基于SpringBoot + MyBatis + WebMagic的爬虫
基于SpringBoot + MyBatis + WebMagic的爬虫
1、爬虫功能模块介绍
1)项目结构总览
- 数据的存储
- 数据导出为excel格式进行查看
- WebMagic爬虫逻辑编写
- 后端与前端建立通信掌握爬虫进度
- Web前端逻辑编写
- SpringBoot整合项目启动类
下面是各个模块代码的详细介绍
2、数据的存储
1)实体类对象
-
每个页面的存储对象都要相应的建立一个实体类对象
-
这里我拿
institutioninfo举例/** * @author 90934 * @create 2020/2/2 * @since 1.0.0 * 只写变量名称,get、set和tostring()全部都直接自动生成 */ @Entity(name = "institution_info") public class InstitutionInfo { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; private String name; private String rnumber; private String oname; private String cperson; private String cnumber; private String pcode; private String fnumber; private String weburl; private String email; private String address; private String start; private String end; private String abasis; private String parameter; private String baseinfoid; }
2) 构造存储数据的方法
-
构造dao层中的数据库接口
/** * @author 90934 * 继承JpaRepository中的方法,减少代码的书写量 */ public interface InstitutionInfoDao extends JpaRepository<InstitutionInfo, Long> { }
3)构造存储的接口和实现方法
-
构造存储的service接口
/** * @author 90934 */ @Component public interface InstitutionInfoService { /** * fetch data by rule id * * @param institutionInfo rule id */ void save(InstitutionInfo institutionInfo); /** * fetch data by rule id * * @param institutionInfo rule id * @return Result*/ List<InstitutionInfo> findInstitutionInfo(InstitutionInfo institutionInfo); /** * 查询数据库中所有的数据 * * @return InstitutionInfo */ List<InstitutionInfo> findAll(); } -
构造service接口的实现类impl
/** * @author 90934 */ @Service public class InstitutionInfoServiceImpl implements InstitutionInfoService { private InstitutionInfoDao institutionInfoDao; @Autowired public void setInstitutionInfoDao(InstitutionInfoDao institutionInfoDao) { this.institutionInfoDao = institutionInfoDao; } @Override @Transactional(rollbackFor = Exception.class) public void save(InstitutionInfo institutionInfo) { //根据机构名称查询数据 InstitutionInfo param = new InstitutionInfo(); param.setName(institutionInfo.getName()); //执行查询 List<InstitutionInfo> list = this.findInstitutionInfo(param); //判断查询结果是否为空 if (list.size() == 0) { //如果结果为空,表示机构基本信息不存在,需要更新数据库 this.institutionInfoDao.save(institutionInfo); } //打开注释,将爬取的数据显示到web端页面进行查看,注意当爬虫数据过快已造成页面崩溃 try { ProductWebSocket.sendInfo("已成功采集 1 条数据!"); } catch (IOException e) { e.printStackTrace(); } } @Override public List<InstitutionInfo> findInstitutionInfo(InstitutionInfo institutionInfo) { //设置查询条件 Example<InstitutionInfo> example = Example.of(institutionInfo); //执行查询 return this.institutionInfoDao.findAll(example); } @Override public List<InstitutionInfo> findAll() { return this.institutionInfoDao.findAll(); } }
3、数据导出为excel格式进行查看
根据此博客内容进行修改:https://www.cnblogs.com/wlxslsb/p/10931130.html
1)构造实体类
构造两个实体类对象,分别存储表的信息和表中的字段名称
-
构造数据库中表信息的实体
-
/** * @author 90934 * @date 2020/2/29 23:47 * @description 导出主题表 * @since 0.1.0 * 只写变量名称,get、set和tostring()全部都直接自动生成 */ public class ExportBean { private Integer id; private String exportCode; private String exportName; private List<ExportFieldBean> fieldBeanList; }
-
-
构造数据库中表信息的实体
-
DROP TABLE IF EXISTS `export`; CREATE TABLE `export` ( `id` int(32) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键', `exportCode` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '导出主题英文名', `exportName` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '导出主题中文名', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 4 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '导出主题表' ROW_FORMAT = Dynamic;
-
-
构造表中的字段信息的实体对象
-
/** * @author 90934 * @date 2020/2/29 23:49 * @description 导出字段表 * @since 0.1.0 * 只写变量名称,get、set和tostring()全部都直接自动生成 */ public class ExportFieldBean { private Integer id; private Integer exportId; private String fieldCode; private String fieldName; private Integer sort; private ExportBean exportBean;
-
-
构造表中字段信息需要的sql语句
-
DROP TABLE IF EXISTS `export_field`; CREATE TABLE `export_field` ( `id` int(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键', `exportId` int(11) UNSIGNED NULL DEFAULT NULL COMMENT '导出主表ID', `fieldCode` varchar(55) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '字段英文名', `fieldName` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '字段中文名', `sort` int(11) UNSIGNED NULL DEFAULT 1 COMMENT '排序字段', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 40 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '导出字段表' ROW_FORMAT = Dynamic;
-
2)使用MyBatis构造mapper对象
使用级联操作查询数据库中相应表和表中字段的信息
-
构造ExportMapper接口查询数据库中表信息,级联在查询当前表信息的时候同时查询其中的表中的字段信息
-
