深入理解计算机系统之异常控制流----fork打印问题
异常是允许操作系统提供进程的概念所需要的基本构造块,进程是计算机科学中最深刻最成功的概念之一。
进程的经典定义就是一个执行中的程序的实例。系统中的每个程序都是运行在某个进行上下文中的。上下文是由程序正确运行所需的状态组成的。这个状态包括存放在存储器中的程序的代码和数据,它的栈,通用目的寄存器的内容,程序计数器,环境变量以及打开文件描述符的集合。
每次用户通过向外壳输入一个可执行目标文件的名字,并运行一个程序时,外壳就会创建一个新的进程,然后再这个新进程的上下文中运行这个可执行目标文件。应用程序也能够创建新进程,且在这个新进程的上下文中运行它们自己的代码或其他应用程序。
用户模式和内核模式:
运行应用程序代码的进程初始是在用户模式中的。进程从用户模式变成内核模式的唯一方法是通过诸如中断,故障或者陷入系统调用这样的异常。当异常发生时,控制传递大哦哦异常处理程序,处理器将模式从用户模式变成内核模式。处理程序运行在内核模式中,当塔返回应用程序代码是,处理器就把模式从内核模式改回用户模式。
Linux提供了一种聪明的机制,叫做/proc文件系统,它允许用户模式进程访问内核数据结构的内容。/proc文件系统将许多内核数据结构的内容输出为一个用户程序可以读的文本文件的层次结构.
上下文切换
操作系统内核使用一种称为上下文切换的较高层形式的异常控制流来实现多任务。上下文切换机制是建立在较底层的异常机制之上的。
内核为每个进程维持一个上下文。上下文就是内核重新启动一个被抢占的进程所需的状态。它由一些对象的值组成,这些对象包括通用目的寄存器、浮点寄存器、程序计算器、用户栈、状态寄存器、内核栈、和各种内核数据结构。
我们最后来看看几道关于fork的题目:
关于fork的定义如下:
函数原型
函数说明

-
fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:
在父进程中,fork返回新创建子进程的进程ID; -
在子进程中,fork返回0;
-
如果出现错误,fork返回一个负值。
题目1;
|
1
2 3 4 5 6 7 8 9 10 11 12 13 |
#include #include int main() { int i; for(i = 0; i < 2; i++) fork(); printf( "hello\n"); exit( 0); } |
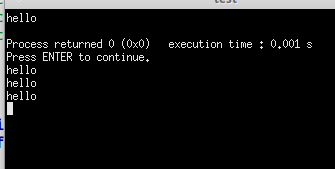
输出四行的hello
题目2:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#include #include void doit() { fork(); fork(); printf( "hello\n"); return; } int main() { doit(); printf( "hello\n"); exit( 0); } |

输出8个hello
从这个例子,我们可以知道fork并不受函数调用的局部效果影响,它的影响是对于整个程序而言的。
题目3:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 |
#include #include int main() { int x = 3; if(fork() != 0) printf( "x=%d\n", ++x); printf( "x=%d\n", --x); exit( 0); } |

可以看到x=4,x=3,x=2都被打印出来了,为什么会出现这种结果呢?
这是因为if语句是父进程,所以会打印4,然后父进程继续运行,打印3,
然后子进程运行打印2.就有这个结果了。
题目4:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
#include #include #include void doit() { if(fork() == 0) { fork(); printf( "hello\n"); exit( 0); } return ; } int main() { doit(); printf( "hello\n"); exit( 0); } |

