闲谈IPv6-源IP地址的选择(RFC3484读后感)
杭州数月的连续淅淅沥沥的雨,让我感到舒适,但却不知湿了多少人的皮鞋?…
回想起2014年的一个周末从上海来杭州,我在思考一个关于IPv6的问题,但一切却不是因为IPv6而起。
缘起
在多年以前,我被一个看似很简单的问题困扰了很久很久。问题是这样的。
在Windows机器上,创建一条基于Tap虚拟网卡的隧道,并且为该虚拟网卡配置一个IP地址,比方说是10.0.1.20/24,同时将感兴趣的流量全部 通过路由的方式 导入到该Tap虚拟网卡,此外该Windows机器上安装的物理网卡的IP地址为192.168.1.20/24。
现在有一个App发起一条 感兴趣连接 ,所谓感兴趣连接就是走隧道的连接。那么请问 该连接上的数据包的源IP地址是什么?是虚拟网卡上的10.0.1.20还是物理网卡上的192.168.1.20?
答案是简单且明确的, 是虚拟网卡上的10.0.1.20!
为什么?因为数据包的源IP地址是基于路由来选择的,除非你显式bind一个特定的IP地址,否则Windows内置的TCP/IP协议栈将会 基于最长前缀匹配算法为你选择一个路由结果指示的出口网卡上配置的IP地址!
在大多数情况下,选择虚拟网卡上的IP作为数据包的源IP地址并不影响正常的通信,只要各个路径的路由是连通可达的,但是…
但是,我们知道,虚拟网卡上的IP地址10.0.1.20可能就是为了建立隧道而被配置的,它并不是专门用于通信的,10.0.1.X/24(或者更加普遍的用法,用/30前缀)的地址仅仅在隧道的两个端点可见。这意味着,如果目标地址不是隧道的另一端,那么便需要在数据包走出另一端隧道的时候,做源地址转换,将其转换成专门的通信地址。
而NAT是会带来很多问题的,为了解决这些问题,我不得不在炎热的夏日夜晚或者寒冷的冬夜写一个无状态的NAT转换器,解决了一个又一个关于NAT,nf_conntrack的问题…幸好隧道的另一端是Linux系统,能让我尽情折腾…
那是2012年到2014年的那段时间,简直是受够了!!
那段故事,请参阅下面的链接:
Windows配置路由时可以指定源地址啦: https://blog.csdn.net/dog250/article/details/10044433
彻底征服Windows上OpenVPN客户端的源地址选择问题: https://yq.aliyun.com/articles/493914
在Linux上实现一个可用的stateless双向静态NAT模块: https://blog.csdn.net/dog250/article/details/42046867
一个可以直接使用的可用iptables配置的stateless NAT实现: https://blog.csdn.net/dog250/article/details/42196919
static stateless 2-way NAT on Linux with iptables的应用实例: https://blog.csdn.net/dog250/article/details/42360579
IPv6带来了福音!
RFC3484简介
IPv6制定了非常严格的 源地址/目标地址选择的机制和策略, 并且这个过程还是可以从外部控制的!这简直太棒了!