** * @author 90934 * @date 2020/2/29 23:51 * @description 导出字段的方法接口 * @since 0.1.0 */ public interface ExportMapper { /** * 获取各个字段的名称 * @param exportKey 字段名称 * @return ExportBean */ @Select("select * from export where exportCode = #{exportKey}") @Results({ @Result(property="fieldBeanList",column="id",one=@One(select="com.hellof.crawler.mapper.ExportFieldMapper" + ".getExportFieldBeanByExportid")) }) ExportBean getExportByExportKey(String exportKey); }
-
-
构造ExportFieldMapper接口查询相应表中的字段信息
-
/** * @author 90934 * @date 2020/3/1 19:33 * @description 获取相关联的field对象 * @since 0.1.0 */ public interface ExportFieldMapper { /** * 获取各个field表中的字段信息 * @param exportid 识别属于表中信息的字段 * @return n */ @Select("select * from export_field where exportId = #{exportid}") ExportFieldBean getExportFieldBeanByExportid(String exportid); }
-
3)构造导出为Excel格式的Service接口及其impl实现类
构造IExportExcelService接口和其相对应的IExportExcelServiceImpl实现类
-
IExportExcelService方法接口
-
public interface IExportExcelService { /** * 根据exportKey查询需要导出的字段,并匹配list每个类中字段来到出excel * @param exportKey 数据库存储的导出英文名 * @param fileName 文件名 * @param list 要到出的数据 * @param req 请求 * @param resp 响应 */ public void exportExcelWithDispose(String exportKey, String fileName, List<?> list, HttpServletRequest req, HttpServletResponse resp); }
-
-
IEportExcelServiceImpl方法接口实现类
-
@Service public class ExportExcelServiceImpl implements IExportExcelService { private ExportMapper exportMapper; @Resource public void setExportMapper(ExportMapper exportMapper) { this.exportMapper = exportMapper; } @Override public void exportExcelWithDispose(String exportKey, String fileName, List<?> list, HttpServletRequest req, HttpServletResponse resp) { List<ExportFieldBean> fieldBeans = this.exportMapper.getExportByExportKey(exportKey).getFieldBeanList(); try { SXSSFWorkbook sxssfWorkbook = new SXSSFWorkbook(); SXSSFSheet sheet1 = sxssfWorkbook.createSheet(fileName); SXSSFRow headRow = sheet1.createRow(0); headRow.createCell(0).setCellValue("序号"); for (ExportFieldBean fieldBean: fieldBeans){ headRow.createCell(headRow.getLastCellNum()).setCellValue(fieldBean.getFieldName()); } int index = 0; SXSSFRow bodyRow = null; JSONArray jsonArray = JSONArray.fromObject(list); for (Object obj:jsonArray){ bodyRow = sheet1.createRow(sheet1.getLastRowNum() + 1); bodyRow.createCell(0).setCellValue(index++); int flag = 0; for (ExportFieldBean fieldBean: fieldBeans){ if (flag == 0){ bodyRow.createCell(bodyRow.getLastCellNum()).setCellValue((Integer) ((JSONObject)obj).get(fieldBean.getFieldCode())); flag = 1; }else { bodyRow.createCell(bodyRow.getLastCellNum()).setCellValue((String) ((JSONObject)obj).get(fieldBean.getFieldCode())); } } } FileOutputStream outputStream = new FileOutputStream(fileName + ".xlsx"); sxssfWorkbook.write(outputStream); outputStream.close(); sxssfWorkbook.close(); //打开注释,将爬取的数据显示到web端页面进行查看,注意当爬虫数据过快已造成页面崩溃 ProductWebSocket.sendInfo("已成功导出 " + list.size() + " 条数据!"); }catch (Exception e){ e.printStackTrace(); } } }
-
4、WebMagic爬虫逻辑代码
WebMagic是一个优秀的可二次开发的爬虫框架,此代码逻辑就是采用这个框架进行编写的
WebMagic框架对于爬虫中的大多数方法都有一个包装好的方法,使用者不必重复进行代码的编写
在使用WebMagic框架的时候,只需要重写PageProcessorr方法就可以完成一个爬虫的构建,如果有额外的需求只需要完成响应方法的重写就可以构建一个优秀的爬虫项目。
官方中文说明文档:http://webmagic.io/docs/zh/posts/ch1-overview/
1)重写PageProcessor方法完成代码逻辑
-
/** * @author 90934 * @date 2020/3/2 18:25 * @description 重写PageProcessor方法 * @since 0.1.0 */ @Component public class TestProcessor implements PageProcessor { @Override public void process(Page page) { } @Override public Site getSite() { return site; } } -
重写process()方法发现链接,将相应链接加入到爬虫队列中等待进程,判断爬虫队列中的连接的类型调用相应的爬取规则,因为现在大多数网页的页面内容是使用ajax技术异步加载出来的,所以必须使用一些自动化测试包来加载网页,通过分析网页的组成来发现链接(本人使用的是Selenium)
@Override public void process(Page page) { //判断url的类型 String queryData = page.getUrl().regex("query\\w+").toString(); String institutionInfo = "queryOrgInfo1"; String domainInfo = "queryPublishSignatory"; String scopeInfo = "queryPublishIBAbilityQuery"; if (queryData.equals(institutionInfo)) { //判断url目的地址是不是queryOrgInfo1 this.saveInstitutionInfo(page); } else if (queryData.equals(domainInfo)) { //判断url目的地址是不是queryPublishSignatory this.saveDomainInfo(page); } else if (queryData.equals(scopeInfo)) { //判断url目的地址是不是queryPublishIBAbilityQuery this.saveScopeInfo(page); } else { List<String> urls = new ArrayList<>(); System.setProperty("webdriver.chrome.driver", "src/main/resources/static/chromedriver.exe"); WebDriver driver = new ChromeDriver(); String url = page.getUrl().toString(); driver.get(url); List<String> addressList = GetAddress.resultData(); //方便测试 // ListaddressList = new ArrayList<>(); // addressList.add("北京"); // addressList.add("天津"); for (String address : addressList) { WebElement orgAddress = driver.findElement(By.id("orgAddress")); orgAddress.clear(); orgAddress.sendKeys(address); WebElement btn = driver.findElement(By.className("btn")); btn.click(); try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } boolean accept = true; while (accept) { try { WebElement pirbutton1 = driver.findElement(By.xpath("//*[@id=\"pirlbutton1\"]")); pirbutton1.click(); Thread.sleep(5000); boolean flagStr = driver.findElement(By.id("pirlAuthInterceptDiv_c")).isDisplayed(); if (!flagStr) { accept = false; } } catch (InterruptedException e) { e.printStackTrace(); } } boolean flagStr = driver.findElement(By.xpath("//*[@id=\"pirlAuthInterceptDiv_c\"]")).isDisplayed(); if (!flagStr) { int maxPage = Integer.parseInt(driver.findElement(By.id("yui-pg0-0-totalPages-span")).getText()); for (int num = 0; num < maxPage; num++) { Html html = Html.create(driver.findElement(By.xpath("//*")).getAttribute("outerHTML")); List<Selectable> list = html.css("div.yui-dt-liner a").nodes(); if (list.size() != 0) { for (Selectable selectable : list) { //获取id String urlStr = selectable.regex("id\\=\\w+").toString(); //组装url放入待爬取队列 urls.add("https://las.cnas.org.cn/LAS/publish/queryOrgInfo1.action?" + urlStr); } } if (num <= maxPage - 2) { WebElement pageNext = driver.findElement(By.xpath("/html/body/div[5]/table/tbody/tr/td[4]/a/img")); pageNext.click(); try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } boolean acceptStr = true; while (acceptStr) { try { //获得点击确定按钮的对象 WebElement pirbutton1 = driver.findElement(By.xpath("//*[@id=\"pirlbutton1\"]")); pirbutton1.click(); Thread.sleep(4000); //判断页面是否还有验证码 boolean flagStr1 = driver.findElement(By.id("pirlAuthInterceptDiv_c")).isDisplayed(); if (!flagStr1) { acceptStr = false; } } catch (InterruptedException e) { e.printStackTrace(); } } } } } } driver.close(); driver.quit(); //将待爬取url放入队列中 page.addTargetRequests(urls); } } -
根据重写的process方法中判断的链接网页的类型调用相应的方法,经过分析知道本页面的链接中在往后的爬取中可分为三种类型:InstitutionInfo、DomainInfo、ScopeInfo;分别构造他们的方法,对页面经行解析
-
InstitutionInfo
/** * 解析页面,获取机构基本信息,保存数据 */ private void saveInstitutionInfo(Page page) { //创建机构基本信息对象 InstitutionInfo institutionInfo = new InstitutionInfo(); //解析页面 Html html = page.getHtml(); //获取对象,封装到对象中 institutionInfo.setName(html.css("div.T1", "text").toString()); institutionInfo.setRnumber(Jsoup.parse(html.css("span.clabel").nodes().get(0).toString()).text()); institutionInfo.setOname(Jsoup.parse(html.css("span.clabel").nodes().get(1).toString()).text()); institutionInfo.setCperson(Jsoup.parse(html.css("span.clabel").nodes().get(2).toString()).text()); institutionInfo.setCnumber(Jsoup.parse(html.css("span.clabel").nodes().get(3).toString()).text()); institutionInfo.setPcode(Jsoup.parse(html.css("span.clabel").nodes().get(4).toString()).text()); institutionInfo.setFnumber(Jsoup.parse(html.css("span.clabel").nodes().get(5).toString()).text()); institutionInfo.setWeburl(Jsoup.parse(html.css("span.clabel").nodes().get(6).toString()).text()); institutionInfo.setEmail(Jsoup.parse(html.css("span.clabel").nodes().get(7).toString()).text()); institutionInfo.setAddress(Jsoup.parse(html.css("span.clabel").nodes().get(8).toString()).text()); institutionInfo.setStart(Jsoup.parse(html.css("span.clabel").nodes().get(9).toString()).text()); institutionInfo.setEnd(Jsoup.parse(html.css("span.clabel").nodes().get(10).toString()).text()); institutionInfo.setAbasis(Jsoup.parse(html.css("span.clabel").nodes().get(11).toString()).text()); try { institutionInfo.setParameter(Jsoup.parse(html.css("span.clabel").nodes().get(12).toString()).text()); } catch (Exception e) { e.printStackTrace(); institutionInfo.setParameter(null); } //获取结构化数据的url String dataUrl = html.xpath("/html/body/div/table[2]/tbody/tr/td/a/@onclick") .regex("foId\\=\\w+").regex("\\=\\w+").regex("[^\\=]\\w+") .toString(); institutionInfo.setBaseinfoid(dataUrl); if (dataUrl != null && dataUrl.length() != 0) { //认可的授权签字人及领域 String domainUrl = "https://las.cnas.org.cn/LAS/publish/queryPublishSignatory.action?baseinfoId=" + dataUrl; //放进待爬取队列 page.addTargetRequest(domainUrl); //认可的检验能力范围 String scopeUrl = "https://las.cnas.org.cn/LAS/publish/queryPublishIBAbilityQuery.action?baseinfoId=" + dataUrl; //放进待爬取队列 page.addTargetRequest(scopeUrl); } //把结果保存起来 page.putField("institutionInfo", institutionInfo); } -
DomainInfo,这个方法比较特殊,因为涉及到json数据的解析,所以在存储数据的时候需要一次存储多组数据,并且在存储的时候需要与之前的数据构造相应的联系例:属于XXX公司的XXX信息,所以需要在这个地方进行一个匹配,通过查询数据库中已存入的信息的某个字段来判断这个json数据属于XXX公司的并将它们组合起来进行存储;这个地方为了避免方法调用时出现空指针错误,所以构造一个方法来装配接下来需要调用的方法。SpringUtil
-
SpringUtil
