lecture5-对象识别与卷积神经网络
Hinton第五课
突然不知道object recognition 该翻译成对象识别好,还是目标识别好,还是物体识别好,但是鉴于范围性,还是翻译成对象识别吧。这一课附带了两个论文《Convolutional Networks for Images,Speech,and Time-series》在前面翻译过:http://blog.csdn.net/shouhuxianjian/article/details/40832953和《Gradient-based learning applied to document recognition》,因为有46页,太多了,暂时没翻译。
一、为什么对象识别这么难
因为人类的视觉系统天生擅长对象识别,所以没法知道在从一大堆像素中如何进行有意识的识别并且进行标记成对象是多么的难。我们必须将对象分割出来;必须处理在光照的变化和不同观点(认为这个是属于什么对象)的情况;必须处理如何定义一个对象,而这些都是很复杂的。处理对象识别需要专业的知识背景,需要处理不同光照和viewpoint(应该就是各种不变性,比如平移,旋转,扭曲什么的),这对于任何的手工设计方案来说都不是轻松完成的。有很多问题是导致为什么识别对象和图像是这么的困难:

首先,从图片中将一个对象从其他的事物中分离出来是很麻烦的,在真实世界中,我们可以周围移动,来获取移动信息;同时两只眼睛可以让我们获得3D信息,但是这些在一张静态图中是没法获得的。所以在如何判定哪些部分属于同一个对象是很困难的,同样当一个对象遮挡了另一个对象,就无法在图片中看到这个对象的全貌。
另一个导致识别对象很困难的原因是照在对象上所反射的像素的强度是很大程度上由光照决定的,所以在白天一个黑色的表面可以比在晚上一个白色的表面获取更多的像素强度。我们的图像中的对象识别就是将像素的强度转换成标签形式而已,而且导致强度的变化的各种原因其实和对象的本身属性没什么关系,或者说对识别对象意义不大。
对象还能以各种表现形式出现,例如在手写识别中,一个手写数字可以以不同的形状出现但是却都表示同一个数字(不同的手写习惯,比如不同的字体,但是都是表示同一个数字)。就拿数字2来说,很多人写的就是一个尖端的形式,而很多人喜欢写成下图中的形式(一个圈,而不是一个尖端)。
同样的关于对象的定义上也是较为麻烦的,比如是从使用上进行定义的同一个对象(在视觉上不一样)。椅子,从有靠背的到直接的板凳,从木头材质的到塑料或者金属的,只要能完成基本的坐的定义,那差不多都可以称之为 椅子了。

另一个导致对象识别很困难的事情是我们在同一个对象上有不同的viewpoint,如果说在在图片中改变viewpoint,那么标准的ML方法就不能很好的适应了。问题出在输入维度之间的信息跳跃。假设图片中的样本提取方法是输入维度等于像素的个数,但是如果在真实世界中一个物体移动了,对于人类来说不需要移动眼睛去追踪它(有可能移动眼珠或者当前后移动的时候连眼珠也不需要移动),但是相同对象的信息就会呈现在不同的像素(不同的视网膜点)上了,例如我们有个数据集,其中的一个样本特征是病人的年纪,另一个特征是病人的体重,然后进行ML的设计和实验,但是发现对于编码器的不同输入位置来说会出现问题,假设在需要输入体重的地方输入了年纪,而在需要输入年纪的地方却输入了体重,显然这没法按照我们设想的那样编码学习。所以需要试图去固定他们,但是这样某种程度上会使得事情变得糟糕(固定不好的时候),Hinton称当信息从一个输入维度跳到另一个维度上的这种现象为 “dimension hopping”,这就是Viewpoint,通常我们采用系统的方法来对其中的一些部分进行固定。
二、达到观点不变性的方法
每次我们人类观察一个对象,都会有不同的viewpoint,所以实际上对象是在不同的像素位置上共享的,但是这种对象识别方法(人类自带的)却和大多数的ML不一样,还是因为单纯的图片表现的信息不够。所以很多不同的方法应运而生来解决viewpoint不变性的问题。

