乘法
print(np.inner(c, d)) # [[10 4], [24 10]] 将d转置,得到的结果
g = np.matrix([1, 2, 3])
h = np.matrix([4, 5, 6])
print(g @ h.T) # 返回的是矩阵 [[32]]
[[4 6]
[6 4]]
[[4 6]
[6 4]]
[[ 8 5]
[20 13]]
[[ 8 5]
[20 13]]
[[10 4]
[24 10]]
[[4 6]
[6 4]]
[[ 8 5]
[20 13]]
[[ 8 5]
[20 13]]
[[ 8 5]
[20 13]]
[[10 4]
[24 10]]
[[32]]
1、先尝试调用sklearn的线性回归模型训练数据
import numpy as np
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
%matplotlib inline
# 调用模型
lr = LinearRegression(fit_intercept=True)
# 训练模型
lr.fit(x, y)
print("估计的参数值为:%s" %(lr.coef_))
# 计算R平方
print('R2:%s' %(lr.score(x,y)))
# 任意设定变量,预测目标值
x_test = np.array([4,5]).reshape(1,-1)
y_hat = lr.predict(x_test)
print("预测值为: %s" %(y_hat))
估计的参数值为:[ 5.7 10.8]
R2:1.0
预测值为: [81.]
2、最小二乘法的矩阵求解(正规方程)
class LR_LS():
def __init__(self):
self.w = None
def fit(self, X, y):
# 最小二乘法矩阵求解
#============================= show me your code =======================
self.w = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y)
#============================= show me your code =======================
def predict(self, X):
# 用已经拟合的参数值预测新自变量
#============================= show me your code =======================
y_pred = X.dot(self.w)
#============================= show me your code =======================
return y_pred
if __name__ == "__main__":
lr_ls = LR_LS()
lr_ls.fit(x,y)
print("估计的参数值:%s" %(lr_ls.w))
x_test = np.array([4,5]).reshape(1,-1)
print("预测值为: %s" %(lr_ls.predict(x_test)))
估计的参数值:[ 9.09571334 14.41433265]
预测值为: [108.45451663]
3、梯度下降法(BGD)
class LR_GD():
def __init__(self):
self.w = None
def fit(self, X, y, alpha=0.02, loss=1e-10): # 设定步长为0.002,判断是否收敛的条件为1e-10
y = y.reshape(-1,1) #重塑y值的维度以便矩阵运算
[m, d] = np.shape(X) #自变量的维度
self.w = np.zeros((d)) #将参数的初始值定为0
tol = 1e5
#============================= show me your code =======================
while tol > loss:
h_f = X.dot(self.w).reshape(-1,1)
theta = self.w + alpha * np.mean(X * (y - h_f),axis=0) #计算迭代的参数值
# axis=0 ,每行
tol = np.sum(np.abs(theta - self.w))
self.w = theta # 同时更新
#============================= show me your code =======================
def predict(self, X):
# 用已经拟合的参数值预测新自变量
y_pred = X.dot(self.w)
return y_pred
if __name__ == "__main__":
lr_gd = LR_GD()
lr_gd.fit(x,y)
print("估计的参数值为:%s" %(lr_gd.w))
x_test = np.array([4,5]).reshape(1,-1)
print("预测值为:%s" %(lr_gd.predict(x_test)))
估计的参数值为:[ 9.09571337 14.41433262]
预测值为:[108.4545166]
4.mini-batch
class LR_GD_M():
def __init__(self):
self.w = None # 参数
self.k = 0 # m的下标
def fit(self, X, y, alpha=0.02, loss=1e-10):
y = y.reshape(-1, 1) # 变成列向量