/** * @author 90934 * @date 2020/2/13 2:03 * @description 解决this.方法无效的工具类 * @since 0.1.0 */ @Component public class SpringUtil implements ApplicationContextAware { private static ApplicationContext applicationContext = null; @Override public void setApplicationContext(@NonNull ApplicationContext applicationContext) throws BeansException { SpringUtil.applicationContext = applicationContext; } public static <T> T getBean(Class<T> cla) { return applicationContext.getBean(cla); } public static <T> T getBean(String name, Class<T> cal) { return applicationContext.getBean(name, cal); } public static Object getBean(String name){ return applicationContext.getBean(name); } public static String getProperty(String key) { return applicationContext.getBean(Environment.class).getProperty(key); } } -
DomainInfo
/** * 装配Service接口,稍后调用查询方法查询相应的字段联系XXX公司和JSon数据的联系 */ private InstitutionInfoService institutionInfoService; @Autowired public void setInstitutionInfoService(InstitutionInfoService institutionInfoService) { this.institutionInfoService = institutionInfoService; } /** * 解析josn格式数据,存储认可的授权签字人及领域数据 */ private void saveDomainInfo(Page page) { //创建一个机构基本信息的实体类查询机构的基本信息,准备整合数据 InstitutionInfo param = new InstitutionInfo(); //创建认可的签字人及领域实体类对象 List<InstitutionDomain> institutionDomains = new ArrayList<>(); //解析json数据, 分离json数据 Json json = page.getJson(); //获取json数据中的baseinfoid的值 String baseinfoid = page.getUrl().regex("foId\\=\\w+").regex("\\=\\w+").regex("[^\\=]\\w+").toString(); //获取json数据中的所有姓名的值 List<String> nameCh = json.jsonPath("$.data[*].nameCh").all(); //获取json数据中的所有评估说明的值 List<String> content = json.jsonPath("$.data[*].assessmentcontent").all(); //获取json数据中的所有授权签字领域的值 List<String> authorizedFieldCh = json.jsonPath("$.data[*].authorizedFieldCh").all(); //获取json数据中的所有说明的值 List<String> note = json.jsonPath("$.data[*].note").all(); //获取json数据中的所有状态的值status List<String> status; status = json.jsonPath("$.data[*].status").all(); param.setBaseinfoid(baseinfoid); List<InstitutionInfo> institutionInfos = getService().institutionInfoService.findInstitutionInfo(param); String name; String date; if (institutionInfos.size() != 0) { InstitutionInfo institutionInfo = institutionInfos.get(0); name = institutionInfo.getName(); date = institutionInfo.getStart() + "-" + institutionInfo.getEnd(); for (int num = 0; num < nameCh.size(); num++) { //创建认可的签字人及领域实体类对象 InstitutionDomain institutionDomain = new InstitutionDomain(); institutionDomain.setIname(name); institutionDomain.setVperiod(date); institutionDomain.setName(nameCh.get(num)); institutionDomain.setContent(content.get(num)); institutionDomain.setDomain(authorizedFieldCh.get(num)); institutionDomain.setDescription(note.get(num)); if ("0".equals(status.get(num))) { institutionDomain.setStatus("有效"); } else { institutionDomain.setStatus("无效"); } institutionDomains.add(institutionDomain); } page.putField("institutionDomains", institutionDomains); } } -
ScopeInfo
/** * 解析josn格式数据,存储认可的检验能力范围数据 * 同理也需要同XXX公司建立联系 */ private void saveScopeInfo(Page page) { //创建一个机构基本信息的实体类查询机构的基本信息,准备整合数据 InstitutionInfo param = new InstitutionInfo(); List<InstitutionTest> institutionTests = new ArrayList<>(); Json json = page.getJson(); //获取json数据中的baseinfoid的值 String baseinfoid = page.getUrl().regex("foId\\=\\w+").regex("\\=\\w+").regex("[^\\=]\\w+").toString(); List<String> bigTypeName = json.jsonPath("$.data[*].bigTypeName").all(); List<String> typeName = json.jsonPath("$.data[*].typeName").all(); List<String> num = json.jsonPath("$.data[*].num").all(); List<String> fieldch = json.jsonPath("$.data[*].fieldch").all(); List<String> detnum = json.jsonPath("$.data[*].detnum").all(); List<String> descriptCh = json.jsonPath("$.data[*].descriptCh").all(); List<String> stdNum = json.jsonPath("$.data[*].stdNum").all(); List<String> standardCh = json.jsonPath("$.data[*].standardCh").all(); List<String> order = json.jsonPath("$.data[*].order").all(); List<String> restrictCh = json.jsonPath("$.data[*].restrictCh").all(); List<String> status = json.jsonPath("$.data[*].status").all(); param.setBaseinfoid(baseinfoid); List<InstitutionInfo> institutionInfos = getService().institutionInfoService.findInstitutionInfo(param); String name; String date; if (institutionInfos.size() != 0) { InstitutionInfo institutionInfo = institutionInfos.get(0); name = institutionInfo.getName(); date = institutionInfo.getStart() + "-" + institutionInfo.getEnd(); for (int i = 0; i < fieldch.size(); i++) { InstitutionTest institutionTest = new InstitutionTest(); institutionTest.setIname(name); institutionTest.setVperiod(date); institutionTest.setBigtypename(bigTypeName.get(i)); institutionTest.setTypename(typeName.get(i)); institutionTest.setNum(num.get(i)); institutionTest.setFieldch(fieldch.get(i)); institutionTest.setDetnum(detnum.get(i)); institutionTest.setDescriptch(descriptCh.get(i)); institutionTest.setStdnum(stdNum.get(i)); institutionTest.setStandardchorder(standardCh.get(i) + " " + order.get(i)); institutionTest.setRestrictch(restrictCh.get(i)); if ("0".equals(status.get(i))) { institutionTest.setStatus("有效"); } else { institutionTest.setStatus("无效"); } institutionTests.add(institutionTest); } page.putField("institutionTests", institutionTests); } } -