机器不同于人类,所以没法轻松的让机器进行感知,而且在工程学上还是在心理学上都没有普遍接受的解决方案。第一个方法是使用足够多的不变性特征;第二个方法是在对象上用个框框起来这样就能对这些像素进行归一化;第三个方法是使用特征复制,然后池化他们,这种方法被称之为“CNN”。第一个方法(将会在随后介绍)是通过使用具有相对于摄像机和视网膜中明确的位置部件功能的层次结构。
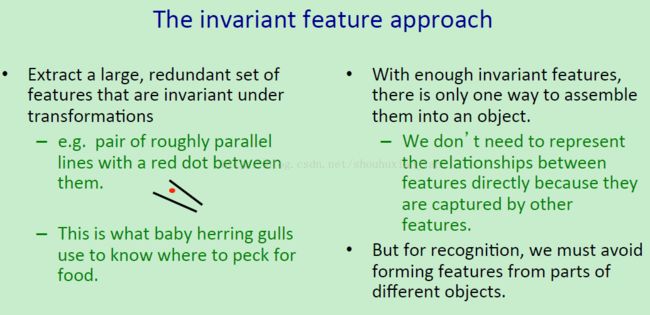
所以不变性特征需要提取大量而且冗余的特征集合,并且具有平移、旋转、缩放等不变性。例如:上图中有两条大致平行的线,中间还有个红点,这个实际上是用来指定小鲱鱼鸥啄食物的地方,如果在木头上画上这个图案,它们会在这块木板上的这个地方啄食(这个例子举的一点都不好,就是说类似条件反射一样,先教动物啄食,然后将这个每次都出现的标记画在木头上,动物还是会去啄食,这里其实想表达的就是这个图案画在哪都可以被动物认识)。在拥有足够的不变性特征的情况下,就需要将它们都聚集到一个对象或者一副图上。不需要直接的去表达特征之间的关系,因为这些关系是基于其他特征的基础上获得的。大量的观点表明我们所需要的就是一个大的特征袋(bag of features),因为在拥有重叠和冗余的特征的情况下,一个特征可以告诉你其余的两个特征是怎么关联的。不幸的是,如果你做识别任务的话,你得到一群由不同的对象的部分组成的特征集合。而这就是在识别的道路上误入歧途了。所以需要避免由不同对象部分上得到的信息而形成的特征。

第二个方法叫judicious normalization(这个暂时不知道怎么翻译够习惯)。如上图右上角的大写字母R,上面还有个框。并有两个坐标轴 top 和front代表R这个字母的相对位置(这样就能够提取出独立的字母并一个一个的排好了),这样在用框附带描述的方法就是可以表现不变性,这里假设字母都有严格的形状,通过加个盒子来解决维度跳跃的问题。如果我们正确的选择了盒子那么对象的正确位置上总是会出现相同的归一化像素,虽然不一定是矩形的盒子,但是这样的方法可以让我们拥有平移、旋转、剪切和拉伸不变性。但是这个盒子却不是那么容易选择的,因为我们会犯分割错误,而且字符可能会闭塞,或者有不寻常的方向,所以不能简单的加个盒子了事。上图中的那个R还需要我们运用自己的有关形状的知识去决定这个盒子是什么样子的(比如大小和坐标,即哪边才是这个字符的上方,前方和后方等等),假如一个小写的d,但是还有个大写的D但是上面出头了一些,那么这两个字母就极其的相似了(只是一个o在左,一个在右)。所以问题就来了,这就是一个先有鸡还是先有蛋的问题,需要正确的做个盒子,那么需要事先识别这个形状,而为了识别这个形状,就需要这个盒子。心理学家认为用心理旋转来处理这个形状的方法不是正确的方向定向。Hinton认为这完全是胡说:这个大写字母R在做心里旋转之前就可以很完美的被人类识别。不过的确在识别的时候会知道这是上下颠倒的,但是这也是为了知道如何进行旋转(人类是将旋转发生在识别之前)。但是在正确识别这个是一个正常的R还是一个镜像R(左右相反),还是需要心理旋转的,但是识别完全不需要。
一个强力的归一化方法是:当训练识别器的时候,需要很好的分割并且用正立的(非颠倒)图像去拟合这个正确的盒子。在测试一些杂乱的图像的时候,可以在不同的位置和尺度上使用任何可能的盒子。这个方法被广泛的应用到检测正立的事物任务上,例如识别在未分割过的图像中的人脸和门牌号,当识别器能够处理位置和尺度不变性的时候将会更加的高效,所以我们才需要在测试各种可能的盒子的时候采用粗糙的网格。
三、为手写数字识别设计的卷积神经网络
由Yann LaCun和他的团队一起发明的DCN(深度卷积网络)在1980年代获得了成功并且商用,而且能够在当时的机器配置上很好的运行。