参见RFC3484:https://www.ietf.org/rfc/rfc3484.txt
具体来讲,在尚未确定源IPv6地址的时候,给出一台机器上不同网卡上配置的所有IPv6地址,作为一个集合,遵循 RFC3484给出的8干条Rule 最终将会确定一个唯一的一个最优IP地址作为通信的源IP地址。
这8条Rule 依次顺序匹配, 每一条Rule简单来讲都是一个比较排序规则,它将一些候选的IPv6地址排在另一些候选IPv6地址之前或者之后,排在后面的地址将再没有机会被选中而被淘汰。
换句话说,只有在一条Rule没有确定唯一的优胜者时,后面的Rule才会起作用。很显然,这是一个逐步细化的不同维度的排序过程,如果前一条Rule选择了多个优胜者,将会进行下一条Rule规定的竞选。
这8条Rule分别是:
- Rule 1: 优选与目标地址相同的地址
- Rule 2: 优选其scope与目标地址scope相比更接近且scope更大的地址
- Rule 3: 优选"preferred" 地址
- Rule 4: 优选home地址
- Rule 5: 优选和路由出口在同一块网卡上配置的地址
- Rule 6: 优选Label匹配的地址
- Rule 7: 优选非临时/临时地址(可配置)
- Rule 8: 优选和目标地址最长前缀匹配的地址
这里主要说说Rule 2,Rule 6以及Rule7。
我们先看什么是scope。
感谢IPv6在设计时就对地址 按照其作用域范围(scope) 进行了 分类,比如:
- fe80::/10 链路本地地址,不能出三层设备,只能用于本二层链路
- fec0::/10 站点本地地址,废弃
- fc00::/7 ULA地址,不能在公网路由,但可用于私有网络,自己把握
- 2002::/16 IPv6/v4兼容地址
- 2001::/32 IPv6/v4兼容地址
- 全球全局地址
这些作用域,比如说链路本地,站点本地,全局等等,在标准上就限制了这些地址能被路由的范围,如果一台公网路由器的协议栈是严格按照标准实现的,那么当它发现类似fc00::/7这种地址的时候,就应该将其丢弃,另外,路由器也不能转发fe80::/10这种链路本地地址,这相比IPv4 只要有路由就能通,一切靠路由 要严格太多了,这种严格大大减轻了配置管理员的负担!
所以说,scope其实就是一个 硬约束,两个地址如果要通信,其socpe越接近,其 在物理上就越接近,与此相对,还有一个 软约束, 即最长前缀匹配度,两个地址的最长前缀越匹配,表明二者 在拓扑上越接近。
Rule 2有两层意思:
- 优选更大scope
这是因为越大的scope,其可达性范围越广。这保证了源和目标通信节点的连通性。 - 优选与目标地址的scope更接近的scope
这是因为,如果源和目标在scope约束下能通信,那么scope越接近,它们在物理上就越接近!
注意,二者是相与的关系。在Rule 2之上,依然存在着scope作用范围的硬约束。
IPv4没有这个scope的概念,但是在很多操作系统协议栈中,它依然被 模拟 了出来,比如对于Linux内核而言,它就将127.0/8以及169.254这种DHCP失败的地址视为了本机scope地址,本地链路scope地址,意思是说它们已经被限制住了范围,此外,关于路由scope也是一样,Linux内核将链路层自己发现的路由,其scope定为link范围,而非自动发现的路由,其scope则是global。
接下来我们看看Rule 6。
IPv6允许为每一个IPv6地址配置一个元组映射: M : { 地 址 前 缀 , 优 先 级 , L a b e l } M:\{地址前缀,优先级,Label\} M:{地址前缀,优先级,Label} 该元组映射作为系统的一张策略表存在,用于选择源IP地址或者目标IP地址。
如果Rule 1~Rule 5均没有选择出优选IP地址,也就是说多个幸存者IP无法决胜负,成了平局,那么在从剩余的幸存者候选IP地址中选择的时候,执行以下序列:
- 用目标IP在M中的“地址前缀”字段执行最长前缀匹配算法;
- 根据1的结果,获取一个元组 m 1 : ( P 1 , P r i o r 1 , L 1 ) m_1:(P_1,Prior_1,L1) m1:(P1,Prior1,L1)
- 针对每一个候选的源IPv6地址 A n A_n An执行1,获取元组 m n : ( P n , P r i o r n , L n ) mn:(P_n,Prior_n,L_n) mn:(Pn,Priorn,Ln)
- 如果 L n = L 1 L_n= L_1 Ln=L1,那么就优选 A n A_n An
- 对于多条 L n = L 1 L_n= L_1 Ln=L1,选择优先级 P r i o r n Prior_n Priorn最高的 A n A_n An
很有意思吧,是的。
我们在Linux上可以直接通过iproute2导出系统默认的这个 M M M映射:
# ip addrl show
prefix ::1/128 label 0
prefix ::/96 label 3
prefix ::ffff:0.0.0.0/96 label 4
prefix 2001::/32 label 6
prefix 2001:10::/28 label 7
prefix 3ffe::/16 label 12
prefix 2002::/16 label 2
prefix fec0::/10 label 11
prefix fc00::/7 label 5
prefix ::/0 label 1
如果我们man一下ip-addrlabel,就知道,这个表其实是可以配置的。
再简单说下Rule 7。
在IPv6中,有一种生命周期有限的地址,称作 临时地址。 临时地址一般用于私密通信,用完即丢。
从底层协议角度来讲,临时地址并不稳定存在,基于此,它作为次优选择会更妥当,但是另一方面,从业务的角度来讲,之所以配置这种临时地址,那么它本来就是要被使用,不然呢?要它干嘛!所以说,临时地址又是一个优选地址。
到底谁对谁错呢?没有对错!由用户自己来决定好了,所以可以从外部来配置说 临时地址到底是优选的,还是不建议的次优选择。
解题
回到本文开头的那个让我恶心了好几年的故事,如果现在让我用IPv6跑同样的程序,问题迎刃而解!
