Python数据分析之:pandas拓展数据分析函数(cum / rolling ) / 作图功能
文章目录
- 1. pandas拓展数据分析函数
- 1.1 .cum()
- 1.1.1 .cumsum():累加
- 1.1.2 .cumprod():累乘
- 1.1.3 .cummax():前n个数依次求最大值
- 1.1.4 .cummin():前n个数依次求最小值
- 1.2. pandas.rolling()
- 2. pandas 作图
1. pandas拓展数据分析函数
1.1 .cum()
因为 .cum 方法是针对 Series 和 Dataframe 结构处理的方法,所以调用的时候格式不是 pandas.cum,而是创建出来的 series 结构来调用 cum 方法:

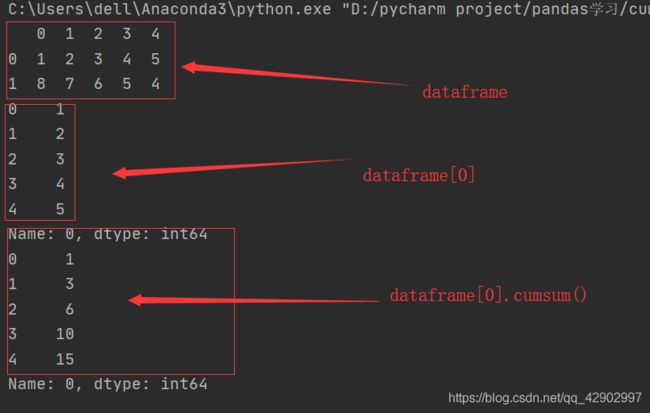
1.1.1 .cumsum():累加
完成累加的操作,从上往下的顺序,每次都计算前几个值的和。
import pandas as pd
series = pd.Series([1,2,3,4])
print(series)
out = series.cumsum()
print(out)