[m, d] = np.shape(X)
self.w = np.zeros((d))
tol = 1e5
while tol > loss:
if self.k < len(y):
# 抽10个
# 抽取小批量的数据
train_size = x.shape[0]
batch_size = 10 # 抽10个
batch_mask = np.random.choice(train_size, batch_size) # 从6000个数据中随机抽取10个 获得其索引
x_batch = x[batch_mask] # 通过索引取出该值
y_batch = y[batch_mask] # 通过索引去除该监督值
h_f = x_batch.dot(self.w).reshape(-1, 1)
theta = self.w + alpha * np.sum(x_batch * (y_batch - h_f), axis=0)
# h_f = X[self.k:self.k+100,:].dot(self.w).reshape(-1, 1)
# theta = self.w + alpha * np.sum(X[self.k:self.k+100] * (y[self.k:self.k+100] - h_f), axis=0)
tol = np.sum(np.abs(theta - self.w))
self.w = theta
self.k += 10
else:
break
def predict(self, X):
# 用已经拟合的参数值预测新自变量
y_pred = X.dot(self.w)
return y_pred
if __name__ == "__main__":
lr_gd_m = LR_GD_M()
lr_gd_m.fit(x,y)
print("估计的参数值为:%s" %(lr_gd_m.w))
x_test = np.array([4,5]).reshape(1,-1)
print("预测值为:%s" %(lr_gd_m.predict(x_test)))
估计的参数值为:[10.42892327 13.28206545]
预测值为:[108.1260203]
最后针对极大似然估计,再来补充一下经典贝叶斯公式:
p ( ω ∣ x ) = p ( x ∣ ω ) p ( ω ) p ( x ) p(\omega|x)=\frac{p(x|\omega)p(\omega)}{p(x)} p(ω∣x)=p(x)p(x∣ω)p(ω)
其中:
p ( ω ) p(\omega) p(ω):为先验概率,表示每种类别分布的概率;
p ( x ∣ ω ) p(x|\omega) p(x∣ω):为类条件概率,表示在某种类别前提下,某事发生的概率;
p ( ω ∣ x ) p(\omega|x) p(ω∣x):为后验概率,表示某事发生了,并且它属于某一类别的概率,有了这个后验概率,我们就可以对样本进行分类。后验概率越大,说明某事物属于这个类别的可能性越大,我们越有理由把它归到这个类别下。
举例:
**已知:**在夏季,某公园男性穿凉鞋的概率为 1 / 2 1/2 1/2,女性穿凉鞋的概率为 2 / 3 2/3 2/3,并且该公园中男女比例通常为2:1,**问题:**若你在公园中随机遇到一个穿凉鞋的人,请问他的性别为男性或女性的概率分别为多少?
从问题看,就是上面讲的,某事发生了,它属于某一类别的概率是多少?即后验概率。
设: ω 1 = \omega_1= ω1=男性, ω 2 = \omega_2= ω2=女性, x = x= x=穿凉鞋
由已知可知:
先验概率 p ( ω 1 ) = 2 / 3 , p ( ω 2 ) = 1 / 3 p(\omega_1)=2/3,p(\omega_2)=1/3 p(ω1)=2/3,p(ω2)=1/3
类条件概率 p ( x ∣ ω 1 ) = 1 / 2 , p ( x ∣ ω 2 ) = 2 / 3 p(x|\omega_1)=1/2,p(x|\omega_2)=2/3 p(x∣ω1)=1/2,p(x∣ω2)=2/3
男性和女性穿凉鞋相互独立,所以
p ( x ) = p ( x ∣ ω 1 ) p ( ω 1 ) + p ( x ∣ ω 2 ) p ( ω 2 ) = 5 / 9 p(x)=p(x|\omega_1)p(\omega_1)+p(x|\omega_2)p(\omega_2)=5/9 p(x)=p(x∣ω1)p(ω1)+p(x∣ω2)p(ω2)=5/9
p ( ω 1 ∣ x ) = p ( x ∣ ω 1 ) p ( ω 1 ) p ( x ) = 3 / 5 p(\omega_1|x)=\frac{p(x|\omega_1)p(\omega_1)}{p(x)}=3/5 p(ω1∣x)=p(x)p(x∣ω1)p(ω1)=3/5
p ( ω 2 ∣ x ) = p ( x ∣ ω 2 ) p ( ω 2 ) p ( x ) = 2 / 5 p(\omega_2|x)=\frac{p(x|\omega_2)p(\omega_2)}{p(x)}=2/5 p(ω2∣x)=p(x)p(x∣ω2)p(ω2)=2/5
参考
吴恩达 CS229课程
周志华 《机器学习》
李航 《统计学习方法》
https://hangzhou.anjuke.com/
https://www.jianshu.com/p/e0eb4f4ccf3e
https://blog.csdn.net/qq_28448117/article/details/79199835
https://blog.csdn.net/weixin_39175124/article/details/79465558
https://blog.csdn.net/zengxiantao1994/article/details/72787849