CNN是基于复制特征的想法上建立的。因为对象可以移动和在不同的像素上显示,如果有个特征检测器在图像的一个地方很有用,那么也可以在图像的其他地方一样有用(UFLDL中卷积章节的图像的“自然图像有其固有特性,也就是说,图像的一部分的统计特性与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征”),所以可以用这个思路在图像的不同位置上建立相同的特征检测器。上图右边的三个特征检测器都是一样的(红色和绿色可能不同,但是三个红色的权值都是相同的,三个绿色也是相同的),说复制也不为过,每个检测器对9个像素进行特征提取,我们同样可以在规模上和方向上进行交叉复制,但是这样会更加的困难而且代价高昂,所以这差不多不是个好想法。在位置上交叉复制可以大大的减少自由参数的数量,所以图中一共27个像素其实只有9个不同的权重而已,并且我们不满足一个特征提取器,所以可以有多个特征图,每个图内部的特征提取器是一样的,不同图上不同,所以不同的特征图就学到了不同的特征,这可以使的图中的每个块可以用许多不同风格的特征来表示。

而且也很容易使用BP来进行训练,实际上可以轻松的修改BP并在权重之间合并任何的线性约束,所以我们只需要像往常一样计算梯度就行,并修改梯度使得在权重更新前后能够满足线性约束。这里最简单的例子是我们想要两个权重相等,即W1 = W2,那么在开始的时候先保证,然后使得在W1上的变化等于W2上的变化,即先计算W1的梯度和W2的梯度,然后求出平均值或者和作为两个权重的梯度,通过这样的权重约束可以让BP来学习重复的特征检测。
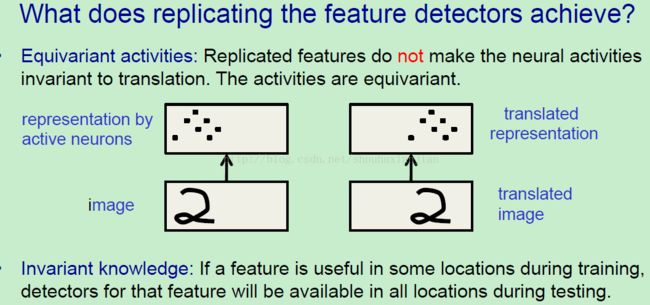
通常在文献中有很多的问题比如重复的特征检测器到底获得了什么,许多人说获得了平移不变性,Hinton认为这不是真的,至少在神经元的激活上不是真的,所以如果观察这个激活部分,重复特征得到的是同变性,而不是不变性。举个例子,上图中的一个图(数字2),和上面的黑点表示激活的神经元,第二个是一个平移后的图,注意到黑点(激活的神经元)同样平移了,所以图像变了,而表征也随着图像改变而改变,这是同变性,而不是不变性,是有不变性存在,但是那是知识(比如识别这个就是2),所以如果学习重复特征检测器,如果知道如何在一个区域中检测一个特征,那么就知道如何在其他区域检测同样的特征,并且主遇到在激活上获得了同变性,在权重中获得了不变性。

