强化学习(RLAI)读书笔记第三章有限马尔科夫决策过程(finite MDP)
第三章 有限马尔科夫决策过程
有限马尔科夫决策过程(MDP)是关于评估型反馈的,就像多臂老虎机问题里一样,但是有是关联型的问题。MDP是一个经典的关于连续序列决策的模型,其中动作不仅影响当前的反馈,也会影响接下来的状态以及以后的反馈。因此MDP需要考虑延迟反馈和当前反馈与延迟反馈之间的交换。
MDP是强化学习问题的一个数学理想化模型,以此来精确地从理论上描述。这章将会介绍强化学习里的一些关键问题,比如反馈reward,值函数value function和Bellman方程。
3.1 The Agent-Environment Interface
MDPs是一个从交互中达成目标的强化学习问题的一个直接的框架。学习者和决策者叫做agent。agent进行交互的其它一切agent之外的东西都叫做环境。agent不断的选择动作,而环境也给出相应的反应,并且向agent表现出新的状态。环境同时也给出一个数值作为反馈。agent的目标就是通过选择不同的action来最大化这个反馈值。

具体地说,agent和环境在每个离散时间步骤进行交互,t=1,2,。。。 每个时间步骤tagent会接收到环境的当前状态![]() 并且在状态的基础上选择动作
并且在状态的基础上选择动作![]() 。每一个步骤之后,作为动作的一个结果,agent会接收到一个数值反馈
。每一个步骤之后,作为动作的一个结果,agent会接收到一个数值反馈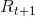 ,并且会发现自己进入一个新的状态里,
,并且会发现自己进入一个新的状态里, 。
。
在有限MDP中,状态动作和反馈值都只有有限个元素。在这种情况下反馈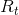 和状态
和状态 有一个只关于前一状态以及前一状态采取的动作的概率分布:
有一个只关于前一状态以及前一状态采取的动作的概率分布:![]() 。这个函数定义出了MDP的动态变化。这个函数对于状态和反馈值求和之后得到1。函数代表的是,下一个状态和反馈仅仅依赖于前一状态和前一状态的动作,而不是前面所有的状态以及动作。状态必须包含一切过往agent和环境交互的所有信息。这种状态叫做有马尔科夫性质。
。这个函数定义出了MDP的动态变化。这个函数对于状态和反馈值求和之后得到1。函数代表的是,下一个状态和反馈仅仅依赖于前一状态和前一状态的动作,而不是前面所有的状态以及动作。状态必须包含一切过往agent和环境交互的所有信息。这种状态叫做有马尔科夫性质。
概率分布函数p可以计算出关于环境的所有概率,比如状态转移概率:
![]()
同样也可以计算出每个状态动作对的反馈期望:
![]()
其中第一个四个参数的概率分布是我们最常使用的。
MDP框架是一个非常抽象而灵活的应用框架,可以通过不同方式用到不同问题上。比如,时间步骤不一定非得是固定间隔的,可以使任意需要作出决策的连续序列。动作可以使低层次的控制比如电压控制,也可以是高层次的决策比如去哪里吃饭。同样状态也可以是各种表现形式,动作也是一样。
需要注意的是,agent和环境之间的界限不是一成不变的。一般来说这个界限靠的离agent更近一些,可能与物理上机器人的界限不太一样。比如传感器和电机控制部分可以被认为是环境的一部分而非agent。其中划分的准则是任何不能被agent随意改变的部分都属于环境。比如agent可能知道每次reward是如何被反馈来的,但是reward的计算部分被认为在agent之外,因为agent不能随意改变它。agent与环境的界限代表的是agent的绝对控制,而不是了解。
而且这个界限也可以根据不同的任务目标进行调整。在一个复杂的机器人里面可能有不同的agent在同时运行。
MDP框架是一个非常抽象的目标导向的框架。它致力于把任务中所有的信息都归约为在agent与环境之间来回传播的三个信号:一是代表agent做出的选择(action),二是代表做出选择的基础(state)以及定义了agent目标的信号(reward)。对于如何把问题中的各个方面抽象成这些信号是一个更偏工程的问题,我们目前先关注在这些问题定义好之后的算法。
练习3.1 空调的控制 下象棋 做饭的火候控制
练习3.2 天气预报,不仅需要关注今天还需要关注前几天。
练习3.3 根据目标来决定界限划分。
练习3.4 只需要把r那一列往前放到一起