Site
/** * 进行爬虫的一些单独的设置 */ private Site site = Site.me() //设置编码格式 .setCharset("utf8") //设置超时时间 .setTimeOut(10 * 1000) //设置重试的间隔时间 .setRetrySleepTime(3 * 1000) //设置重试的次数 .setRetryTimes(3); @Override public Site getSite() { return site; } -
Start
private InstitutionInfoPipeline institutionInfoPipeline; private InstitutionDomainPipeline institutionDomainPipeline; private InstitutionTestPipeline institutionTestPipeline; @Autowired public void setInstitutionInfoPipeline(InstitutionInfoPipeline institutionInfoPipeline) { this.institutionInfoPipeline = institutionInfoPipeline; } @Autowired public void setInstitutionDomainPipeline(InstitutionDomainPipeline institutionDomainPipeline) { this.institutionDomainPipeline = institutionDomainPipeline; } @Autowired public void setInstitutionTestPipeline(InstitutionTestPipeline institutionTestPipeline) { this.institutionTestPipeline = institutionTestPipeline; } /** * 爬虫的启动方法 */ public void start(PageProcessor pageProcessor) { //开启线程 Spider.create(pageProcessor) .addUrl("https://las.cnas.org.cn/LAS/publish/externalQueryIB.jsp") .setScheduler(new QueueScheduler().setDuplicateRemover(new BloomFilterDuplicateRemover(100000))) .addPipeline(this.institutionInfoPipeline) .addPipeline(this.institutionDomainPipeline) .addPipeline(this.institutionTestPipeline) .thread(10) .run(); try { ProductWebSocket.sendInfo("爬虫采集已结束,请在数据库中进行查看,或导出为Excel格式进行查看!"); } catch (Exception e) { e.printStackTrace(); } } -
构造装配Service的方法调用SpringUtil类
/** * @return SpringUtil工具类 */ private JobProcessor getService() { return SpringUtil.getBean(this.getClass()); }
-
2)重写Pipeline类构建数据通道存储爬虫的结果
1.InstitutionInfoPipeline
/**
* @author 90934
* @date 2020/2/3 18:31
* @description 定制的pipeline类
* @since 0.1.0
*/
@Component
public class InstitutionInfoPipeline implements Pipeline {
private InstitutionInfoService institutionInfoService;
@Autowired
public void setInstitutionInfoService(InstitutionInfoService institutionInfoService) {
this.institutionInfoService = institutionInfoService;
}
@Override
public void process(ResultItems resultItems, Task task) {
//获取封装好的机构基本信息对象
InstitutionInfo institutionInfo = resultItems.get("institutionInfo");
//判断数据是否为不空
if (institutionInfo != null) {
//如果不为空把数据保存在数据库中
this.institutionInfoService.save(institutionInfo);
}
}
}
2.InstitutionDomainPipeline
/**
* @author 90934
* @date 2020/2/7 12:27
* @description 定制认可的签字人及领域pipeline类
* @since 0.1.0
*/
@Component
public class InstitutionDomainPipeline implements Pipeline {
private InstitutionDomainService institutionDomainService;
@Autowired
public void setInstitutionDomainService(InstitutionDomainService institutionDomainService) {
this.institutionDomainService = institutionDomainService;
}
@Override
public void process(ResultItems resultItems, Task task) {
//获取封装好的pojo对象
List<InstitutionDomain> institutionDomains = resultItems.get("institutionDomains");
//判断数据是否为不空
if (institutionDomains != null) {
this.institutionDomainService.save(institutionDomains);
}
}
}
3.InstitutionTestPipeline
/**
* @author 90934
* @date 2020/2/9 21:41
* @description 自定义的认可的检验能力范围pipeline通道
* @since 0.1.0
*/
@Component
public class InstitutionTestPipeline implements Pipeline {
private InstitutionTestService institutionTestService;
@Autowired
public void setInstitutionTestService(InstitutionTestService institutionTestService) {
this.institutionTestService = institutionTestService;
}
@Override
public void process(ResultItems resultItems, Task task) {
//获取封装好的pojo实体类
List<InstitutionTest> institutionTests = resultItems.get("institutionTests");
if (institutionTests != null){
this.institutionTestService.save(institutionTests);
}
}
}
3)构造一个读取文档类GetAddress,读取address文档中的字段信息,根据字段信息来爬取相应区域的数据
/**
* @author 90934
* @date 2020/2/4 21:36
* @description 读取txt文档中的地址信息,导入爬虫进程
* @since 0.1.0
*/
public class GetAddress {
public static List<String> resultData() {
List<String> list = new ArrayList<>();
//读取更新后的机构基本信息url
String pathname = "classpath:static/address.txt";
try {
File file = ResourceUtils.getFile(pathname);
FileReader reader = new FileReader(file);
BufferedReader bufferedReader = new BufferedReader(reader);
String line = null;
while ((line = bufferedReader.readLine()) != null) {
//向List中添加url
list.add(line);
}
} catch (Exception e) {
e.printStackTrace();
}
return list;
}
}
5、后端与前端建立通信掌握爬虫进度