输出三个hello,这是因为 doit函数里面的子进程 fork两个hello,然后结束进程。
doit函数里面的父进程继续运行,打印一个hello。加起来就是三个hello。
题目5:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
#include #include #include void doit() { if(fork() == 0) { fork(); printf( "hello\n"); return; } return ; } int main() { doit(); printf( "hello\n"); exit( 0); } |
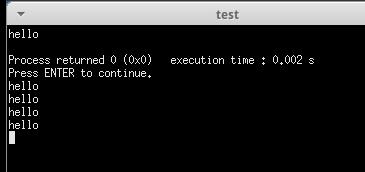
打印出5个hello,跟上一题不同点就是doit的子进程并没有结束,导致程序往后运行,多打印出两个hello。
题目6:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
#include #include #include int counter = 1; int main() { if(fork() == 0) { counter--; exit( 0); } else { wait( NULL); printf( "conter=%d\n", ++counter); } exit( 0); } |
conter=2
从这里看到全局变量也被子进程拷贝过去了。因此子进程的conter和父进程的conter并没有影响。
题目7:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
#include #include #include void end( void) { printf( "2"); } int main() { if(fork() == 0) { atexit(end); } if(fork() == 0) { printf( "0"); } else { printf( "1"); } exit( 0); } |
判断下面那个输出是可能的。注意:atexit函数以一个指向函数的指针为输入,并将添加到函数列表中,当exit函数被调用时,会调用该列表中的函数。
A.112002
B.211020
C.102120
D.122001
E.100212
判断如下:
只有第一个子进程的两个子进程退出调用exit才会打印2而且顺序一定是02或者12.
而第一个父进程是不会打印出2的。所以只能是01或者是10.
往往是父进程的调用速度比子进程的调用速度要快,因为子进程需要复制行为,导致比较慢。
因此有:
父进程,父进程,打印1 ,退出
运行子进程,打印0
子进程,父进程,打印1,退出打印2
子进程,子进程,打印0,退出打印2;
于是有下面的结果:
实际测试结果如下:
101202
题目8:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
void foo(
int n)
{ int i; for(i = 0; i < n; i++) { fork(); } printf( "hello\n"); exit( 0); } int main() { foo( 3); } |
题目9:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
int main() { if(fork() == 0) { printf( "a"); exit( 0); } else { printf( "b"); waitpid(- 1, NULL, 0); } printf( "c"); exit( 0); } |
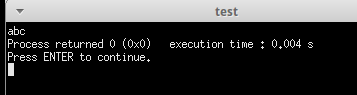
这是因为缓存为问题,b和c是同一个缓存属于父进程,而a在另外一个缓存属于子进程,
因为子进程先退出,所以先打印a
再然后父进程退出,打印bc。
于是有abc
下面我们来看一道常见的面试题: 下面这道题也是缓存的问题,也涉及到缓存复制的问题。
第一次产生两个进程,父进程,其中缓存为‘-’,子进程缓存为‘-’;
程序继续运行,父进程分裂再分裂成两个进程,这个时候每个进程的缓存就变成了‘--’,就是有4个。
同理子进程也是有4个。
因此就编程了8个。答案是8个。这个是缓存作怪的问题。
前两天有人问了个关于Unix的fork()系统调用的面试题,这个题正好是我大约十年前找工作时某公司问我的一个题,我觉得比较有趣,写篇文章与大家分享一下。这个题是这样的:
题目:请问下面的程序一共输出多少个“-”?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#include
#include
#include
int
main(
void
)
{
int
i;
for
(i=0; i<2; i++){
fork();
printf
(
"-"
);
}
return
0;
}
|
如果你对fork()的机制比较熟悉的话,这个题并不难,输出应该是6个“-”,但是,实际上这个程序会很tricky地输出8个“-”。
要讲清这个题,我们首先需要知道fork()系统调用的特性,
- fork()系统调用是Unix下以自身进程创建子进程的系统调用,一次调用,两次返回,如果返回是0,则是子进程,如果返回值>0,则是父进程(返回值是子进程的pid),这是众为周知的。
- 还有一个很重要的东西是,在fork()的调用处,整个父进程空间会原模原样地复制到子进程中,包括指令,变量值,程序调用栈,环境变量,缓冲区,等等。
所以,上面的那个程序为什么会输入8个“-”,这是因为printf(“-”);语句有buffer,所以,对于上述程序,printf(“-”);把“-”放到了缓存中,并没有真正的输出(参看《C语言的迷题》中的第一题),在fork的时候,缓存被复制到了子进程空间,所以,就多了两个,就成了8个,而不是6个。
另外,多说一下,我们知道,Unix下的设备有“块设备”和“字符设备”的概念,所谓块设备,就是以一块一块的数据存取的设备,字符设备是一次存取一个字符的设备。磁盘、内存都是块设备,字符设备如键盘和串口。块设备一般都有缓存,而字符设备一般都没有缓存。
对于上面的问题,我们如果修改一下上面的printf的那条语句为:
|
1
|
printf
(
"-\n"
);
|
或是
|
1
2
|
printf
(
"-"
);
fflush
(stdout);
|
就没有问题了(就是6个“-”了),因为程序遇到“\n”,或是EOF,或是缓中区满,或是文件描述符关闭,或是主动flush,或是程序退出,就会把数据刷出缓冲区。需要注意的是,标准输出是行缓冲,所以遇到“\n”的时候会刷出缓冲区,但对于磁盘这个块设备来说,“\n”并不会引起缓冲区刷出的动作,那是全缓冲,你可以使用setvbuf来设置缓冲区大小,或是用fflush刷缓存。
我估计有些朋友可能对于fork()还不是很了解,那么我们把上面的程序改成下面这样:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#include
#include
#include
int
main(
void
)
{
int
i;
for
(i=0; i<2; i++){
fork();
//注意:下面的printf有“\n”
printf
(
"ppid=%d, pid=%d, i=%d \n"
, getppid(), getpid(), i);
}
sleep(10);
//让进程停留十秒,这样我们可以用pstree查看一下进程树
return
0;
}
|
于是,上面这段程序会输出下面的结果,(注:编译出的可执行的程序名为fork)
|
1
2
3
4
5
6
7
8
9
10
|
ppid=8858, pid=8518, i=0
ppid=8858, pid=8518, i=1
ppid=8518, pid=8519, i=0
ppid=8518, pid=8519, i=1
ppid=8518, pid=8520, i=1
ppid=8519, pid=8521, i=1
$ pstree -p |
grep
fork
|-
bash
(8858)-+-fork(8518)-+-fork(8519)---fork(8521)
| | `-fork(8520)
|
面对这样的图你可能还是看不懂,没事,我好事做到底,画个图给你看看:

注意:上图中的我用了几个色彩,相同颜色的是同一个进程。于是,我们的pstree的图示就可以成为下面这个样子:(下图中的颜色与上图对应)

这样,对于printf(“-”);这个语句,我们就可以很清楚的知道,哪个子进程复制了父进程标准输出缓中区里的的内容,而导致了多次输出了。(如下图所示,就是我阴影并双边框了那两个子进程)

现在你明白了吧。(另,对于图中的我本人拙劣的配色,请见谅!)