3.2 Goals and Rewards
在强化学习中,agent的目标是通过一个特殊的信号,reward来进行描述的。不正式的说法是agent的目标是最大化它接收到的所有reward的和。也就是说目标不是最大化当前reward而是长期的累计reward。reward信号的使用是强化学习最重要的特征之一。尽管这种形式看起来限制很大,但是实际已经证明它很灵活且应用面很广。
如果我们想要agent完成某件事,那么一定要把reward定义为agent在完成目标时最大化。所以reward真正反映了任务的目的是一个很重要的事。另外reward不应该是教会agent如何完成目标的地方,reward信号是告诉agent想要完成什么而不是如何完成。因此类似于在下棋时给制造出一个陷阱很多reward是不对的。
3.3 Returns and Episodes
我们以及非正式的讨论过agent的目标是最大化累积reward。下面介绍这个累积reward的正式定义。大体的说我们寻求最大化反馈的期望值 ,被定义为反馈序列的某些特殊函数,其中最简单的定义是
,被定义为反馈序列的某些特殊函数,其中最简单的定义是
![]() ,
,
T表示的是最后一个时间步。这个定义对于那些能够自然分成一个个序列的任务很有意义,比如玩一局游戏或者走一个迷宫等等,每一次都是一个序列。那些有一个中止状态的任务被成为episodic tasks。另外有一些没法分开成一个个序列的任务比如一个机器人整个生命过程,也就是可以被认为时间步骤是无限的任务,叫做continuing tasks。对于这种任务直接把以后所有的reward相加会得到一个无穷值,也就没法最大化,因此期望值被定义为discounting的形式,即t+1以后每个reward都多加一个[0,1]之间的系数 ,即:
,即:
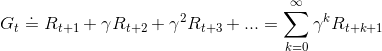 。
。
写为递推形式为![]() 。对于小于1的情况,如果反馈序列R是有限值,那么这个无限项相加的结果也是一个有限值。如果每次返回reward的是+1,那么最终
。对于小于1的情况,如果反馈序列R是有限值,那么这个无限项相加的结果也是一个有限值。如果每次返回reward的是+1,那么最终 。
。
练习3.5 把![]() 改为
改为![]()
练习3.6 未失败返回0,失败返回-1。 ![]() ,k是当前状态之后的步数。似乎没啥区别。
,k是当前状态之后的步数。似乎没啥区别。
练习3.7 没有办法找到出口。没有。
练习3.8 算一下
练习3.9 G1=20 G0=20
练习3.10 等比求和公式
3.4 Unified Notation for Episodic and Continuing Tasks
之前介绍了两种任务,一种有结束状态的episodic tasks,另一种是无限状态的continuing tasks。由于对于episodic tasks来说,每一个episode都是从头开始,而且属于哪一个episode并不会影响结果,因此一般忽略关于episode的下标。
为了让两种形式的任务的返回值能够写成统一的形式,我们把episodic tasks的结束状态当成一个特殊的无限循环状态,对于到达结束状态的任务,之后还会无限地返回结束状态并且返回reward为0。经过这样的设计,就能够把两种任务的反馈期望结合起来写为统一的形式:
 , 其中T可以是无穷,而可以等于1,但是这两个条件不能同时满足。
, 其中T可以是无穷,而可以等于1,但是这两个条件不能同时满足。
3.5 Policies and Value Functions
基本所有的强化学习算法都会评估值函数,也就是评估状态或者状态动作对中的agent是否更接近目标。更接近定义为未来反馈值的期望。而值函数是根据某种特殊的动作选择方式来定义的。这种选择动作的方式叫做策略(policy)。
正式的policy定义是指从状态到选择每个可选动作概率的映射。如果agent在时刻t时遵从policy  ,那么
,那么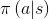 就是指当
就是指当![]() 时动作
时动作![]() 的概率。
的概率。
练习3.11 ![]()
在状态s时遵循策略的值函数 ,是从当前状态开始遵循策略之后的反馈值的期望。对于MDPs可以写成
,是从当前状态开始遵循策略之后的反馈值的期望。对于MDPs可以写成