且慢,即便是在当时,我如果使用Linux的话,不是还是可以用ip route add命令加上src参数来明确源IP地址的吗?出问题的是Windows啊啊啊!
是的,出问题的是Windows,但是和IPv4的标准路由不同,由于ip label是IPv6的RFC标准建议,所以大多数操作系统均支持了它,Windows也不例外!
在netsh上下文中,可以看到类似的东西:
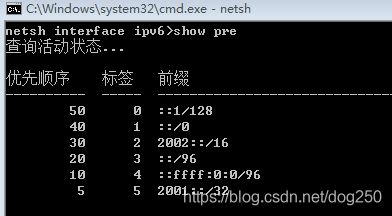
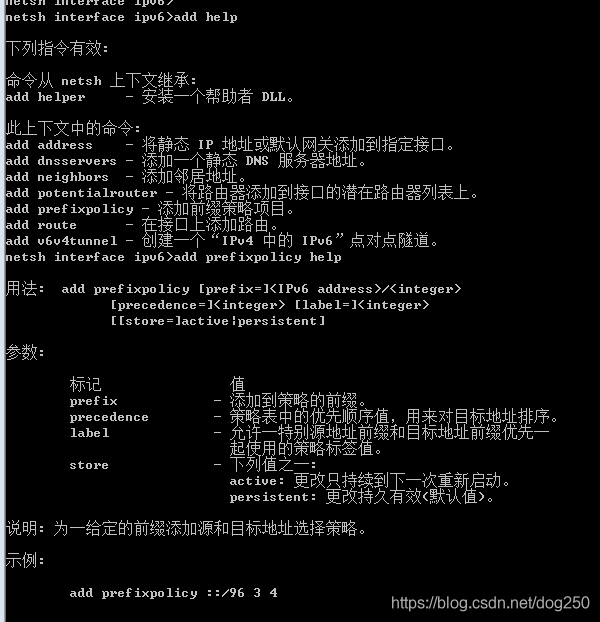
至于说怎么配置,简单了!一路help即可:
好了,现在回到那个悲哀的故事,如果用IPv6,我应该怎么配置感兴趣流量的源IP地址不选择虚拟网卡IP,而选择物理网卡呢?
假设目标IPv6地址是一个全球全局地址,而虚拟网卡上是一个本地链路地址,那么根据Rule 2就可以淘汰掉虚拟网卡上的地址,但是如果虚拟网卡上的地址也是一个全球全局地址呢?
我们知道在Rule 6之前先要执行Rule 5,而Rule将会选择虚拟网卡上的全局地址,根本没有机会执行Rule 6让你折腾这个Label表,那怎么办?
别忘了还有Rule 3呢!哈哈!
