python 3爬取 四川一分一段数据(查分数在哪个区间段)
今天项目组某个同学机器学习需要知道分数对应哪个区间段,于是乎,我又成了苦力了...
我们爬取网址是:http://www.creditsailing.com/zt/gaokao/yifenyiduan.html#sichuan里面还有其他省的,可以换省查询。
这次爬取的是这个数据很简单,终于不再是像上篇那么贼难,数据还难处理,现在心里都难受的...
需要的环境:python3 +pycharm(或者你喜欢的编译器)
需要的库:requests(网页请求库),xlwt(excel库),Beautifulsoup库(网页解析库)
还是先上镇楼图:
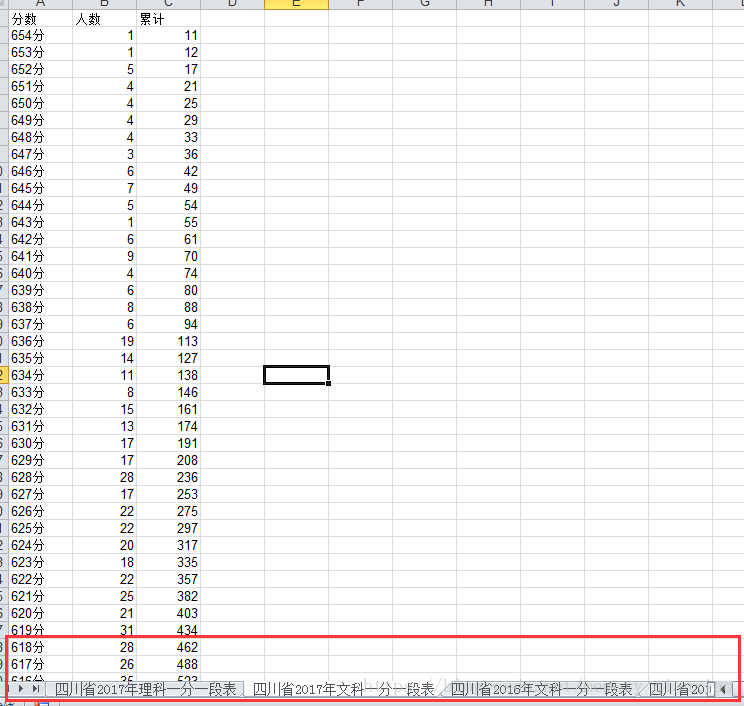
进入网页后我们找到四川的:

我们文理科都需要,所以点进去两个网址复制下来,然后都一次性请求下来,保存到两个变量中。然后传入到保存数据的函数里
def main():
#理科
url="http://www.creditsailing.com/GaoKaoZhiYuan/666259.html"
#文科
url2="http://www.creditsailing.com/GaoKaoZhiYuan/666260.html"
html1=Geturl(url)
html2=Geturl(url2)
GetInfo(html1,html2)然后我们进入到详情页面,F12后面,看到所有数据都在table标签里面的每个tr标签里面,每个tr标签有分数,人数,累计,然后逐个遍历Beautiful提取就ok。文理分别存入info1,info2列表内。
def GetInfo(html1,html2):
soup1=BeautifulSoup(html1,"html.parser").find_all("tr")
soup2=BeautifulSoup(html2,"html.parser").find_all("tr")
info1=[]
info2=[]
#拿理科一份一段表存入列表
for i in soup1:
l=[]
for j in i:
l.append(j.string)
if l!=[]:
info1.append(l)
#拿文科一分一段表
for i in soup2:
l = []
for j in i:
l.append(j.string)
if l != []:
info2.append(l)
我们把爬取好的数据存入excel表,用的是xlwt库。没有的直接pip install xlwt,不知道用法点击传送门:xlwt用法
file=xlwt.Workbook(encoding='urf-8')
print("正在写入Excel四川省理科一分一段表.....")
table1=file.add_sheet("四川省2017年理科一分一段表")
for i in range(len(info1)):
for j in range(len(info1[i])):
table1.write(i,j,info1[i][j])
print("正在写入Excel四川省文科一分一段表.....")
table2 = file.add_sheet("四川省2017年文科一分一段表")
for i in range(len(info2)):
for j in range(len(info2[i])):
table2.write(i, j, info2[i][j])
file.save("四川省一分一段表.xls")
print("数据写入成功!")最后我们放上完整源代码:
import requests,xlwt
from bs4 import BeautifulSoup
def Geturl(url):
try:
r=requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
print("请求成功!")
return r.text
except:
print("请求失败,请检查网络.....")
def GetInfo(html1,html2):
soup1=BeautifulSoup(html1,"html.parser").find_all("tr")
soup2=BeautifulSoup(html2,"html.parser").find_all("tr")
info1=[]
info2=[]
#拿理科一份一段表存入列表
for i in soup1:
l=[]
for j in i:
l.append(j.string)
if l!=[]:
info1.append(l)
#拿文科一分一段表
for i in soup2:
l = []
for j in i:
l.append(j.string)
if l != []:
info2.append(l)
file=xlwt.Workbook(encoding='urf-8')
print("正在写入Excel四川省理科一分一段表.....")
table1=file.add_sheet("四川省2017年理科一分一段表")
for i in range(len(info1)):
for j in range(len(info1[i])):
table1.write(i,j,info1[i][j])
print("正在写入Excel四川省文科一分一段表.....")
table2 = file.add_sheet("四川省2017年文科一分一段表")
for i in range(len(info2)):
for j in range(len(info2[i])):
table2.write(i, j, info2[i][j])
file.save("四川省一分一段表.xls")
print("数据写入成功!")
def main():
url="http://www.creditsailing.com/GaoKaoZhiYuan/666259.html"
url2="http://www.creditsailing.com/GaoKaoZhiYuan/666260.html"
html1=Geturl(url)
html2=Geturl(url2)
GetInfo(html1,html2)
if __name__ == '__main__':
main()
最后再说一下,因为有2016,2015这个网站没有数据,要去其他网站爬方法类似。