激活函数总结
一 主要作用
激活函数的主要作用就是加入非线性因素,以解决线性模型表达能力不足的缺陷,在整个神经网络起到至关重要的作用。
在神经网络中常用的激活函数有Sigmoid、Tanh和relu等,下面逐一介绍。
二 Sigmod函数
1
函数介绍
Sigmoid是常用的非线性的激活函数,数学公式如下:
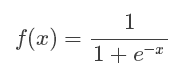
2 函数曲线
Sigmoid函数曲线如下图,其中x可以是负无穷到正无穷,但是对应的y却只有0~1的范围,所以,经过Sigmoid函数输出的都会落到0~1的区间,即Sigmod函数能够把输入的值“压缩”到0~1之间。
3 在TensorFlow中对应的函数
在TensorFlow中对应的函数为:
tf.nn.sigmoid(x,name=None)
从图像上看,随着x趋近正负无穷大,y对应的值越来越接近1或-1,这种情况叫做饱和。处于饱和态的激活函数意味着,当x=1000和x=100时的反映都是一样的。
所以,为了能有效使用Sigmod函数,其极限只能在-6~6之间,而在-3~3之间应该会有比较好的效果。
三 Tanh函数
1 函数介绍
Tanh函数可以说是Sigmoid函数的值域升级版,由Sigmoid函数的0~1之间升级到-1~1.但是Tanh函数也不能完全替代Sigmoid函数,在某些输出需要大于0的情况下,还是要用Sigmoid函数。
Tanh函数也是常用的非线性激活函数,其数学形式如下:
tanh(x)=2sigmoid(2x)−1
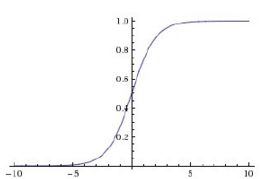
2 函数曲线
Tanh函数曲线如下图,其x取值也是从负无穷到正无穷,对应的y值变成-1到1之间,相对于Sigmoid函数有更广的值域。
3 在TensorFlow中对应的函数
在TensorFlow中对应的函数
tf.nn.tanh(x,name=None)
显而易见,Tanh函数跟Sigmoid函数有一样的缺陷,也是饱和问题,所以在使用Tanh函数时,要注意输入值的绝对值不能过大,否则模型无法训练。
四 ReLU函数
1 函数介绍
更为常用的激活函数(也称为Rectifier)。其数学公式如下:
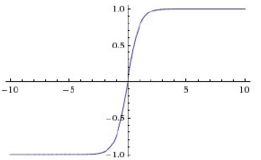
f(x)=max(0,x)
该公式非常简单,大于0的留下,否则一律为0,具体图像如下图
ReLU函数应用的广泛性与它的优势是分不开的,这种对正向信号的重视,忽略了负向信号的特性,与我们人类神经细胞对信号反映及其相似。所以在神经网络中取得了很好的拟合效果。
另外由于ReLU函数运算简单,大大地提升了机器的运行效率,也是Relu函数一个很大的优点。
与Relu函数类似的还有SoftPlus函数。
公式介绍:
两者曲线比较如下:
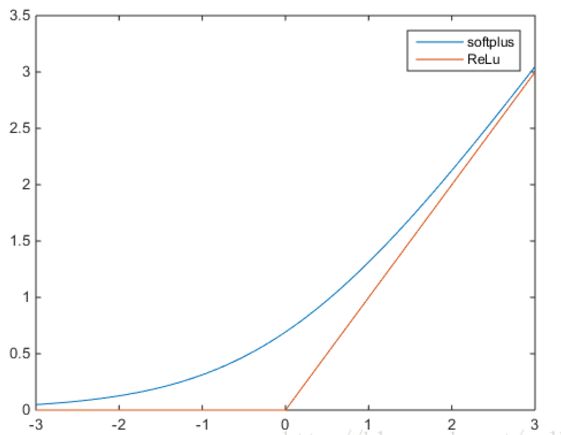
二者的区别:SoftPlus函数更加平滑,但是计算量很大,小于0的值保留的相对更多一点。
虽然ReLU函数在信号响应上有很多优势,但这仅仅是在正向传播方面。由于其对负值的全部舍弃,因此很容易使模型输出全零从而无法再进行训练。例如,随机初始化的w加入值中有个负值,其对应的正值输入值特征也被全部屏蔽了,同理,对应负值输入值反而被激活了。这显然不是我们想要的结果。于是在ReLU的基础上又演化出了些变种函数。
- Noisy relus
为max中的x加了一个高斯分布的噪声。
公式如下:
Leak relus
在ReLU基础上,保留一部分负值,让x为负值时乘0.01,即Leak relus对负信号不是一味地拒绝,而是缩小。