1)MyEndpointConfigure
/**
* @author 90934
* @date 2020/2/28 23:13
* @description 通信节点配置类
* @since 0.1.0
*/
public class MyEndpointConfigure extends ServerEndpointConfig.Configurator implements ApplicationContextAware {
private static volatile BeanFactory content;
@Override
public <T> T getEndpointInstance(Class<T> clazz) {
return content.getBean(clazz);
}
@Override
public void setApplicationContext(@NonNull ApplicationContext applicationContext) throws BeansException {
MyEndpointConfigure.content = applicationContext;
}
}
2)WebSocketConfig
/**
* @author 90934
* @date 2020/2/27 13:08
* @description websocket的configuration配置文件
* @since 0.1.0
*/
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.socket.server.standard.ServerEndpointExporter;
@Configuration
public class WebSocketConfig {
@Bean
public ServerEndpointExporter serverEndpointExporter() {
return new ServerEndpointExporter();
}
@Bean
public MyEndpointConfigure newConfigure() {
return new MyEndpointConfigure();
}
}
3)ProductWebSocket
/**
* @author 90934
* @date 2020/2/28 12:10
* @description WebSocket服务端
* @since 0.1.0
*/
@ServerEndpoint("/")
@Component
@Slf4j
public class ProductWebSocket {
/**
* 静态变量,用来记录当前在线连接数,应该把设计成线程安全的
*/
private static final AtomicInteger ONLINE_COUNT = new AtomicInteger(0);
/**
* concurrent包的线程安全set,用来存放每个客户端对应的ProductWebSocket对象。
*/
private static CopyOnWriteArrayList<ProductWebSocket> webSocketSet = new CopyOnWriteArrayList<>();
/**
* 与某个客户端的链接会话,需要通过它来给客户发送数据
*/
private Session session;
/**
* 链接建立成功调用的方法
*/
@OnOpen
public void onOpen(@PathParam("userId") String userId, Session session) {
log.info("开始爬虫进程,请稍后");
this.session = session;
webSocketSet.add(this);
addOnlineCount();
if (userId != null) {
List<String> totalPushMsgs = new ArrayList<String>();
totalPushMsgs.add("爬虫启动成功--当前爬虫启动数量为: " + getOnlineCount());
if (!totalPushMsgs.isEmpty()) {
totalPushMsgs.forEach(this::sendMessage);
}
}
}
/**
* 连接关闭调用方法
*/
@OnClose
public void onClose() {
log.info("爬虫已关闭");
webSocketSet.remove(this);
subOnlineCount();
}
/**
* 收到客户端消息后调用的方法
*
* @param message 客户端发过来的消息
*/
@OnMessage
public void onMessage(String message) {
log.info("当前爬取的数据为: " + message);
}
/**
* 发生错误时调用
*/
@OnError
public void onError(Session session, Throwable error) {
log.info("websocket出现错误!");
error.printStackTrace();
}
public void sendMessage(String message) {
try {
this.session.getBasicRemote().sendText(message);
log.info("数据获取成功,数据为: " + message);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 多数据返回方法
*/
public static void sendInfo(String message) throws IOException {
for (ProductWebSocket productWebSocket : webSocketSet) {
productWebSocket.sendMessage(message);
}
}
public static synchronized int getOnlineCount() {
return ONLINE_COUNT.get();
}
/**
* 爬虫启动数量加一
*/
public static synchronized void addOnlineCount() {
ONLINE_COUNT.incrementAndGet();
}
/**
* 爬虫启动数减一
*/
public static synchronized void subOnlineCount() {
ONLINE_COUNT.decrementAndGet();
}
}
6、Web前端逻辑编写
1)MyWebController
/**
* @author 90934
* @date 2020/2/18 14:26
* @description 爬虫项目启动Web端页面逻辑
* @since 0.1.0
*/
@RestController
@ServerEndpoint("/websocket")
public class MyWebController {
private JobProcessor jobProcessor;
private InstitutionInfoService institutionInfoService;
private IExportExcelService iExportExcelService;
private InstitutionDomainService institutionDomainService;
private InstitutionTestService institutionTestService;
@Autowired
public void setInstitutionDomainService(InstitutionDomainService institutionDomainService) {
this.institutionDomainService = institutionDomainService;
}
@Autowired
public void setInstitutionTestService(InstitutionTestService institutionTestService) {
this.institutionTestService = institutionTestService;
}
@Autowired
public void setiExportExcelService(IExportExcelService iExportExcelService) {
this.iExportExcelService = iExportExcelService;
}
@Autowired
public void setInstitutionInfoService(InstitutionInfoService institutionInfoService) {
this.institutionInfoService = institutionInfoService;
}
@Autowired
public void setJobProcessor(JobProcessor jobProcessor) {
this.jobProcessor = jobProcessor;
}
@PostMapping("/crawler/run")
public void runCrawler() {
this.jobProcessor.start(jobProcessor);
}
@PostMapping("/exportExcelInfo")
public void exportExcelInfo(HttpServletRequest req, HttpServletResponse resp) throws Exception {
List<InstitutionInfo> list = this.institutionInfoService.findAll();
this.iExportExcelService.exportExcelWithDispose("institution_info", "机构基本信息" + UUID.randomUUID().toString(),
list, req, resp);
try {
ProductWebSocket.sendInfo("数据导出成功");
} catch (IOException e) {
e.printStackTrace();
}
}
