创新实训(49)——后端sql优化,提升sql运行速度
前言
在使用网页时,发现有的板块刷新比较慢,体验很不好,之前也优化过多次代码的逻辑以及使用spring cache提高响应速度,今天从sql的角度优化一下代码的执行速度。
select * from 的问题
项目中有很多操作是获取文章列表,而之前获取文章列表时常常使用select * from article 后面接着代码逻辑,但是文章列表显示的内容有限,根本不可能显示所以内容,所以优化了相关方面的sql,将select * from article改成了查询具体的字段,这样不仅提升了sql的效率,还提升了网络中传输数据的效率,比较文本内容还是很长的,传输起来比较费劲,在查询列表时,并不需要显示文本的内容。
count(1)、count(*)与count(列名)的问题
经过查阅资料:
(1) count(1) andcount(*)
当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count(*)用时多了!从执行计划来看,count(1)
和count()的效果是一样的。但是在表做过分析之后,count(1)会比count(*)的用时少些,不过差不了多少。
如果count(1)是聚索引,id,那肯定是count(1)快。但是差的很小的。
因为count(*)自动会优化指定到那一个字段。所以没必要去count(1),用count(),sql会帮你完成优化的 因此:
count(1)和count(*)基本没有差别!
(2)count(1) and count(字段)
两者的主要区别是
count(1) 会统计表中的所有的记录数,包含字段为null 的记录。
count(字段) 会统计该字段在表中出现的次数,忽略字段为null 的情况。即不统计字段为null 的记录。
(3)count(*) 和 count(1)和count(列名)区别
执行效果上:
count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL
count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL
count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。
执行效率上:
列名为主键,count(列名)会比count(1)快
列名不为主键,count(1)会比count(列名)快
如果表多个列并且没有主键,则 count(1) 的执行效率优于 count(*)
如果有主键,则 select count(主键)的执行效率是最优的
如果表只有一个字段,则 select count(*)最优。
内连接和笛卡尔积的运行速度问题
参考资料:https://zhuanlan.zhihu.com/p/54699827

通过测试发现,内连接和笛卡尔积没什么运行速度的区别,内连接只要保证小表连接大表即可,mysql的内连接会自动选择小表连接大表,所以没什么影响,而外连接就要注意让小表去连接大表了。
进行表的连接时,提前进行筛选 提高运行效率
一个比较明显的提升,三个表的连接,并且有一个表非常大,通过提前对数据进行选择,减小数据量,提升sql的运行效率
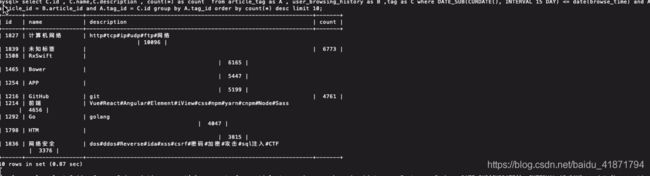
优化前:
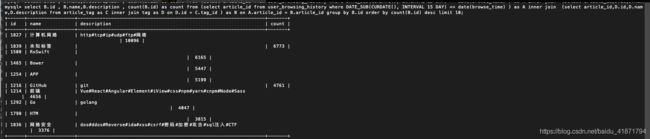
优化后:
优化前sql:
select C.id , C.name,C.description , count(*) as count
from article_tag as A , user_browsing_history as B ,tag as C
where DATE_SUB(CURDATE(), INTERVAL #{day} DAY) <= date(browse_time)
and A.article_id = B.article_id and A.tag_id = C.id
group by A.tag_id
order by count(*) desc
limit #{limit} offset #{offset}
优化后sql:
select B.id , B.name,B.description , count(B.id) as count from
(select article_id from user_browsing_history
where DATE_SUB(CURDATE(), INTERVAL #{day} DAY) <= date(browse_time) ) as A
inner join
(select article_id,D.id,D.name,D.description from article_tag as C inner join tag as D on D.id = C.tag_id ) as B
on A.article_id = B.article_id
group by B.id
order by count(B.id) desc
limit #{limit} offset #{offset}
其他诸如此类的操作就不一一贴出了,原理是一样的,提前进行表的连接操作
进行表的连接,然后order by时,可以提前进行选择,排序,然后在进行表的连接
优化前:

优化后:

优化前sql:
SELECT distinct A.id, A.author ,A.update_time,A.title,A.summary,
A.read_count,A.like_count,A.blog_id
FROM article as A , user_liking as B
where B.user_id = #{userId} and A.id = B.article_id
ORDER BY B.click_liking_time
DESC limit #{limit} offset #{offset}
优化后sql:
SELECT A.id, A.author ,A.update_time,A.title,
A.summary,A.read_count,
A.like_count,A.blog_id FROM
article as A
inner join
(select distinct article_id
from user_liking
where user_id = #{userId}
ORDER BY click_liking_time DESC )as B
on A.id = B.article_id
limit #{limit} offset #{offset}
其他诸如此类的sql也会按照这个原则进行优化的
学习到的一个操作
如果where条件筛选的字段有索引的话,比如id>1000,id有索引,可以先将id进行order by ,这样可以提高选择的效率,我看有一篇博客这么写的,我还没有尝试,不知道效果怎么样。
总结
对后端项目中的sql语句进行了一定程度上的优化,虽然表不是很大,优化的速度也比较有限,但是做优化还是有必要的。