大数据-重新学习hadoop篇-完成
前言:
首先这次重新学习为了后面校招,我会把我每天复习学到的一些觉得重要的知识点进行总结下来,持续更新,为实习做准备,加深记忆,从今天开始可能就不会法leetcode的相关题解了,但是每天还是会做每日一题的,加油。
hadoop优势
1.高可靠性:Hadoop底层的hdfs会进行副本存储,当一台机器挂了的时候,它有副本就可以重新启动恢复
2.高扩展性:当双11这种网络拥堵情况出现的时候,可以扩充机器进行负载均衡,所以扩展性也是非常不错的
3.高效性:可以多节点同时工作和高可靠性相互依赖
4.高容错性:任务失败可以重新调度
hadoop的三个大版本显著区别(1.0,2.0,3.0)
对于hadoop1.0来说不存在YARN,没有资源调度,没有高可用,会出现单点故障
对于hadoop2.0来说增加了YARN,也有了多机器操作
对于hadoop3.0来说增加了HA,MapReduce得到了性能优化
hadoop的shell命令
首先有三个命令:
hadoop fs:通用的文件系统命令,针对任何系统,比如本地文件,HDFS......(当文件系统是HDFS时候,与下面两个等效)
hadoop dfs:特定针对HDFS的文件系统,但hadoop3.0之后不推荐用(但是这个bug比较少)
hdfs dfs:hdfs文件系统的操作命令,建议用这个代替hadoop dfs的命令
我推荐用hadoop dfs因为我用hdfs dfs命令老有错误。。。
操作命令:
移动本地文件夹到HDFS端-moveFromLocal(注意一般的hdfs操作命令都是驼峰命名法)
hadoop dfs -moveFromLocal (本地文件夹位置) (HDFS文件夹位置)复制本地文件到HDFS端-copyFromLocal
hadoop dfs -copyFromLocal (本地文件夹位置) (HDFS文件夹位置)3.复制本地文件到HDFS端-put(与copyFromLocal用法一致,这个简单用的多)
hadoop dfs -put (本地文件夹位置) (HDFS文件夹位置)4.复制HDFS端文件到本地-copyToLocal
hadoop dfs -copToLocal (HDFS文件夹位置) (本地文件夹位置)5.复制HDFS端文件到本地-get
hadoop dfs -get (HDFS文件夹位置) (本地文件夹位置)6.追加命令(因为HDFS不支持文件修改,或者说文件修改效率很低下)-appendToFile
如果要修改两种方法1.将hdfs文件get拉取到本地磁盘修改之后在put上去进行覆盖 2.追加
hadoop dfs -appendToFiile (本地文件夹位置) (HDFS文件夹位置)7.一些其他的命令,类似于linux命令,Eg:ls,ll,cat,touch,chmod,tail .......
hadoop dfs -ls /javaapi实现hdfs的读写过程
比较简单,没啥演示的,导入jar包,配置config,就可以使用了......