问题是,我们在Linux上废弃一个地址非常容易,执行下面的语句就可以了:
ip addr change $IPv6_addr_to_deprecated dev tun preferred_lft 0
但是,Windows上怎么办呢?不会又是一个Linux上很容易,而Windows上完全做不到的事情吧。
我就不信Windows不按标准实现IPv6。仔细看看netsh,还真有类似的配置,且看:
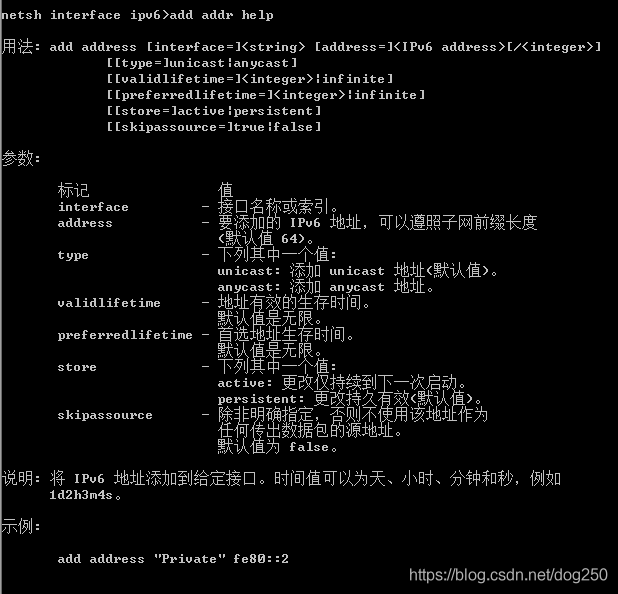
哈哈,不错!
这样,将虚拟网卡上的IP地址给废弃掉,接下来我们就可以常规化使用Rule 6来把玩Lable table了!
具体怎么玩呢?很简单。配置如下一条规则即可:
ip addrlabel add prefix $目标地址 label 123
ip addrlabel add prefix $物理网卡地址 label 123
翻译至Windows上等价配置即可!
RFC3484可以说是用一种常规的方法,去除了我的一块心病,为了解决这个问题,我想了无数个Trick,但事后看来都是奇技淫巧,同时我也要感谢这个问题,让我学了很多东西。
说点形而上的
看完了具体的描述,我总是要写两句形而上的东西。
我们想象一下, 为什么IPv6要有如此复杂且具体的源IP地址/目标IP地址选择机制,为什么IPv4没有这样的机制?这是为什么?
似乎我们从IPv4说起问题会变得简单。IPv4太平(so flat!)太自由太没约束了!
我在2010年和2017年分别写了两篇文章:
关于IP网段间互访的问题—路由是根本: https://blog.csdn.net/dog250/article/details/5303291
两台不同网段的PC直连是否可以相互ping通: https://blog.csdn.net/dog250/article/details/68951615
都是在说一个意思,即 只有有路由,就能互通!
是的,IPv4就是这么运作的! 在IPv4中,任意地址都可以通往世界的任何地方。 确实如此,即便是127.0.0.1这样的地址,在高版本的内核中,也可以被NAT了!就更别提什么192.168这种地址了。只要没有外部ACL把这种地址 挡在内部 ,没有什么内部机制阻止其漂洋过海。
IPv4完全是基于最长前缀匹配来选择使用哪个IP地址作为源,具体目标IP地址 在拓扑上距离更近。 IPv4在默认 “路由是聚合的” 这个前提的基础上得到了 最长前缀匹配出来的结果拓扑上距离更近 的结果。
基于此一厢情愿,一开始并没有什么私有地址,没有什么规定10.0.0.1,192.168这种不能被公网路由,10.0/8就是一个普通的A类段。
但事实上,并非如此。IPv4的地址分配非常混乱!