如果想要在激活中获得不变性,那么就需要对重复特征检测器进行池化操作(如上图所示),所以就能在一个DNN的每一层得到一个小数量的平移不变性。这里的一个优势就是减少了输入到下一层的数量,所以我们能够拥有更多不同的特征图,允许我们在下一层中学习更多不同的特征,事实上采用四个邻居特征检测器的最大值比均值效果要好(应该是说max-pool比average-pool要好)。这里有个问题就是在经过了几次池化后,我们损失了特征的精确位置信息,如果我们想识别人脸,这个完全不用担心,因为我们已经得到了一些眼睛,鼻子,嘴巴等相对的位置信息,这些已经足够说明这是个人脸了,但是如果想精确得到这个人脸属于谁的,就需要使用眼睛之间的,鼻子和嘴巴之间精确的空间关系,而这些信息在CNN中已经被丢弃了。
第一个让人印象深刻的CNN模型就是Yann LeCun的Le Net模型:1、有着许多的隐藏层;2、每层都有许多的重复单元图;3、在层之间有池化操作(将附近的重复单元的输出进行池化),先对毗邻的单元进行池化,然后在送到下一层;4、也是一个广泛的网络能够及时字符都是重叠的也能马上适应,所以不需要做独立字符分割的预操作;5、采用了更智能的方法去训练整个系统,而不是一个识别器,所容易可以在一端输入像素,在另一端得到整个zip编码,在训练系统的过程中采用了一种被称为最大边缘(maximum margin)的方法,但是在这个网络出来的时候这个最大边缘的方法还没有被发明。现在这个网络在北美已经使用并且处理了近乎10%的支票识别,所以这是有很大的实际价值,在Yann的主页上有很多的demo,Hinton说应该都去看看,因为它们展示了如何很好的适应在尺寸、方向、位置、数字的重叠上的不变性,而且这些使用的各种背景噪音足以让大部分方法望尘莫及。
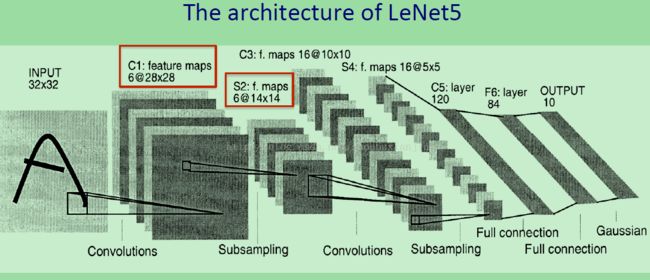
LeNet-5的结构如上图所示,在输入部分就是像素,然后是一系列的特征图并跟随着子采样,所以在C1特征图中,有6个不同的图,每个都是28×28,每个局部感受野差不多是3×3的(这里Hinton应该错了 ,应该是5×5的才对),而且他们的权重都是一起被约束的,所以每个图只有9个参数(应该是25个),这样可以使得学习更加的高效,也意味着只需要更少的数据,在这个特征图之后,就是被称为子采样,现在称为池化。所以通过对C1中的一群邻居重复特征的输出进行池化,可以得到一个更小的图,并将给下一层提供输入,而下一层就是发掘更复杂特征的一层(这也是DL的思想),随着网络的前进,得到的特征更加的复杂,但是也有更多的位置不变性。

上图就是LeNet-5系统烦的错误,通过对数字的显示可以看出,这些数字是即使对于人来说也是很难分辨的,在一共1w个测试样本上的实验显示值犯了82个错误,也就是说它有着超过99%的正确率,并且主遇到大多数的错误人类还是可以发现的,如果按照人的错误的话差不多在20-30之间,但是没人真的这么干过,但是还需记得,这个网络认为对的那部分,人类有可能还会犯错,所以要真的比较的话得在整个测试集上进心比较。