hdfs写入数据的流程
1. 用户请求数据namenode数据是否可以上传
2. namenode进行数据响应 第一点:查看该用户是否有权限进行写 第二点:查看上传目录是否可行
3. namenode响应结果(根据复制负载均衡和节点可用性来选择datanode)给用户(并且自己会将元数据存入本地磁盘保存,后面会说),用户开启流传输通达通道,每次发送一个block(0-128m)大小的资源
4. 用户准备发送,FsDataoutStream流发送,以最小单位chunk开始(512byte内容+4byte头文件),当chunk到达64k时候进行打包以流的形式发送到datanode
5. datanode被namenode选择好了之后,建立两个管道,第一个是传输管道,第二个是ACK应答管道(保证数据的完整性,如果机器挂断,后面还可以恢复)
6.数据传输采用串行方式进行传输,传给第一个datanode后,它一边接受一般往后面其他副本datanode进行传输,然后等代它们的ACK应答
网络括扑,节点距离计算
简单,不重要,了解即可,类似与树找父母节点
副本选择(根据源码读取得到结论)
1.第一步找到一个最近机架放至第一个副本
2.第二个是与第一个节点不同机架的最近机架(高可用性)
3.第三个是与第二个节点相同机架的不同节点(高效性)
解释:首先第一个节点找最近的是没啥好说的,第二个节点找不同就是为了宕机之后的恢复,高效性的体现,第三个与第二个在同一个机架是为了防止网络传输导致性能损失,因为第一个节点与第二个节点传递时候要建立一个网络连接(跨机架连接),第二个与第三个也要建立,但如果第二个和第三个在同一个机架的话,就可以避免跨机架传输减少网络资源浪费
为什么block大小一般是128m??(新浪面试题)
因为这个与硬盘传递效率有关,当hdfs找资源的时间为10ms时,我们理想状态下,当寻找时间是传递时间的百分之10的时候最为理想,所以传递时间为1s,正常我们的机械硬盘传递速度是100mb/s,好公司的固态硬盘可以达到200mb/s,所以当100mb/s的时候我们block为128mb时是最理想的(1024进制,不能是100mb吧?),所以大公司一般的block大小是256m
Hdfs读取数据流程
1.首先客户端向namenode发送读取请求,namenode根据1.用户权限 2.内容有效性(根据元数据是否存在)
2.namenode将元数据返回给客户端,客户端创建FsDataInputStream流进行block读取
3.根据负载均衡(每个datanode都有副本)来读取对应的datanode
4.串行从datanode读取好对应的block后,进行拼接就可以得到
namenode和Secondnamenode工作原理(重点)
一般开发环境下是不存在2nn的,因为有HA可以完美完成2nn的工作(因为2nn的内容没有nn完全,毕竟是秘书.不存inprogress文件.这个文件记录用户在线操作)
有个问题就是将namenode的元数据存在内存还是磁盘呢?
1.内存 计算速度快,但是宕机之后数据就没了,安全性不好
2.磁盘 计算速度慢,但是持久化到磁盘的话是安全的
有人说两个一起用?只会更慢........
我们根据core-site.xml发现了元数据和hdfs的存储数据在data目录里面

找到这个目录查询档期那namenode到底存了什么,进入这个目录?
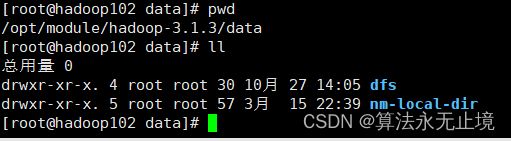
发现有两个目录dfs和nm-local-dir
进入nm-local-dir,我们发现是一些内存缓存(cache)