于是才有了这种所谓 私有地址 的划分。 私有 属性并不是IPv4的内在属性。
IPv6整洁了地址规划的过程,让路由内在地就是可汇聚的,正如IPv4最初的五类分类地址时代一样,天生就是路由强制汇聚的。但是为了达到这种效果,就必须将地址的用途进行强制化,比如说 为了防止地址a被从一个大的汇聚块A里抠出来而被用于链路层通信,就需要规定类似“链路层通信必须用xxx等地址”等约束 。
你不让人家乱用IP地址,你就得告诉人家什么时候用什么。
IPv6也和IPv4最初一样,对地址进行了分类划分,只不过分类更加复杂和精细化。IPv4最初的分类只是为了地址的分配(A类地址数量巨多,B类中等,C类偏少…),IPv6的分类则是根据地址的scope等属性进行分类的,这是本质的不同。
于是乎比方说fe80::/10就出来了,专门用于链路层通信,这是IPv6一开始就这么规定的。对比IPv4,169.254这种地址是后来才被规定的,而且还不是强制规定,感觉像是随便拍脑袋拍了一个地址。
IPv6地址被分类了,也就不再被管理员完全掌控和解释了。对比IPv4地址,那可是管理员想怎么配置就怎么配置,想怎么解释就怎么解释的。只要你有路由,169.254照样可以出去。
管理员不再可以控制地址用法的解释权,内在机制就要把某些以前管理员做的事情,帮其完成。比如如何选择通信时的源IP地址,比如如何选择DNS返回来的多个IPv4,IPv6混杂在一起的地址作为目标IP地址。这就有了这个RFC3484,专门来指示在通信的时候,如何来选择用哪个IP地址。注意,这个是RFC,不是让配置管理员看着做的,而是让操作系统协议栈实现时照着实现的。
嗯,这是最简单的为人处事的方法,省去了管理员学习很多东西。确实,机器在某些方面更不容易犯错,它们会做得更好,要让人学会理智,真的太难。
如果让管理员自己配置而不加以协议栈层面的约束,那么不专业的管理员很有可能会配置一个fe80的地址,期望它做全局通信,岂不乱套…
形而上地总结一下IPv4和IPv6:
- IPv4:无法一眼从地址上看出其scope,地址的解释权在配置管理员那里。
- IPv6:特定地址块有着严格的scope,地址的解释权在协议栈。
我们实际地看一个例子。
对于IPv4,当我为我的网卡enp0s3和enp0s8配置好并激活时,iproute2的地址展示结果如下:
[root@localhost ~]# ip addr ls
1: lo: <LOOPBACK> mtu 65536 qdisc noqueue state DOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 08:00:27:c8:4a:ad brd ff:ff:ff:ff:ff:ff
inet 10.0.2.15/24 brd 10.0.2.255 scope global noprefixroute dynamic enp0s3
valid_lft 84416sec preferred_lft 84416sec
inet6 fe80::647a:59b:f3ac:82e4/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: enp0s8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 08:00:27:ff:26:e6 brd ff:ff:ff:ff:ff:ff
inet 192.168.56.101/24 brd 192.168.56.255 scope global noprefixroute dynamic enp0s8
valid_lft 1023sec preferred_lft 1023sec
inet6 fe80::fbb2:a1e:e59:15eb/64 scope link noprefixroute
valid_lft forever preferred_lft forever
这时,我们可以看到两块网卡都自动生成了一个fe80的地址,这个时候看看IPv4的路由:
[root@localhost ~]# ip route ls
default via 10.0.2.2 dev enp0s3 proto dhcp metric 101
10.0.2.0/24 dev enp0s3 proto kernel scope link src 10.0.2.15 metric 101
192.168.56.0/24 dev enp0s8 proto kernel scope link src 192.168.56.101 metric 100
可以看到协议栈自动生成了两条 链路层路由,很显然,这些路由所关联的IP地址就是你配置在网卡上的IP地址。
我们再看看IPv6的路由:
[root@localhost ~]# ip -6 route ls
fe80::/64 dev enp0s8 proto kernel metric 256
fe80::/64 dev enp0s3 proto kernel metric 256
懵了吧…按照IPv4的理解方式,这明显是路由冲突了!但是对于IPv6而言,却不是这样。IPv6明确规定fe80的地址仅仅针对链路有效,不能跨网卡,不能跨路由器通信,所以说,如果你想用上述两条路由中的任意一条,你就必须指定网卡:
ping6 fe80::xxyy%网卡ID
还记得我之前总扯的那些关于IPv4的Trick吗?其实内核协议栈本身关于IPv4就有Trick,比如 和直连主机的非直连网卡通信 ,这就涉及到了ARP如何去获取一个 IP地址没有配置在本网卡上的网卡MAC地址 ,还记得怎么解吗?