这里先讨论下一个普通的点,关于如何将先验知识注入到ML中,并具体的应用到NN上。我们可以通过对网络的设计像Lenet-5一样将先验知识注入进去:局部连接、权重约束、或者神经元激活函数的选择等,都是为了这个任务具体选择的。这些都比手动设计特征更不具有侵略性(就是更好的适应原始数据),
但是仍然还是有偏见认为这个网络只是解决这个问题的一个特别的方法而已(就是不认同他的泛化能力)。我们有着如何用越来越大的特征来进行对象识别的想法,并通过交叉空间来重复这些特征,并将这些付诸于这个网络来实现。有一个可代替的方法去处理先验知识并且让网络更自由,我们所能做的就是用我们的先验知识得到更多的训练数据。这个工作的第一个例子就是由Hofmann和Tresp做的,他们试图对一个钢厂所发生的事情进行建模,他们想知道各种输入变量与钢厂出来的东西之间的关系,实际上他们使用一个旧的Fortran模拟器来模拟钢厂。当然这个模拟器不够真实,只能提供近似值。所以他们有着真实数据和一个模拟器,他们所能做的就是运用这个模拟器去生成许多综合数据,然后将生成的数据加入到实际数据中,并且认为这样得到的效果比只使用真实数据要好。如果Hinton没记错,这个大Fortran模拟器产生的数据只值几十个额外的真实样本,但是他们的想法还是很不错的。当然如果你生成了许多综合数据,这可以让学习学的更久,所以在学习的速度上,更高效的方法是将知识通过类似连接或者权重约束的方法和Net-5中一样来处理。但是现今的计算机已经不同往日了,通过生成综合样本的处理知识的方法已经开始显得越来越好了。具体的,他允许通过优化去发掘我们没有想过的多层网络的方法(就是现在可以训练多层网络了)。事实上,我们也许从来没有完全懂得如何去做,如果我们只是想要一个问题的好结果,那么好吧。

所以使用综合数据是一个强有力的方法去处理手写数字识别。LeNet-5通过使用不变性的知识去设计连接和权重共享和池化。而这些得到了80的错误,如果通过添加更多的技巧,比如综合数据,这个结果可以降低到40个错误。Switzerland中的一个团队,就是通过注入综合数据的方法,他们花了很多工作在如何创建非常有益的综合数据。所以对于每个真实的训练情况,他们可以通过转换得到更多训练样本,然后在GPU上用一个更大的网络(每层有很多的单元)和更多的层来训练,这个GPU让他们得到了13x的加速,而且因为他们的这些综合数据的加入使得这个网络不会过拟合,如果他们只是在GPU上使用一个大网络,而不添加这些额外的数据,那么就会导致严重的过拟合使得在训练数据集上表现很好但是在测试集上表现的很糟糕,所以他们是真的结合了三个技巧:通过实验生成许多的综合数据,然后在GPU上训练一个大网络。

他们在这个数据集上获得了35个错误,上图中每个错误的上方是正确的答案,下面的两个数字是模型得到的前两个最接近的答案,通过观察发现错误的结果总在正确的结果附近(只有5个样本不是,就是红框部分),通过更多的工作例如建立不同的模型然后使用一个共识(投票系统)可以将结果降低到只有25个错误,而这已经接近人类完美水准了。

一个问题是如何知道一个得到了30个错误的模型真的比一个得到了40个错误的模型要好,他们之间有明显的不同吗?不,这取决于犯的错误是什么,通过统计哪些是对的哪些是错的数字的方法,而这是统计测试被称之为NcNemar测试,这个测试通过使用具体的错误是比使用数字更具敏感性的。例如:如上图中两个表,第一个数值29和12表示的就是模型1和模型2都错的个数,在Magnema测试中,可以忽略这些黑色的数字只看红色的,,感兴趣的就是那些一个模型预测的和另一个模型预测的不同的地方,那么第一个表就是11:1,相当明显了,这表明第一个表中模型2要比模型1好,这种情况不是偶然而是必然。如果再次观察第二个表,然后告知模型1花费了40个小时的时间,模型2花费了30个小时的时间,但是可以看出在他们不同的地方模型判对15个而这里模型2判定是错的,相反只有25个错误,这里综合的评价是他们之间的差异并不明显,所以没法说哪个模型更好。
四、为对象识别设计的卷积神经网络
人们总是在问是否这种为了识别手写数字任务设计的网络能够去做那些视觉界的人们称之为真实的任务(个人:应该是说是否能够迁移学习吧),也就是在高分辨率的具有杂乱场景的彩色图中去识别对象,所以你需要处理分割,需要处理3D的viewpoint,需要处理5-foot list问题。因为有许多不同的对象在周围,所以没法知道哪个才是感兴趣的那个。课程的开头为了提起大家的兴趣而介绍的由Alex Krizhevsky提出的网络,其结果显示它适合用来做对象识别,但是那时候还不能完败最好的计算机视觉系统,然而现在可以了,在Emenise上研究多年的人们逐步的让这些网络能够识别手写数字了。