![v_{\pi}(s) \doteq E_{\pi}[G_{t}|S_{t}=s] = E_{\pi} \left\{ \sum_{k=0}^{\infty}\gamma^{k}R_{t+k+1}|S_{t}=s \right\}](http://img.e-com-net.com/image/info8/912dc695a3384e1981ae5948bd5be551.gif) ,
,
其中![]() 是指当agent遵循策略是对随机值的期望。如果有结束状态,那么结束状态的值为0。
是指当agent遵循策略是对随机值的期望。如果有结束状态,那么结束状态的值为0。
同样的我们定义当遵循策略在状态s时采取了动作a的值 ,可以写成:
,可以写成:
![q_{\pi}(s,a)\doteq E_{\pi}[G_{t}|S_{t}=s, A_{t}=a] = E_{\pi}\left\[\sum_{k=0}^{\infty}\gamma^{k}R_{t+k+1}|S_{t}=a,A_{t}=a\right\]](http://img.e-com-net.com/image/info8/8f76358661a2470f89d32bcc1afdf459.gif) ,
,
叫做策略下的动作值函数。
练习3.12 ![]()
练习3.13 ![]()
可以从经验中评估这两个值函数。比如一个遵循策略的agent为遇到的每一个状态都保有一个平均反馈值,那么随着时间接近无穷大,那么这个平均值也会逐渐收敛到,对于也是一样的道理。这个方法叫做蒙特卡洛法因为使用了很多随机样本真实反馈值的平均。而对于有些问题,状态太多保持每个状态的值不太现实,这时候就使用参数化的函数来保持这两个值函数。
这两个值函数都可以写成递归的形式,叫做贝尔曼等式(Bellman equation)。对于v的递推等式如下:

这个过程可以使用一个图来表示:

在右图中从顶上的状态s开始可以在遵循策略下采取集合中的任何动作a。对于每个动作环境都会给出对应的不同反应,也就是转移到对应的状态分布p,并且根据转移到的状态s'会返回不同的值r。上述贝尔曼等式就是将不同的动作和对应的转移状态分布的反馈值进行求期望得到的。
对于右图我们叫做backup diagrams,因为这个图展示了值函数从后一个状态往前进行传递的过程。另外图中的状态不需要是不一样的,比如每个状态下一时间可能转移到这个状态本身。
练习3.14 0+1/4(2.3+0.4-0.4+0.7) = 0.7
练习3.15 ![]() 每个v都加了个
每个v都加了个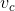 ,因此不会影响选取动作。
,因此不会影响选取动作。
练习3.16 不会有影响。当c大于0就会得到无穷大的反馈,如果c小于0,就会跟不加c一样。
练习3.17
练习3.18 ![]()
练习3.19 ![]()
3.6 Optimal Policies and Optimal Value Functions
解决一个强化学习问题也就是意味着找到一种选择动作的策略能够获得足够多的奖励反馈。对于fMDP来说是能够定义出一个最优策略的。在值函数之上定义一种策略的偏序关系,如果一个策略 的所有状态的值函数都大于策略,那么就说前一个策略更好。这样会有一个最优策略,尽管可能不止一个,我们只用
的所有状态的值函数都大于策略,那么就说前一个策略更好。这样会有一个最优策略,尽管可能不止一个,我们只用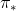 表示。
表示。
这些最优策略有相同的值函数,叫做最优状态值函数。这个函数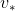 被定义为:
被定义为:
![]() 。
。
同样的也存在一个最优动作值函数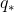 :
:
![]() 。
。
对于状态动作对(s,a)来说,这个动作值函数给出了在状态s时采用动作a之后遵循最优策略得到的期望反馈。
![]() 。
。
对于这两个值函数来说,他们必须满足上节讲到的bellman equation,但是对于最优值函数有独特的形式,如下:

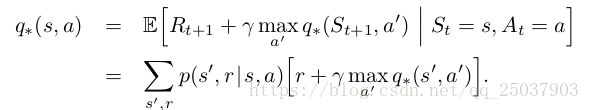