进入dfs,第一个data文件进去一直点是我们hdfs的副本的实时存储文件,里面存放我们的hdfs内容

进入第二个name,in_use.lock是缓存

再进入current,发现了namenode的存储内容(重点)
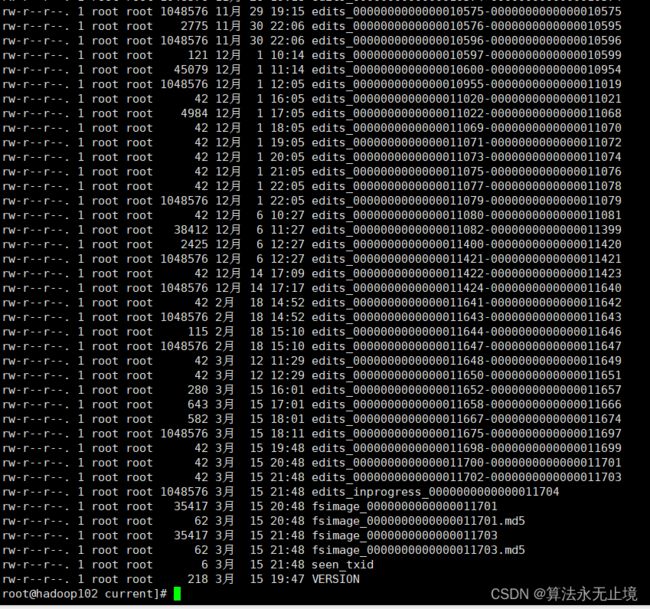
1. edits_0000000000000011702-0000000000000011703 是我们的操作内容(加密了无法查看)
2. edits_inprogress_0000000000000011704 可以理解为我们正在操作的内容(和后面的2nn有关系)
3. fsimage_0000000000000011701 和 fsimage_0000000000000011701.md5 是镜像序列话的文件,md5是加密文件
4. seen_txid记录当前操作的id,VERSION记录当前版本
然后我们进入2nn的目录,因为我是集群,所以我的2nn在另一个虚拟机上面
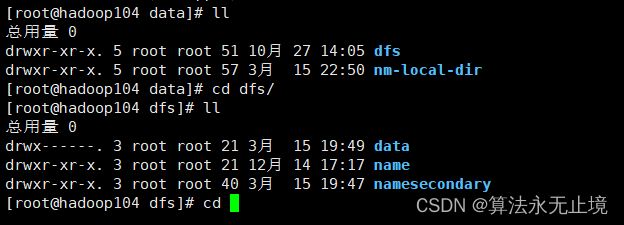
进入namesecondary
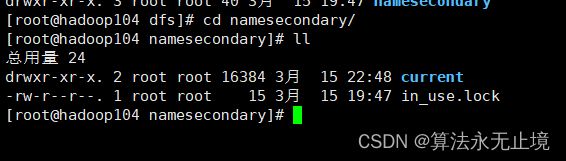
一直进到底

发现和我们的nn是一样的配置,但是少了一个edits_inprogress_0000000000000011704,seen_txid
所以我们现在来看两个的工作机制会更清楚,再说之前提一句,fsimage文件是存储数据结果的,因为hdfs无法进行修改只能追加,edits是将操作过程记录下来,最后服务器启动的时候就会将二者合起来生成新的edits加载到内存
1.当启动服务器的时候fsimage(镜像文件)文件和edits(编辑日志)合并起来放到内存里面
2.当用户的CRUD操作来了之后,我们会先修改inprogress文件再同步到内存的edits(因为这样安全,防止突然宕机引起丢失数据)
3.2nn会规律的向nn发送checkpoint请求(1.一小时 2.当edits内容到100w条的时候)
4.如果checkpoint得到响应之后,2nn会把nn里面的inprogress和edits拉到磁盘进行合并,在自己磁盘里面进行备份(就是我们看到的那些edits文件, 但是没有inprogress,因为2nn不做资源调度 )
5.合并完成之后备份了之后,发送给nn,形成新的edits,并且nn建立一个新的fsimage覆盖原来的fsimage,之后用户的CRUD都会在新的fsimage进行备份存储
(2023.3.15.23点05分 )
我找到了一些方法查看fsimage镜像文件的方法
hdfs oiv -p 文件类型 -i 编辑日志 -o 转换后文件输出路径查看edits文件的方法
hdfs oeev -p 文件类型 -i 编辑日志 -o 转换后文件输出路径我们用上面方法打开文件进行查看
打开xml文件

往下翻,下面有我们的树目录,里面记载了我们的父节点和子节点,也就是我们所说的上级目录和下级目录

(2023.3.27.22点10分)
edits文件
我们都知道edits文件是用户的操作结果文件.所以还是很重要的.它的合并有三个条件:
1.每一小时合并一次.我们可以在文件存储目录里面看到
2.每一次开关机Namenode的时候合并
3.当文件到达100w条时合并(这种情况一般是生产环境下.2nn每60s检查一次文件大小)
DataNode
因为Namendoe在内存里面所以我们不能说往里面存大量无用的数据.只能是存储一些 元数据.一些DataNode信息等等.