@PostMapping("/exportExcelDomain")
public void exportExcelDomain(HttpServletRequest req, HttpServletResponse resp) throws Exception {
List<InstitutionDomain> list = this.institutionDomainService.findAll();
this.iExportExcelService.exportExcelWithDispose("institution_domain", "机构已正式公布的授权签字人及领域" + UUID.randomUUID().toString(),
list, req, resp);
try {
ProductWebSocket.sendInfo("数据导出成功");
} catch (IOException e) {
e.printStackTrace();
}
}
@PostMapping("/exportExcelTest")
public void exportExcelTest(HttpServletRequest req, HttpServletResponse resp) throws Exception {
List<InstitutionTest> list = this.institutionTestService.findAll();
this.iExportExcelService.exportExcelWithDispose("institution_test", "机构已正式公布的检验能力范围" + UUID.randomUUID().toString(),
list, req, resp);
try {
ProductWebSocket.sendInfo("数据导出成功");
} catch (IOException e) {
e.printStackTrace();
}
}
}
2)index.html
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="utf-8">
<title>爬虫启动页面title>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link href="css/bootstrap.min.css" rel="stylesheet">
<link href="css/bootstrap-responsive.min.css" rel="stylesheet">
<link href="css/site.css" rel="stylesheet">
head>
<body>
<div class="container">
<div class="spanCrawler">
<h1>
crawler Slate
h1>
<div class="well crawler-slate">
<p>You have not created any projects yet.p>
<button th:type="button" th:onclick="crawler()" class="btn btn-primary"><i
class="icon-plus icon-white">i> 开始你的爬虫
button>
<button th:type="button" th:onclick="exportExcelInfo()" class="btn btn-primary"><i
class="icon-plus icon-white">i> 导出机构基本信息
button>
<button th:type="button" th:onclick="exportExcelDomain()" class="btn btn-primary"><i
class="icon-plus icon-white">i> 导出签字人及领域
button>
<button th:type="button" th:onclick="exportExcelTest()" class="btn btn-primary"><i
class="icon-plus icon-white">i> 导出检验能力范围
button>
div>
<div class="well crawler-slate" style="overflow-y: scroll; height: 65%">
<table id="message" th:class="ridge">
table>
div>
div>
div>
div>
<script src="js/jquery.min.js">script>
<script src="js/bootstrap.min.js">script>
<script src="js/site.js">script>
body>
html>
3)js文件和css文件太过冗长,有选择的进行展示
let websocket = null;
//判断当前浏览器是否支持WebSocket
if ('WebSocket' in window) {
//连接WebSocket节点
websocket = new WebSocket("ws://localhost:8080/");
} else {
alert('Not support websocket')
}
//连接发生错误的回调方法
websocket.onerror = function () {
setMessageInnerHTML("爬虫通道连接失败");
};
//连接成功建立的回调方法
websocket.onopen = function (event) {
setMessageInnerHTML("爬虫通道链接成功");
}
//接收到消息的回调方法
websocket.onmessage = function (event) {
setMessageInnerHTML(event.data);
}
//连接关闭的回调方法
websocket.onclose = function () {
setMessageInnerHTML("爬虫通道已关闭");
}
//监听窗口关闭事件,当窗口关闭时,主动去关闭websocket连接,防止连接还没断开就关闭窗口,server端会抛异常。
window.onbeforeunload = function () {
websocket.close();
setMessageInnerHTML("爬虫通道已关闭");
}
//将消息显示在网页上
function setMessageInnerHTML(innerHTML) {
if (innerHTML.toString() === "爬虫采集已结束,请在数据库中进行查看,或导出为Excel格式进行查看!") {
alert(document.getElementById('message').innerHTML = "" + innerHTML + " ")
} else {
document.getElementById('message').innerHTML += "" + innerHTML + " ";
}
}
//开启爬虫
function crawler() {
$.ajax({
url: '/crawler/run',
type: 'post',
contentType: 'application/json;charset=utf-8',
success: function () {
console.log("爬取成功!")
},
error: function (error) {
console.log('接口不通' + error);
},
})
}
function exportExcelInfo() {
$.ajax({
url: '/exportExcelInfo',
type: 'post',
contentType: 'application/json;charset=utf-8',
success: function () {
console.log("导出数据成功")
},
error: function (error) {
console.log('接口不通' + error);
},
})
}
function exportExcelDomain() {
$.ajax({
url: '/exportExcelDomain',
type: 'post',
contentType: 'application/json;charset=utf-8',
success: function () {
console.log("导出数据成功")
},
error: function (error) {
console.log('接口不通' + error);
},
})
}
function exportExcelTest() {
$.ajax({
url: '/exportExcelTest',
type: 'post',
contentType: 'application/json;charset=utf-8',
success: function () {
console.log("导出数据成功")
},
error: function (error) {
console.log('接口不通' + error);
},
})
}
table.ridge {
text-align: center;
display: block ruby
}
td.dashed {
border-style: dashed;
}
7、SpringBoot整合项目启动类
1)SpringBoot项目的入口
/**
* @author 90934
*/
@SpringBootApplication
@MapperScan(basePackages = {"com.hellof.crawler.mapper"})
public class CrawlerApplication {
public static void main(String[] args) {
SpringApplication.run(CrawlerApplication.class, args);
}
}
2)application.properties配置文件
#DB Configuration:
spring.datasource.driverClassName=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/jigou_data?useUnicode=true&characterEncoding=utf8&rewriteBatchedStatements=true&useSSL=false&serverTimezone=UTC&allowPublicKeyRetrieval=true
