自然语言学习——使用word2vec对文本进行情感分析
本文主要讲述了如何对影评数据做情感分析,就是如何判断这条评论是好评还是差评。对文本处理的方法是word2vec,然后用随机森林的方法构建模型,最后训练模型进行预测。前面一、二部分主要是讲述如何处理文档,有点啰嗦可以快速阅读,主要方法从第三部分开始。
一、读取文档
在进行文本情感分析之前,当然需要大量的文本数据,我使用了一些影评数据(labeledTrainData.tsv)作为训练集来完成。内容如下图所示:

该训练集拥有25000条影评数据,图中只显示了五行数据,id可表示评论者,sentiment表示是好评(1)还是差评(0),review则是影评内容。
在读取完文档后,先看看我们所得到的影评数据是一个什么样的内容:以第一条为例(with all this……),如下图所示:

仔细观察会有
这样的网页标签存在,在进行网页爬取影评的时候这样情况肯定会出现,为了得到完好的文本,需要对文本进行一个预处理,如下。
二、文本预处理
1.去掉html标签
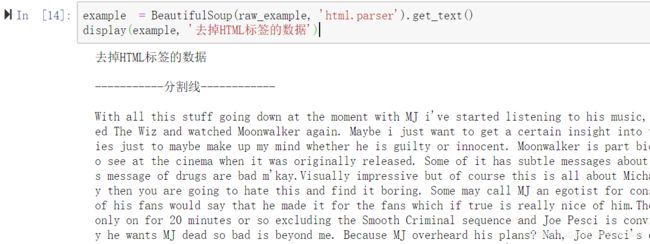
使用BeautifulSoup库可以轻松去除html中的标签,得到所需文本。
2.移除标点
由于标点符号对我们的文本情感分析是没有用处的,所以我们也需要把标点符号去掉:

去除标点后就如上图所示,使用的正则匹配的方式。
3.切分成词
计算机对一句话进行分析的难度较大,对单词进行分析就相对简单一些,所以需要将每一句话的单词提取出来,这也是为什么我们需要去除标点的原因,因为去除标点后比较好分词。
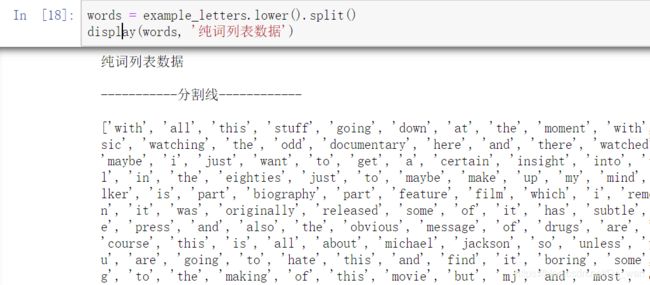
上图为得到分词后的结果,全部转为小写。
4.去停用词
停用词类似于be、but、by等等这些对情感分析毫无影响的词语,需要全部去掉,以免干扰结果。
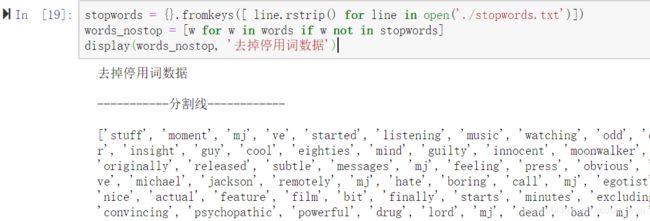
上图中像with,all,this这些单词都已经去除了。
5.重组为新句子
第一个cell中写了一个新函数clean_text,其功能就是将上述4条的功能写进一个函数。然后返回一个合并好的新句子(这个句子毫无语法而言,因为去掉了一些单词)。
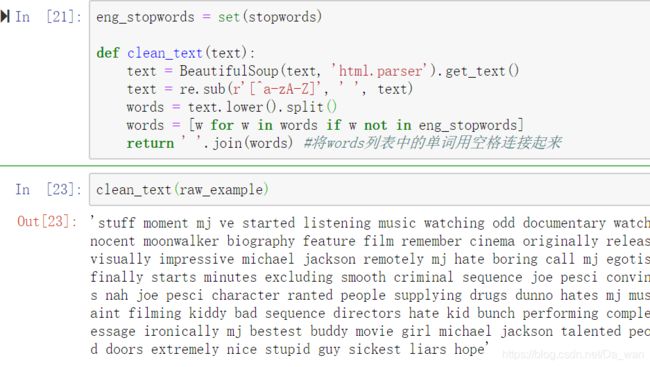
得到的就是上图中输出的这一条句子。这仅仅只是一个影评,需要对文档中的25000条影评做同样处理,得到新的一栏clean_review