所以一些校验信息.数据长度.时间戳这些数据量大的就会存到DataNode里面. 当服务器启动的时候自动想NameNode汇报.这里面的汇报就会有心跳机制(6小时汇报一次本身块总信息.3s报一次是否死亡信息,当汇报信息时间超出10分钟之后会再给10次机会如果还没有汇报,则认为DataNode死亡)
数据完整性
有CRC校验码等一些手段.(对原始数据进行校验封装.和java流传输时候的序列化一样)
MapReduce过程(重点)
序列化
MapRecude也是网络传输所以也是具有序列化的.它的序列化和java的不一样.它是本身自己就有的.比java序列化带的信息量少.传输快
java实现
1.如果mapreduce过程没有用到它们提供的demo的话,自己的实现类需要实现反序列化
2.实现对应的Writeable接口
3.重写序列化方法
4.重写反序列化方法(与序列化方法顺序一致)
5.如果是放在key的位置还需要实现Compatrto接口(后面的shuffle.reduce需要排序使用)
框架流程
1. inputformat读取数据
2.将数据拉到map端
3.shuffle阶段
4.reduce阶段
5.outputformat拉到磁盘
切片规则
和块大小保持一致.如果是在本地环境就是32m.在集群128m.大公司256m.几个切片到时候对应几个maptask.因为Math.max(minSize,Math(maxSize,blockSize))
1.minSize大小一般是1
2.maSize大小一般是Long.MaxValue,long最大值
3.blockSize表示块大小
综上所述切片规则就是块大小
切片规则还有一个1.1倍的原理(源码告诉的)
就是当你的文件大小不足blockSize大小的1.1倍时切位1片
EG:32mb的本地情况下,因为本地情况下是32m,所以它切成2片码???并不是因为33<32*1.1(35)所以切一片即可..注意逻辑是一片,物理还是切为两片(这里有的小迷糊)
切完后提交给Yarn,每一个文件单独切分(重要)
MapReduce源码简单读取
submit()->ensurestate(JobState.DEFINE)->SetUseNewApi()->connect()
1.submit()提交工作
2.ensurestate(JobState.DEFINE) 检查当前的状态信息是否正确
3.SetUseNewApi()新老api的兼容问题 1.x 2.x 3.x .....
4.connect() 提供对应的jar包.xml文件(本地需要提交.集群环境自带).切片信息---这里面的提交信息完事后就会自动删除.还有一些连接过程(yarn客户端和本地客户端....)
CombineTextInputFormat切片规则
这个切片规则是为了防止小文件很多的情况下.用上面的切分方法(fileInputFormat)会生成很多的小文件及其的不容易管理.所以这个就可以使用(生产环境使用很多)
这个是按照SetMaxInputSplitSize值进行切分的.一般大小是4m
规则:
1.先将文件进行字典排序
2.按照SetMaxInputSplitSize进行初次切分.大于它的直接分半
3.最后按照顺序合并即可
如果是8.02=4+2.01+2.01
注意:如果SetMaxInputSplitSize设置比较大,就只会生产一个切片
ReduceTask
默认开启一个.MapTask根据切片信息进行变化
MapReduce流程(重点)
1.获取处理文本
2.客户端进行submit()提交参数配置信息...到Yarn
3.进行文件切片
4.根据切片信息进行MapTask的开启
5.MapTask默认开启TextInputFormat有两个验证(是否可以切割.RecorderReader(键值对的读取方式))
6.将数据根据客户的特定Map生成特定的键值对
7.进入环形缓冲区(重点)
环形缓冲区(大小一般为100m)分为2部分(各50m),第一部分是索引(元数据),第二部分是数据(k,v)
数据进来的时候先打上标签.当两个的值合起来到达80%时进行反向溢写(为了时间效益的最大化.因为如果到了100%在溢写的话.会有各数据流的打开和关闭时间会浪费掉)
溢出到磁盘的时候会进行快排(分区内排--分区按照hash值%mod)(根据字典顺序)注意这里面的排序不是排数据.而是排索引.因为这是初步排序.而且这样排速度快.不需要调换数据位置.这里面的溢出还是溢出到一个文件(可能一个文件包含多个分区)里面的.