spring.datasource.username=root
spring.datasource.password=123456
#JPA Configuration:
spring.jpa.database=MySQL
spring.jpa.show-sql=true
3)logback-spring.xml配置文件
<configuration scan="false" scanPeriod="60 seconds" debug="false">
<property name="LOG_HOME" value="/hellof/log" />
<property name="appName" value="hellof-springboot"/>
<appender name="stdout" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%npattern>
layout>
appender>
<appender name="appLogAppender" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_HOME}/${appName}.logfile>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/${appName}-%d{yyyy-MM-dd}-%i.logfileNamePattern>
<MaxHistory>365MaxHistory>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MBmaxFileSize>
timeBasedFileNamingAndTriggeringPolicy>
rollingPolicy>
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [ %thread ] - [ %-5level ] [ %logger{50} : %line ] - %msg%npattern>
layout>
appender>
<logger name="com.hellof.crawler" level="debug" />
<logger name="org.springframework" level="debug" additivity="false"/>
<root level="info">
<appender-ref ref="stdout" />
<appender-ref ref="appLogAppender" />
root>
configuration>
4)pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.2.5.RELEASEversion>
<relativePath/>
parent>
<groupId>com.hellofgroupId>
<artifactId>crawlerartifactId>
<version>0.0.1-SNAPSHOTversion>
<name>crawlername>
<description>Demo project for Spring Bootdescription>
<properties>
<java.version>1.8java.version>
properties>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.mybatis.spring.bootgroupId>
<artifactId>mybatis-spring-boot-starterartifactId>
<version>2.1.1version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-loggingartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-thymeleafartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-websocketartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-jpaartifactId>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<scope>runtimescope>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.seleniumhq.seleniumgroupId>
<artifactId>selenium-javaartifactId>
<version>3.141.59version>
dependency>
<dependency>
<groupId>us.codecraftgroupId>
<artifactId>webmagic-coreartifactId>
<version>0.7.3version>
<exclusions>
<exclusion>
<artifactId>log4jartifactId>
<groupId>log4jgroupId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>us.codecraftgroupId>
<artifactId>webmagic-extensionartifactId>
<version>0.7.3version>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-lang3artifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>net.sf.json-libgroupId>
<artifactId>json-libartifactId>
<version>2.4version>
<classifier>jdk15classifier>
dependency>
<dependency>
<groupId>cn.afterturngroupId>
<artifactId>easypoi-baseartifactId>
<version>4.1.3version>
<exclusions>
<exclusion>
<artifactId>guavaartifactId>
<groupId>com.google.guavagroupId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>cn.afterturngroupId>
<artifactId>easypoi-webartifactId>
<version>4.1.3version>
dependency>
<dependency>
<groupId>cn.afterturngroupId>
<artifactId>easypoi-annotationartifactId>
<version>4.1.3version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poiartifactId>
<version>4.1.2version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poi-ooxmlartifactId>
<version>4.1.2version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poi-ooxml-schemasartifactId>
<version>4.1.2version>
dependency>
<dependency>
<groupId>commons-fileuploadgroupId>
<artifactId>commons-fileuploadartifactId>
<version>1.4version>
dependency>
<dependency>
<groupId>commons-iogroupId>
<artifactId>commons-ioartifactId>
<version>2.6version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
<exclusions>
<exclusion>
<groupId>org.junit.vintagegroupId>
<artifactId>junit-vintage-engineartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.xmlunitgroupId>
<artifactId>xmlunit-coreartifactId>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
build>
project>
8、项目运行结果展示
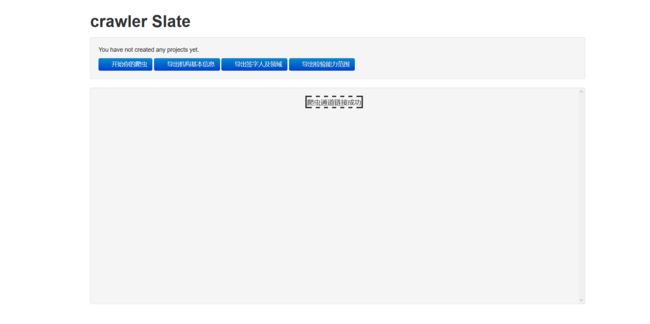
1)项目首页

2)开始爬虫
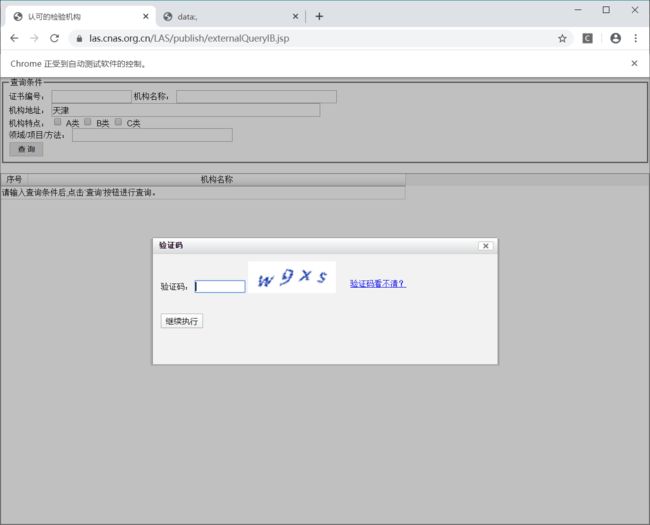
本项目中的爬虫因为网页采用的异步加载的初始信息,所以使用的是selenium进行页面的渲染,并且有着验证码阻碍爬虫的进行,考虑的短时间内的效率问题,所以没有使用机器识别,需人工手动输入验证码内容以获取初始信息。
-
人工验证获得初始链接
-
提示爬虫完成进度
-
可将爬取到的数据进行导出处理,导出格式为Excel文件
-
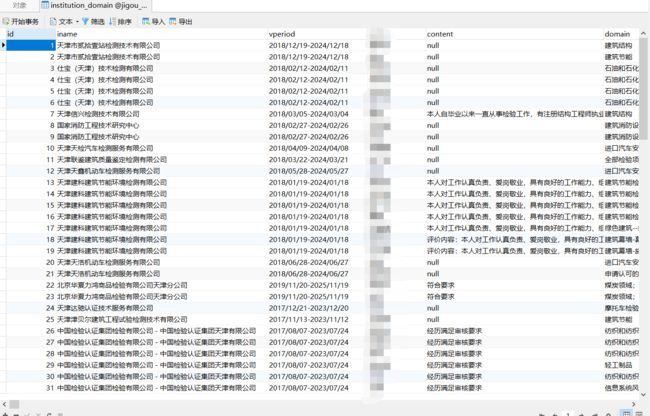
打开数据库进行查看爬取的信息
-
打开Excel文件查看导出数据


3)项目运行时可能出现的问题
- 问题:当爬取速度过快或数据过多的是啥web页面可能会崩溃
- 解决办法:刷新页面即可,爬虫进程并不会影响
- 如果需要更换爬虫网址,只需要模仿JobProcess类重新编写爬虫逻辑、或者直接修改Jobprocess类即可
- 当更换爬虫网址的时候除:websocket、util、mapper、io、export这五个包中的方法和SpringBoot启动类不需要更改以外,其他包中的类都需要进行相应的修改。
项目源代码地址:https://github.com/masonsxu/Crawler-Job-JiGou