这只是一个简单的处理,将文本处理成自己想要得到的有用信息。
三、word2vec词向量编码
得到清洗的文本后表示已经完成了一步,接下来需要开始建立模型,训练模型了。我们都知道文本是没法被计算机分析的,只要0,1才是计算机处理的语言。接下来就是开始这一步操作,将清洗后的文本转为0,1矩阵才能开始训练模型。代码如下图所示:

vetorizer = CountVectorizer(max_features=5000):这行代码是统计所有文本中词频前5000的单词,这是一个类,目前还没有对文本进行任何操作,只是先设置成这样,也可以改成4000,6000等等。
train_data_features = vetorizer.fit_transform(df.clean_review).toarray():这表示开始对文本进行处理了,标准就为上一行代码设置的那样,然后转换为数组的形式。
得到的为25000行,5000列的数据:通俗一点讲呢就是先统计频数最多的前5000个单词为标准,第一个影评中有一个单词在这5000个里面就标为1,没有就标0,后面的类推。完成后,就将这25000行文本转为了(25000L,5000L)的数组了,这也是我们前面所做的操作的最终目标。
四、构造随机森林分类器
在将所有影评数据处理成(25000L,5000L)的向量后,需要将这些数据放入模型中去训练,才能预测之后的影评数据是好评还是差评。
![]()
forest = RandomForestClassifier(n_estimators=100):表示构造一个随机森林分类器。
forest = forest.fit(train_data_features, df.sentiment):表示将处理好的影评数据(25000L,5000L),和是否好评的数据(0\1)放入模型中训练。运行后,则表示模型已经训练完成。
五、预测测试集的情感状态
1.预处理测试集数据
在训练完模型后,为了测试模型的好坏,我们需要通过测试集(testData.tsv)来验证这个模型。测试集中没有sentiment一栏,因为这就是我们需要预测的结果。对测试集我们同样需要进行如上所示的1,2,3,4的操作来清洗影评数据。

最终我们也得到了测试集中25000条影评的特征向量,也就是(25000L,5000L)数组.
2.预测测试集影评情感状态
在得到了测试集的特征向量后,我们就可以开始进行预测了。
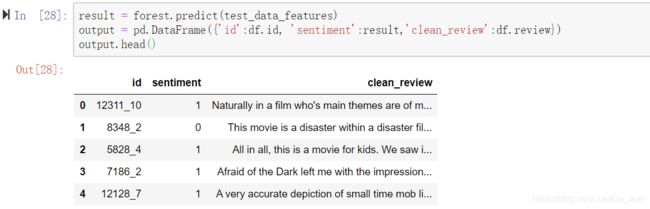
我们通过建立好的随机森林模型,往其中丢入测试集的数组,就可以得到预测的sentiment(情感状态),然后输出结果。
3.检测预测结果
在预测好后,我们看看,预测的sentiment这一栏到底准不准确,我们先看看第一条影评数据是好评还是差评,从上图可知第一条预测的结果为1(好评)。将第一条影评拿下来翻译看看:

根据意思大概也能看出是一条好评,后面的这些预测结果我也检查了一些,的确挺准确的。
六、总结
对以上部分做一个小小的概括:
1.先对训练集做预处理,将文本转为机器方便处理的0,1数组。
2.建立模型,训练模型
3.对测试集做预处理,预测测试集中的影评是好评还是差评
4.检查结果,完成
以上是我在学习过程中记录的一些笔记,内容可能不太规范,还请见谅。本文的代码,训练集,测试集等文件都已经上传。