许多机器视觉的研究者说如果你想要去识别在彩色图中的真实对象,而这无异于在浪费时间,因为他们认为从Emnise上学到的课程无法泛化到那个领域中去。这是一个值得思考的问题。下面介绍几个原因,关于为什么这是一个很难的任务:1、首先,是因为有许多不同的对象,即使我们考虑真实场景中识别了1000类,仍然还有1000对100的差距;2、即使不考虑像素的分级,我们使用的样本类别是256*256的彩色像素(就是像素的分级没有人类的256这么简单,例如不但有RGB编码还有很多其他的编码),相比较于28*28的灰度图来说,像素太多(一个是图片大,一个是彩色还有RGB三通道);3、在真实场景中,我们所获取的都是3D中的2D图像,这期间就损失了深度等信息,而且真实场景中有着杂乱的类别,而这些在手写中都没有出现;4、在手写中,可以出现重叠的字母,那样就需要进行分割处理,但是不会出现其他不透明的对象将感兴趣的对象完全遮挡的情况;5、在同样场景下手写识别没有很多不同的对象存在。所以问题就是在这些问题下CNN能够胜任在真实场景下的任务吗,CNN在手写识别上很好的完成,那么在彩色图像上呢,在真实彩色图像中,我们可能需要注入一些先验知识,因为假设我们不将先验知识注入到网络中,而是通过所有的知识像上述一样去生成额外的训练样本,那么对于当前的网络来说这个计算量就太大了。

上图就是近年来的一个强有力的竞争结果,是基于一个被称之为ImageNet的数据集。ImageNet实际上是说的机器图像(就是我们电脑上的图像),只是他暂时只收录了1.2百万张而已,而所谓的分类任务就是将他们很好的进行标记。现在这些图像已经手动标记了差不多1000类,但是这不是完全可靠的(因为有时候会标记错误),因为一张图像中有可能有2个类别,而只标记了一个,所以为了使得任务更加的合理,计算机视觉系统可以允许有5个赌注(估计就是可以保留模型预测的前5个不同的结果吧),而且当5个赌注中的一个是等于人类给定这个图像的标签的,那么就算正确。
这仍然是个局部化的任务,因为许多的计算机视觉系统会采用BOF 特征袋的方法,对于整幅图或者图像的一个象限来说,他们知道特征是什么,但是不知道在哪,这可以让他们进行对象识别,但是却不知道准确的位置信息。这可不像人类的行为,除了人类大脑受伤得了平衡综合症,那么他们只知道识别对象,但是却不知道在哪,所以对于局部化任务来说,就需要在对象上设置一个盒子,一旦识别到了对象,那么至少得要有50%的部分是正确框起来的。
在这个任务上,人们试了许多当前现有的最好的计算机视觉方法,有来自 Oxford 和 the French National Research Labs Inria和Xerox's European Research Center和其他大学的团队都在研究这个任务,然后发现的确很难。这些计算机视觉系统通常都使用复杂的多阶段系统。这些系统的早期阶段是通过手调来优化数据的参数的,然后在系统的顶层阶段通常都是一个学习算法,但是也没法学到所有的方法。
有例如DNN所执行的方法中,当通过BP进行训练,这个网络不需要end-to-end学习,因为在前面的特征提取器中的参数会被BP告知如何调整才能接近最后的类别决策部分。