输出到磁盘的时候在进行归并排序(对于已经半序列化的数据来说更快).在这之前有一个combiner(压缩合并)操作.可选择的.目的为了减轻Reducer过程的压力
8.所有的MapTask过程完成后会开启ReduceTask过程(这个其实不一定完全是当MapTask完成之后开启的.大多数情况下是)
9.ReduceTask会主动拉取磁盘的数据进行对应的用户合并,会生成多个文件.每一个文件一个分区.拉到文件后进行再一次归并排序,这也是为什么我们Recuder过程时.相同的key会进入到一个Reduce过程
10.用户进行特定的Reduce之后.利用RecorderWriter写出到磁盘形成对应的分区文件Partitaion
(2023.3.27.22点51分)
(2023.3.28.22点31分)
shuffle详解
1.数据进来先打上了分区标签.这个分区按照用户指定的再Map阶段就进行了分区
2.环形缓冲区80%进行反向溢出.一半存元数据(index(位置信息).partition(分区信息).keystart(序列化了.因为要进行io传输).valuestart(序列化了))利用元数据到时候进行快排.一半存真正数据
3.溢出到磁盘这过程(这里还做了归并排序)还可以加入combiner阶段
4.开启ReduceTask过程
2023.4.16.18:14
Partitioner详解
源码自带的按照HashCode值进行分区=>(HashCode%Long.MaxValue)%Mod
如果是自己自定义一个分区策略
1.继承Partittioner接口,重写getPartition方法,分区必须从0号分区开始
2.在Job驱动种加入,job.set......(*.class)
3.修改ReduceTask数量,不然默认ReduceTask数量是1,走的默认系统自带的分区
Combiner详解
主要的目的就是减少Reducer端的压力,进行一个提前的预合并,因为一般开发环境下Reducer端是少于Map端的,一般的合并位置在Map端进行预合并,使用的前提是 局部合并的结果不会影响到整体的结果 这个是非常重要的,而且记住一点,没有Reducer阶段就没有Combiner阶段,Map阶段只负责计算。
环形缓冲区的元数据
包含以下几种meta:index、partition、keystart、valuestart(支持序列化,因为要跨节点传输)
Hadoop的压缩方式
主要分为三种情况
1.在Map端的压缩:主要考虑能不能切片
2.网络传输方面的压缩:考虑压缩速度
3.Reducer端:考虑压缩率
压缩方式:Snappy、Lzo、......
YARN
基础架构:
ResourceManger:1.处理客户端请求 2.监控ResourceManger 3.启动ApplicationMaster
NodeManger:1.管理单节点资源 2.处理ResourceManger命令 3.处理ApplicationMaster命令
ApplicationMaster:1.为应用程序申请资源,并且分配内部任务 2.任务的监控和容错
Container:容器,对于Yarn的抽象,包含CPU,磁盘,网络......
工作流程:
1.用户提交MR程序-main()-job.waitForCompletion()-开启YARN
2.想ResourceManger申请Application,ResourceManger,返回一个资源提交路径
3.用户将jar,xml,split,提交
4.ResourceManger将请求放入FIFO缓存队列,并将请求发送给NodeManger,开启对应的Continer容量,来运行MR任务,将用户刚上传的jar,xml,split下载到本地进行MapTask任务
5.NodeManger向ResourceManger申请开启MapTask容器,随之开启Continer开启对应的MapTask
6.MapTask完了之后重复上述的过程进行ReducerTask任务的开启
7.所有任务执行完毕之后进行资源的释放
Yarn调度器算法
过程由ResourceManger进行调度
大体上分为三种算法:
FIFO,容量,公平
Apache Hadoop 3.1.3默认用的资源调度器是Capacity Scheduler,也就是我们上面所提到的容量调度器的一种实现
FiFO基本是不用的因为效率是十分低下的,它采用的是我们传统意义上的队列,先进先出的算法进行排序,而且是单队列,效率不高,后面的两种算法在此基础上增加了多队列的方式进行提高性能.
容量队列的实现:多队列(FIFO),每一个单独的FIFO都有分配对应的资源进行任务的执行,容量队列保证每一个资源的最低和最高资源分配情况,让多FIFO可以进行互相的一个调用。比如有的队列内容是空闲,那么它的资源就可以被其他队列所使用,如果该队列的任务到了之后,被占用资源即可返回
公平调度器:多队列(FIFO),容量保证,灵活性,多租户进行使用。
将上面两个算法进行一个区分:
容量:选择资源利用率低的队列进行使用
公平:选择对资源缺额比较大的进行使用
至此结束Hadoop的复习过程