答案就是配置系统参数:
net.ipv4.conf.all.arp_ignore
net.ipv4.conf.all.arp_filter
...
多年来,我帮助无数人解决过无数个类似的问题…
IPv6来了,这些Trick都不复存在,甚至ARP也被统一到ICMPv6里面了,如何连通主机,看懂RFC3484即可!
关于实现
看Linux内核的源码,以选择源地址为例,整个地址选择浓缩在了 ipv6_dev_get_saddr 函数中,简单看了一下,该函数其实就是对机器上所有的地址进行了一个冒泡排序而已。排序的规则就是从Rule 1到Rule 8,遍历两层嵌套,外层是遍历设备,内层是遍历每一个设备的所有IPv6地址。
为了说明上面形而上的一个细节,注意一个代码段:
for_each_netdev_rcu(net, dev) {
struct inet6_dev *idev;
/* Candidate Source Address (section 4)
* - multicast and link-local destination address,
* the set of candidate source address MUST only
* include addresses assigned to interfaces
* belonging to the same link as the outgoing
* interface.
* (- For site-local destination addresses, the
* set of candidate source addresses MUST only
* include addresses assigned to interfaces
* belonging to the same site as the outgoing
* interface.)
*/
if (((dst_type & IPV6_ADDR_MULTICAST) ||
// 如果是链路本地地址,不允许跨网卡!
dst.scope <= IPV6_ADDR_SCOPE_LINKLOCAL) &&
dst.ifindex && dev->ifindex != dst.ifindex)
continue;
...
}
这段代码说明了,内核协议栈的实现,直接限制了 地址不能乱用,完全遵循scope的规定!
例子
理解RFC3484最好的方法不是使劲读文档,也不是思考,最好的方式就是直接去读RFC3484后面的实例,这些实例非常好。
我这里摘录几个:
10.1. Default Source Address Selection
The source address selection rules, in conjunction with the default
policy table, produce the following behavior:
Destination: 2001::1
Candidate Source Addresses: 3ffe::1 or fe80::1
Result: 3ffe::1 (prefer appropriate scope)
Destination: 2001::1
Candidate Source Addresses: fe80::1 or fec0::1
Result: fec0::1 (prefer appropriate scope)
Destination: fec0::1
Candidate Source Addresses: fe80::1 or 2001::1
Result: 2001::1 (prefer appropriate scope)
Destination: ff05::1
Candidate Source Addresses: fe80::1 or fec0::1 or 2001::1
Result: fec0::1 (prefer appropriate scope)
Destination: 2001::1
Candidate Source Addresses: 2001::1 (deprecated) or 2002::1
Result: 2001::1 (prefer same address)
Destination: fec0::1
Candidate Source Addresses: fec0::2 (deprecated) or 2001::1
Result: fec0::2 (prefer appropriate scope)
Destination: 2001::1
Candidate Source Addresses: 2001::2 or 3ffe::2
Result: 2001::2 (longest-matching-prefix)
…
10.2. Default Destination Address Selection
The destination address selection rules, in conjunction with the
default policy table and the source address selection rules, produce
the following behavior:
Candidate Source Addresses: 2001::2 or fe80::1 or 169.254.13.78
Destination Address List: 2001::1 or 131.107.65.121
Result: 2001::1 (src 2001::2) then 131.107.65.121 (src
169.254.13.78) (prefer matching scope)
Candidate Source Addresses: fe80::1 or 131.107.65.117
Destination Address List: 2001::1 or 131.107.65.121
Result: 131.107.65.121 (src 131.107.65.117) then 2001::1 (src
fe80::1) (prefer matching scope)
Candidate Source Addresses: 2001::2 or fe80::1 or 10.1.2.4
Destination Address List: 2001::1 or 10.1.2.3
Result: 2001::1 (src 2001::2) then 10.1.2.3 (src 10.1.2.4) (prefer
higher precedence)
特别妙的是最后一个完整实例,它告诉我们,原来IPv6可以仅仅捣鼓地址就能实现IPv4必须用ACL,NAT,Policy Routing等配置出来的效果:
10.5. Configuring a Multi-Homed Site
Consider a site A that has a business-critical relationship with
another site B. To support their business needs, the two sites have
contracted for service with a special high-performance ISP. This is
in addition to the normal Internet connection that both sites have
with different ISPs. The high-performance ISP is expensive and the
two sites wish to use it only for their business-critical traffic
with each other.