上图是这个数据集中的测试集上的一些例子(在第一课中已经观察了一些),看第一个猎豹的图,虽然图中有一个对象,但是却并不完整。有Alex Krizhevsky的DNN给出的未归一化的概率作为结果预测值,可以看到结果还是挺可信的,如果结果不是猎豹,那么第二个选项就是豹,还有例如第三个答案,雪豹等等;第二个图中有着许多的对象而我们感兴趣的对象只占了一小块的区域,但是这个网络能够正确的预测这是子弹列车,但是也有着其他的赌注,例如高速列车和 电力机车等,如果观察这幅图,可以看到还有许多其他的东西可以被标记,例如占图像区域比列车比重还大的屋顶,在这类图像中,就需要能够适应很多可选择的目标的情况;最后一张图没有复杂的背景,这个对象很好的被独立出来,但是这个网络没有第一次就猜中这个,但是在前五个赌注中倒是有了,但是这也说明这个网络没法对所有的东西都能够很好的识别,看着下面这几个判断,他们到都是合情合理的标签,如果眯起眼睛看,在不能很好的观察这个图像的时候,你会发现,其他的几个标签是多么的自然,这也说明这个网络犯错还算合情合理。

上图是几个大学或者机构的计算机视觉系统的比赛结果,可以发现最好的几个结果都是很相似的,所以Tokyo大学在这里算最好的了,牛津大学,他们有个很好的计算机视觉组,算是欧洲最好的了,相比较发现可能觉得达到26%是很难的一件事,如果结果超过了26%,比他们要好,那么你就拥有了差不多最好的计算机视觉系统。所以Alex Krizhevsky的网络得到了16.4%的更好的成绩,从之前的几个比较重发现和第二名差距还是很大的,之后的几名之间几乎没什么差距(这里Hinton在自夸他学生的网络,哈哈)。

Alex Krizhevsky的网络如上图所示,他是神经网络的先驱Yann LeCun的网络(早期用来做数字识别,后期用来做真实对象识别)的更深的版本,DCNN,然后通过从Yann团队,begino团队和其他团队那里学到的知识,并提出了这个DNN用来做真实视觉。
它有7层隐藏层,比通常的更深而且不算上最大池化层这一层(即有7层卷积层),前面的层是卷积的,如果我们有更大的计算机,那么就可以只用局部感受野,而且不需要绑定任何权重(就是不权重共享),但是在对他们做卷积的时候,必须剔除一些参数,所以需要在考虑计算机计算时间的情况下减少训练数据;最后两层都是全局连接的,而且整个模型的大部分参数都在这里,差不多在这部分中两层之间有16百万的参数存在,最后两层所干的的事情就是将从前面提取的局部特征进行很好的组合,很显然因为有很多的组合存在,所以这里才需要这么多的参数;而且在每个隐藏层中的激活函数还是ReLu,因为这种激活函数的学习速度比逻辑单元学的更快,但是他们的代价也大;Hinton同样也会使用归一化,当其他单元有更强的激活值的时候,就使用一层去压缩单元的激活值,所以会有一个边界检测器,在相当弱的边界下也能获得激活。而且在周围如果有更多强烈的单元,那些都是不相关的。