同样地,也可以建立一个 dataframe 的结构,然后从其中抽取出一个 series 结构进行计算,如下:
dataframe = pd.DataFrame([[1,2,3,4,5],[8,7,6,5,4]])
print(dataframe)
s1 = dataframe.loc[0]
print(s1)
x = s1.cumsum()
print(x)
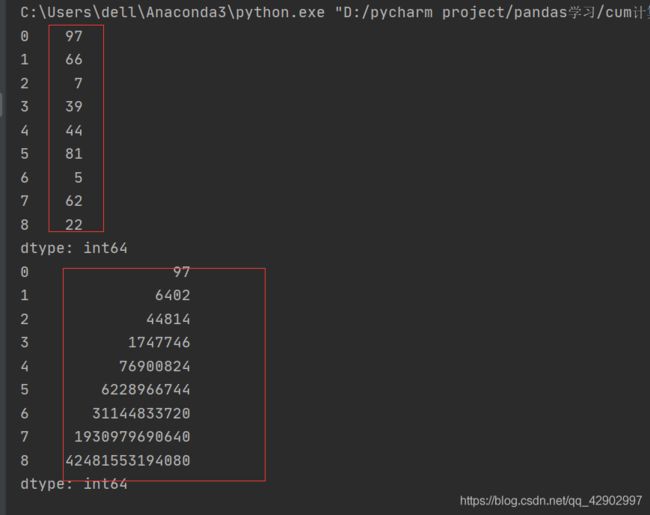
1.1.2 .cumprod():累乘
from random import random, randint
import pandas as pd
lst = []
for i in range(1,10):
lst.append(randint(1,100))
series = pd.Series(lst)
prod = series.cumprod()
print(series)
print(prod)
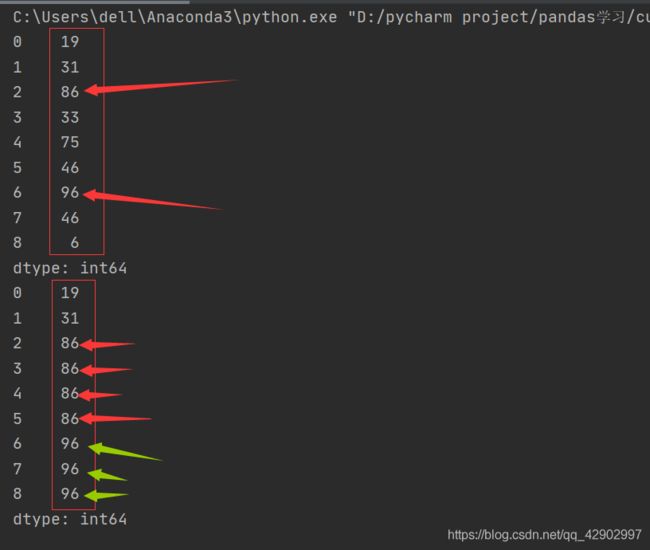
1.1.3 .cummax():前n个数依次求最大值
import pandas as pd
lst = []
for i in range(1,10):
lst.append(randint(1,100)) //先生成一个随机的长度为10的列表
series = pd.Series(lst) //用这个列表生成一个series结构
max = series.cummax() //依次求其前n个数的最大值
print(series)
print(max)
1.1.4 .cummin():前n个数依次求最小值
from random import random, randint
import pandas as pd
lst = []
for i in range(1,10):
lst.append(randint(1,100))
series = pd.Series(lst)
min = series.cummin()
print(series)
print(min)
1.2. pandas.rolling()
pandas.rolling 的对象是整个列表,所以他的使用格式是 pd.rolling_mean(D,k),意思是针对整个表,每 k 列计算一次均值,如果k=2就是相邻的两列.
- pandas.rolling_sum()
- pandas.rolling_mean()
- pandas.rolling_var()
- pandas.rolling_std()
- pandas.rolling_corr()
- pandas.rolling_cov()
- pandas.rolling_skew()
- pandas.rolling_kurt()
注意,在目前最新的pandas版本中,这种写法改了。如果原来的格式是:pd.rolling_mean(dataframe,k) 那么在新版本中统一改成了 dataframe.rolling(k).mean() 这种格式,因此所有的都要变成:
- dataframe.rolling(k).mean()
- dataframe.rolling(k).sum()
- dataframe.rolling(k).var()
- dataframe.rolling(k).std()
- dataframe.rolling(k).corr()
- dataframe.rolling(k).cov()
- dataframe.rolling(k).skew()
- dataframe.rolling(k).kurt()
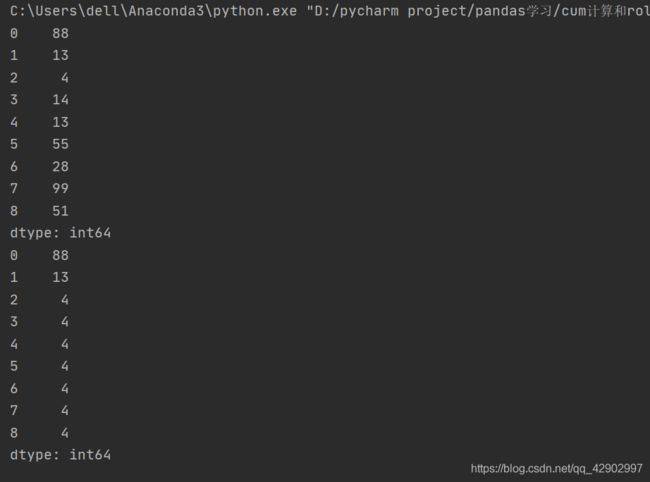
【rolling().sum 举例】
import pandas as pd
import numpy as np
data = np.random.randint(1,100,(6,5))
df = pd.DataFrame(data)
print(df)
x = df.rolling(2).sum() //相邻行求和
print(x)

2. pandas 作图
matplotlib 可以绘制的图的种类,pandas内置库中都包含,所以,如果得到了pandas 的 dataframe 类型的数据,其实可以直接作图:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = np.random.randint(1,100,(6,5))
df = pd.DataFrame(data)
print(df)
df.plot(kind='box')
plt.show()

但需要注意的是,用 dataframe.plot() 做出来的图需要用 plt.show() 显示出来。
但我个人觉得,还是用 matplotlib 专门负责作图比较好~~