Each site has two global prefixes, one from the high-performance ISP
and one from their normal ISP. Site A has prefix 2001:aaaa:aaaa::/48
from the high-performance ISP and prefix 2007:0:aaaa::/48 from its
normal ISP. Site B has prefix 2001:bbbb:bbbb::/48 from the high-
performance ISP and prefix 2007:0:bbbb::/48 from its normal ISP. All
hosts in both sites register two addresses in the DNS.
The routing within both sites directs most traffic to the egress to
the normal ISP, but the routing directs traffic sent to the other
site’s 2001 prefix to the egress to the high-performance ISP. To
prevent unintended use of their high-performance ISP connection, the
two sites implement ingress filtering to discard traffic entering
from the high-performance ISP that is not from the other site.
The default policy table and address selection rules produce the
following behavior:
Candidate Source Addresses: 2001:aaaa:aaaa::a or 2007:0:aaaa::a or
fe80::a
Destination Address List: 2001:bbbb:bbbb::b or 2007:0:bbbb::b
Result: 2007:0:bbbb::b (src 2007:0:aaaa::a) then 2001:bbbb:bbbb::b
(src 2001:aaaa:aaaa::a) (longest matching prefix)
In other words, when a host in site A initiates a connection to a
host in site B, the traffic does not take advantage of their
connections to the high-performance ISP. This is not their desired
behavior.
Candidate Source Addresses: 2001:aaaa:aaaa::a or 2007:0:aaaa::a or
fe80::a
Destination Address List: 2001:cccc:cccc::c or 2006:cccc:cccc::c
Result: 2001:cccc:cccc::c (src 2001:aaaa:aaaa::a) then
2006:cccc:cccc::c (src 2007:0:aaaa::a) (longest matching prefix)
In other words, when a host in site A initiates a connection to a
host in some other site C, the reverse traffic may come back through
the high-performance ISP. Again, this is not their desired behavior.
This predicament demonstrates the limitations of the longest-
matching-prefix heuristic in multi-homed situations.
However, the administrators of sites A and B can achieve their
desired behavior via policy table configuration. For example, they
can use the following policy table:
Prefix Precedence Label
::1 50 0
2001:aaaa:aaaa::/48 45 5
2001:bbbb:bbbb::/48 45 5
::/0 40 1
2002::/16 30 2
::/96 20 3
::ffff:0:0/96 10 4
… 后面过程执行的解释,我就不再摘录,请自行思考,非常好玩。
后记
世界上迄今为止最大的飞机,A380停产了,貌似印证了一个道理, 枢纽到枢纽的战略行不通, 庇护制的NAT终将失败!那么怎么办?
当然是 点对点 咯!
相对A380较小的飞机可以完美胜任点对点的运输任务,这意味着 去枢纽化 进程势在必得!
嗯,IPv6也旨在点对点传输,在我看来,IPv4的NAT节点就是枢纽,扫掉它们!世界正在微型化…
领主的领主,毕竟,不是我的领主。
浙江温州皮鞋湿,下雨进水不会胖。