数学公式如下:

再进一步让这个0.01作为参数可调,于是,当x小于0时,乘以a,a小于等于1.其数学形式
f(x)=max(x,ax)
- Elus
当x小于0时,做更复杂的变化
公式如下:
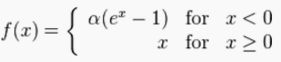
Elus函数激活函数与ReLU函数一样都是不带参数的,而且收敛速度比ReUL函数要快。
Elus函数,不使用批处理比使用批处理能够获得更好的效果。
Elus函数,不使用批处理的效果比ReUL函数加批处理效果更好。
2 TensorFlow中对应的函数
在TensorFlow中,关于ReUL函数的实现,有以下两个对应的函数
tf.nn.relu(features,name=None):一般ReUL函数,即max(features,0)
tf.nn.relu6(features,name=None):是以6为阈值的ReUL函数,即min(max(features,0),6)
在TensorFlow中,Softplus函数对应的函数如下:
tn.nn.softplus(features,name=None)
在TensorFlow中,Elus函数对应的函数如下:
tf.nn.elu(features,name=None)
在TensorFlow中,Leaky rulus公式没有专门的函数,不过可以利用现有的函数组成而得到
tf.maximum(x,leak*x,name=name) #leak为传入的参数,可以设为0.01等。
五 Swish
Swish函数是谷歌公司发现的一个效果更优于Relu的激活函数。经过测试,在保持所有的模型参数不变的情况下,只是把原来模型中ReLU激活函数修改为Swish函数,模型的准确率均有上升。
公式如下:
f(x)=x * sigmod(x),
变形Swish-B激活函数的公式则为f(x)=x * sigmod(b * x)
其中b为x的缩放参数,一般情况取默认值1即可.
在TensorFlow的低版本中,没有单独的Swish函数,可以手动封装,代码如下:
def Swish(x,beta=1):
return x*tf.nn.sigmoid(x*beta)
六 小结
神经网络中,运算特征是不断进行循环计算,所以在每次循环过程中,每个神经元的值也是不断变化的,这就导致了Tanh函数在特征相差明显时候效果会很好,在循环过程中其会不断扩大特征效果并显示出来。
但有时候当计算的特征间的相差虽比较复杂却没有明显区别,或是特征间的相差不是特别大时,就需要更细微的分类判断,这时Sigmoid函数的效果会更好一些。
后来出现的ReLU激活函数的优势是,经过其处理后的数据有更好的稀疏性。即,将数据转化为只有最大数值,其他都为0.这种变换可以近似程度地保留数据特征,用大多数元素为0的稀疏矩阵来实现。
实际上,神经网络在不断反复计算中,就变成了ReLU函数在不断尝试如何用一个大多数0的矩阵来表达数据特征。以稀疏性数据来表达原有数据特性的方法,使得神经网络在迭代运算中能够取得又快又好的效果。所有目前大多数用max(0,x)来代替Sigmoid函数。
七 参考
https://blog.csdn.net/bojackhosreman/article/details/69372087
https://blog.csdn.net/qrlhl/article/details/60883604
https://blog.csdn.net/swfa1/article/details/45601789
https://blog.csdn.net/FontThrone/article/details/78636353