hadoop核心------>HDFS原理
一 、hdfs体系架构
1.NameNode------>管理节点------>hdfs中老大
(1)维护着整个文件系统的文件目录树;
(2)维护元数据信息;
(3)接收用户的操作请求
2.DataNode------>提供真实文件数据的存储服务------>hdfs中小弟
将文件进行划分并编号,切分成n个Block,HDFS默认Block大小是128MB
3.Secondary NameNode(伪分布式,hadoop1.0用)------>保持文件系统最新的元数据------>hdfs中秘书
合并NameNode的edit logs到fsimage文件中
二 、元数据存储细节
元数据存储在内存中,举个例子,现在要存储一个文件a.log
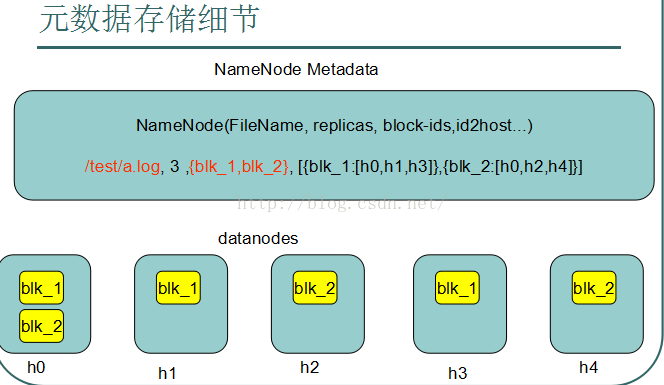
/test/a.log是一个要存储的文件,要存储3个副本(防止一个机器挂掉,文件丢失,所以需要副本),文件被切分成2块,叫做
blk_1和blk_2,blk1存放在h0,h1,h2三台机器上,blk2存放在h0,h2,h4三台机器上
三 、NameNode工作原理
1. 基本概念
fsimage:元数据镜像文件。存储某一时段NameNode内存元数据信息。
edits:操作日志文件。
fstime:保存最近一次checkpoint的时间
2.工作原理
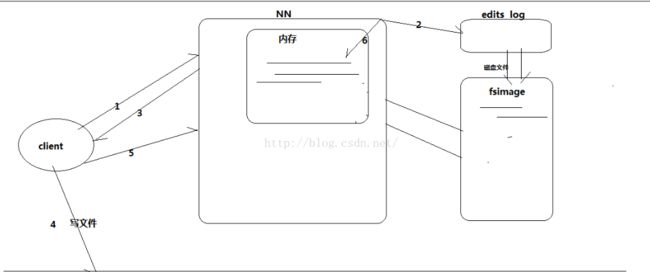
1.客户端Client向NameNode发出要写文件的请求,告诉NameNode我要开始写文件了
2.NameNode向edis log文件中记录元数据操作日志
3.NameNode返回信息给客户端Client,告诉客户端可以写文件操作了
4.客户端Client开始向DataNode中写数据
5.客户端Client通知NameNode写文件成功了
6.NameNode将新产生的元数据信息更新到内存中,并向edis log中写消息(即使机器断电,信息仍会保存到edis log中)
四 、SecondNameNode原理
Hadoop会维护一个fsimage文件,也就是namenode中metedata的镜像,但是fsimage不会实时与namenode内存中的metedata保持一致,而是每隔一段时间通过合并edits文件来更新内容。Secondary namenode就是用来合并fsimage和edits文件来更新NameNode的metedata的。
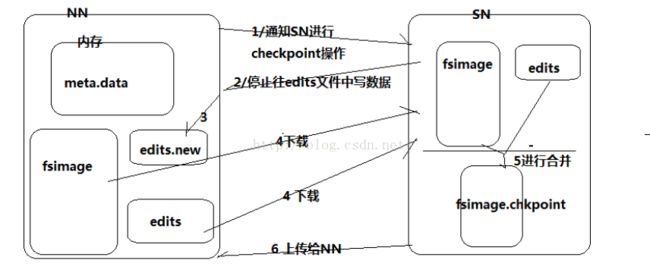
1.NameNode通知SecondNameNode进行checkpoindt操作
2.SecondNameNode收到消息,停止向edis log中写入信息
3.NameNode中生成一个新的edis log
4.原有的edis log 和fsimage下载到SecondNameNode中
5.SecondNameNode将原有的edis log 和fsimage进行合并,产生一块新的fsimage
6.新产生的fsimage上传给NameNode,取代旧的fsimage