上图是Hinton等人的一些小技巧,用来明显的改善这个网络的生成能力。首先,通过使用转换的形式增强这些数据:上图中的是一个对256×256的图进行下采样的技巧,但是不直接使用原图,Alex Krizhevsky通过在这些图中随机提取224×224的块,这使他有了更多的图像去训练,并且有助于转换和不变性,即使是对于CNN来说,这也仍然是有用的。他还使用了图像的左右翻转,这使得数据量一下子成了两倍,他没有用上下翻转,因为他认为重力(垂直方向)是很重要的,而左右翻转不会改变些什么,除非都是些文字才会有差异,对于自然图像来说,无所谓。在测试的时候,他不止使用一个块,他使用不同的块,四个角,中间,这样加起来就5个块了,然后接着用左右翻转,测试数据一共就有10倍了,他通过将这些所有的测试数据输送到网络,然后对最后的结果进行综合,在顶层中,也是大部分参数的所在的地方,他使用一个新的正则化技术,Dropout,这非常的有效,并且可以防止网络过拟合,这个技术在最后的结果中占了不少的比重。Hinton会在随后的课程中讲解这个,但是对于现在粗略的说就是:每次你表现一个训练样本,都将一层中近乎一半的隐藏节点忽略掉,也就是说这层中的其他隐藏单元不能相互牵制了,不能通过修正错误(例如BP)来影响这层中的其他单元(因为都默认忽略了),这就使得每个神经元看上去更加的独立了(关于Dropout的请看具体的论文),这也就是说每个神经元可以在做有意义的事情的基础上更加的独立,并且不同于这层中的其他神经元,所以Drouput阻止了层间单元过多的合作,许多的合作是有益于你和训练数据的,但是如果这个测试分布明显不同,那么所有的合作都会导致过拟合。
Alex的这个网络需要较高的硬件要求,但是现在这些配置也就几千美元(额,,,好贵)。Alex也是个很好的程序员,他在两块Nvidia GTX 580GPU上部署了CNN,每个GPU上都有超过500个流处理器,因为显卡这种擅长算术,但却不擅长其他的事情(就是喜欢矩阵计算,打个比方,GPU只能单纯的干一件事情,而CPU是全能),因为GPU擅长矩阵乘法等,所以如果你将隐藏层的激活向量基于样本数量上堆叠在一起,那么就是个矩阵了,然后就可以通过下一层的权重乘以这个矩阵来最后进行作为下一层的输入,如果矩阵很大,那么GPU刚好发挥优势,差不多可以将速度提升30x,而且他还有很宽的内存,这些都是nn所需要的,因为在NN中需要等待另一个权重然后才能相乘来进行激活,所以在面对百万级别的权重的时候,不能将它们都放入cache中。通过使用这些,他能在一个礼拜以内训练好这个网络,而且这也让他能在测试的时候快速的将从10个块中的结果进行组合,所以能够以帧的速率进行计算。在将来,希望能够将这个网络分布式的在一个大数量核心上,随着核心的日益便宜,很多在Google人们已经能够这样实验了,而且在不同的机器上的传输更快的话,那么就能够在更大的网络上进行分布了,Google已经有了这样的模拟网络了,这个网络有着1.7十亿个链接,随着发展,这个DNN肯定会比老式的计算机视觉系统更快,因为它几乎不需要手动设计,而且可以在巨大数据集上进行计算和提取信息。Hinton认为在所有的最好的对象识别系统上,至少在静态图像上,可以使用DNN了。

这里是其他的应用领域。Vlad Mnih 使用一个有着局部感受野的非卷积网络去从空中俯视图中提取道路,这些都是城市场景的杂乱式的空中俯视图,通过使用ReLU和相比较大的图像块,并且用16×16大小的块来预测中心点的值,这个块中的点可能是一部分道路或者不是。这个任务最好的的地方就是有很多的标签训练数据可以使用,因为这个图可以告诉你道路的中心线在哪,和道路的粗略的宽度,所以从这个图中获得的向量可以告诉你道路的中心线,然后就能估计哪些像素属于道路了。然而,这个任务也依然很难,因为,这些道路可能会被建筑物所遮挡,或者会被树木遮挡,或者会被路上的车遮挡,而且建筑物的阴影是随着光照(晴天和阴天)不断的在改变。例如:这里有微小的viewpoint的变化,所以这个平面基本上看上去是向下的,但是在任何大照片中,他看上去却不是在每个像素上都是笔直向下的,最坏的问题是数据中的标签有可能是错误的。比如因为地图还没有完全注册,所以得到的标签是错的。在大多数的情况下,不需要一个地图被注册到米的级别(民用的差不多5米就很好了,军用的可能会精确到厘米吧),在数据中一个像素有可能就代表着一平米了,所以如果一个错误的注册地图是3米的,那么就在数据中就有3个像素的标签是错误的;另一个严重的问题是人们在制作地图的时候可能随意决定这里是不是一条路,还是条巷道。在大图像块上训练大NN,使用百万级别的样本,Hinton这是这个任务唯一的希望了。
上图就是数据的样子,这是Tornoto的部分图,上图的上面是从图中提取的两个图像块,图中绿色的就是正确识别的道路的像素,而红色的就是系统认为是道路,但是其实不是的地方,实际上那里只是个停车的地方而已。