而对于最优的这两种情况也有对应的backup diagrams。表示v的图中在状态s时选择最优动作a之后得到反馈然后根据概率分布转移到下一个状态s'。而表示q的图中在状态s选择了动作q之后先根据概率分布转移到下一状态s',然后在状态s'再选择其最优动作a'。

对于有限状态MDP来说,最优贝尔曼方程中v是有一个不依赖于策略的唯一解的。最优贝尔曼方程实际上是一组等式,其中对n个状态有n个未知数以及n个方程,因此是可解的。只要知道了环境的状态转移概率分布p,就可以直接解出。对q也是一样。
如果有了最优值,那么很容易就会选到最优动作和最优策略。可以被看成是一步搜索,从当前状态搜索能够达到下一最优状态的动作是什么。这种策略也叫贪心算法。对于v来说最好的一点是使用贪心算法进行一步搜索最优动作,也就保证了长期的最优,因为值函数v本身就包含了未来动作的反馈期望。而有了最优q函数,我们选择下一步最优动作时无需考虑接下来的状态,而是可以直接选择动作。
直接解贝尔曼最优方程是解决问题的一种方案,但是这种方法很少直接应用。因为这样做需要进行很多搜索和观察所有的可能等等。这个方法需要三个假设:(1)我们准确知道环境的变化(状态转移概率分布);(2)我们有足够的计算资源直接计算;(3)马尔科夫性质。一般来说很难三个条件都达到。
但是有很多其他类型的决策性方法被看成是近似解决贝尔曼最优方程的方式,在接下来的章节会讲,比如启发式搜索,动态规划等等。
练习3.20 草地外是q(s,driver)的样子,草地上是v的样子。
练习3.21 直接是v的样子不变。
练习3.22 left right 都一样
练习3.23 太多了。
练习3.24 10+16.0*0.9 = 24.400
练习3.25 ![]()
练习3.26 ![]()
练习3.27 ![]()
练习3.28 ![]()
练习3.29 略
3.7 Optimality and Approximation
虽然我们已经定义出了最优值函数和最优策略,而且理论上也可以直接计算出来。但是通常情况下我们没法得到这么多的计算资源。与此同时内存溢出也是一个很大的问题,因为很多问题的状态数量太多超过存储范围。对于这些情况我们就不能够使用直接存储每个状态的值函数而是必须使用一种更精简的参数型函数表示的方法。
强化学习的框架迫使我们进行近似求解。而且这个框架同时也很容易进行近似,比如对于很多小概率出现的状态,选择最优解和次优解区别不大。而且强化学习的在线学习的特性让其能够方便地对出现比较多的状态进行更多关注。这是一个强化学习区分其它近似求解MDP的关键特点。
3.8 Summary
强化学习是关于学习如何与环境交互以达成目标的。强化学习的agent和环境在离散时间步骤上进行交互,它们之间的交互定义了一个特定的任务:agent的动作,做出动作的基础也就是状态,以及评估每次动作的反馈。agent内部是完全被agent掌控的,在agent之外的都是环境并且可以不完全了解。策略是指基于状态选择动作的一种随机规则。agent的目标是最大化所有时间接收到的reward的和。
上面定义的强化学习设定通过一个状态转移分布构成了马尔科夫决策过程。一个有限状态MDP是包含有限状态有限动作和有限reward集合的MDP。很多强化学习的理论局限于有限状态MDP,但是很多方法和想法不局限于此。
反馈值是agent想要最大化的未来奖励的函数(通过期望值的形式)。根据任务本身的特点和是否使用discounting有不同的定义。不使用discounting的方式适用于episodic tasks,另一种适用于continuing tasks。定义一个特殊状态可以让这两种形式使用同一个等式。
每个状态的值函数和动作值函数是基于动作或动作状态对的遵循该策略的未来反馈期望。最优值函数是所有策略中当前状态能够获得的最大反馈期望。取得最优值函数的策略叫做最优策略。贝尔曼最优等式是贝尔曼等式的一个特殊形式,可以得到最优值函数的解。根据最优值函数又能得到最优策略。
根据对整个环境的了解又把强化学习问题分为complete knowledge 和 incomplete knowledge两种。分类标准是agent是否建立起对环境变化的准确而完全的模型。
即使agent拥有完整而准确的环境模型,agent一般也没有足够的计算资源去利用它。内存也是一个很大的限制,因为很多问题中状态的数量远远超过能够合理存储的程度。尽管我们定义了一个最优方案来有利于对强化学习概念的理解,但是现实是很多时候只能对其进行不同程度的近似。强化学习更关注的是那些找不到最优解但是能够通过一些方式进行近似的例子。