pandas介绍——进阶操作(11)
这次部分的内容比较零碎,代码没有什么逻辑性,大部分都是为了展示pandas的各种技能操作
首先我们来新建一个
# 建立一个新的Series,并将index改成日期形式
# 利用pd.date_range()函数可以设置index的日期,起始日期以及日期长度
s=pd.Series([1,2,3,4,5,6],index=pd.date_range('20170102',periods=6))
s输出:
2017-01-02 1 2017-01-03 2 2017-01-04 3 2017-01-05 4 2017-01-06 5 2017-01-07 6 Freq: D, dtype: int64
简易读取index的内容
# 可以直接读取s的index
s.index输出:
DatetimeIndex(['2017-01-02', '2017-01-03', '2017-01-04', '2017-01-05',
'2017-01-06', '2017-01-07'],
dtype='datetime64[ns]', freq='D')
tolist函数也是我们会常用到的函数
# tolist()的作用是将array转化成列表list形式
np.random.randn(1,4).tolist()输出:
[[-1.7189628799092767, 0.7103794820527385, 0.45113746394159093, -0.04345089283022651]]
继续~
下面练习一下重命名index——Reindex
新建一个Series
s1=pd.Series(np.random.randn(1,4).tolist()[0],index=['A','B','C','D'])
s1输出:
A 0.351200 B 0.426345 C -0.479479 D 0.699487 dtype: float64
然后给index进行重新赋值,并且这一次我们多给几个index
# 给index重新赋值,多出来的默认为空值
s2=s1.reindex(['A','B','C','D','E','F'])
s2输出:
A 0.351200 B 0.426345 C -0.479479 D 0.699487 E NaN F NaN dtype: float64
我们看到,新的index ‘E’和‘F’的value都暂时是NaN。那么我们可以对现在为空值的EF进行赋值
s3=s1.reindex(['A','B','C','D','E','F'],fill_value=0)
s3这样空值的部分就被赋值为0
A 0.351200 B 0.426345 C -0.479479 D 0.699487 E 0.000000 F 0.000000 dtype: float64
继续~
再次新建一个DataFrame
df=pd.DataFrame(np.random.randn(4,4),index=['r1','r2','r3','r4'],columns=['c1','c2','c3','c4'])
df输出:
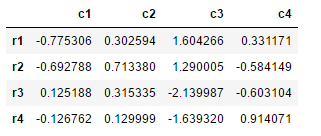
那么再次给它新的index
df.reindex(['r1','r2','r3','r6','r4','r5'])注意,这次‘r6’是插入在‘r4’'r5'之间的
输出:

可以看出,index 为 r4 的会按照之前的保留下来。
当然对column也是可以操作的
df.reindex(columns=['c1','c2','c3','c6','c4','c5'])输出:

Drop 数据的练习。Drop意思就是将数据去除。
和刚才一样,先从Series开始
s1=pd.Series(np.arange(5),index=[1,2,3,4,5])
s1输出:
1 0 2 1 3 2 4 3 5 4 dtype: int32
删除特定标号的index
# 将标号为4的这行删除
s1.drop(4)输出:
1 0 2 1 3 2 5 4 dtype: int32
再来是DataFrame
df=pd.DataFrame(np.random.randn(4,4),index=['r1','r2','r3','r4'],columns=['c1','c2','c3','c4'])
df输出:
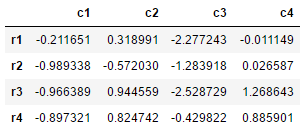
df.drop('r4')输出:
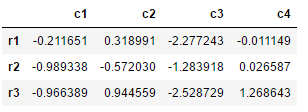
所以可以看到,drop函数可以很方便的将我们不需要的index删除。
当然也可以drop掉column
# 如果要drop列数的话,需要加入axis=1
df.drop('c3',axis=1)输出:
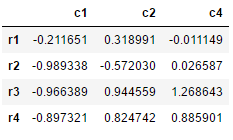
注意:此时显示的df虽然只剩下c1,c2,c4三个列,但是实际上df依然是4个列
df.drop('c3',axis=1) 只是显示出df这个DataFrame被drop掉C3后的样子,但是df并没有改变

下面介绍一下数据和数据之间的运算操作
还是先从Series开始
比如我现在有两个数据,两个数据的index的共有部分都存在ABC,那这两个数据是否可以进行运算呢?
s1=pd.Series(np.arange(5),index=['A','B','C','D','E'])
s1输出:
A 0 B 1 C 2 D 3 E 4 dtype: int32
s2=pd.Series(np.arange(3),index=['A','B','C'])
s2输出:
A 0 B 1 C 2 dtype: int32
现在s1和s2都含有相同的index (ABC),也有不同的index(DE),我们可以简单的进行运算
# 简单的相加的话,同样index的元素可以进行运算
s1+s2输出:
A 0.0 B 2.0 C 4.0 D NaN E NaN dtype: float64
可以看到,相同index的数据是可以被相加的。这也是pandas处理数据的优势。当index相同时,pandas默认为是可以被统一处理的数据。
再来试一下DataFrame
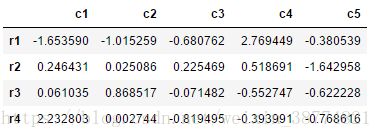
df1=pd.DataFrame(np.random.randn(4,5),index=['r1','r2','r3','r4'],columns=['c1','c2','c3','c4','c5'])
df1输出:
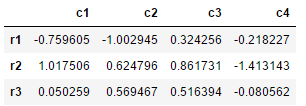
df2=pd.DataFrame(np.random.randn(3,4),index=['r1','r2','r3'],columns=['c1','c2','c3','c4'])
df2输出:
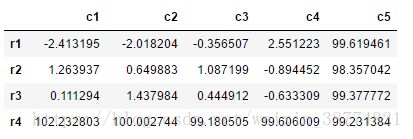
当然我还是可以相加,但这次df2的空值部分,我们让其默认值为100
# 将df1和df2相加,df2的空值部分填充为100
df1.add(df2,fill_value=100)输出:
最后介绍与复习一下排序功能
在之前提到过,可以用sort()函数来对数据进行排序
s1=pd.Series(np.arange(5),index=['B','D','C','A','E'])
s1输出:
B 0 D 1 C 2 A 3 E 4 dtype: int32
现在s1的index顺序是错的(当然是我们故意弄错的),我们现在来修正一下
# 可以对index进行排序
s1.sort_index()输出:
A 3 B 0 C 2 D 1 E 4 dtype: int32
当然也可以对value进行排序
# 可以对values进行排序
s1.sort_values()输出:
B 0 D 1 C 2 A 3 E 4 dtype: int32
最后介绍一下ascending()函数
# ascending 的意思为,是否按照从小到大排序
# 如果为false,则按照从大到小进行排序
s1.sort_values(ascending=False)输出:
E 4 A 3 C 2 D 1 B 0 dtype: int32
好啦,pandas大部分功能已经被我们实现过了~为了对数据进行分析,掌握numpy和pandas这样的包是非常有必要的
下一节将会继续介绍python三大数据分析包最后一个包,matplotlib。
谢谢~